基于TensorFlow的卷积神经网络的研究与实现
2018-11-05郑攀海郭凌丁立兵
郑攀海 郭凌 丁立兵


摘要: 本文基于TensorFlow设计一种卷积神经网络。通过介绍卷积神经网络的结构,研究卷积神经网络中的前向传播和反向传播算法,推导了前向传播和反向传播的数学公式,并利用TensorFlow买现一种卷积神经网络。在CIFAR10数据集上训练6 000次的topl准确率为74.3%,验证了方法的有效性。
【关键词】TensorFlow 卷积神经网络 前向传播 反向传播
近年来卷积神经网络在图像分类、目标检测、图像语义分割等领域取得了一系列突破性的研究成果。卷积神经网络强大的特征学习与分类能力引起了广泛的关注,具有重要的分析与研究价值[1]。
卷积神经网络的概念最早源于19世纪60年代科学家研究猫的视觉皮层细胞时,提出的感受野[2,3]概念。即每一个视觉神经元,只会处理一小块区域的视觉图像。20世纪80年代,日本科学家提出的神经认知机制[4]是最早实现的卷积神经网络。神经认知机制中包含两类神经元,第一类用来抽取特征的S-cells,对应卷积核滤波操作。第二类是用来抗变形的C-cells,对应激活函数和最大池化操作。通常用全连接网络将像素点作为输入特征处理图像问题[5],没有充分利用到图像空间上的局部相关性,这种方法的最大问题就是参数太多,导致训练时间长,甚至不能训练和过拟合等一系列问题。而卷积神经网络有效利用了图像在空间结构上的关系,从而减少需要学习的参数量,提高BP算法的效率。在LeNet-5,VGGNer,InceptionNet,ResNet[6,7,8,9]等系列经典的图像处理算法中都使用了卷积层做为图像的特征提取代替人工提取。
机器学习的一个重要问题就是模型转化成程序需要花费大量的时间、精力。而谷歌第二代分布式机器学习系统TensorFlow[10]很好的缓解了这个问题。TensorFlow于2015年11月在GitHub开源。自开源以来用户量急剧增加,远远领先其他深度学习开源框架。TensorFlow的核心概念是计算图,计算图是对计算模型的一种抽象。图上每一个运算操作作为节点,节点与节点之间的连接称为边,在边中流动的数据称为张量。会话(Session)是用户使用TensFlow时的交互接口,在TensorFlow中使用会话来执行定义好的计算图的运算。TensorFlow对神经网络中常用的梯度下降算法,BP算法和卷积神经网络都有很好的封装,从而开发人员可以简单而快速的将设计的神经网络转换成程序,并进行研究和测试。这极大的缩短开发周期和促进了机器学习的普及。
本文的主要工作是基于TensorFlow,讨论卷积神经网络的结构,推导了卷积神经网络的前向传播和反向传播算法,对TensorFlow在实现神经网络中常用的函数做了介绍,设计了一种卷积神经网络,并在CIFARl0数据集上进行训练。
1 卷积神经网络架构
卷积神经网络与全连接神经网络类似,从众多经典的卷积神经网络归纳出用于图片分类问题的卷积神经网络架构,卷积神经网络由输入层、若干卷积层、池化层和全连接层组成[11]。下面主要介绍卷积神经网络核心卷积层以及池化层。
1.1 卷积层及其前向传播算法
卷积层是卷积神经网络的核心部分,也被称为过滤器(filter)或者卷积核,即动物视觉中的感受野。图l给出了卷积核的结构示意图。卷积核在数学中就是三维矩阵,矩阵的长度与宽度一般由人工指定。常用的大小是3x3或5X5。深度与前一层网络节点矩阵深度一致。卷积的好处是不管图片尺寸如何,需要訓练的权值数量仅与卷积核的大小、卷积核的数量有关,从而减少了网络中的参数。
卷积神经网络的前向传播算法中需要指定卷积核的深度,卷积核矩阵的尺寸。为了增加对边缘像素的利用一般会在输入矩阵的周围加上若干圈O,再进行计算,这个过程称为填充(padding)。卷积过程中每次移动的像素距离的大小我们定义为步幅(stride)。
图2是前向传播的过程示意图,由图2可以归纳出前向传播算法的公式:
其中参数hik是经过卷积核后更高维的特征图中像素点的权值;aij是输入该层网络的图像的像素点权值;Wij是该像素点对应的权重,即是需要训练的神经网络参数;n是卷积核的尺寸,s是步幅,σ是激活函数,b是偏置项;1i是输入矩阵的长,ki是输入矩阵的宽,p是填充项,1、k分别是高维特征图矩阵的长和宽。
由图2可以看出卷积核具有权值共享,即一个卷积层可以有多个不同的卷积核,而每一个卷积核都对应一个滤波后映射出的新图像。同一个新图像中每一个像素都来自完全相同的卷积核。权值共享可以有效减少网络的参数降低模型复杂度,减轻过拟合的问题。但是权值共享后会导致一种卷积核只能提取一种特征。为了增加卷积神经网络的表达能力,需要设计多个核,在网络中的表现就是增加了特征图的深度。
以python语言为例在使用TensoFlow前以import tensorfiow as tf将其导入到程序中。在TensorFlow中函数tf.nn.conv2d()可以实现卷积网络前向传播算法,调用格式如下: tf.nn.conv2d(input, filter, strides, padding)
(1)
其中mput是上一层网络的输出,filter是该层网络的卷积核,strides是每次移动的步长,padding有两个参数,SAME表示添加全O填充,VALID表示不填充。
1.2 池化层及其前向传播算法
引入池化层能有效的缩小特征图矩阵的尺寸,减小最后全连接层中的参数数量,防止过拟合问题。池化层的前向传播过程与卷积层前向传播过程类似,通过过滤器在图片上滑动完成。池化层过滤器中的计算不是节点的加权和,而是采用更加简单的最大值或者平均值运算,相应的被称为最大池化层和平均池化层。在TensorFlow中函数tfnn.max_pool实现了最大池化层的前向传播算法调用格式如下:
tf.nn.max_pool(input,filter,strides,padding)
这里的参数意义与(1)式一致。
1.3 梯度下降算法和反向传播算法
神经网络的优化过程分为两阶段。第一阶段通过前向传播算法计算得到预测值,将预测值和真实值之间做对比得出两者之间的差距。第二阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。在实际应用中梯度下降算法计算时间长,为了加速更新过程可以使用随机梯度下降算法和动量梯度下降算法。假设用0表示神经网络参数,J(0)表示在给定参数取值下,训练数据集上损失函数的大小。神经网络的训练目标可以抽象为寻找参数θ,使得J(θ)最小。梯度下降算法参数更新公式为:
其中η定义为学习率即每次参数更新的幅度。
BP算法是训练神经网络的核心算法,主要的思想是网络最后输出的结果与真实值比较计算误差,利用链式求导法将误差反向逐级传下去。图3为反向传播示意图,其中conv.表示第i层卷积,下面将结合图3推导反向传播算法。
假设第i层权重系数为w.,偏置系数为bi,输出为fi(x),则根据前向传播算法可得:
定义C(x)为代价函数,根据梯度下降算法得参数更新公式:
在TensorFlow中可采用下述三种优化器实现反向传播算法:
tftrain.GradientDescentOptimizer(learningrate).minimize(loss),
tf.train.MomentumOptimizer(learningrate,momentum).minimize(loss),
tf.train.AdamOptimizer(learning_rate)minimize(loss)
其中leaming_rate是学习率,是神经网络中重要的超参数,学习率过大可能导致模型不收敛,学习率过小可能导致模型收敛速度慢。loss值为需要优化的损失函数。以上为基于灰度图像提出了卷积神经网络的前向传播和反向传播算法。对于RGB图像,可以将其视为三张互不相关的灰度图进行并行处理。
2 利用卷积神经网络对ClFAR-10识别
本文的训练数据集采用CIFAR-10数据集。CIFAR-10数据集包含60000张32*32的彩色图像,其中训练集50000张,测试集10000张,含有10类图片分别是airplane、automobile、bird. cat、deer. dog、frog、horse. ship.truck。其中每类的图片6000张,每张图片上只含一类目标。
2.1 设计卷积神经网络
一个卷积神经网络主要由输入层、卷积层、池化层、全连接层、Softmax[12]层组成。输入层是整个神经网络的输入,对于处理图像的卷积神经网络一般是由图片的像素点。全连接层是由全连接神经网络所构成的,在经过多轮的卷积层和池化层处理得到信息含量更高的特征后,利用全连接神经网络给出最后的分类结果。交叉熵函数是分类问题中使用较广泛的损失函数,刻画了两个概率分布之间的距离。
softmax的定义公式:
其中zi表示输出为第i类的概率。
从定义式可以看出原始神经网络被用作置信度来生成新的输出,而新的输出满足概率分布的定义。这个新的输出,可以认为是经过神经网络的推导一个样例为不同类别的概率。这样就将神经网络的输出变成了概率分布,从而可以使用交叉熵函数来预测概率分布和真实答案的概率分布之间的距离。交叉熵一般会与sofimax回归一起使用,Tensorflow对这两个功能进行了统一封装。定义了交叉熵损失函数调用代码如下:
cross_entropy= tf.nn.softmax_crossentropy_with_logits(y,_y)
其中y代表了原始神经网络的输出结果,-y代表标准答案。
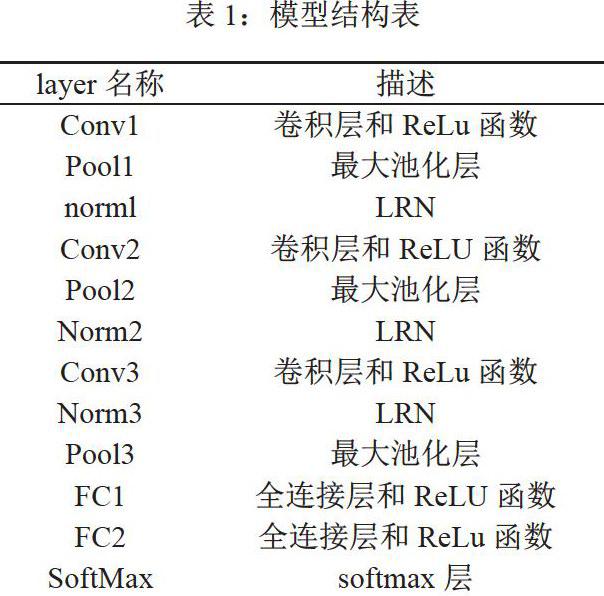
表1给出了一种用于解决CIFAR-10识别问题的卷积神经网络模型,使用局部响应归一化层LRN对结果处理[13],LRN最早是Alex提出,原理是模仿生物神经系统的“侧抑制”机制,引入对神经元活动的正反馈机制,让其中响应比较大的值权重更新最大,抑制反馈较小的神经元的更新。增强模型泛化能力。
整个模型的激活函数采用RELU函数,池化层采用最大池化。为了防止模型过于复杂在模型中加入刻画模型复杂程度的指标R(w)。在优化损失函数时不是直接优化J(θ),而是优化J(θ)+λR(W),其中λ表示模型复杂损失在总损失中所占的比例。常用刻画R(w)函数有两种,一种是Ll正则化计算公式是:
另一种是L2正则化计算公式是:
本文采用的是L2正则化。
深度学习在图像识别上领先其他算法的主要因素是对海量数据的高效利用,我们采用了对图片进行翻转,色彩调整,大小调整,亮度调整,随机剪裁等图像处理方式,得到更多样本提高了模型的泛化能力。
2.2 实验结果
图4给出了模型的训练6000次结果top-l准确率达到74.3%。
对实验结果利用TensorFlow中的数据可视化工具Tensorboard进行观察。Tensorboard设计的交互过程能将运行过程中的计算图、各种指标随着时间的变化趋势以图像的形式清晰的展示出来。图5為损失函数在训练过程变化趋势,在Tensorboard中由图5可见loss值不断呈下降趋势。
4 结语
目前,机器学习己广泛的运用于工业界与学术界。本文研究了卷积神经网络并利用TensorFlow快速实现并训练神经网络,对深度学习算法的发展与未来应用具有一定的意义。
参考文献
[1]李彦冬,郝宗波,雷航,卷积神经网络研究综述[J].计算机应用,2016, 36(09): 2508-2515+2565.
[2] Hubel D H,Wiesel T N.Receptivefields, binocular interaction andfunctional architectures in catsvisual cortex[J].Journal of Physiology,1962,160 (01):106-154.
[3]张振,陈哲,吕莉,王鑫,徐立中,基于视觉感受野的自适应背景抑制方法[J].仪器仪表学报,2014, 35( 01):191-199.
[4]孟丹,基于深度学习的图像分类方法研究[D].华东师范大学,2017.
[5] Fukushima K,Miyake S.Neocognitron: ASelf-Organizing Neural Network Modelfor a Mechanism of Visual PatternRecognition [J]. IEEE Transactions onSystems Man&Cybernetics;, 1982,SMC-13 (05): 826-834.
[6]Lecun Y,Bottou L,Bengio Y,et al.Gradient-based learning applied todocument
recognition [C]. Proceedingsof the IEEE, 1998, 86 (11): 2278-2324.
[7]Simonyan K,Zisserman A.Very DeepConvolutional Networks for Large-Scale Image Recognition [J]. ComputerScience,2 014.
[8] Szegedy C,Liu W,Jia Y,et al. Goingdeeper with convolutions [C]. IEEEConference on Computer Vision andPattern Recognition, 2015:1-9.
[9]He K,Zhang X,Ren S,et al. IdentityMappings in Deep ResidualNetworks [C]. European Conferenceon Computer Vision. Springer,Cham。2016: 630-645.
[10]姜新猛,基于TensorFlow的卷积神经网络的应用研究[D].华中师范大学,2 017.
[11]孙亚军,刘志勤,曹磊,全连接和随机连接神经网络并行实现的性能分析[J].计算机科学,2000,7 (03): 96-97.
[12]冉鹏,王灵,李昕,刘鹏伟,改进Sof tmax分类器的深度卷积神经网络及其在人脸识别中的应用[J].上海大學学报,2018, 24 (30): 352-366.
[13]龙贺兆.基于稀疏深层网络的SAR图像分类方法[D].西安电子科技大学,2015.
