Possible Impact of Spatial and Temporal Non-Uniformity in Land Surface Temperature Data on Trend Estimation
2018-11-05ZhiyuLIWenjunZHANGandHaimingXU
Zhiyu LI, Wenjun ZHANG, and Haiming XU*
1 Joint International Research Laboratory of Climate and Environment Change, Collaborative Innovation Center on Forecast and Evaluation of Meteorological Disasters, Key Laboratory of Meteorological Disaster of Ministry of Education, Nanjing University of Information Science &Technology, Nanjing 210044
2 College of Atmospheric Sciences, Nanjing University of Information Science & Technology, Nanjing 210044
ABSTRACT The present work investigates possible impact of the non-uniformity in observed land surface temperature on trend estimation, based on Climatic Research Unit (CRU) Temperature Version 4 (CRUTEM4) monthly temperature datasets from 1900 to 2012. The CRU land temperature data exhibit remarkable non-uniformity in spatial and temporal features. The data are characterized by an uneven spatial distribution of missing records and station density, and display a significant increase of available sites around 1950. Considering the impact of missing data, the trends seem to be more stable and reliable when estimated based on data with < 40% missing percent, compared to the data with above 40% missing percent. Mean absolute error (MAE) between data with < 40% missing percent and global data is only 0.011°C (0.014°C) for 1900–50 (1951–2012). The associated trend estimated by reliable data is 0.087°C decade–1 (0.186°C decade–1) for 1900–50 (1951–2012), almost the same as the trend of the global data. However, due to non-uniform spatial distribution of missing data, the global signal seems mainly coming from the regions with good data coverage, especially for the period 1900–50. This is also confirmed by an extreme test conducted with the records in the United States and Africa. In addition, the influences of spatial and temporal non-uniform features in observation data on trend estimation are significant for the areas with poor data coverage, such as Africa, while insignificant for the countries with good data coverage, such as the United States.
Key words: temperature trend, gridded data, non-uniformity
1. Introduction
Global warming concerns governments as well as scientists around the world for its huge impacts on society and human life. Based on several gridded historic datasets, such as Hadley Centre–Climatic Research Unit Temperature Version 4 (HadCRUT4; Morice et al.,2012) dataset, Goddard Institute for Space Studies(GISS; Hansen et al., 2010) dataset, and Merged Land–Ocean Surface Temperature Analysis (MLOST; Vose et al., 2012) dataset, global surface temperature anomalies increased by about 0.89°C for the period 1901–2012 (Intergovernmental Panel on Climate Change Fifth Assessment Report, abbreviated as IPCC AR5) (IPCC, 2013).However, it is pointed out that observation records differing in data source, time period, and data processing will lead to different trends (Xu and Powell, 2010). There exhibit some spatial differences in surface temperature trends among the three datasets (Figure TS.2 in IPCC AR5) (IPCC, 2013), although a significant global warming pattern can be basically captured by all of them. The IPCC AR5 pointed out that the signals are reliable over those grid boxes with greater than 70% complete records(IPCC, 2013). We should be cautious about trend estima-tions derived from various gridded datasets for both global and regional issues.
For land surface temperature, many previous studies have suggested that there are several uncertainties in current instrumental records, including station error (Brohan et al., 2006; Williams et al., 2012; Wang, 2014), coverage error (Hansen et al., 2010; Saffioti et al., 2015),and bias error (Hausfather et al., 2013; Ren et al., 2014,2017). Each of them can cause uncertainties on land surface temperature estimation. For example, some studies suggested that global warming hiatus is mainly related to coverage bias of instrumental records (Cowtan and Way,2014; Karl et al., 2015). They proposed that the global trend is supposed to be higher than that reported in IPCC AR5, and it is the coverage bias that leads to the “slowdown” in the increase of global surface temperature. It is also argued that missing observations in the Arctic region lead to a considerable underestimation of the effect of polar amplification on temperature trends (Saffioti et al., 2015).
It is known that the distribution of land stations is uneven in space, and changes with time (McKitrick, 2010;Jones and Moberg, 2003, Jones et al., 2012; Morice et al., 2012). According to Morice et al. (2012), the impact of coverage bias is enhanced by the decreasing number of available observations since the early 1990s, due to the change of station availability in the source data. This probably affects short-term temperature trends, especially on regional scales (Saffioti et al., 2015). Therefore,non-uniform features of records in space and time may have some impact on trend estimation. All the problems discussed here are to call into a question as to how the inhomogeneity in space and time affects land surface temperature trend estimation in precision.
2. Data and method
There are three principal groups that operationally derive global surface temperature from piecemeal historical records: CRU–Hadley record (HadCRU), NASA record (GISS), and NOAA record (MLOST), which are also used in AR5 (IPCC, 2013). In terms of land surface air temperature data, HadCRU is compiled by the Climatic Research Unit (CRU) of the University of East Anglia, while both GISS and MLOST depend on the same land data archives—the Global Historical Climatology Network (GHCN; Vose et al., 1992). As an official archived dataset of more than 30 sources, GHCN contains historical temperature, precipitation, and pressure data for thousands of land stations worldwide. It has often been used as a foundation for reconstructing past global temperature. GHCN publishes its raw data as they come in, and the latest version is GHCN V3 (Lawrimore et al., 2011). GHCN also provides a homogeneity-adjusted version (GHCN-adj). Combined with GHCN V3 and the Scientific Committee on Antarctic Research (SCAR;Turner et al., 2004) data, the current analysis of GISS uses satellite observed nightlights to identify measurement stations located in extreme darkness and then adjusts temperature trends of urban and peri-urban stations(Hansen et al., 2010). From 1978 onward, CRU began the production of gridded land air temperature anomalies based on instrumental temperature records held by various national meteorological organizations (NMOs)around the world. Apart from NMO source materials,there are three additional sources that incorporate station data across the world’s land areas in the latest CRUTEM4: the World Meteorological Organization(WMO) official international climate monitoring (CLIMAT) network, the Monthly Climatic Data for the World(MCDW), and the decadal World Weather Records(WWR) volumes (Jones et al., 2012). A significant majority of sites from GHCN are also involved in the CRU product. CRU has abundant typical stations and more continuous time series, thus it is chosen for our study and the reliable instrumental records of CRU are discussed in this study.
CRU Temperature version 4 (CRUTEM4) monthly station and gridded temperature datasets from 1900 to 2012 are obtained for this study. The missing data at each land station (grid box) are depicted by the ratio of missing months to all the months during our study period, and the lower the missing percent is, the more reliable the time series is. Note that missing data also exist in the gridded dataset. On the other hand, mean absolute error(MAE) is used to measure the discrepancy between the two time series, which is defined as
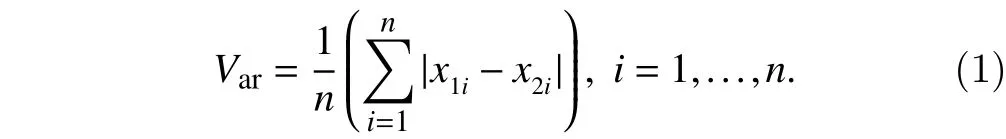
Here, x1is grid box value and x2is station value in Fig. 4,while x1is grid box value within (exceeding) 40% missing rate and x2is referenced grid box value in Figs. 6 and 9. The subscript i refers to year.
3. Spatiotemporal non-uniform features in CRU land temperature records

Fig. 1. Distributions of missing data (in percent) at each land station during (a) 1900–2012, (b) 1900–50, and (c) 1951–2012.
Figure 1 presents the spatial and temporal features of instrumental records for the latest CRUTEM4. Strong non-uniform spatial and temporal distributions are detected for station records during 1900–2012 (Fig. 1). The majority sites are concentrated in developed countries and regions such as the United States and Europe, while relatively few sites are located in the developing countries/regions such as Africa, South America, the Tibet Plateau of Asia, the Arctic, and Antarctic. For the distribution of missing data, the low missing percent areas include the United States, Europe, India, Japan, and Southeast Australia, while South America and Africa have relatively high missing percent.

Fig. 2. Temporal distribution of available global stations during 1900–2012. Both solid black curve and red pluses indicate the number of stations in each year. The visible black curve helps to reveal sudden change from one year to the next. Dashed black lines indicate average values of station numbers during 1900–50 and 1951–2012.
Temporal distribution of available global stations during 1900–2012 is generally displayed in Fig. 2. The number of available global stations is only about 2200 at the beginning of 1900, then gradually increases with time and dramatically increases around 1950 and 1960. In detail, the number of available stations in 1951 is 559 more than that in 1950, while it is 375 more in 1961 than in 1960, indicating a significant increase around 1950 for the period 1900–2012. Figure 2 also shows that the number of stations has declined after the peak in the 1960s,with a series of stepped reductions occurring at the end of each decade. However, the average number of available sites during 1951–2012 is much more (about 5590)than that before 1950 (3051), manifesting a significant non-uniform feature in temporal distribution. As a major source of CRUTEM4, the WWR volumes are onward up from the 1950s to the 1990s and they are released every 10 yr at the end of each decade (Jones et al., 2012).Moreover, the station number reduction at the end of each decade is related to the change in station availability in the WWR volumes according to Jones et al. (2012).
To examine the differences of missing data distribution between 1900–50 and 1951–2012, missing percent is calculated for each period (Figs. 1b, c). During 1900–50,majority regions around the world show large missing percent, more than 90% in South America, Africa, and East Asia (except for Japan). In contrast, missing data are much less in the United States, parts of Europe and India,Japan, and Southeast Australia. After 1950, observations are significantly improved around the world, especially in East Asia and Russia. The observations in the United States remain excellent. However, the quality of instrumental records in Africa and South America is still unsatisfactory, and the spatial and temporal non-uniformity remain existent in the distribution of station records.
In this study, the Climate anomaly method (CAM;Jones, 1994) is used to interpolate station records to regular grids of CRU, which requires changing all the station temperature data to anomalies, from a common period such as 1961–90 on a monthly basis. Grid-box anomaly values are then produced by simple un-weighted averaging of individual station anomaly values within each 5° × 5° grid box for all months (Jones and Moberg,2003, Jones et al., 2012). The station number/density within each 5° × 5° grid box is distinguished by different colors, from dark blue to orange, to indicate the increasing number of stations (Fig. 3). From Fig. 3a, it is clear that boxes on land are almost covered with dark blue before 1950, except for the United States, West Europe,and Southeast Australia. The densest box of 94 sites is located in West Europe with orange color, while there are some blank boxes with no records concentrated in South America, Africa, and South Asia. A majority of the 5° × 5° grid boxes covered with dark blue color have fewer than 10 or even 5 sites within. As a result, data from these areas are possibly accompanied by huge sampling errors, and the associated trend estimation may be doubtful. As Hofstra et al. (2010) noted, when station numbers within the grid box were not sufficiently large in estimating the average, the variance of the area average was likely to be larger than the true variance, and the estimate would not be a ‘‘true’’ areal average. When considering the ideal condition for the density distribution of sites, that is, including all of the stations in the calculation (Fig. 3b), most parts of the world are still covered by blue. Although the density has been improved greatly, especially in Africa, South America,Europe, East Asia, and Southwest coast of South America, the overall station density distribution is unsatisfactory. In general, land instrumental records are featured with non-uniform station density. Possible influences of the station density on the gridded data and thus trend estimation are not discussed here. The non-uniform distribution of the gridded datasets after interpolation based on stationed values, may also induce uncertainties in trend estimation, especially for the period 1900–50, which will be discussed next.
4. Impact of data spatiotemporal nonuniformity on global temperature trend estimation

Fig. 3. Density (number of stations per grid box) distributions of (a) available global stations before 1950 and (b) all stations during 1900–2012 in each 5° × 5° grid.

Fig. 4. Global temperature changes (Tanom; °C) and associated trends (trend; °C decade–1) and differences (Var; °C) during 1900–2012, calculated by the station (red) and gridded (blue) data, respectively. The straight lines are linear regression results. The vertical dashed line marks the year 1950.
Figure 4 displays annual latitude-weighted averaged global temperature changes and associated trend estimations derived from CRU station and gridded datasets during 1900–2012. Anomalies of station data is calculated based on 1961–90 normal provided by CRU. Although station records are spatially non-uniform and associated result may be regional averaged estimation, station records show generally similar variability to gridded dataset for the global average. In comparison, the variability of station records is much larger compared with gridded records, especially in the period of 1900–50 (Fig. 4).After 1950, differences between these two datasets are significantly reduced, mainly due to increased stations(from 3051 to 5590). It is also confirmed by MAE between station and gridded datasets, which is 0.156°C during 1900–50 and decreases to 0.091°C after 1950.Similar tendencies exist in both types of datasets for global land surface temperature, which are 0.088°C dec-ade–1(0.089°C decade–1) derived from station (gridded)dataset before 1950, and 0.180°C decade–1(0.185°C decade–1) from station (gridded) dataset after 1950. It seems that station records can reflect the signal of global average surface temperature to some extent, especially when station density has been greatly improved. However, considering the necessity of weight adjustment in trend estimation, we will only discuss gridded records in the following text.
Missing data may result in trends estimated from a different period instead of the study period. Without considering the impact of missing data, our routine calculation may be doubtful for containing noises from kinds of time period. Therefore, it is necessary to test how different percentages of missing data influence the trend calculation. Next, the sensitivity of global land surface temperature trend during 1900–2012 to missing data is examined. Note that the results are confined within our study period. The red curves in Fig. 5 are the estimated trends varying with accumulated missing data. For example, the trend estimated with 20% missing percent data is the trend calculated from all the grid boxes with 20% missing records or less. The black curves represent the amount of grid boxes used in the calculation. For the gridded data (Fig. 5a), the trends are decreasing with increasing missing data when missing percent is within 25% and then fluctuates until reaching around 40%.What is worth mentioning is that almost no change is found when the missing percent exceeds 60%. It is related to the signals from the boxes with poor records being concealed by those with good records since the increased grid numbers can be ignored.
Individual missing percent and corresponding trends are shown in Fig. 5b. As an example, a trend bar between 10% and 20% missing percent means that this trend is derived from sites with missing data between 10% and 20%. Correspondingly, the bar below the solid horizontal line with slanted lines indicates the amount of grid boxes used. From Fig. 5b, it seems that most of available grid boxes are concentrated in missing percent within 10%and no box reveals missing percent beyond 90% as a result of interpolation. Note that estimated trends display a certain uncertainty for different missing data, especially for the missing percent of 30%–60%.

Fig. 5. Temperature trends (°C decade–1) during 1900–2012 based on gridded datasets with different percentages of missing data. (a) Accumulated trend (red curve, left ordinate) and number of involved grid boxes (black curve, right ordinate); (b) individual trends (color-filled bars, left ordinate) and corresponding numbers of grid boxes (color-lined bars, right ordinate).
Considering the impact of missing data, the reliable trends in IPCC AR5 are estimated from the gridded boxes that have greater than 70% complete records.However, according to our test result, trends exceeding 30% missing percent are still under fluctuation (Fig. 5a).It seems that 40% missing percent is more reasonable for our discussion. Regarding 40% as an appropriate standard, the global land temperature during 1900–2012 with missing percent within 40% and exceeding 40% are calculated to detect their difference. As a reference, the global temperature series are provided here with all the data (including missing percent within and exceeding 40%). The MAE between data within 40% missing percent and the whole dataset is expressed as “MP 40% Var”and the MAE between exceeding 40% and the global data is expressed as “excluding MP 40% Var.” For the gridded records (Fig. 6), all the three time series are almost the same except for the one exceeding 40%. Compared with the records within 40% missing percent, the exceeding 40% part is obviously different from the global time series before 1950. The ratio between “excluding MP 40% Var” and “MP 40% Var” is nearly 26, and the trend of data within 40% missing percent (0.087°C decade–1) is much closer to the global trend (0.091°C decade–1). It seems that the signal of global land temperature can be described using the data within 40% missing percent. With data improved after 1950, the differences are reduced. The ratio between “excluding MP 40% Var”and “MP 40% Var” is reduced to 5.8, and both trends are closer to the reference series.
The above analyses suggest that the variability and trend of land surface temperature with missing observations within 40% largely reflect the global average signal. The signal of global temperature change mainly comes from areas with good data coverage, concealing signals from regions with poor data coverage. This phenomenon is remarkable in the gridded dataset before 1950. It may be because interpolation has exaggerated the distinction between good and poor data covered areas through weighted adjustment.
5. An extreme test of impact of data spatiotemporal non-uniformity on temperature trend estimation
To explore the impact of non-uniform observation in space and time on local temperature trend estimation, the United States with good data coverage and Africa with poor data coverage are compared and taken as an extreme example. Figure 7 shows the temporal distributions of available stations for the two regions from 1900 to 2012. It is obvious that the United States has good data coverage, with 1400 stations on average. The changes of these sites are slight and only about 100 stations have been added since 1940. In contrast, there are only 200 sites in Africa on average. Consistent with the global records, the stations in Africa dramatically increase around 1950, showing an obvious uneven temporal distribution in the observation.
A sensitivity test for the influence of missing records on regional trend estimation is conducted for the United States and Africa. Trends (for the period 1900–2012)varying with accumulated missing data are shown in Fig. 8. Attributed to good observation network in the United States, its estimated trend is hardly affected by missing data percent, which is featured almost by a straight line, except for the tiny increase around 10%missing percent. Over Africa, when missing percent is below 20%, the trends computed from the gridded dataset decrease with the missing data, and then increase and fluctuate until reaching 60% missing percent. Similar to global signal, compared with trends exceeding 30%missing percent, trends exceeding 40% missing percent seem to be more stable. It seems that the trend of poor data covered areas tends to be more sensitive to missing data than that of the good data covered areas.

Fig. 6. Temperature changes (Tanom; °C) and associated trends (trend; °C decade–1) and differences (Var; °C) during 1900–2012 estimated using all grid boxes (blue), grid boxes with only good data coverage [defined by missing percent (MP) of 40% at most; red], and grid boxes with poor data coverage (excluding the data used in drawing the red curve; orange). The vertical dashed line marks the year 1950.

Fig. 7. Temporal distributions of available stations in America (red)and Africa (blue) during 1900–2012. Grey filling indicates negative anomalies.

Fig. 8. Temperature trends (°C decade–1) during 1900–2012 calculated from the gridded dataset in the US (red) and Africa (blue) against different percentages of missing data.
We have mentioned in Section 4 that the signal of global temperature change mainly comes from areas with good data coverage. Further, we would like to take the United States and Africa as extreme examples to illustrate how the estimated trend (during 1900–2012)changes if only the countries with good and poor data coverages are involved in the gridded datasets. Records of the United States and Africa are put together as a complete dataset. Reliable trend estimated from this record within 40% missing percent is shown as reference and compared with these two regional trends, respectively(Fig. 9). For simplicity, associated differences are called“Am Var” (MAE between US temperature time series and reference time series) and “Af Var” (MAE between Africa temperature time series and reference time series). For the period 1900–1950, “Am Var” (0.145°C) is smaller than “Af Var” (0.154°C) by nearly 5.8%, indicating a smaller difference between the US and the combined dataset. Similar features are also captured by comparison of trends. Theoretically, the integrated time series should be dominated by Africa signals for its bigger land coverage in gridded data calculation; however, its reliable signal seems mainly coming from the United States for its better data coverage. Note the reference time series tends to be close to Africa signals until observations are improved after 1950. Thus, the overall pattern of temperature change and related trends tends to be dominated by the area with good coverage of observation, such as the United States. This is in accordance with Fig. 6 on the global issue.
6. Conclusions and discussion
CRUTEM4 monthly land surface temperature datasets from 1900 to 2012 are used in this study to examine the influence of spatial and temporal non-uniformity on land temperature trend estimation. The main conclusions are as follows.
(1) Instrumental observed land surface temperature records exhibit a large non-uniformity in space and time.Spatial non-uniformity is featured with uneven distributions of missing records and station density. Low-missing percent areas include the United States, West Europe and so on, while South America and Africa have high missing percent. For the station density, majority sites are mainly concentrated in developed countries, and relatively few sites are located in the developing countries.In terms of temporal non-uniformity, it is clear that there is a significant increase of available sites that happened around 1950.

Fig. 9. Temperature changes (Tanom; °C) and associated trends (trend; °C decade–1) and differences (Var; °C) in the US (Am, red), Africa (Af,blue), and both the US and Africa (Am + Af, black) based on gridded datasets. The vertical dashed line marks the year 1950.
(2) Considering the impact of missing data, the reliable trends are estimated based on data within 40% missing percent. However, due to the spatial non-uniformity of instrumental record, the reliable signal of global averaged land temperature seems mainly coming from some regions with good coverage in spatial distribution, especially for the period 1900–50.
(3) It is shown that the trend of land surface temperature in the poor data covered area tends to be more sensitive to non-uniformity in records than that in the good data covered area. Further, records of the United States and Africa are put together as a complete dataset to conduct an extreme test. The results also confirm that the temperature change and related trends tend to be dominated by the area with good coverage of observations.

Fig. 10. (a) Global temperature trends (°C decade–1) based on the station (red) and gridded (blue) data; (b) “MP 40% Var” (orange) and “excluding MP 40% Var” (green) during different periods.
Since 1900, global temperature changes exhibit distinct multi-decadal fluctuations (Fig. 4), characterized by global warming slowdowns in the mid-twentieth century(around 1940–75) and early 21st century (around 2000–12) and accelerations in the early and late twentieth century (around 1910–40 and 1975–2000) (e.g., England et al., 2014; Meehl et al., 2016). Here, we compare the global temperature trends based on the station and gridded data, as well as the “MP 40% Var” and “excluding MP 40% Var” during these different periods in Fig. 10.The signals estimated from station data are slightly exaggerated during the accelerations compared with the gridded data, and almost the same during the slowdowns(Fig. 10a). For the gridded data, the “MP 40% Var” are much smaller than the “excluding MP 40% Var.” The latter tends to decrease with time due to the increasing observations (Fig. 10b). We need to mention that this study only discusses some uncertainty in the land surface temperature trend estimation for the gridded datasets. There are many unresolved issues regarding station instrumental records processing and associated temperature trend estimation, such as better interpolation method and impact of different data biases on trend estimation.
杂志排行

Journal of Meteorological Research的其它文章
- A Review of Climate Change Attribution Studies
- Sensitivity Study of Anthropogenic Aerosol Indirect Forcing through Cirrus Clouds with CAM5 Using Three Ice Nucleation Parameterizations
- Estimation of the Aerosol Radiative Effect over the Tibetan Plateau Based on the Latest CALIPSO Product
- Influences of the Internal Mixing of Anthropogenic Aerosols on Global Aridity Change
- The Observation of Ice-Nucleating Particles Active at Temperatures above –15°C and Its Implication on Ice Formation in Clouds
- Analysis of Paths and Sources of Moisture for the South China Rainfall during the Presummer Rainy Season of 1979–2014