基于改进LightGBM的交通模式识别算法
2018-11-01熊苏生
熊苏生
(1.华南师范大学,广东 广州 510631; 2.阿里巴巴集团,浙江 杭州 311121)
0 引 言
用户的交通模式是指人们的出行方式,随着交通越来越智能化,对居民出行的交通模式识别,有利于城市规划建设者和道路交通管理者掌握人们的出行方式,合理规划交通布局,缓解交通压力,为智能交通的精细引导、实时路况以及市政决策提供了数据支撑。手机传感器技术具有的实时性、动态性、可持续性等特性,被部分交通行业学者所发掘[1]。应用手机传感器数据进行交通模式识别逐渐成为国内外学者研究的热点。
1 研究现状
识别用户的交通模式是一个典型的模式识别问题,目前国内外研究者提出了相应的解决方案。首先,通过手机和穿戴式设备收集数据并对数据集进行一个基本的预处理,去除一些重复数据和信号异常数据,生成待实验数据集。然后,提取特征值并对特征值进行分析与比较,得到最终特征。最后,使用各分类模型进行分类,得出分类结果并评估。
在识别用户交通模式的研究中,较高的识别准确率、丰富的识别种类和便于实施的要求非常重要[2]。一方面,准确地识别多种类别的交通模式是它能够被实际应用的基础;另一方面,考虑到成本与实施问题,要求方法是易于被普通用户接受的。近年来已经有不少相关研究,然而,这些研究均不能很好地满足以上3个方面的需求。Wang等[3]提出的方法能识别包括地铁在内的6种交通模式,但在分类规则方面,使用基于生活规则的判别条件加单一分类算法决策树,相比于集成学习分类算法(如随机森林等),在识别准确率、强壮性和适应性方面表现均存在不足。Reddy等[4]提出一种基于手机的GPS和加速度传感器的交通模式识别方法,准确率高达93.6%,且仅依赖于手机传感器数据满足便于实施的要求,但是它只能区分静止、步行、跑步、自行车和机动车这5种模式,不能将机动化的交通模式区分开来。Xiao等[5]和廖思静[6]提出一种基于决策树的组合模型的交通模式识别方法,能够识别丰富的类别(包括地铁),实施简便,但识别非步行交通模式准确率较低。Stenneth等[7]提出一种基于GPS和GIS的识别方式,准确率高达93.4%,能够将地面上的机动化交通区分开来(不包括地铁),但识别需借助于后台服务器的运算,不易实施。Yu等[8]提出一种基于加速度传感器、陀螺仪和磁力计的识别方法,能耗低并且易运算,但数据预处理和特征选择方法较为简单,对机动化交通识别准确率不高。
对当前国内外的研究现状和进展进行总结,得到如下结论:在数据采用方面大部分使用GPS、WiFi、蓝牙和加速度传感器这些数据相结合,在识别类别丰富的前提下,对步行交通模式识别准确率较高,但是对非步行交通模式识别准确率较低。针对这类问题,本文提出一种基于改进的LightGBM算法[9](K-lightGBM)结合移动端的识别方法对交通模式进行识别的方法。
2 LightGBM简介
LightGBM是微软DMTK团队开源发布的,为Gradient Boosting算法的改进版本。LightGBM是一个轻量级的GB框架,基于决策树的学习算法,支持分布式。其中Gradient Boosting算法的思想是将弱分类算法提升为强分类算法,从而一定程度提高分类准确率。算法主要流程如下:
1)初始化m棵决策树,训练样例的权重为1/m;
2)训练弱分类器f(x);
3)决定该弱分类器的话语权∂;
5)得到最终分类器:
Fm(x)=∂0f0(x)+∂1f1(x)+∂2f2(x)+…+∂mfm(x)
(1)
3 K-lightGBM
针对LightGBM算法在交通模式识别应用中很难区分机动车交通模式这一问题,本文提出改进的K-lightGBM算法进行识别,给每个决策树子分类器的话语权引入K值,进行重新判定。基于交通模式规则去除部分错误分类树,针对2种交通模式特征区域相似(在交通模式中例如:汽车和公共汽车),用一阶隐马尔科夫链[10]验证结果,更新K值,使损失函数L(Fm(x),y)更加减少,提高模式识别精度。算法主要流程如下:
1)初始化m棵决策树,训练样例的权重为1/m;
2)训练弱分类器f(x);
3)决定该弱分类器的话语权∂;
4)根据前一段轨迹,判断其是否符合步行-非步行-步行的交通规则;
5)针对特征区域相似的2种交通模式,采用马尔科夫链对弱分类器结果进行验证,更新话语权为K∂;
7)得到最终分类器:
Fm(x)=∂0K0f0(x)+∂1K1f1(x)+
∂2K2f2(x)+…+∂mKmfm(x)
(2)
3.1 K值
K值的设定如公式(3):

(3)
其中,
(4)
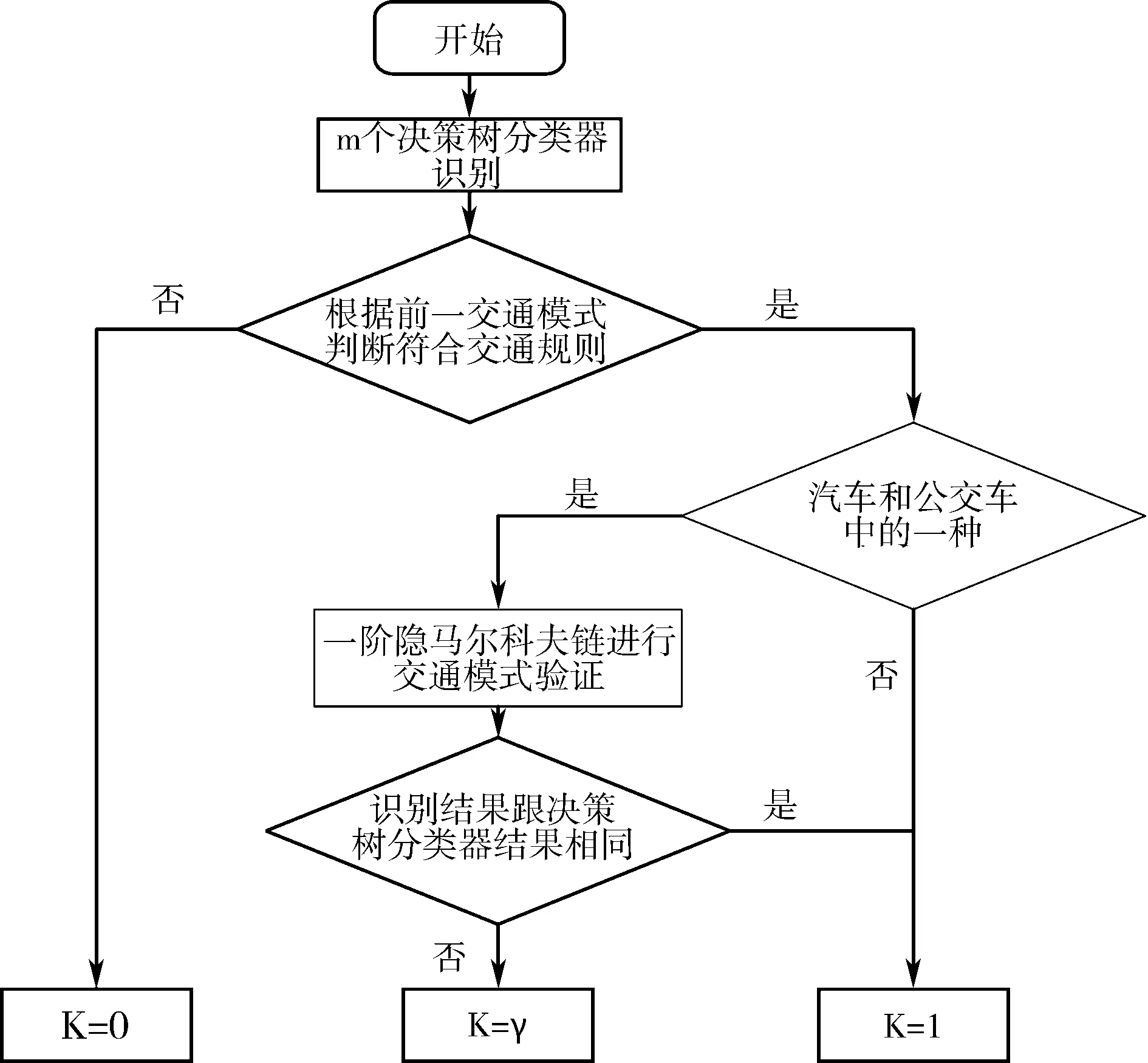
图1 K值选取算法流程
式(4)中:n1表示当前决策树子类识别模式样本总数,n2表示另一种与该模式特征区域相似的样本总数。K值选取流程如图1所示。
从图1可知,当决策树子类识别结果不满足步行-非步行-步行的交通规则,则认定该子类为错误分类,设K=0;如满足交通规则,当识别的交通模式是汽车和公共汽车的一种时,使用一阶隐马尔科夫链验证,如识别结果与决策树子类不相同,则认定该子类为模糊分类,设K=γ;其余情况,认定子类为精确分类,设K=1。
3.2 一阶隐马尔科夫链模型
在随机序列中,居民当前的交通模式只与前一交通模式有关,符合一阶隐马尔科夫过程(时间是离散的,因有步行转换过程)。公式如下:
θ=(C,D,π)
(5)
式中,隐马尔可夫模型θ由初始状态概率向量π、状态转移概率矩阵C和观测概率矩阵D决定。π和C决定状态序列,D决定观测序列。马尔可夫模型中最主要的是状态转换的转移矩阵,下面阐述在交通模式识别中,状态转移过程。设在马尔科夫链中第n个时刻的状态为Sn,则可能转移的状态有9种:S0,S1,S2,…,S8。整个状态集合定义为:
S={S0,S1,S2,…,S8}
(6)
其中,第n个时刻的状态Sn∈S。转移概率如式(7):
pij=p(Sn+1=Sj/Sn=Si)
(7)
式(7)中,
Si,Sj∈S,pij表示Si状态到Sj状态的转移概率。状态转移矩阵可描述为式(8):
(8)
3.3 损失函数
在分类中,一般损失函数[11]越小,模型拟合程度越好。经过改进后的最终分类器,损失函数的变化如式(9):
L(Fm(x),y)≤L(Fm-1(x),y)
(9)
式(9)中,除了子类是错误分类,目标损失函数L不变,否则目标损失函数L是随着子类的增加而减少的。经过m次目标损失函数变化,得到最终分类器Fm(x)。
4 相关工作
本文选择了3种传感器的时域特征和频域特征的最优特征集对多种交通模式进行分层识别,分别是步行、汽车和公共汽车、跑步、自行车、摩托、火车、地铁和高铁。采用基于交通模式规则(居民出行交通模式是步行到非步行再到步行的周期过程)和一阶隐马尔科夫链算法改进的K-lightGBM算法,减少了错误分类率,分层识别算法如图2所示。
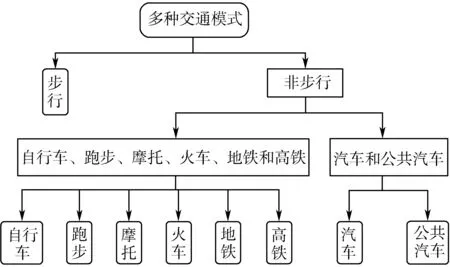
图2 分层识别算法
本文的算法框图如图3所示。首先用Butterworth滤波[12]对加速度计、陀螺仪和磁力计这3种传感器数据进行滤波处理,然后分别计算3种传感器用于交通模式识别的时域特征和频域特征,经过对提取的特征用CFS算法进行分析,选取最优特征集,最后通过改进的K-lightGBM算法进行识别,得出最终结果。
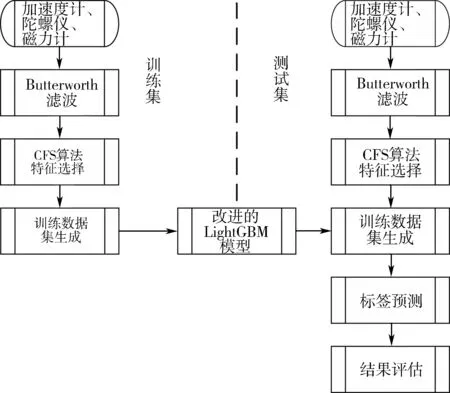
图3 算法框架图
4.1 传感器选择
为了选择合理的传感器数据进行交通模式识别,本文在文献[8]基础上,分析了传感器能耗和数据集对分类精度的影响,采用控制变量的方法进行实验。把仅使用加速度计传感器数据进行识别的分类精度作为基准,平均精度提升率设置为0%;把使用GPS数据进行识别的能耗作为基准,平均能耗降低设置为0 mA[8];“√”表示采用了该类传感器数据,如表1所示。
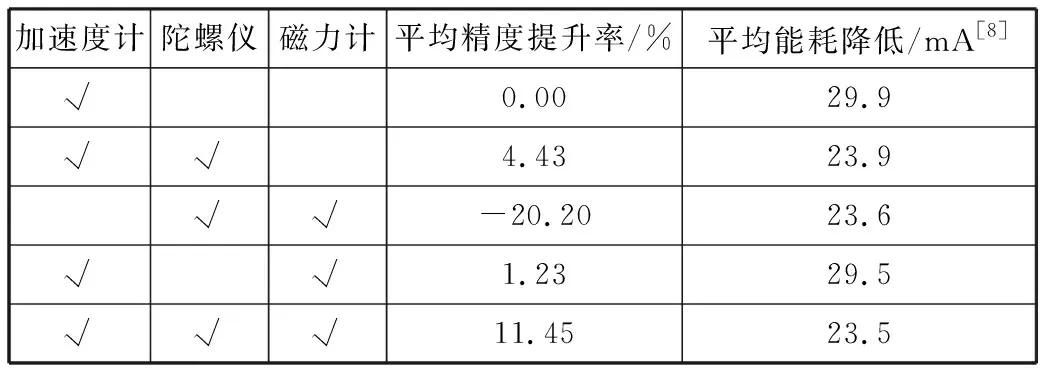
表1 传感器影响分类精度与能耗表
从表1可知,三轴加速度计对实验的分类精度影响最大,当缺少三轴加速度传感器数据时,精度下降了20.20%。而同时采用三轴加速度计、陀螺仪和磁力计传感器的数据时精度是最高的,提升了11.45%。使用三轴加速度计、陀螺仪和磁力计相对于使用GPS有较低的能耗,至少降低23.5 mA,其中减少使用三轴加速度计、陀螺仪和磁力计其中的1种或2种传感器对能耗的降低不明显。从而可知,使用三轴加速度计、陀螺仪和磁力计传感器收集数据进行模式识别不仅能耗较低,而且还有较高的精度。
4.2 Butterworth滤波
当传感器收集数据时,电路经常存在较大噪声,对于数据的分析有重大影响,真实的传感器数据会被噪声所干扰,使得结果数据质量严重下降。为了在实验中抑制高频信号干扰,本文采用Butterworth低通滤波方法对数据进行滤波。
在实际应用中,传感器数据除了对一些特定的动作使用特定的单轴来辨别方向之外,通常将三轴数据合成一个值[13],这样在确保精度的同时,减少了计算复杂性,见公式(10):
(10)
式(10)中,A为合成值,ax、ay和az分别表示三轴读数。在对传感器数据进行滤波时,为提高滤波效果,本文分别对三轴数据进行了Butterworth滤波,再将三轴数据进行合成。Butterworth滤波传递函数为:
(11)
式(11)中,(u,v)为原点坐标,w0为截止频率,n为滤波阶数,取正整数,它控制滤波的衰减速度。滤波的特性完全由阶数n决定,当n增大时滤波器的特性曲线变得更陡峭,因此在通带的更大范围内接近于1,在阻带内更迅速地接近于0,因而振幅特性更接近于理想的矩形频率特性。滤波前后对比如图4所示。
图4给出了3种传感器数据滤波前后波形。横坐标表示时间,纵坐标表示传感器示数,其中A、G和M波段分别表示加速度计、陀螺仪和磁力计滤波前的信号波形,γ(A)、γ(G)和γ(M)波段分别表示加速度计、陀螺仪和磁力计滤波后的信号波形。从滤波前的波形可以看出,信号有很杂乱的毛刺波形,经过Butterworth滤波后,数据曲线变得光滑,毛刺波形较少。

(a) 加速度计数据滤波前后对比波形
(b) 陀螺仪数据滤波前后对比波形
(c) 磁力计数据滤波前后对比波形
4.3 特征选择
本文针对每种传感器计算了19种特征,并将它们分为时域特征和频域特征,采用Filter的相关性度量CFS算法对每一维的特征“打分”并进行特征选择。CFS(Correlation-based Feature Selection)是基于关联规则的特征选择算法,由Hall[14]提出。CFS估计特征子集并对特征子集进行排序,即对每个特征子集进行排名。采用启发式的方式评估特征子集的价值。启发式方程为:
(12)
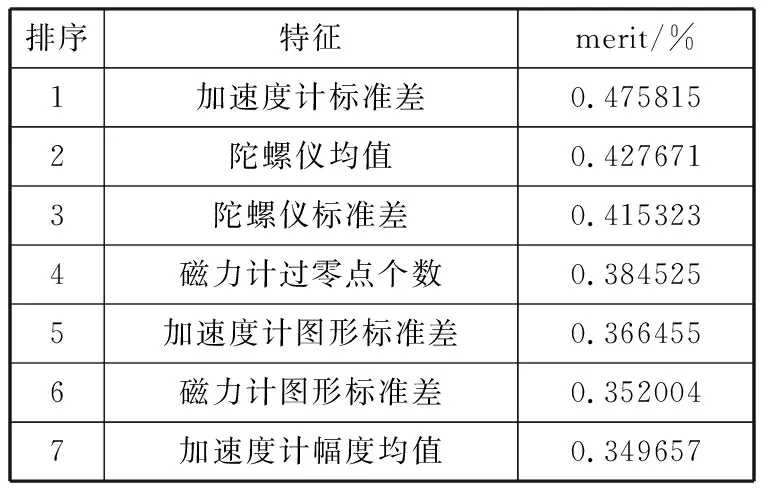
表2 特征排序表
5 实验结果及分析
本文采用HTC公司提供的数据集,该数据集大小为100 GB,记录了一组150名大学生和一组74名工人各311 h的轨迹数据。他们的交通模式分为9种模式:步行、跑步、自行车、摩托车、汽车、公共汽车、地铁、火车和高速铁路(高铁)。在系统设计中,本文采用分层抽样,把数据从内部分成74.5%训练集和25.5%测试集进行实验,横坐标表示交通模式类型,纵坐标表示轨迹段数,数据分布如图5所示。
本文用Python语言编写代码,设置好模型参数,将经过预处理的数据分别代入到K-lightGBM、LightGBM、XGBoost、SVM和KNN这5种分类模型进行实验,得出最终分类结果。
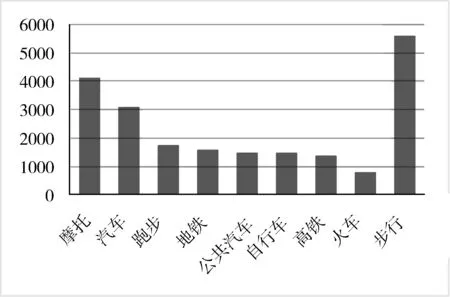
图5 数据分布图
5.1 评价指标
准确率和召回率是广泛用于交通模式识别领域的2个度量值,用来评价结果的质量。f1值是准确率和召回率的调和均值,相当于准确率和召回率的综合评价指标。公式如下:
(13)
(14)
(15)
其中,tp表示将正类预测为正类的数,fp表示将负类预测为正类的数,fn表示将正类预测为负类的数。
5.2 K-lightGBM的K值对分类影响
K-lightGBM算法在对于2种特征区域相似的交通模式识别中,当子类验证为模糊分类时,需要分析K的取值对分类精度的影响。如图6所示,当K=γ时,识别的分类最高,当K从0到1进行取值,分类精度是先增加,然后再减少的过程。从而可知,在经过一阶隐马尔科夫链验证决策树子类为模糊分类时,令K=γ最佳。
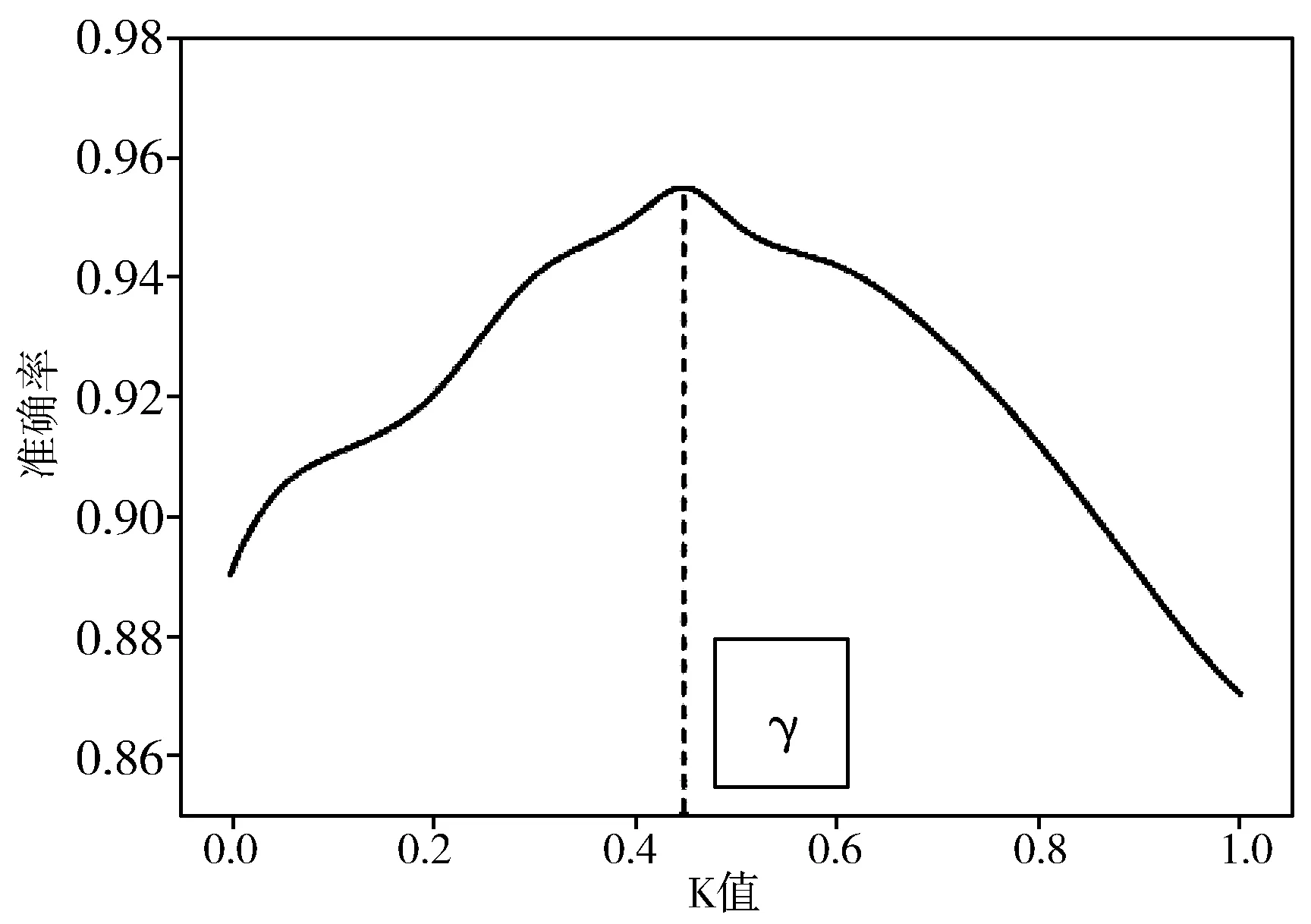
图6 K取值对分类精度的影响
5.3 常用算法对比
本文采用SVM、KNN、XGBoost、LightGBM和K-lightGBM这5种模型进行实验,对比分析各模型对交通模式的识别结果。
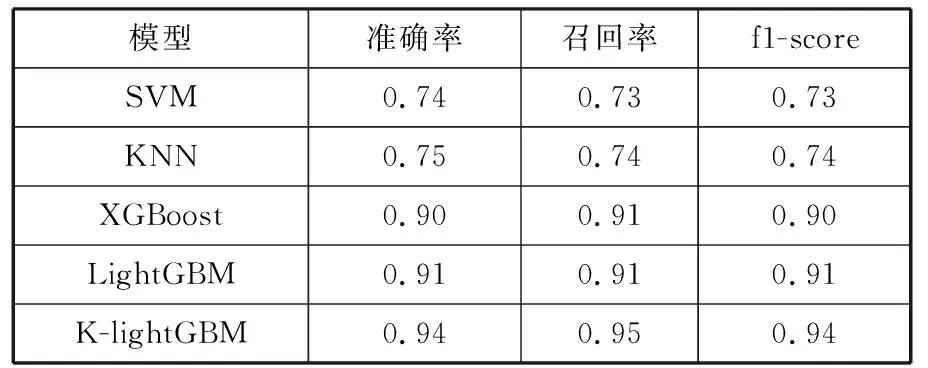
表3 各模型分类精度表
如表3所示,通过HTC数据集分类结果的对比,可以看出,K-lightGBM分类方法对该数据集的准确率、召回率和f1值最高,分别为94%、95%和94%,其中K-lightGBM的准确率相比于LightGBM分类方法提高了3%,比XGBoost提高了4%,比SVM提高了20%,比KNN提高了19%。由此结果可以得出,K-lightGBM算法在对交通模式识别时,比其他4种模型识别效果好,各项指标都有一定的提高。
5.4 与文献[8]对比
K-lightGBM识别方法与同样使用HTC数据集的文献[8]的方法对比如表4所示,分析可知,在步行、跑步、自行车和机动车(摩托、汽车、公共汽车、火车、地铁和高铁的总称)交通模式上分类准确率分别提高了8%、1%、3%和5%。这说明本文提出的K-lightGBM相对于文献[8]方法能更准确地识别居民出行的交通模式。
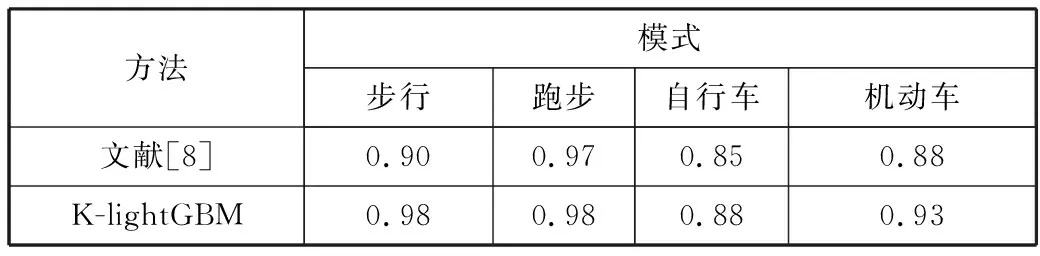
表4 K-lightGBM与文献[8]分类精度比较
5.5 3种集成学习准确率对比
实验将HTC数据集按递增梯度分成样本大小不同的6组数据,从分类准确率的角度分析改进后的K-lightGBM、LightGBM和XGBoost三者的算法优异。
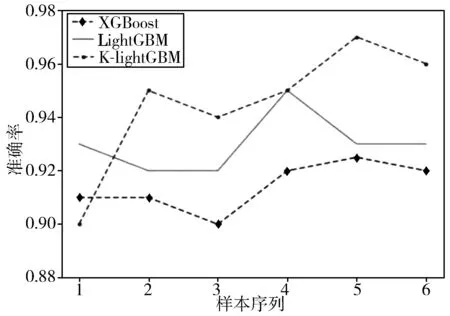
图7 3种算法识别准确率比较
从图7可以看出,除了样本较小的极少组实验,K-lightGBM算法比其他2种集成学习算法分类精度都要高,从准确率曲线表明,本文提出的K-lightGBM算法比其他2种算法较优。
5.6 不同交通模式分类准确率
为探究K-lightGBM的识别效果,针对HTC数据集的不同交通模式的识别效果进行实验。
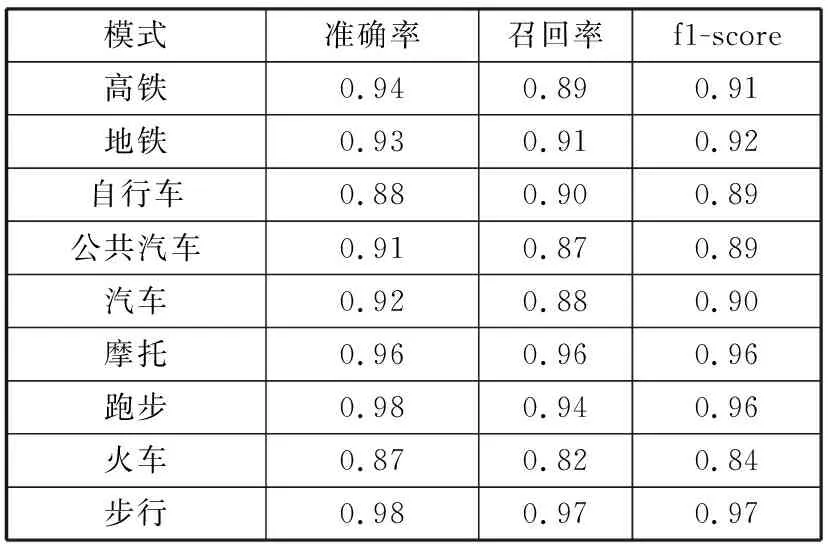
表5 K-lightGBM对不同交通模式识别准确率
如表5所示,从K-lightGBM模型中各交通模式的分类结果可以看出,高铁、地铁、自行车、公共汽车、汽车、摩托、跑步、火车和步行都有很高的分类准确率、召回率和f1值。其中火车的分类准确率最低,但仍旧有87%,跑步和步行的准确率最高达到了98%。由此可以得出结论,K-lightGBM算法对各交通模式均有很高的识别精度。
6 结束语
本文提出一种基于智能手机传感器的模式识别方法,首先通过Butterworth滤波器对加速度计、陀螺仪和磁力计这3种传感器数据进行滤波,减少噪声对真实数据的干扰,随后用Filter方差法选择最优特征集,使用基于居民出行规则和一阶隐马尔科夫链改进的K-lightGBM模型进行分类,实验表明该方法分类精度不仅较高,而且能识别多种交通模式。实验过程依靠手机传感器收集数据,操作简单,有一定的工程应用价值。
目前影响交通模式识别的因素有很多,主要影响有3方面:数据集的选择、特征值的选择和分类模型的选择[15-17]。因为数据集的局限性,本文方法在选择特征时没有与周围环境相结合。如,日常生活中在轨迹附近的兴趣点不同,居民的停留时间和行为是不一样的;不同地区人们停留的次数和方向的转换率也是不同的。笔者下一步研究特征值时,将结合停留点周围环境去计算相应的特征,最后通过排序和比较选择最优特征集合,同时加强对集成学习和深度学习的研究,提高模式识别的分类精度。
