卷积神经网络对SAR目标识别性能分析
2018-11-06,,
, ,
(海军航空大学, 山东烟台 264001)
0 引言
合成孔径雷达(Synthetic Aperture Radar,SAR)由于具有全天候、全天时和一定的穿透成像能力,可以不受气候条件对地面及海面目标持续观测,已经被广泛应用于战场侦察和情报获取等领域[1]。区别于传统光学图像,SAR图像具有微波波段成像和相位相干处理的显著特征[2],这使得SAR图像一方面可以反映出目标的微波散射特性,获得大量从光学图像和红外遥感图像无法得到的信息[3],另一方面也受到阴影、迎坡缩短和顶底倒置等不利影响,增强了图像的模糊性和畸变性,难以直接解读。SAR自动目标识别(Automatic Target Recognition,ATR)作为SAR图像解译中的重要环节,一直都是国内外学者的研究重点[4]。传统SAR图像目标识别方法主要由预处理、特征提取、识别分类等相互独立的步骤组成,特征提取过程一般需要借助SIFT[5],HOG[6]等算法提取具有良好区分性的特征才能较好地实现分类,但复杂的流程不仅限制了SAR图像目标检测识别的效率,也制约了目标检测识别的精度[7]。
卷积神经网络(CNN)作为一种端到端的处理架构可以直接使用图像的原始像素作为输入,降低了对图像数据预处理的要求并且避免了复杂的特征工程,自动学习数据的分层特征相比人工设计特征提取规则可以对原始数据进行更本质的刻画。此外,局部连接、权值共享及池化操作等特性可以有效地降低网络的复杂度,减少训练参数的数目,使CNN模型对平移扭曲缩放具有一定程度的不变性和容错能力[8]。1995年,Lecun等提出的LeNet-5系统[9]在MNIST数据集上得到了0.9%的错误率,并在20世纪90年代成功应用于银行的手写支票识别,但此时的CNN只适合小图片的识别,对于大规模数据识别效果不佳[8]。2012年,Krizhevsky等[10]提出的AlexNet在ImageNet大规模视觉识别挑战竞赛(ImageNet Large Scale Visual Recognition Challenge,LSVRC)上取得了15.3%的Top-5错误率(指给定一张图像,其标签不在模型认为最有可能的5个结果中的几率),远远超过第二名26.2%的成绩,使得卷积神经网络开始受到学界的高度关注,许多性能优秀的网络模型也在AlexNet之后被陆续提出[11]。2014年,Szegedy等[12]提出了基于Inception结构的GoogLeNet,将Top-5错误率降低到了6.67%。同年,牛津大学的视觉几何组提出的VGGNet[13]也取得了优异的成绩,获得了ILSVRC-2014中定位任务第一名和分类任务第二名。2015年,He等[14]提出的残差网络(Residual Network,ResNet)致力于解决识别错误率随网络深度增加而升高的问题,使用152层深度网络取得了3.57%的Top-5错误率。2017年,中国自动驾驶创业公司Momenta的WMW团队提出的SENet(Squeeze-and-Excitation Networks)[15]通过在网络中嵌入SE模块,在图像分类任务上达到了2.251%的Top-5错误率,是迄今为止该挑战赛上取得的最好成绩。此外,近年来出现的DenseNet[16],ResNext[17],ShuffleNet[18]都在不同方面提升了卷积神经网络的性能。
当前,很多卷积神经网络模型在计算机视觉领域取得了很好的效果,但很多性能优异的网络尚未推广到SAR图像目标识别领域,且在各类挑战赛中参赛者一般会使用每副验证图像的多个相似实例去训练多个模型,再通过模型平均或DNN集成获得报告或论文中描述的足够高的准确率,导致不同抽样方式或集成大小下模型准确率与报告中的网络性能产生偏差。基于此,本文首先介绍了几种具有代表性的卷积神经网络模型,然后在MSTAR数据集上对各网络的性能进行测试,分析不同模型对SAR图像识别的性能,为卷积神经网络在SAR图像目标识别上的应用建立基础参考。
1 近五年主流卷积神经网络模型
1.1 AlexNet
AlexNet[10]是一个8层的卷积神经网络,由5个卷积层(其中一些紧跟着最大池化层)和3个全连接层组成,最后通过softmax层得到分类评分。AlexNet的主要创新点在于:采用了修正线性单元[19](Rectified Linear Units,ReLU)作为激活函数,更加符合神经元信号激励原理,这种简单快速的线性激活函数在大数据条件下相比于sigmoid等非线性函数可以获得更好和更快的训练效果;采用了Dropout和数据增强(data augmentation)等策略防止过拟合,降低了神经元复杂的互适应关系,增强模型鲁棒性;采用两块GTX 580 GPU并行训练,两个GPU可以不用经过主机内存直接读写彼此的内存, 大幅提高了网络训练速度。
1.2 VGGNet
VGGNet[13]是牛津大学和Google DeepMind公司的研究员一起研发的深度卷积神经网络,探索了卷积神经网络的深度与其性能之间的关系,突出贡献在于证明使用很小的卷积(3×3),增加网络深度可以有效提升模型的性能。VGGNet还采用了多种方法对网络性能进行优化:采用尺度抖动(scale jittering)方法对图片进行裁剪,得到尺寸不一的图片进行训练,增强模型鲁棒性和泛化能力;采用预训练(pre-trained)方法先训练浅层网络,再利用训练好的参数初始化深层网络参数,加速收敛;在网络中去掉了AlexNet中提出的局部响应归一化策略,减少了内存的小消耗和计算时间。
1.3 GoogLeNet
GoogLeNet由Szegedy等于2014年提出的,是一个基于Inception结构的22层深度卷积神经网络架构。该网络的显著特点是不仅增加了网络的深度,还通过引入Inception模块拓宽了网络的宽度,主要原理是利用密集成分来近似最优的局部稀疏结构。 Inception模块的结构如图1所示,采用了不同尺度的卷积核(1×1,3×3,5×5)来处理图像,使图像信息在不同的尺度上得到处理然后进行聚合,使模型同时从不同尺度提取特征,增强了学习能力,该模块的使用使得GoogLeNet的参数比AlexNet少12倍,但准确率更高。图1中粉色部分的1×1卷积核的作用是降低参数量,加速计算,详细原理可见文献[20]。此外,GoogLeNet的作者还做了大量提高模型性能的辅助工作,包括训练多个模型求平均、裁剪不同尺度的图像做多次验证等,详见文献[12]的实验部分。
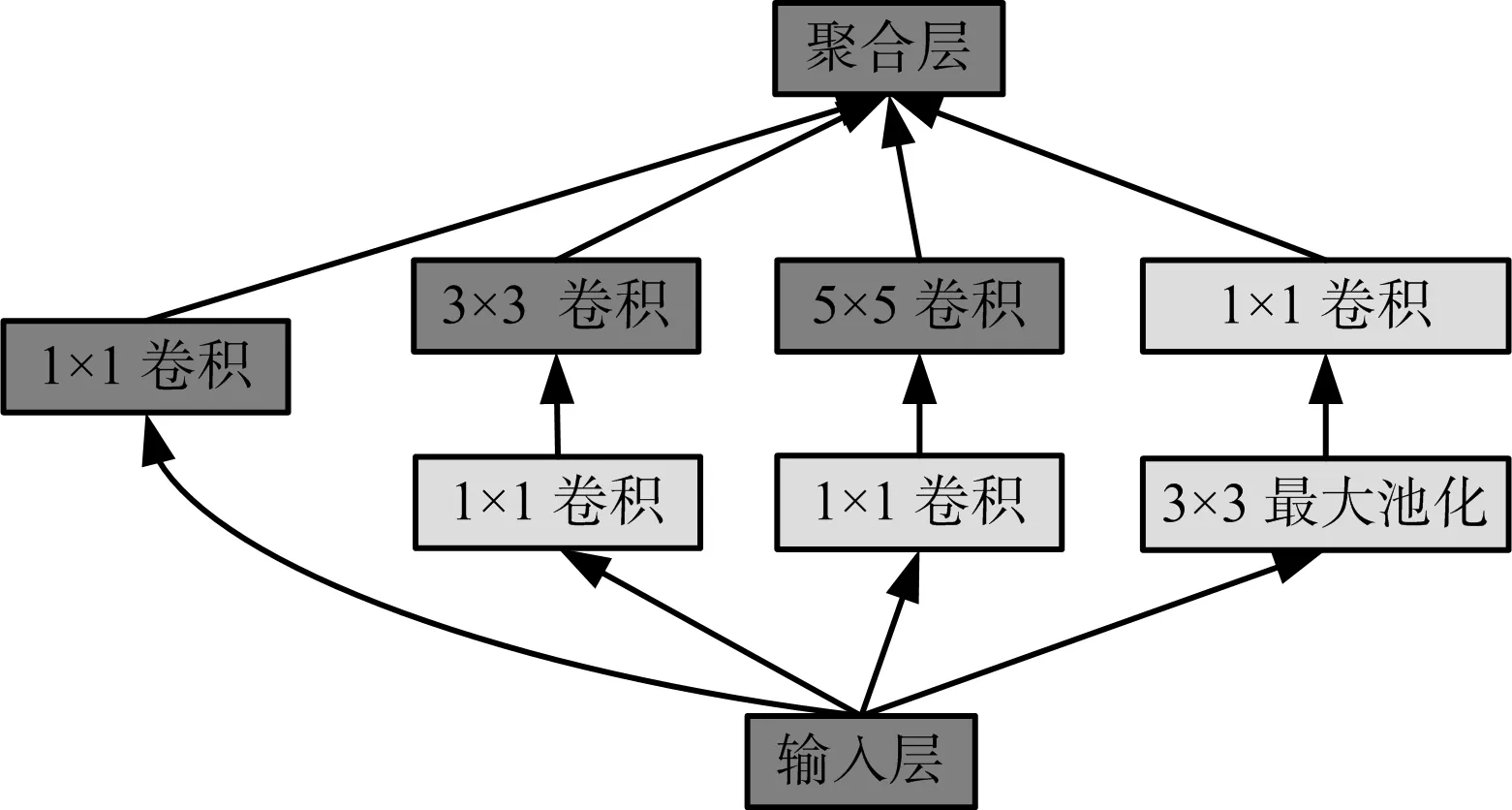
图1 Inception模块结构
1.4 ResNet
自VGGNet提出以来,学者们纷纷致力于通过提升网络的深度以取得更好的性能,但随着网络深度的不断增加,梯度弥散/爆炸[21](vanishing/exploding gradients)问题和随机梯度下降法(Stochastic Gradient Descent,SGD)难以优化深层网络带来的退化[22](degradation)问题随之而来,导致训练和测试误差随网络深度增加而增大。He等针对该问题提出了一个152层的残差网络结构(residual network),如图2所示。H(x)是某一层原始的期望映射输出,x是输入,通过快捷连接[23-24](shortcut connections)在网络中加入一个恒等映射(identity mapping),就相当于从输入端旁边开设了一个通道使得输入可以直达输出,优化目标由原来的H(x)变成输出和输入的差H(x)-x,而对于一个可优化的映射,其残差也会很容易优化至0,且将残差优化至0和把此映射逼近另一个非线性层相比要容易得多[25],因此这样的结构降低了深层网络参数优化的难度,解决了退化问题。文献[26]是He等对ResNet的后续研究,对自身映射在残差网络中的作用进行了更深层次的分析和验证,并提出了改进版的ResNet。
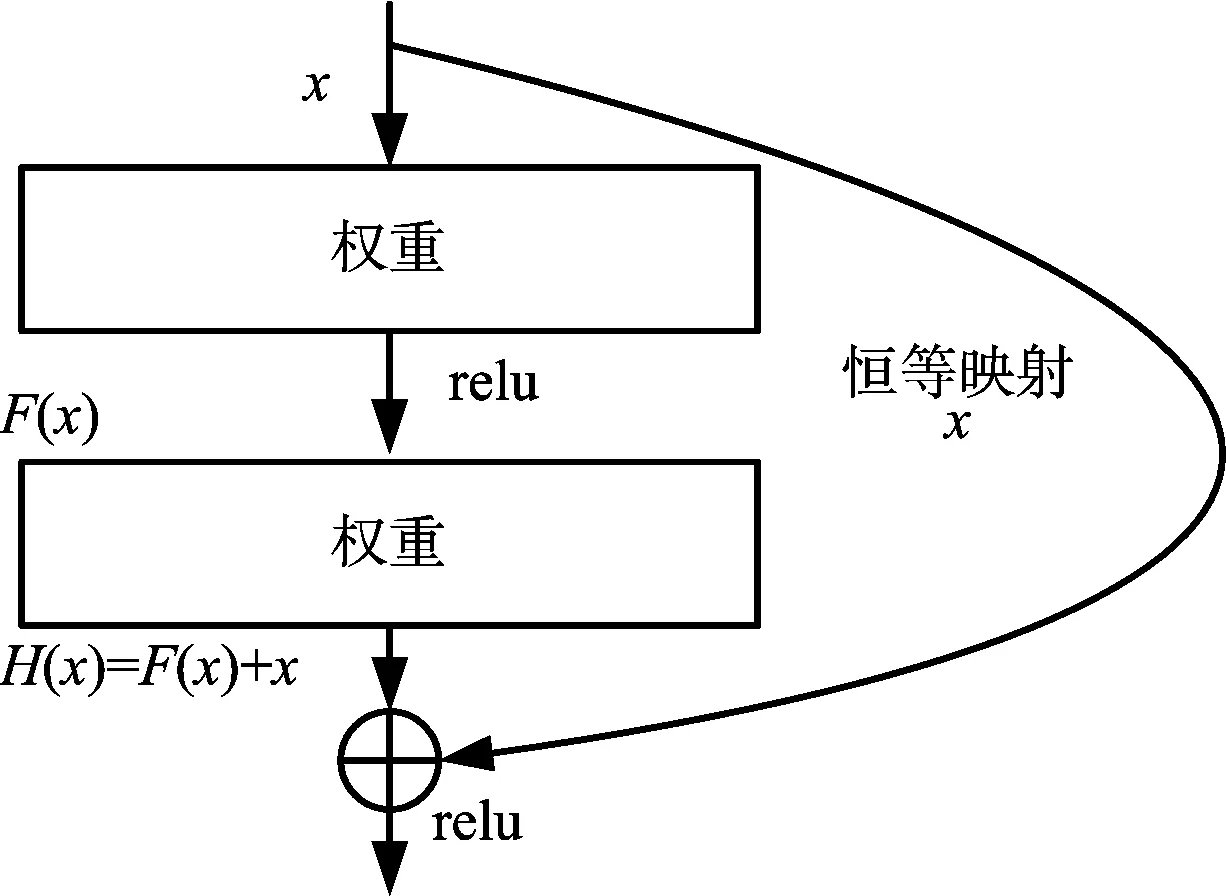
图2 残差网络结构
1.5 DenseNet
ResNet结构中的数据旁路(skip-layer)技术可以使信号在输入层和输出层之间高速流通,核心思想是创建一个跨层连接来连通网路中前后层。文献[16]基于这个核心理念设计了一种具有密集连接的卷积神经网络,即DenseNet。其与ResNet最大的区别在于网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入,通过密集连接实现特征的重复利用,增强了网络的泛化能力。在密集连接的前提下可以把网络的每一层设计得很“窄”,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),所以可以达到降低冗余性的目的。简单来说,DenseNet有以下优点:减轻了梯度消失问题;强化了特征传播;大幅度减少了参数数量。这篇论文获得了2017年IEEE国际计算机视觉与模式识别会议的最佳论文奖。
1.6 SENet
前述很多工作都是从空间维度层面来提升网络的性能,文献[15]将考虑重点放在卷积神经网络特征通道之间的关系,在网络中引入了包含压缩(Squeeze)和激发(Excitation)操作的SE模块,并基于此提出了SENet。Squeeze操作将每个二维的特征通道变成一个实数来代表全局的感受野,并且输出的维度和输入的特征通道数相匹配。Excitation操作是一个类似于循环神经网络中门的机制,通过参数w来为每个特征通道生成权重,用来显式地建模特征通道间的相关性。最后进行重新标定权重(reweight)操作,将 Excitation的输出权重看作是进行过特征选择后每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,提升有用的特征并抑制对当前任务用处不大的特征。文献[15]将SE模块嵌入ResNeXt,BN-Inception,Inception-ResNet-v2上进行结果对比均获得了不错的增益效果。
2 基于经典卷积神经网络模型的SAR图像目标识别实验
2.1 数据集



图3 MSTAR数据集
2.2 实验准备
由于数据集中的原始图片大小均为128像素×128像素且目标基本都处于图片的中心位置,故不需要对原图片作预处理,只进行数据整理即可。首先为训练集和测试集中的所有图片制作标签,用0~8分别代表9类待识别目标,之后将各类数据重新编号整理至同一文件夹下,最后通过pytorch框架中的Dataset模块将数据导入网络中,可以用于直接训练。
本文实验在64位Ubuntu 14.04系统环境下进行,软件方面主要基于深度学习架构pytorch和python开发环境pycharm,硬件主要基于Intel(R) Core(TM) i7-6770K @ 4.00 GHz CPU和NVIDIA GTX1080 GPU,采用 CUDA8.0加速计算。
2.3 实验结果及分析
2.3.1 识别精度分析
为了准确对比各网络的表现,结合数据集实际情况对实验条件作了以下统一设置:迭代次数设置为50次,即将所有图片在网络中训练50次,批处理大小为16,即每次向网络中输入16张图片数据同时进行处理,反向传播过程采用交叉熵损失函数,学习率设置为0.01。分别在LeNet,AlexNet,VGGNet-16(表示16层的网络,下同),Inception-v3(GoogLeNet的改进型),ResNet-18,ResNet-101,ResNet-152,SEResNet-18,SEResNet-101,DenseNet-161(每层通道数为48)共10个模型上测试网络的识别能力。各网络的训练损失曲线和精度曲线如图4和图5所示,最终训练精度和测试精度如表1所示。
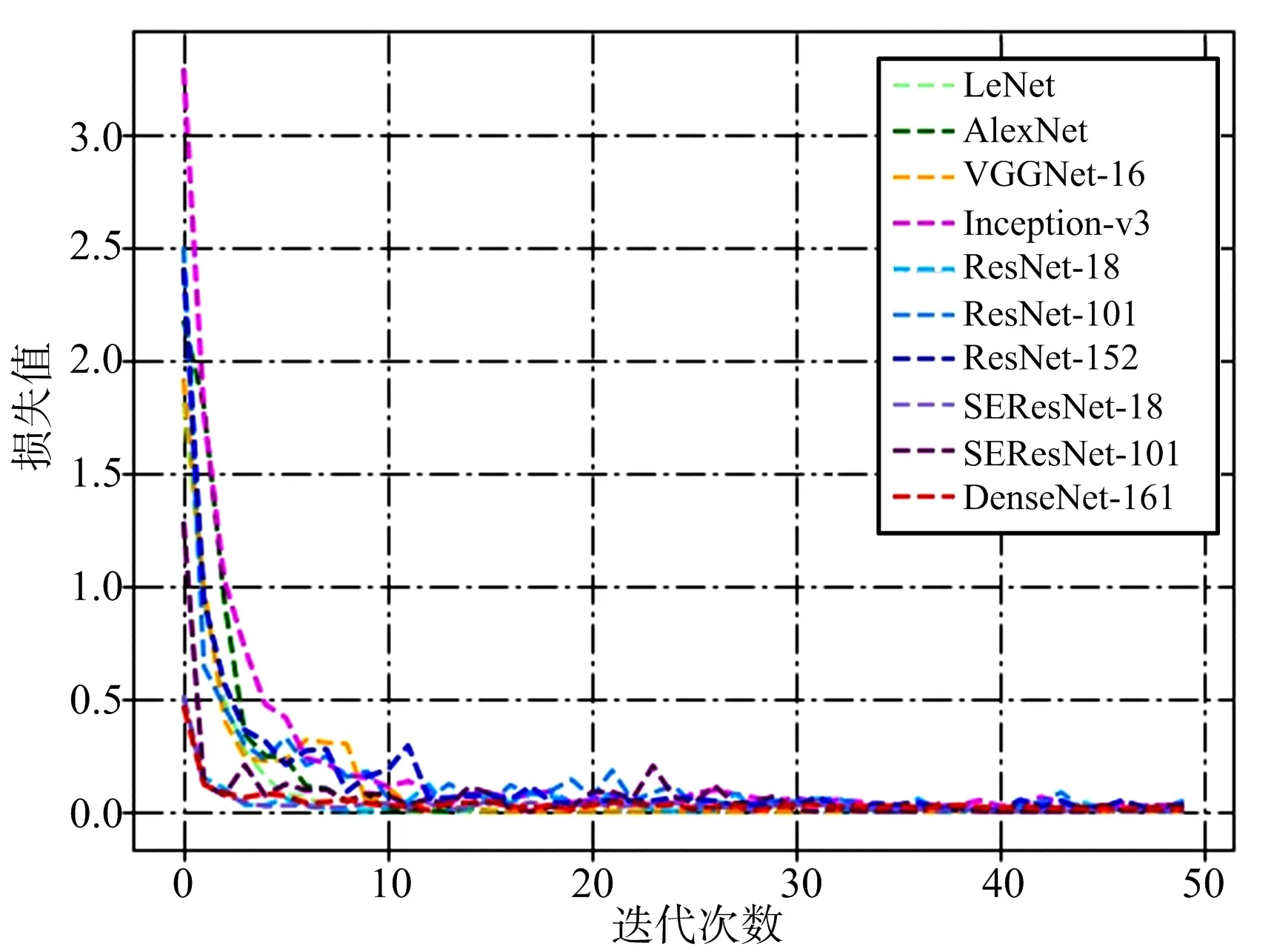
图4 模型损失曲线
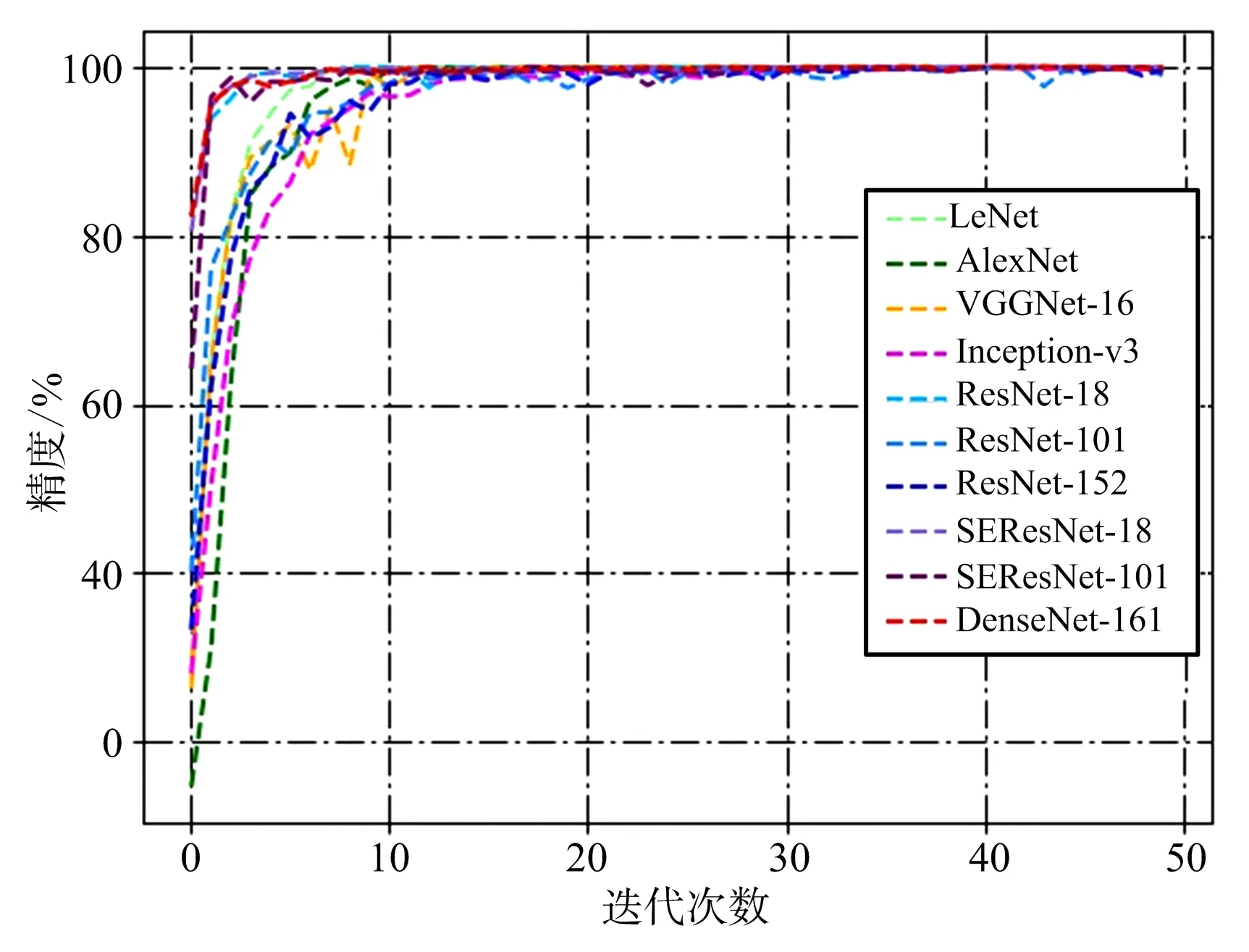
图5 模型精度曲线
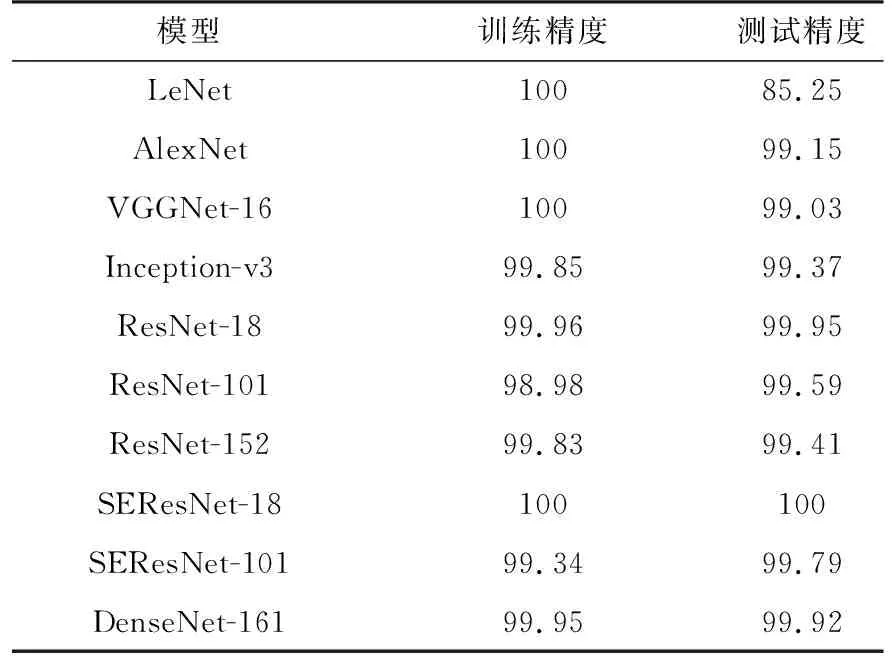
由图4可以看出,各网络在迭代数据集10次左右后都趋于收敛,说明对训练集达到了较好的拟合效果。根据表1可知,除LeNet外的所有模型在测试集上的最终精度都达到了99%以上,SEResNet-18达到了100%的识别精度,测试精度充分说明了CNN模型对SAR图像具有较强的识别和学习能力。LeNet,AlexNet和VGGNet-16三个模型虽然在训练集上都达到了100%的精度,但测试集上的精度却低于其他模型,反映出这些模型的泛化能力不如其他模型。值得注意的是,ResNet和SEResNet系列模型都体现出了网络层次加深识别精度却有所下降的趋势,这并不符合预期,原因在2.3.3节中进行分析。
各模型在测试集上都取得了很高的精度且差异很小,除了网络自身具有较好的性能外,可能还受到以下两点原因的影响:一是本文所采用的数据集属于中小型数据集,总共只有5 156张图片,9种类别,而实验中采用的网络基本都是可以训练百万量级图片,完成近千种分类的大型网络,因而会得到较好的识别效果;二是由于SAR图像数据获取渠道有限,实验中的训练集和测试集图片仅是不同俯仰角成像下的SAR图像,数据集间的差异较小,导致得到了较高的识别精度。虽然数据集较小且训练和测试图片差异较小,但并不影响研究各模型的性能差异,且表1中实验结果基本真实地反映了各模型在其他数据集上的相对表现。
2.3.2 计算资源分析
除了需要考量模型的识别性能,运算时间和模型尺寸等指标也是应用中需要考虑的重要指标。为此,在实验过程中记录了各模型训练和测试时每个迭代周期内的运算时间,并由此计算出各模型的运行总时间、平均时间、单次迭代最大最小时间及时间的标准差,结果如图6和表2所示。
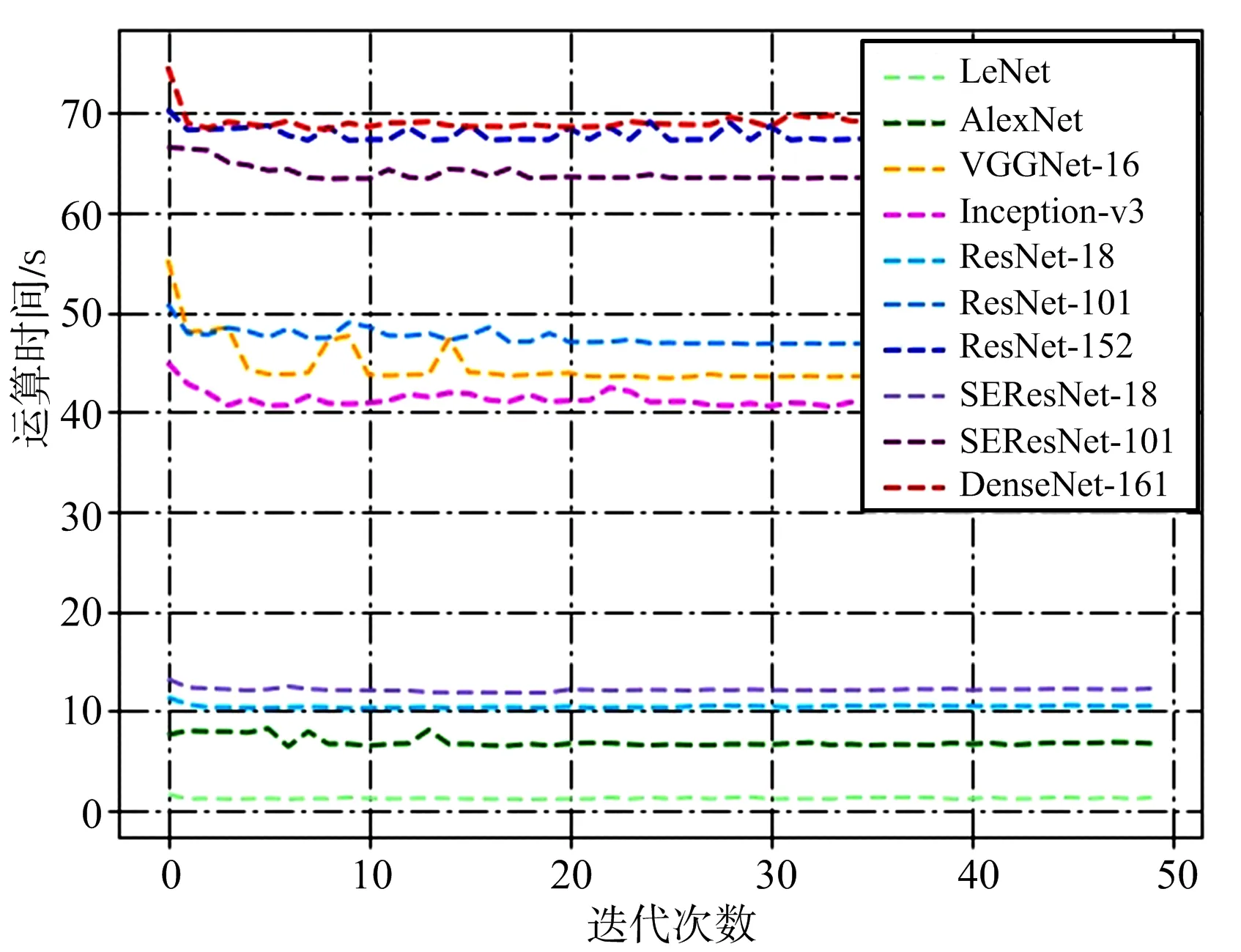
图6 模型运算时间
s
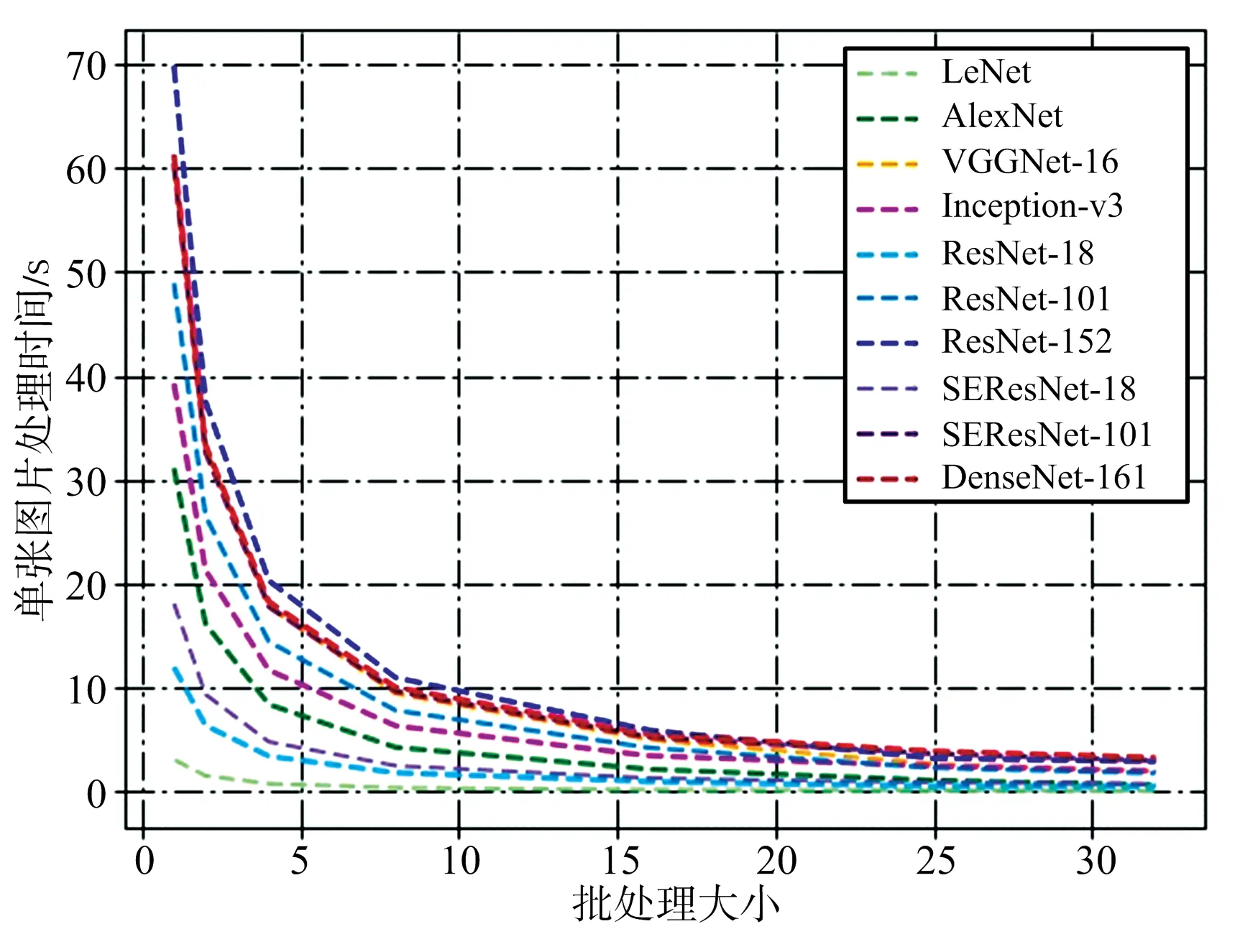
图7 单张图片处理时间
由图6和表2可知,模型的运行时间基本分成了3档,LeNet,AlexNet,ResNet-18和SEResNet-18的运行时间比较短,Inception-v3,VGGNet-16和ResNet-101居中,SEResNet-101,ResNet-152和DenseNet-161运行时间最长,最长时间和最短时间相差近57倍,说明模型深度的增加会明显提高运行时间,也说明在达到基本相同精度的条件下,CNN模型运行时间还有很大的压缩空间。运行时间标准差反映了迭代时的稳定性,可以发现,对于计算时间较小的模型,其稳定性也较好。
另外,SE模块的引入使得计算时间有所增加,SEResNet-101的计算时间接近ResNet-152,计算开销有所增大,但SEResNet-101相比ResNet-101获得了较大的性能提升。
图7给出了模型处理每张图片所需时间与批处理大小的关系,二者呈近似反比关系,批处理大小从1增加到10,每张图片所需的处理时间可以下降3~4倍。由图中还可看出,对于单张图片处理时间越大的网络,处理时间随批处理大小下降的趋势就越明显,这也是批量处理技术广泛应用于当前大型网络加速计算的原因所在。
为了更加全面地研究各模型的计算资源占用情况,实验还记录了各模型在经过训练后的尺寸大小,如表3所示,图8给出了各模型的平均运行时间和模型尺寸之间的对应关系。
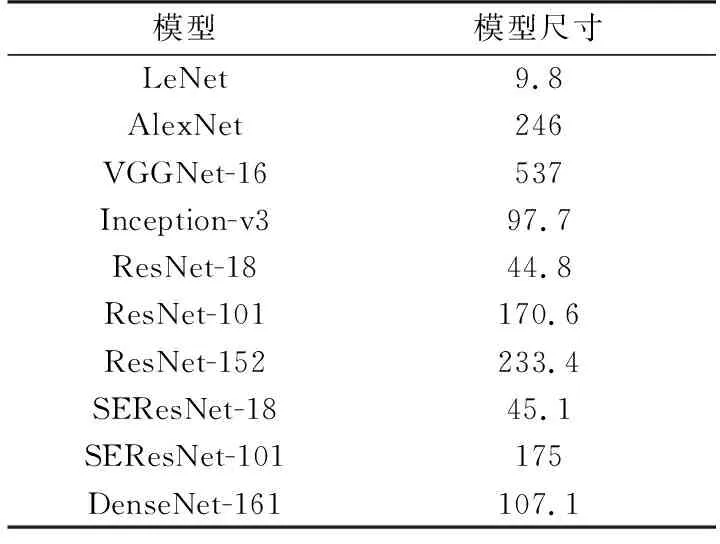
表3 模型尺寸 MB
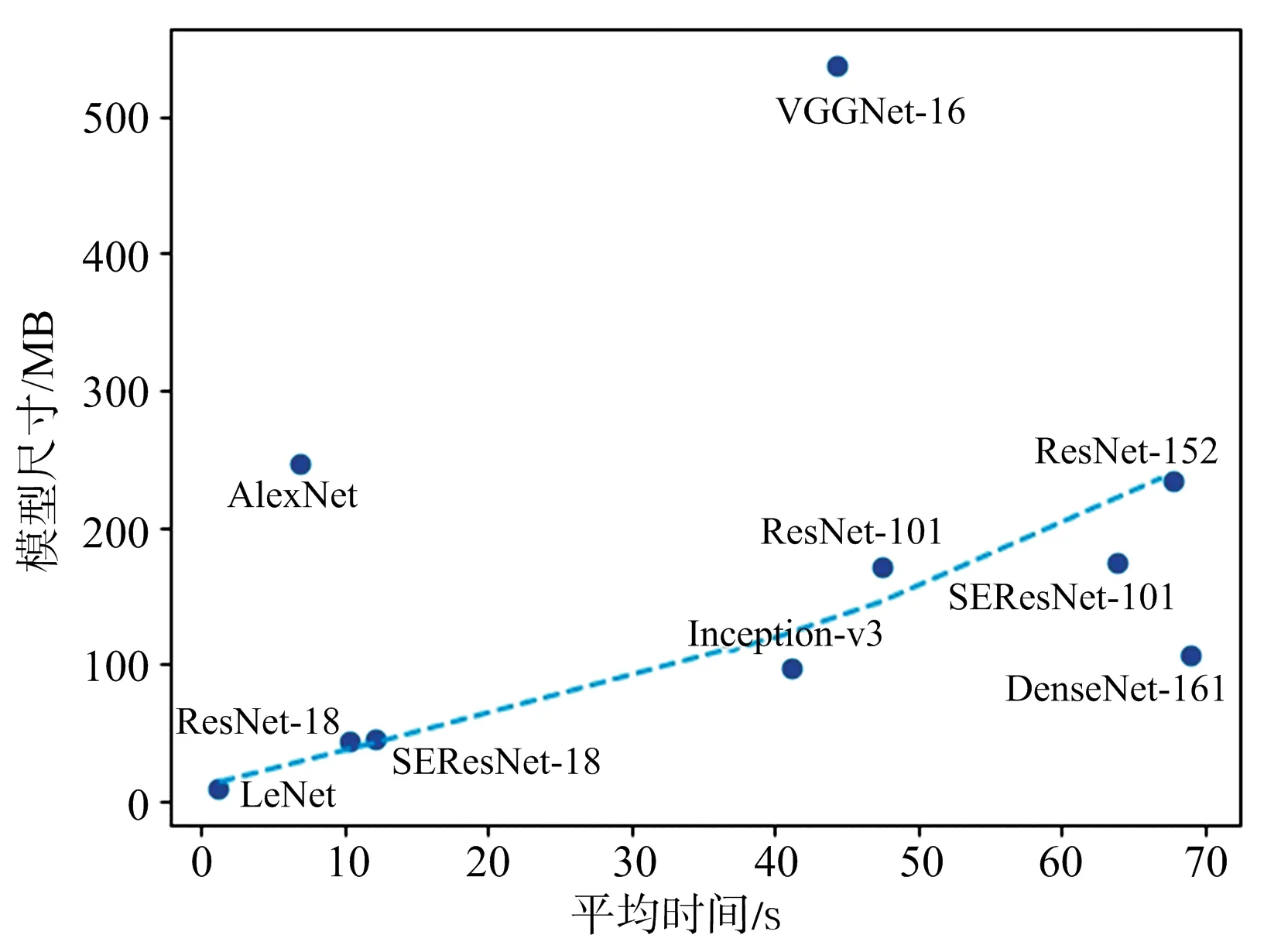
图8 模型平均运行时间和模型尺寸关系图
由图8可以看出,作为早期的CNN模型,AlexNet,VGGNet都是通过加深网络深度和提高模型复杂度来获取更好的性能,从而增加了模型尺寸,而ResNet,DenseNet等新型网络在获得更好的识别性能的同时还显著降低了模型尺寸。图8中除AlexNet,VGGNet和DenseNet-161以外其余网络的模型尺寸基本与运行时间呈正相关,DenseNet-161虽然模型较小却耗时最多,主要是因为其密集连接结构会极大地增加运算量,说明运行时间不仅与模型尺寸相关,很大程度上也受到实际运算量的影响。
综合考虑识别精度和计算耗费,ResNet-18和SEResNet-18两个模型可以在较小的运算时间和模型大小下,取得和其他模型相当或优于其他模型的识别效果,在本实验数据集下是理想的选择。
2.3.3 梯度弥散问题的讨论
为便于分析,从实验结果图5中选取部分模型,如图9所示。
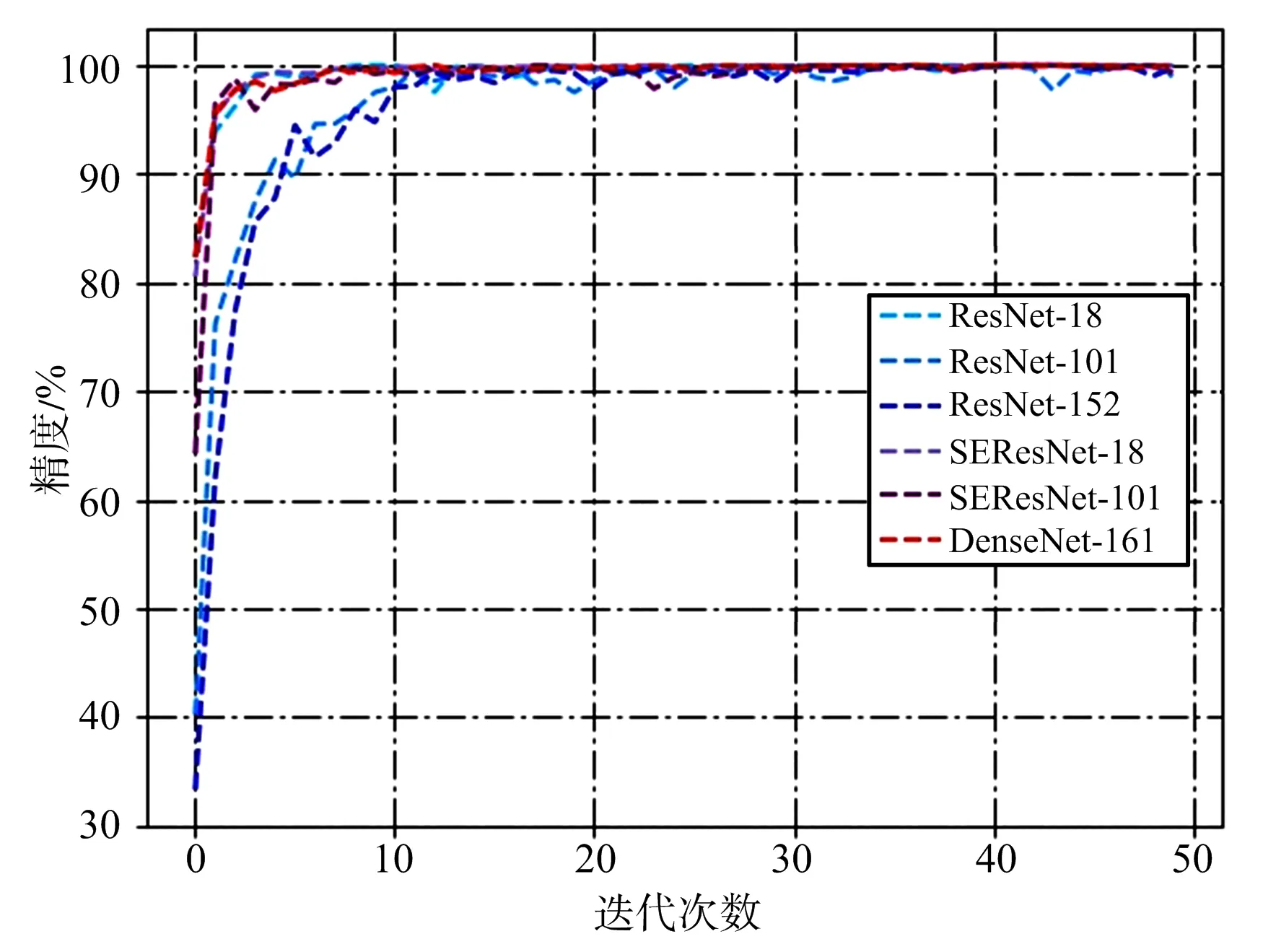
图9 部分模型精度图
结合表1和图9可以看出,浅层网络ResNet-18和SEResNet-18都取得了很好的识别效果,而深层网络ResNet-101 和ResNet-152模型没有取得预想中的比ResNet-18更好的识别性能,引入SE模块的SEResNet-101和采用了密集连接方法的DenseNet-161模型则获得了优于ResNet-101和ResNet-152的识别性能。以上现象说明深层网络中梯度前向传播时出现的“梯度弥散”问题在ResNet-101和ResNet-152中并没有得到很好的解决,而SE模块和密集连接方法则有效缓解了这一问题。
3 结束语
SAR图像目标自动识别是SAR图像解译中的重要环节,也是研究热点和难点。本文将计算机视觉领域关于目标识别的最新成果和近年来出现的若干性能优异的CNN模型应用到SAR图像目标识别上,取得了很好的识别效果,多个模型识别率达到99%以上。综合考量这些CNN模型在SAR图像数据集上的识别性能、计算消耗、运作机制等指标,对比分析了不同模型的优劣之处,实验结果为SAR图像目标识别系统在实际应用中选择、组合和优化各类CNN模型提供了数据支撑和有效参考。
