一种具有迁移学习能力的RBF-NN算法及其应用
2018-11-05许敏史荧中葛洪伟黄能耿
许敏,史荧中,葛洪伟,黄能耿
(1. 江南大学 物联网技术学院,江苏 无锡 214122; 2. 无锡职业技术学院 物联网技术学院,江苏 无锡 214121)
1985年,Powell提出多变量插值的径向基函数(radical basic function, RBF)方法。1988年,Moody和Darken[1]提出了一种神经网络结构,即RBF神经网络。该网络能够以任意精度逼近任意连续函数,非线性拟合能力强,具有很强的鲁棒性,因此应用广泛,如海洋表面温度预测[2]、网络安全态势预测[3]、智能轮椅自适应控制[4]、失业率预测[5]、电力系统的可用输电能力在线估计[6]、在线恶意垃圾邮件检测[7]等。随着应用范围的推广,研究者们发现RBF神经网络仍存在一些不足,制约其进一步的发展和应用,故许多专家学者提出了一些改进算法,如有学者提出对神经网络的结构进行优化,相关学习算法主要有两大类:1)先构造复杂的网络结构,再通过训练精简网络结构,如韩敏等[8]提出了一种改进的RAN算法,该方法采用样本的输入输出信息对网络进行初始化,再根据FPE剪枝策略对网络结构进行简化;2)先采用精简的网络结构,再通过训练增大网络规模,直至达到泛化要求,如Platt等[9]提出了一种资源分配网络,该方法首先创建一个精简网络,当网络出现异常模式时,通过分配新单元和修改已有单元参数来进行学习,直至网络稳定。基于聚类的RBF神经网络隐含层数据中心一般通过K-means聚类算法获得,故有学者提出对该聚类方法进行优化以提高算法泛化性能[10-12]。此外,还有一些学者研究各种基于进化算法的RBF神经网络[13-15]。如Lacerda等[13]提出使用遗传算法优化学习参数;Shekhar等[14]提出使用模拟退火算法确定神经网络的连接权值;Alexandridis等[15]提出使用粒子群算法和模糊均值法确定隐含层的中心,改进网络的结构等。
从上述文献综述可以发现,以往的研究主要围绕RBF神经网络的网络结构和参数设计展开,所解决问题的场景是采集到的数据能反映数据集的分布情况,但在实际应用中,信息采集器或传感器设备可能会出现故障,导致采集到的数据不完整。训练样本不完整,或多或少都会影响RBF神经网络的学习效率,使网络的推广能力变差。训练样本反映数据集总体分布的程度对算法的泛化性能有着重要的影响。到目前为止,样本数量和质量对RBF神经网络算法泛化性能影响方面的研究还不多。针对上述问题,本文将迁移学习思想引入RBF神经网络,提出已标签样本少时的RBF神经网络学习算法。所谓迁移学习,就是学习已有的源领域知识来解决目标领域中已标签样本数量较少甚至没有的学习问题[16-17]。该思想已广泛应用于分类、回归、概率密度估计等各类机器学习领域。本文在文献[18]提出的RBF算法的基础上,提出了具有迁移学习能力的RBF神经网络 (ε-RBF with transfer learning ability,TLRBF)算法,通过引入不敏感损失函数和学习源领域径向基函数的中心向量及核宽和源领域模型参数,帮助目标领域建立模型。
1 RBF神经网络
RBF神经网络由输入层、隐含层和输出层组成,由图1所示。其中,,,隐含层节点数为M,RBF神经网络完成的非线性映射。

图1 RBF神经网络模型Fig. 1 The model of RBF neural network
在RBF神经网络中,输入层接收训练样本;隐含层节点通过径向基函数执行一种非线性变化,将输入空间映射到一个新的空间,若该径向基函数定义为高斯函数,设表示高斯函数的中心,表示高斯函数的核宽,该函数可表示为
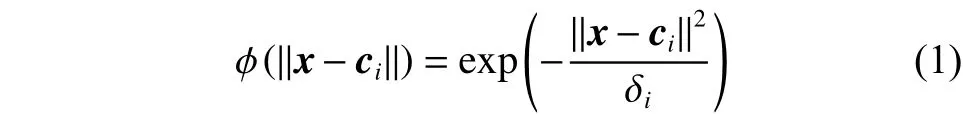

2 RBF神经网络与线性模型
由第1节介绍可知,RBF神经网络的参数有3个,径向基函数的中心向量,核宽和隐含层与输出层的连接权值。其中,、可利用模糊C均值(FCM)聚类技术确定,参数利用梯度下降学习算法获得。设表示FCM聚类算法得到的样本对于第i类的模糊隶属度,是可调缩放参数,n表示训练样本规模,M表示隐含层节点数,径向基函数的中心和核宽可由式(3)表示:
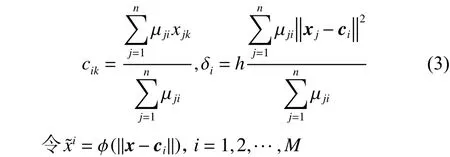


由式(5)可知,当径向基函数隐含层被估计后,网络的输出可转换成一个线性模型。
3 具有迁移学习能力的RBF神经网络
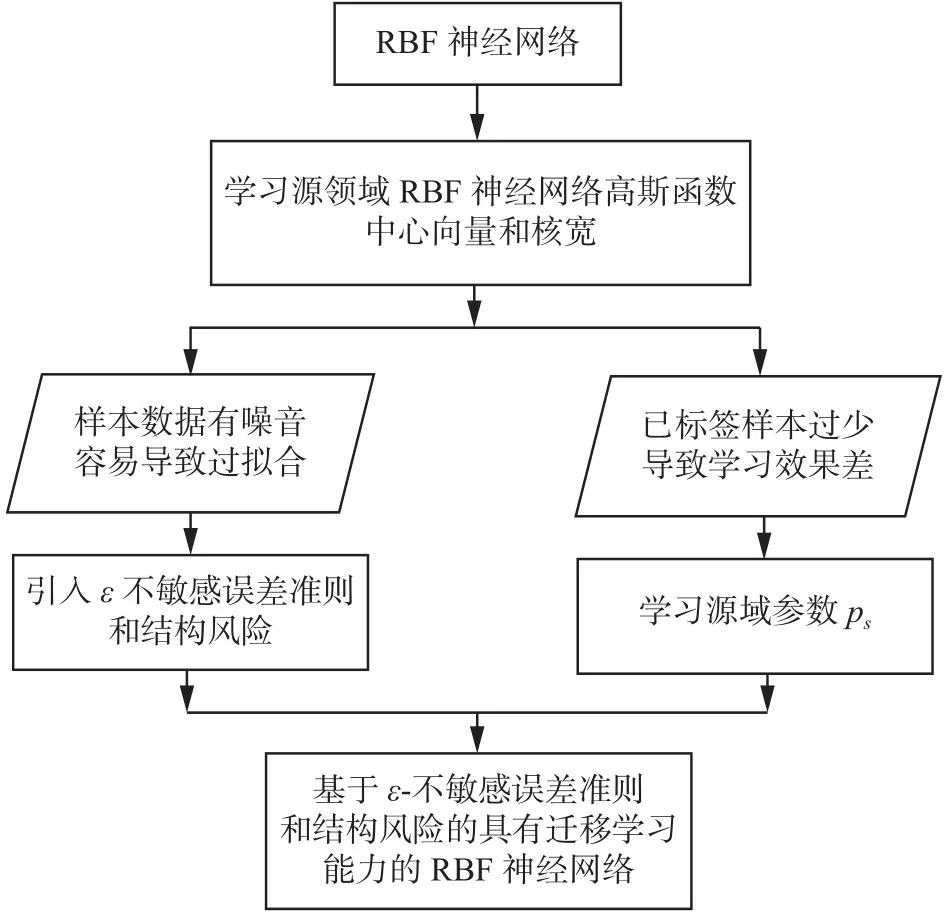
图2 TLRBF算法思路Fig. 2 The idea of theTLRBF algorithm
下面具体介绍算法的实现。





接着,加入结构化风险项。支持向量机是结构风险最小化原则的一种实现,学习支持向量机的实现方法,引入正则化项,使算法结构风险最小,故式(9)加入结构化风险项后可用式(10)表示:

最后,为了使本文提出算法具有迁移学习能力,在学习源领域径向基函数的中?心向量?和核宽后,加入学习源领域模型参数项,故最终,所求解的问题可表示为
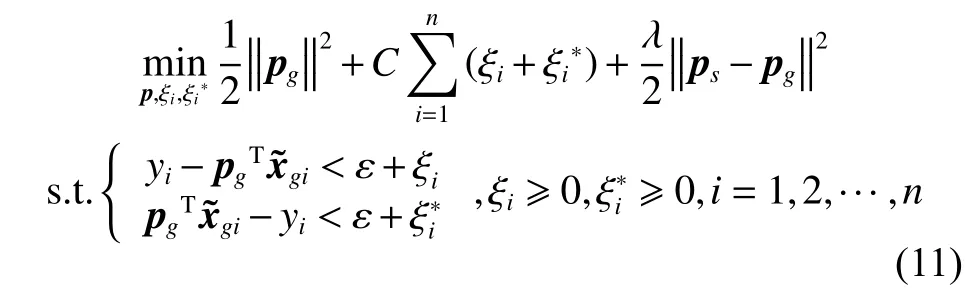
引入拉格朗日乘子,构造出式(11)的拉格朗日函数:

式(12)相应的对偶问题形式为
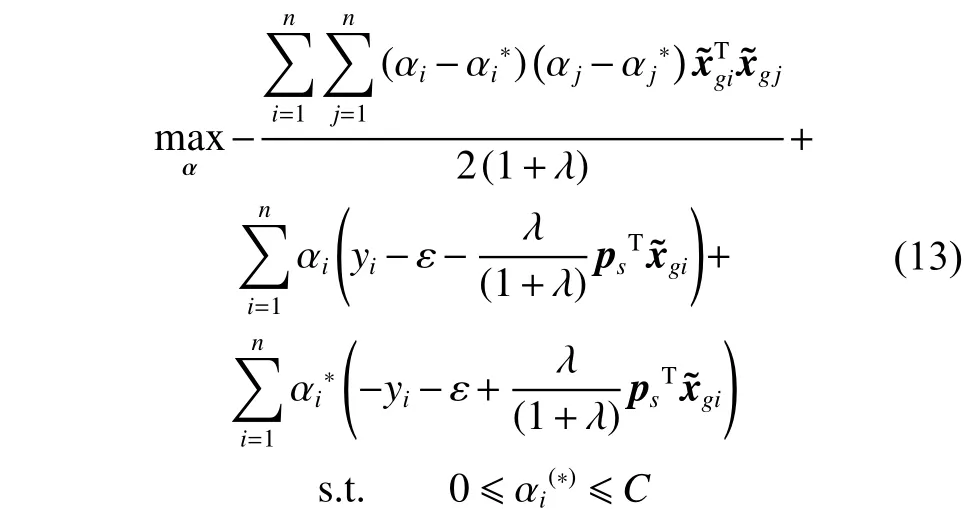
利用式(13)得到最优解:

1) 学习源领域径向基函数中心向量和核宽,确定hg值,带入式(6),得目标领域高斯函数中心向量 cgi和核宽 δgi;
2) 将目标领域高斯核中心向量cgi和核宽δgi带入式(1)得;
3) 求解式(13)对应的二次规划问题;
4) 利用式(13)求得的二次规划最优解,根据式(14)求得隐含层和输出层之间的权值;
上述算法参数设置除高斯函数核宽中的可调参数hg外,还有式(13)需设置的3个参数,分别是、、,确定参数的方法是网格搜索策略,5重交叉验证获得。
4 实验研究
4.1 实验设置
本节利用模拟数据集和在谷氨酸发酵过程中采集的真实数据集对本文所提算法进行实验验证。在4.2节和4.3节分别描述模拟数据集和真实数据集的构成及实验结果分析。为了突显本文所提算法的优势,两组实验在3个场景下进行,场景1为目标域数据集RBF神经网络算法训练;场景2为源领域历史数据集和目标领域当前数据集RBF神经网络算法合并训练;场景3为加入源领域历史知识的目标领域数据集迁移学习训练。
为了有效评估算法的性能,采用如下性能指标[18]:

式中:N表示测试样本规模,yi表示第i个样本的采样输出,表示第i个样本的径向基神经网络输出。
4.2 模拟数据集实验
在已标签数据较少而导致RBF神经网络预测精度降低的前提下,验证本文所提算法可通过学习相关历史领域知识提高预测精度。所设计的模拟数据集符合以下两个原则:1)当前数据集和历史数据集既存在相关性,又有自己的数据分布特点;2)当前目标域数据集已标签样本较少,无法反映出数据集的整体分布情况。
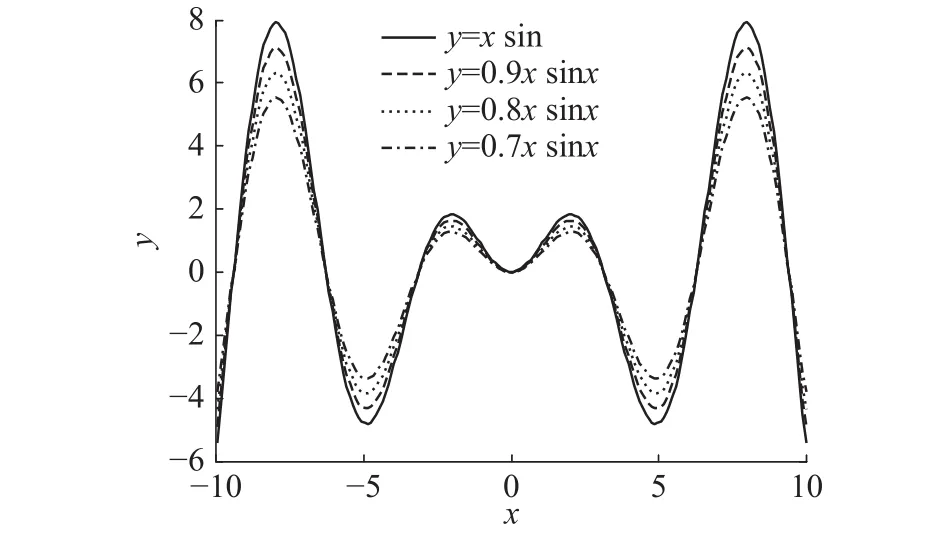
图3 目标域场景函数和源域场景函数Fig. 3 Target domain functions and source domain functions

表 1 各种算法在模拟数据集上的泛化性能比较Table 1 Comparison of generalization performance of various algorithms on artificial data sets
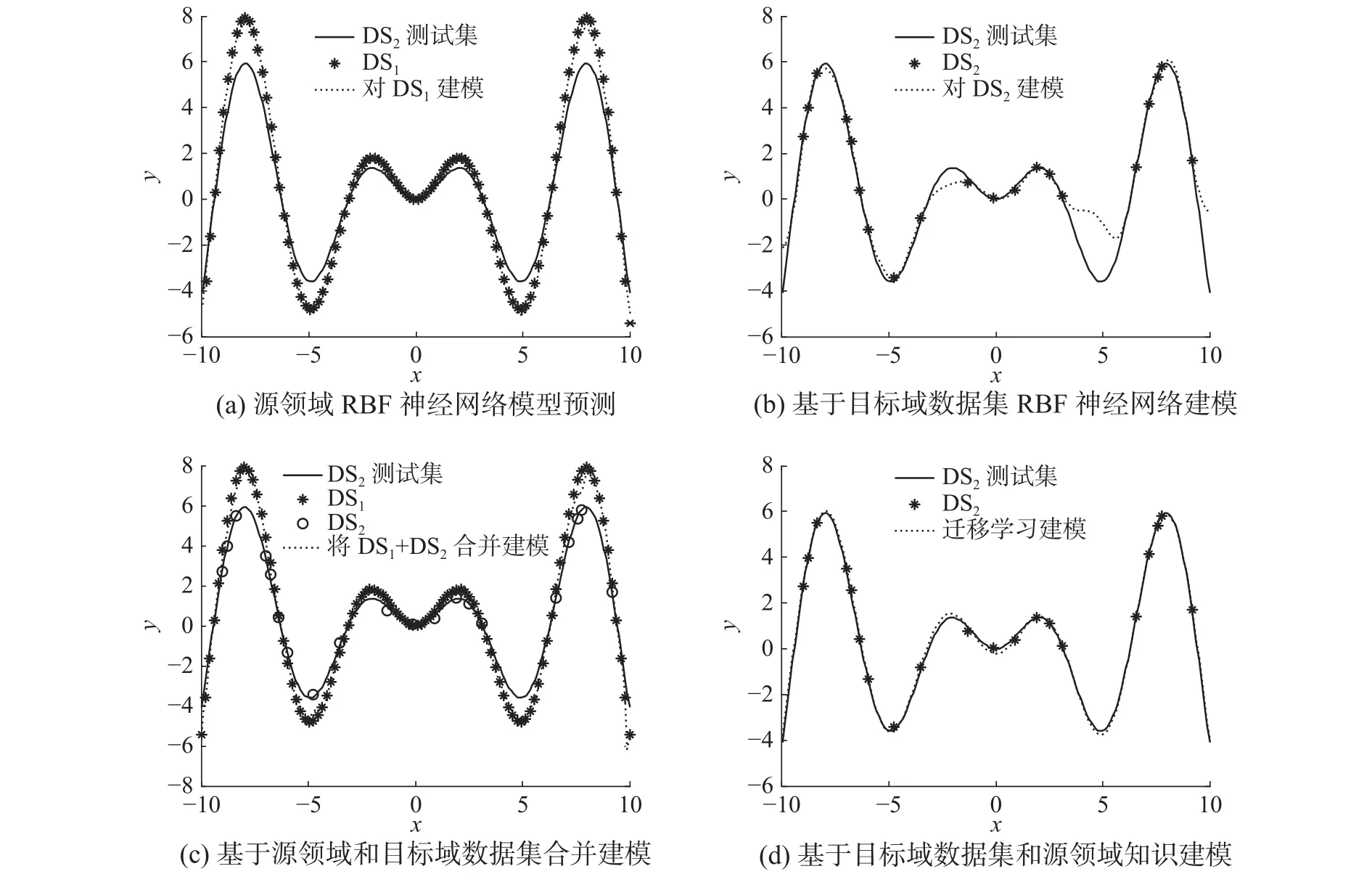
图4 相关系数为0.75时,各算法性能Fig. 4 The performance of each algorithm on r is 0.75
由表1和图4可以得出如下结论:
1) 观察表1和图1(a)可知,若直接使用源域模型对目标领域测试集进行预测,目标领域和源领域差异由r为0.9时的0.106 1增大到r为0.65时的0.521 9。随着r系数的减小,源领域与目标域数据分布差异增大,误差增幅明显。
2) 目标域数据集规模较小,存在某些数据段缺失的现象,不能反映目标域数据集的整体分布,如图4(b)所示。传统RBF神经网络算法可以对当前采样数据集逼近,但无法对缺失的地方进行弥补,导致仅用目标域数据集进行训练泛化性能不高,如表1和图4(b)所示。
3) 将源领域数据集和目标域数据集合并训练,算法性能较仅用源领域进行训练并没有明显提高,如表1和图4(c)所示。其原因是源领域数据集对目标领域数据集来说,规模很小,其对于建模的影响作为可容忍噪声忽略了。此外,一些高度机密的源领域历史数据集很难获取,合并训练并不一定能实现。
4) 从表1和图4(d)可知,基于历史知识的迁移学习算法具有较好的性能。和仅用目标领域数据集训练相比,缺失的部分通过历史知识的学习加以弥补,提高了泛化性能;和源领域及目标领域数据集合并训练相比,不仅提高了精度,且因为学习的是知识,而不是所有历史数据集参与训练,历史场景数据还具有保密性。
由此,可以得出结论,本文所提算法解决了RBF-NN算法不具有迁移学习能力的问题。
4.3 真实数据集实验
本部分实验数据来自工厂采集到的真实发酵数据集[19]。该数据集记录了食品发酵过程中记录下的21批数据,每批数据有14条记录,共有294条记录。该数据集记录了发酵过程的采样时间(h),葡萄糖浓度(Glucose concentration),菌体浓度(Thalli concentration)和谷氨酸浓度(Glutamic acid concentration)。其输出为下一时刻的葡萄糖浓度(h+1)、菌体浓度(h+1)和谷氨酸浓度(h+1)。将前1~16批数据共224条记录作为源领域数据集;剩余的5批数据中,17~19批数据42条记录中,任意选取20条记录作为目标域数据集,数据集已标签样本较少,不能反映数据集的整体分布情况;20~21批数据作为目标域测试数据集。
观察图5和表2,可以得出如下结论,因目标域训练集已标签数据较少,而RBF和-RBF算法没有迁移学习能力,故两算法泛化性能不理想,而学习了源领域知识的-TLRBF算法,弥补了数据量小和缺失数据的不足,泛化性能较好。
RBF神经网络算法基于最小平方误差准则,对小样本数据集或存在噪声的数据集容易过拟合而导致泛化性能下降。-RBF引入不敏感准则和结构风险,对小样本数据集显示出了更鲁棒的性能,但对采样样本不能反映数据集整体分布的数据集泛化性能仍不理想。-TLRBF不仅引入不敏感准则和结构风险项,还学习了源领域知识,能弥补缺失数据的不足,泛化性能较RBF和-RBF有很明显的改善。


图5 各种算法泛化性能比较Fig. 5 Comparison of generalization performance of various algorithms

表 2 各种算法于真实发酵数据集上性能比较Table 2 Comparison of performance of various algorithms on real fermentation data sets
5 结束语
已有RBF神经算法及其改进算法大多未考虑采样样本不能反映数据集整体分布而导致算法泛化性能降低的情况。本文通过采用知识迁移的思想,提出能充分学习源领域知识的具有迁移学习能力的RBF神经网络学习算法。本文所提方法并不需要大量源领域样本参与目标领域模型的建立,仅是学习源领域的高斯核中心向量及核宽以及源领域模型参数帮助数据存在一定程度的信息缺失的目标领域建立模型,这是传统的RBF神经网络学习算法所不具备的。通过合成数据实验以及真实发酵过程的仿真实验,验证了本文方法较之于传统方法具有更好适应性。但本文方法采用网格搜索策略和交叉验证方法来获得各个参数的值,加大了获取各参数最优值的工作量,在今后的工作中,将致力于研究两个领域间的相关性与参数取值间的关系,以估计参数的合理区间,减少获得最优参数的工作量。
