基于Django与HDFS的分布式三维模型文件数据库构建
2018-11-05廖先富刘俊男
廖先富 刘俊男


摘要: 随着多媒体技术及Internet的迅速发展,三維数据模型的数据快速增加,大容量高速存储系统为三维模型的海量存储提供了基本保障,模型数据库的研究将对工业生产、医学数据管理、机械制造和生产、航空航天领域、罪犯识别系统等方面提供了有力的支持。本文将构建一个基于Hadoop的HDFS文件存储功能与Django相结合构建一个云端分布式三维数据存储系统。通过该系统将解决三维数据目前单一存储的问题。该系统将对于三维模型数据提供“云集中”存储。用户将数据模型统一上传至三维模型数据库中,在构建三维场景时,用户能够通过模型管理系统系统的接口,实现模型库中三维模型的检索、导入、移除功能。
【关键词】云计算三维模型 Django HadoopHDFS
1 云存储技术及HDFS简介
1.1 云存储的概念及结构
云存储是在现有的云计算基础上发展而来,利用集群与网络技术将多台服务器硬盘或其他存储设备连接成一个虚拟的云硬盘,在底层屏蔽了不同存储介质的差异,把网络中各种存储设备协调一致进行工作,共同对外提供数据存储及业务访问功能的一种新的网络存储方式,使用户在操作时感觉就像在操作一个的存储设备一样。云存储伴随云计算技术发展而产生,是对云计算的延伸和发展。
云存储与传统的存储设备不同,云存储一般由底层的多台存储设备构成,高层由对应的应用软件、客户端以及访问接口等组成。通过访问接口层,用户可对云存储进行操作,同时也在一定程度上保证了数据的安全。
1.2 HDFS设计理念
1.2.1 HDFS分布存储
HDFS的设计理念是当数据集的大小超过单台数据计算机的存储能力时就有必要将其区并存储到若干台单独的计算机上。HDFS作为Hadoop生态圈的基础,一流式数据访问模式来存储超大文件,具有一下特点:
(1)适合存储超大文件。由于HDFS的底层建立在多存储模块之上,所以一般存储的文件在GB甚至TB级别。
(2)运行在廉价硬件之上。HDFS在设计之初就考虑到了在集群足够大时,节点故障并不是小概率事件,而是一种常态。所以在设计之初就考虑到了故障的处理,所以当节点发生故障时HDFS能够继续运行并且不让用户感觉到中断。因此HDFS并不需要运行在高可靠但是昂贵的服务器上,普通的服务器即可。这也使得企业的云服务成本进一步得到降低。
(3)流式访问。在HDFS的设计中认为数据一次写入需要多次读取,所以采用了流式访问。
1.2.2 HDFS的组成
HDFS组成如1图所示。
(1)块(block)。
每个磁盘都有默认的数据块大小,这是磁盘进行读/写的的最基本单位,用户在使用文件系统对文件惊醒读写时完全不需要知道块的细节,这些对用户都是透明的。HDFS同样有块的概念,作为HDFS中最基本的存储单位,默认大小为64MB,相对于普通的文件块,HDFS中的块设计的就非常大,这样设计的目的是最小化寻址开销。
其中Tf为寻址所花费的时间,Te代表磁盘传输文件所需时间。根据公式可知随着块的增大,寻址所花费的时间就会减小,因此效率e的比例就会增大。
(2) NameNode和SecondaryNameNode。
(3) DataNode。
(4) HDFS客户端。
1.2.3 HDFS容错机制
(1) HDFS数据块副本机制在HDFS中一个文件可能有许多的数据块( Block)组成,每个数据块的副本的默认数量是3,其中两个放在同一个机架中,一个放在其他机架。这样有效的避免了因外界原因使得某一存储介质不可用而导致数据丢失问题。
(2)心跳检测。 在NameNode和DataNode之间维持心跳检测,当网络出现故障或者拥堵等原因导致DataNode发送的心跳包并未让NameNode接收到,该DataNode被判定无效且不会发送任何新的1/0操作给该DataNode。
(3) HDFS负载均衡。NameNode根据DataNode发送的心跳信息和数据块信息来掌握DaraNode的当前状态,HDFS有一个balancer工具,可以由管理员启动,用来迁移DataNode之间的数据块,当集群负载较高的时候不宜采用,因为可能会造成网络阻塞,造成客户端延迟过大。
(4)检测文件块的完整。HDFS会记录每个创建文件的所有块的校验和,当以后检索文件块或者发现从摸个节点获取文件块时,会首先进行确认校验和是否一致,如果不一致就会放弃该DataNode上的文件块,从其他DataNode上获取。
2 Djang0简介
Dj ango是一个开放源代码的Web应用框架,由Python写成。采用了MVC的框架模式,即模型M,视图V和控制器C。它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的,即是CMS(内容管理系统)软件。Django的主要目的是简便、快速的开发数据库驱动的网站。它强调代码复用,多个组件可以很方便的以“插件”形式服务于整个框架,Dj ango有许多功能强大的第三方插件,你甚至可以很方便的开发出自己的工具包。这使得Django具有很强的可扩展性。它还强调快速开发和DRY(Do Not RepeatYourself)原则。
Django的优点:
(1)自助管理后台,admin interface是Django里比较吸引眼球的一项contrib,让你几乎不用写一行代码就拥有一个完整的后台管理界面。
(2)虽然Django自带的ORM不如SQLAlchemy强大,但也不弱。一般来说可以不怎么使用SQL语句,每条记录都是一个对象,而取对象的关联,易如反掌。
(3) URL design,利用正则表达式進行构建URL。快速且具有很强的适用性。
3 项目构建
3.1 项目简介
随着多媒体技术及Internet的迅速发展,三维数据模型的数据快速增加,大容量高速存储系统为三维模型的海量存储提供了基本保障,模型数据库的研究将对工业生产、医学数据管理、机械制造和生产、航空航天领域、罪犯识别系统等方面提供了有力的支持。为了解决单一服务器并不能满足大量文件存储的难题,分布式的存储被提出,分布式的出现解决了单一机器难以满足存储要求的难题。Hadoop是分布式的一种优秀的实现。Dj ango则是一款优秀的web框架,利用Dj ango可以快速的开发出应用。因此本文将结合Dj ango与Hadoop的Hdfs设计出存储三维模型的web版数据库。
3.2 项目架构
3.2.1 系统架构
三维模型数据库项目的存储层为Hadoop集群,利用HDFS作为三维模型的存储介质。通过HDFS的作为存储介质可以控制模型文件的副本数量,达到安全,高效的目的。数据层利用Mysql或者HBASE作为存储三维模型的信息。服务层利用Django进行页面的展示或者下载。如图2,图3所示。
3.2.2 业务逻辑
用户通过注册获取属于自己的数据库,在自己的数据库中可以进行上传,预览,下载操作。见图4。
3.3 项目的关键实现
3.3.1 Django用户认证
Dj ango内置了用户认证功能,可以免于自己编写登录认证功能。要使用Django自带的认证功能,首先要通过from django.contribimport auth导入auth模块。通过auth模块提供的函数实现注册功能。代码展示如下:
deflogin(request):
if request.method=='GET':
return render(request, "Iogin.html")
ifrequest.method=="POST":
username=request.POSTget("usemame”,””)
password=request.POSTget("password”,””)
U S e r
=authenticate(username=username,password=password)
if user is not None and user.is active:
auth.login(request, user)
print(user)
context={
”user": user,
)
return HttpResponseRedirect(/page/l')
else:
context={
”user": None,
err':”密码或者用户名错误”
)
retum render(request, 'login.html',context)
3.3.2 python操作HDFS
Hadoop的底层接口是通过Java API提供的,但是Dj ango是由python语言进行开发,因此,为了使dj ango能对HDFS进行操作,所以使用了pyhdfs的python包进行操作。可以通过pip install pyhdfs进行安装。Pyhdfs是基于WEBHDFS封装的python包,可以通过简单的函数调用来达到对HDFS的操作。
3.3.3 Django与HDFS的整合
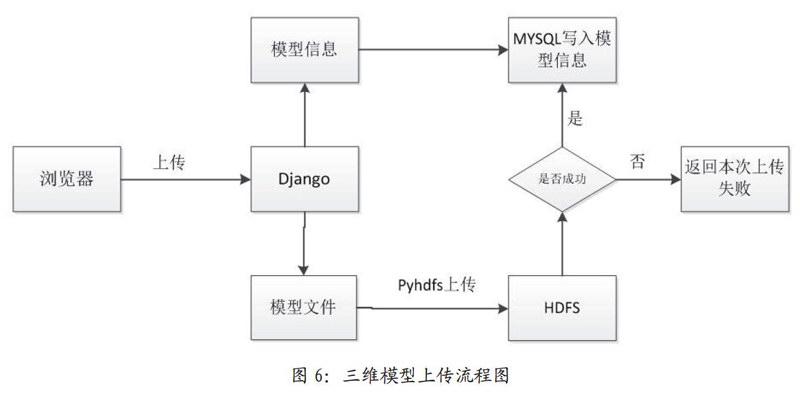
在构建web应用时,三维模型文件的上传到HDFS,需要通过Dj ango将文件上传到HDFS中。前端页面通过form表单进行上传,后端的django接受上传的文件块进行保存到临时缓存目录,再由pyhdfs进行上传到HDFS中。如图6所示在下载时通过Mysql数据库中三维模型文件的HDFS引用地址,再利用pyhdfs进行下载。图6所示。
部分代码如下:
4 总结
本系统的开发建立了一种新型的分布式存储方式,解决来了传统单一服务器不能存储海量三维模型的问题。
为需要大量使用三维模型的企业及用户带来了很大的便利。同时利用Djnago进行开发,极大的简化了开发的难度,为后期的拓展开发提供了便利。当然在本系统中默认考虑的是大型的三维模型文件,由于HDFS本身的特性(每个Block的大小为128M),并不适合对小型模型的存储。
