基于排序学习的视频摘要
2018-11-05王鈃润聂秀山杨帆吕鹏尹义龙
王鈃润,聂秀山,杨帆,吕鹏,尹义龙
(1. 山东大学 计算机科学与技术学院,山东 济南 250101; 2. 山东财经大学 计算机科学与技术学院,山东 济南250014; 3. 山东大学 软件学院, 山东 济南 250101)
随着手机、摄像机等录像设备的普及,视频拍摄越来越简单方便。一项调查显示,在YouTube视频网站,每天视频的上传时长大约是14万小时[1],视频数据的爆炸式增长带来了一些不可避免的问题。对于用户来说,浏览14万小时的视频需要不间断地观看大约16年时间,同时,存储如此庞大的视频数据也给网站带来巨大的压力,除此之外,视频检索也要花费更多时间。由于视频数据快速增长带来的一系列问题,视频处理的相关技术也逐渐受到人们的重视。
为了解决由于庞大的视频数据造成的问题,人们提出了视频摘要技术。视频摘要是视频处理的一种技术,简单地说,它是从视频中选取几个视频段或者几张图片,被选出来的视频段或图片可以简要概括视频内容。在视频摘要之前,基本上需要花费与视频等长的时间来浏览视频,但是有了视频摘要后,人们只需要观看视频段或图片就可以清楚视频的内容,为浏览视频节省了大量时间。而且,因为视频段或图片基本上包含了视频的主要内容,只要存储视频段或图片即可,为网站视频存储节省了大量空间。同时,在搜索视频时,没必要花费大量的时间搜索整个视频,只需检索相应的视频段或图片。视频摘要技术可以解决视频数据迅猛增长产生的问题,极大地方便了人们的生活。
对于视频摘要的分类,有很多不同的标准。根据输出的摘要类型划分,可以分为动态视频摘要和静态视频摘要[2]。动态视频摘要是从视频中选取一些视频片段,把这些视频片段组织连贯起来,形成一段流畅的视频作为摘要。静态视频摘要是从视频中选取几帧重要的视频帧,将这些视频帧组织起来构成视频的摘要。这两种形式的视频摘要有各自的特点[3]。动态视频摘要是一小段视频,包含了音频信息和连续的动作信息,可以帮助用户更加生动地了解视频的主要内容。静态视频摘要是由图片组成的,以时间顺序呈现在用户面前,具有更高的浏览效率。当然,无论是动态视频摘要还是静态视频摘要,都能代表视频内容,都能达到在看过视频摘要后就可以清楚地知道视频内容的效果。
由于视频数据的增多,根据视频内容自动提取视频摘要已经是大势所趋。一般来说,视频摘要都由以下4个步骤组成:特征提取、视频镜头分割、视频内容重要性评价、视频摘要生成[2]。特征提取是视频处理最基础的一步,提取的视频帧特征有全局特征(例如颜色、纹理、运动信息)和局部特征(例如尺度不变特征变换SIFT)[4]。近来,也用到了一些高级语义特征和深度特征。视频镜头分割[2]就是把一长段视频分成几个小片段,满足同一片段内的视频内容尽可能相似,不同片段间的视频内容尽可能不同,通常是根据视频帧之间的相似度进行视频分段。视频内容重要性评价是指算法按照一些规则和依据,对视频内容的重要性进行评价,为后续提取视频摘要做准备。生成视频摘要是根据重要性评价结果,将其中比较重要的部分提取出来,作为整个视频的摘要,其输出形式可以是动态的短视频或者是静态的图片帧。本文的视频摘要形式是静态的视频帧。
视频摘要的方法有很多,聚类[5]是主要方法之一,聚类是把相似的视频帧聚成一簇,从每一簇里选取几帧组成视频摘要。之后出现了对视频摘要做约束的方法,例如摘要应该覆盖视频的内容,摘要的冗余性应该比较低等,针对这些约束各自构建了计算公式,然后从视频帧集合中选取一个分数最高的子集作为摘要。然而,这些方法有一些缺点,首先要对摘要做约束,这个是要先验知识的,理解角度不一样对摘要的约束也不同,对摘要的约束个数也不同,约束不同继而构造的计算公式也不一样。还有,摘要是从视频帧集合中选取根据约束公式计算的分数最高的子集。若一个视频有个 帧,视频帧集合则有种组合,计算复杂度是,每增加一帧计算量会呈指数式增长。针对以上问题,本文提出了一个基于排序学习[6](learning to rank)的视频摘要方法。
本文工作的主要贡献有以下两点:
1)本文视频摘要的方法不依赖于先验知识的约束。本文把视频摘要看成是对视频帧的排序,根据训练集训练排序算法,使得和视频相关的帧排在前面的位置。
2)相比之前的视频摘要方法,本文方法的计算量大大降低。本文是对视频帧打分,计算复杂度是,之前的大多数方法是对视频帧集合打分,计算复杂度是。
本文方法是基于排序学习算法来解决关键帧选取问题,把视频帧选取看成一个排序问题,与视频相关性大的帧被排在前面,这些帧被选为关键帧。本文方法依然是按照视频摘要的4个步骤进行,因为视频的连续性,首先对视频分段,然后提取视频帧的深度特征,之后用排序学习算法对视频中的帧排序,最后选取排在前面的帧组成视频摘要。
1 相关工作
大多数视频摘要的方法基于两个准则,一个是选取的关键帧能尽可能多地包含视频内容,另一个是被选取的关键帧之间尽可能不同。基于这两个准则,设计了不同的计算公式。Guan等[4]提出了基于关键点的关键帧选择(keypoint-based keyframe selection)算法,是一种无监督方法,文中给出覆盖率和冗余性两个公式,提取每个视频帧的SIFT局部特征,把提取到的所有帧的SIFT局部特征组成关键点池,每个视频帧与关键点池进行匹配,从关键点池中去掉已经匹配的关键点,能最多覆盖关键点池并且可以最小化摘要冗余性的帧被选为关键帧。Chakraborty等[6]设计了代表性和独特性两个公式,代表性是度量关键帧集合与视频的相似性,独特性是量化关键帧集合中帧之间的相似性,赋予代表性和独特性合适的权重来计算候选集合的得分,得分最高的集合被选为关键帧集合。Gong等[1]提出了seqDPP(sequential determinantal point process)模型,它是一个概率模型,是基于DPP模型做了改进。DPP模型可以确保选择的关键帧之间互不相同,但是却没有考虑到视频的时序性。例如,一个视频中开始部分包含了吃早餐的镜头,结束部分包含了吃晚餐的镜头。如果使用DPP模型它只会从早餐和晚餐里选一个镜头,但是因为吃早餐和吃晚餐是两件不同的事情,而且相隔时间比较长,所以这两个镜头应该都被选为关键帧。为了弥补这个缺陷,Gong等先把视频分割成几个小片段,在每个小片段里使用DPP算法,在当前片段里选取关键帧时要考虑到前一片段中已经选取的关键帧,避免当前片段选取的关键帧与前一片段选取的关键帧过于相似。Li等[5]提出了4个模型,分别是重要性、代表性、多样性和故事性,重要性是指选取的关键帧要包含重要的人和物,代表性是指选取的关键帧能代表视频内容,多样性是指选取的关键帧要尽可能不同,故事性是指选取的关键帧故事性比较强,用户能比较容易理解视频内容。相应地构建了4个公式并且学习得到关于4个模型的权重,最终用于计算关键帧集合的分数,分数最高的关键帧集合被选为视频摘要。Hu等[7]提出了用多个属性和图片质量来提取摘要,在文中提出了9个属性和一个计算图片质量的方法。Hu等认为摘要中的帧应该是清楚的、清晰的,而视频中的一些帧质量不是高的,有可能是失真的、模糊的,这些图片不应该被选择到摘要中,所以计算了每帧的质量作为这一帧可以被选为关键帧的权重。Sun等[8]提出了SASUM(semantic attribute assisted video SUMmarization)的视频摘要方法,学习了一个深度神经网络用来提取每一帧的语义特征,用得到的语义特征把图片聚成几组,选取每组的中心片段组成最终的视频摘要。
大多数的视频摘要方法都是根据个人经验构建模型,然后学习各个模型的权重,之后计算视频帧集合的分数,从中选取分数最高的视频帧集合作为视频摘要。对于这类方法,首先要构建模型,模型设计的好坏,模型的个数对摘要的结果有很大的影响。除此之外,还要计算所有视频帧集合的分数,一个仅有20个帧的视频就会产生一百多万种组合,计算复杂度是。
本文的视频摘要方法是对视频帧打分,使得自动产生的分数分布与人工标记的分数分布尽可能吻合。学习打分的过程是基于排序学习算法,该算法不仅考虑到帧与视频的关系,也考虑到帧与帧之间的关系。本文的方法直接利用人工标记的摘要训练学习器,不依赖先验知识的约束。而且,本文的方法是对视频帧打分,计算复杂度是,相比于对帧集合打分的方法,复杂度大大降低。
2 基于排序学习的视频摘要
2.1 排序学习
排序学习被广泛应用于文档检索,给予一个查询条件,排序学习算法会给出与查询条件相关的文档关于相关性的一个由高到低的排序,排在越前面的文档是越符合查询条件的文档。排序学习算法有基于点、基于文档对[9]、基于文档列表3种方法。视频摘要与基于文档列表排序的思想更切合,在视频摘要中借鉴的是基于文档列表的方法。
Listwise方法对文档的排序结果进行优化,使得预测的排序与ground truth的排序更接近。在训练阶段,把排序函数自动产生的分数与ground truth中的分数转换成概率,衡量两个概率分布的误差,误差越小说明自动排序结果和ground truth排序结果越接近。预测时直接用训练好的排序函数对文档打分,分数越高说明与查询条件越相关。
在Listwise方法里有两种概率模型,分别是Permutation Probability和 Top k Probability,概率模型把文档得分转换成概率,计算所有排列的概率组成概率列表。构建的概率模型应该满足与ground truth分布越接近的分布发生的概率越大。每种排列对应一个概率,所有可能的排列的概率之和为1。Permutation Probability考虑了所有文档的排列,Top k Probability仅考虑了k个文档的排列。本文采用的是Top k Probability,用公式表示为

2.2 排序学习视频摘要方法详述
视频摘要是把与视频相关的视频帧按照相关性排序并呈现给用户,不同的视频时长不一样。文档检索是根据文档与查询条件的相关性由高到低排序,把排序后的文档呈现给用户,不同的检索条件相关的文档数目不一样。文档检索是要学习文档的顺序,自动产生的相关性高的文档要尽可能与人工标注的一样,视频摘要是要学习视频帧的顺序,自动产生的与视频相关性高的帧要尽可能与人工标注的一样。在这里视频相当于查询条件,视频帧相当于文档。基于排序学习的文档检索的广泛应用,证明排序学习可以很好地学习到人工排序的过程,视频摘要和文档检索是如此相似,因此本文提出了基于排序学习的视频摘要,把视频摘要建模成视频帧与视频的相关性排序。主要分为以下5个步骤:
1)视频预处理:由于视频的连续性,不能直接对视频视频使用排序学习算法。如果直接使用排序学习算法会导致选出来的摘要中有太多相似的图片,这与摘要中的帧应尽可能不同相悖。所以,在排序学习算法之前需要对视频分段,在本文中是把视频2 s分为一段。
2)特征提取:本文用到的特征是视频帧的深度特征[10],是用预训练的VGG-19卷积神经网络提取的。VGG-19网络包含了16个卷积层和3个全连接层。每个视频帧用预训练的VGG-19卷积神经网络提取到4 096维特征,然后用PCA算法对4 096维特征降维,属于同一个视频的帧的特征平均后就是该视频的特征。
3)学习排序函数:在对视频每一帧打分之前,首先要根据训练样本学习排序函数,有了排序函数后再对视频中的每一帧打分。
在本文的符号表示中,上角标表示视频帧id,下角标表示视频id。视频集合,视频的视频帧列表,表示视频第个视频帧。每个视频帧列表都有一组相关性分数,表示视频帧与视频的相关程度的得分。
对于视频摘要来说,没必要使得预测的概率列表和ground truth的概率列表,相应位置对应的排列中所有视频帧的顺序相同,只要使得分数第一高的帧排在该排列的第一个位置,分数第2高的帧排在排列第2个位置,以此类推,即只要排列中的第1个帧相同即可,即排序学习算法Top k Probability中的k=1。还有,本文的排序函数中特征和权重是线性关系,是指数函数。
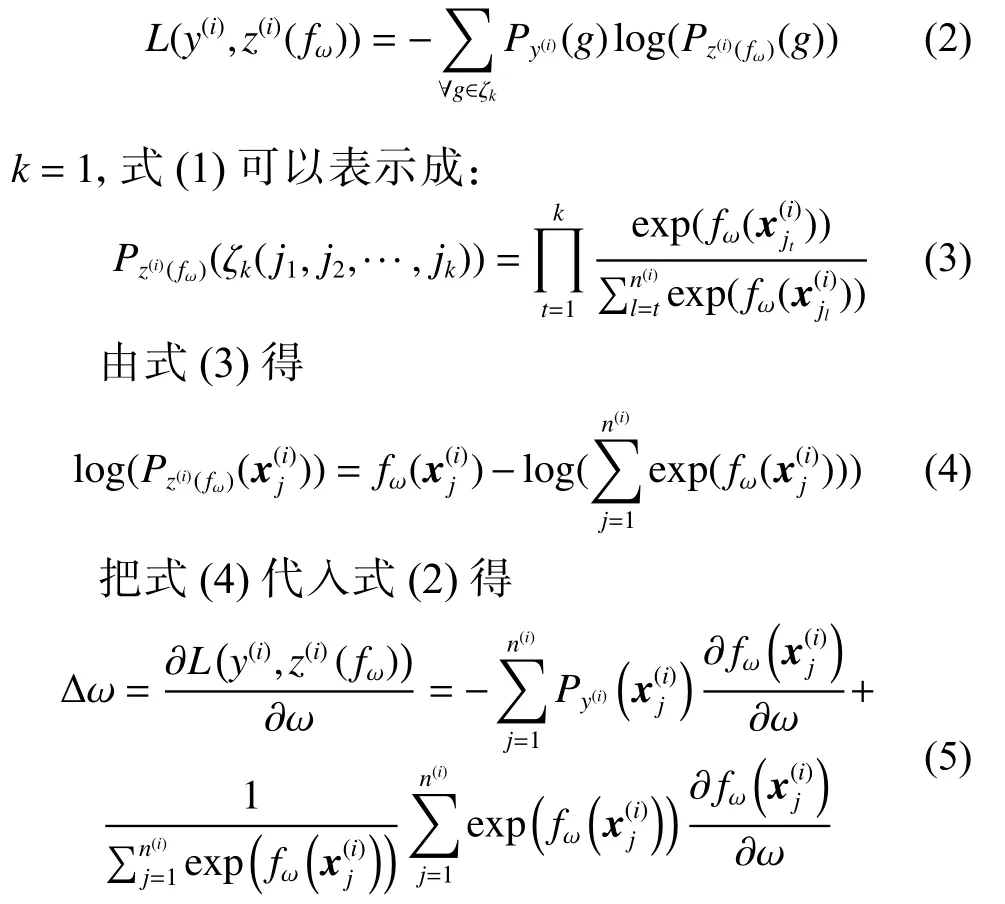
之后用梯度下降法求解。
4)打分:前面根据训练样本学习到的排序函数被认为是学到了人选取关键帧的一个过程,现在可以利用学习到的排序函数

对视频中的帧打分。
5)提取关键帧:本文生成摘要的方法是把视频帧看成一个排序问题,和视频相关性大的帧排在前面。利用前面学到排序函数对视频中的帧打分,得分高的帧就被选为关键帧,计算复杂度是。大多数视频摘要方法,把生成摘要看成一个优化的问题,从所有的视频帧集合中找出一个得分最高的集合作为视频摘要,计算复杂度是。
3 实验与结果
3.1 实验设置
3.1.1 数据集
实验用的数据集是TVSum50数据库[11],包含50个视频,10个类别,每个类别有5个视频,视频时长2~10 min不等,视频包含了新闻、纪录片、用户拍摄等不同的种类,视频被每2 s分成一段,每个视频段由20个用户打分,产生20个分数(1~5,5代表该视频段与视频最相关,依次递减),分数高的视频段中的帧被选为关键帧。就像其他论文中那样,摘要的长度被限制在小于视频长度的15%。从每个类别的视频里随机选取一个视频作为测试视频,剩下的视频作为训练视频,也就是40个视频作为训练集,10个视频作为测试集。如图1所示。

图1 判断两个图片相似的情况,从每个阈值里选取了两组图Fig. 1 Judging the similarity between the two pictures and selecting two pairs of pictures from each threshold
3.1.2 评估方法
对于自动产生的摘要A和人工标记的ground truth摘要B,本文是通过计算摘要A和摘要B的匹配程度来判断摘要A的好坏。从摘要A和摘要B中分别取出一个视频帧组成一个包含两个视频帧的对,若A中有个帧,B中有个帧,则会产生种对。计算每对的距离,若距离小于某个阈值,则认为这个视频帧对成功匹配,需要注意的是每个视频帧只能成功匹配一次。精确率、 召回率和F-score定义为
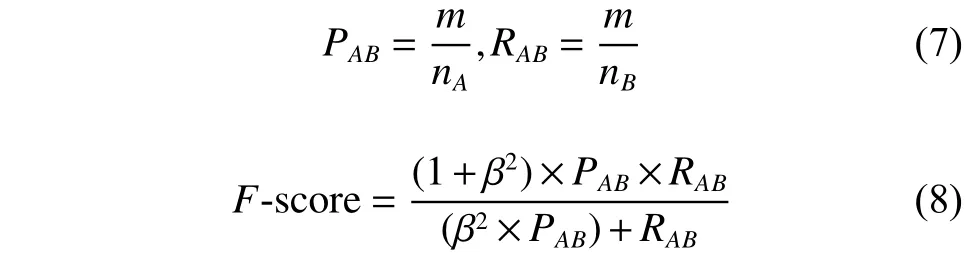
用自动产生的摘要分别与20个人工标记的摘要计算P、R、F-score,之后取平均值作为该视频的最终结果。
3.2 实验和结果
3.2.1 阈值设置
视频帧用不同的特征提取方法得到的帧是不一样的,判断两个视频帧是否相似的阈值也随之不同,若阈值设置太大会产生两个完全不一样的图片被判断为相似,使得F-score值偏大;反之,若阈值设置太小会使得F-score值偏小,所以要判断阈值为为何值时认为两个帧相似会比较合理。
从图2中可以看出F-score随阈值的增大而增加。设置阈值是为了判断两个图片是否相似,阈值设置太大就不能解决这个问题,所以要选取合适的阈值。
从图2中可知,threshold=0时,只有两个图片一模一样才会被判断相似;threshold=0.04时,观察发现两个不相似的图片被认定相似,也就是说阈值设置太大了;最终threshold设置为0.03。
3.2.2 实验改进
uniform sample 和random sample都是取样中的方法,uniform sample是按照固定间隔抽取视频帧,random sample是随机抽取关键帧。聚类是从较大的簇中选取视频帧,用了两种聚类方法k-均值聚类(k-means cluster)和谱聚类(spectral cluster)。LiveLight (online video highlighting)方法[12]是通过字典衡量冗余信息,删除冗余信息来选取摘要。sample、cluster和LiveLight都是非监督方法,而本文的方法是有监督的方法,用人工标记的摘要学习排序函数,学习人工打分的过程,实验结果表明本文的方法更好,如表1所示。

图2 阈值取不同值时对应的F-score值Fig. 2 F-score value with different threshold

表 1 不同方法在TVSum50上的实验结果Table 1 The Results on TVSum50
4 结束语
由于目前大多数的视频摘要方法要对摘要做约束并构建相应的公式,而且还要从众多的视频帧集合中挑选比较好的集合作为摘要,不仅需要先验知识,由于集合数目太多,还会增加计算量。本文呈现的视频摘要的方法,把提取摘要看作是对视频帧的排序问题,利用人工标记的关键帧训练排序函数,使得排在前面的帧是人工标记的帧,因此不是对视频帧集合打分,而是对单个帧打分,这样可以减少计算量,在TVSum50数据集上表现出比其他几个视频摘要的方法好。
