基于ISOA的LS-SVM地铁站空调系统能耗预测模型
2018-11-01高学金付龙晓武翠霞
高学金,付龙晓,武翠霞,王 普
(1.北京工业大学信息学部,北京 100124; 2.数字社区教育部工程研究中心,北京 100124;3.城市轨道交通北京实验室,北京 100124; 4.计算智能与智能系统北京市重点实验室,北京 100124)
0 引 言
地铁已成为解决城市道路交通阻塞和居民乘车难问题的最有效的途径,并能够减少城市污染,改善地面交通状况,带来显著的社会效益和经济效益[1]。然而随着我国能源问题的严重,地铁运营成本不断增大,地铁站空调系统是整个地铁系统的能耗大户,约占总用电量的30%~50%[2],因此地铁站空调系统的节能意义重大。空调系统能耗的准确预测是实现节能运行的前提,空调能耗预测的方法有回归分析、指数平滑法、灰色预测和人工神经网络模型预测等[3-5],然而由于空调系统中影响能耗的因素众多[6],如送风温度、回风温度、冷机的出水温度、室外温湿度时刻表、当前时刻的站内环境温湿度和能耗值等,每个影响因素之间相互耦合,且空调系统能耗变化具有非线性和时变性,预测模型的精度达不到令人满意的程度。
支持向量机[7](Support Vector Machine, SVM)是在统计学上发展起来的一种算法,而最小二乘支持向量机(Least Squares Support Vector Machines, LS-SVM)使用求解一组线性方程代替标准的QP问题,从而大大减少了学习过程的计算时间[8],其已经广泛地应用于空调系统能耗的预测。但是由于LS-SVM参数选择带有随机性,给系统性能带来很大的影响,针对参数选取问题一些学者在进一步的研究中引进了一些智能算法来改进模型的性能。
蚁群算法、教学算法和粒子群优化算法等[9-10]在LS-SVM的参数寻优中逐渐被应用。叶永伟等人[11]利用网格搜索算法和交叉验证方法寻找最小二乘支持向量机的最优参数组合,与常规最小二乘支持向量机进行比较预测精度有所提高,推广能力较强,但是搜索时间较长;吕游等人[12]直接采用文献[11]提出的方法对参数进行优化,未对优化方法进行改进提升,但验证了网格搜索算法优化LS-SVM参数的推广性能;张广明等人[13]考虑目标函数的变化极值点对预测误差的影响,采用改进的粒子群算法优化最小二乘支持向量机的参数,预测模型取得较高的预测精度,但是预测时间较长;戟钢等人[9]采用精英策略,同时引入粒子历史最优信息改进引力搜索算法,将改进后的算法应用到最小二乘支持向量机的参数寻优机制,并与遗传算法、粒子群算法等进行比较,优化后的预测模型预测精度更高,但是计算过程复杂,粒子迭代次数增多。
最小二乘支持向量机建模的精度主要取决于核函数的构造及其参数的选择。传统的参数选择方法不仅受数据规模的限制,而且优化方法相当耗时,很难精确找到最优参数。综合精度和速度这2方面性能指标,搜索者优化算法(Seeker Optimization Algorithm, SOA)具有相对优势[14]。该算法是一种基于种群的启发式随机搜索算法,目前应用在典型函数的优化、电力系统无功优化[15]、图像分割[16]、IIR数字滤波器优化设计[17]和SVM参数优化[18]等方面。随着近几年的发展,又被称为人群搜索算法。但是人群搜索存在计算时间长的问题,从搜索步长和搜索方向这2个方面进行改进,可以解决此问题。
本文对SOA算法主要有2个方面的改进:1)用高斯隶属函数代替线性隶属函数,加快收敛过程;2)方向更新中,预动方向采用个体最优适应度值和当前个体的适应度值比较得出,提高了计算速度。本文最后将ISOA(Improved Seeker Optimization Algorithm)应用于LS-SVM的参数寻优,并基于地铁实训平台的数据,建立空调系统的能耗预测模型,为地铁站空调系统的节能运行提供依据。
1 LS-SVM回归原理
支持向量机做回归是通过一个非线性映射函数φ(·),将输入数据映射到一个高维空间,进行线性回归,此时在高维空间的线性回归就相当于低维空间的非线性回归。
最小二乘支持向量机的算法如下:设训练样本集合D={(xi,yi)},i=1,2,…,N,其中xi∈R为训练样本的输入数据,yi∈R为与之对应的输出数据,xi与yi之间对应的回归函数可以定义为:
yi=ωφ(xi)+b
(1)
式中,ω为权值矢量,b为偏置。根据结构风险最小化原理,最优化问题就转化为寻找使下面风险函数最小的y:
(2)
其中,γ为惩罚系数,ei为误差,约束条件为yi=ωTφ(xi)+b+ei,i=1,2,…,N。利用拉格朗日乘子法,引入Lagrange乘子αi,如下:
(3)
公式两边分别对ω、b、ei、αi求偏导数,得:
(4)
(5)
(6)
(7)
消去中间变量ω和ei,则求解的最优化问题转化为求解线性方程组:
(8)
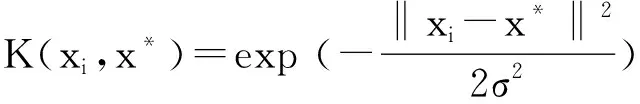
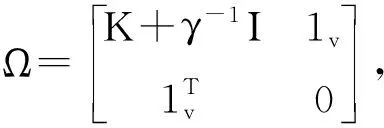
(9)
2 改进的人群搜索算法
2.1 人群搜索算法
人群搜索算法[19](Seeker Optimization Algorithm, SOA)模拟人的随机搜索行为,将人的智能搜索行为直接应用于对优化问题的搜索。优化搜索计算中:在连续空间的搜索过程中,最优解可能存在于较优解的领域内。因此,当搜寻者所处位置较优时,应该在较小领域内搜索;当搜索者所处位置较差时,应该在较大领域内搜索。SOA利用能有效描述自然语言和不确定性推理的模糊逻辑来对上述搜索规则进行建模,并确定搜索步长。其通过社会学习和认知学习,分别获取社会经验和认知经验,并结合智能群体的自组织聚集行为、以自我为中心的利己主义行为和人的预动行为,确定个体搜索方向。
SOA的模糊系统将目标函数值按递减的顺序排列,将排列得到的序号值1到s的自然数作为模糊推理的输入,采用线性隶属度函数模糊输出,如式(10):
(10)
式中,ui为第i个种群目标函数的线性隶属度,s为种群个数,Ii为第i个种群目标函数降序排列后的序号,umax和umin分别为最大和最小的隶属度值。
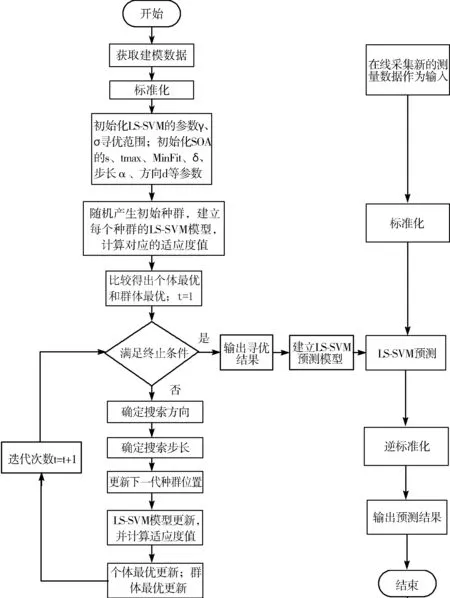
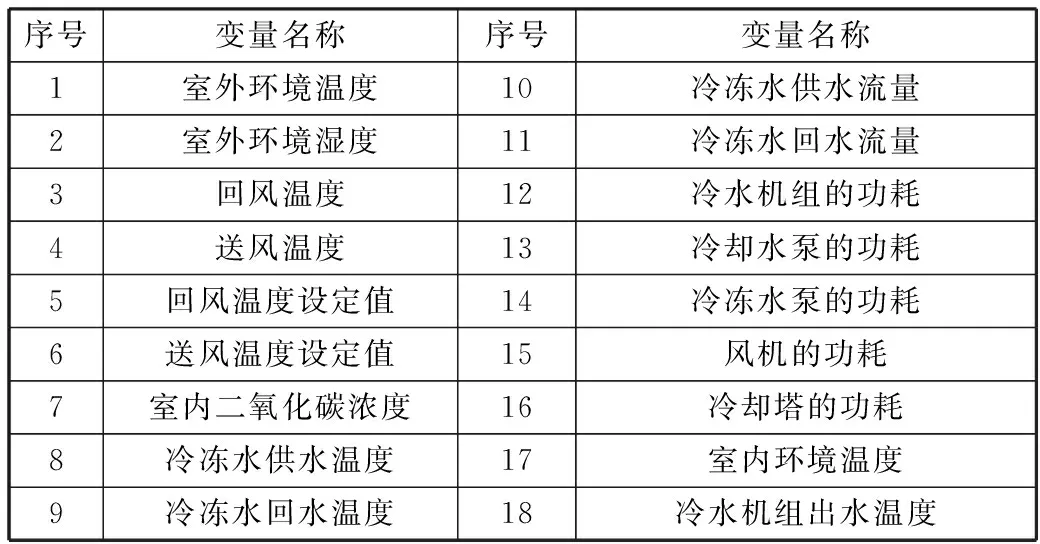
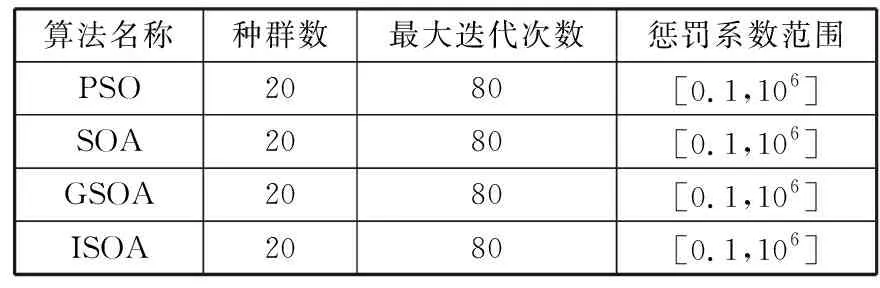
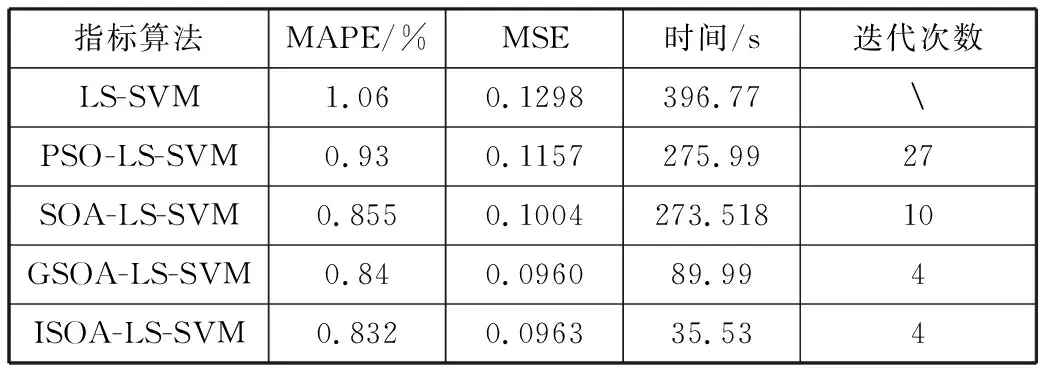
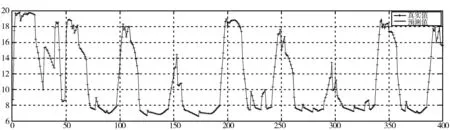
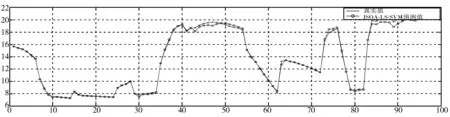
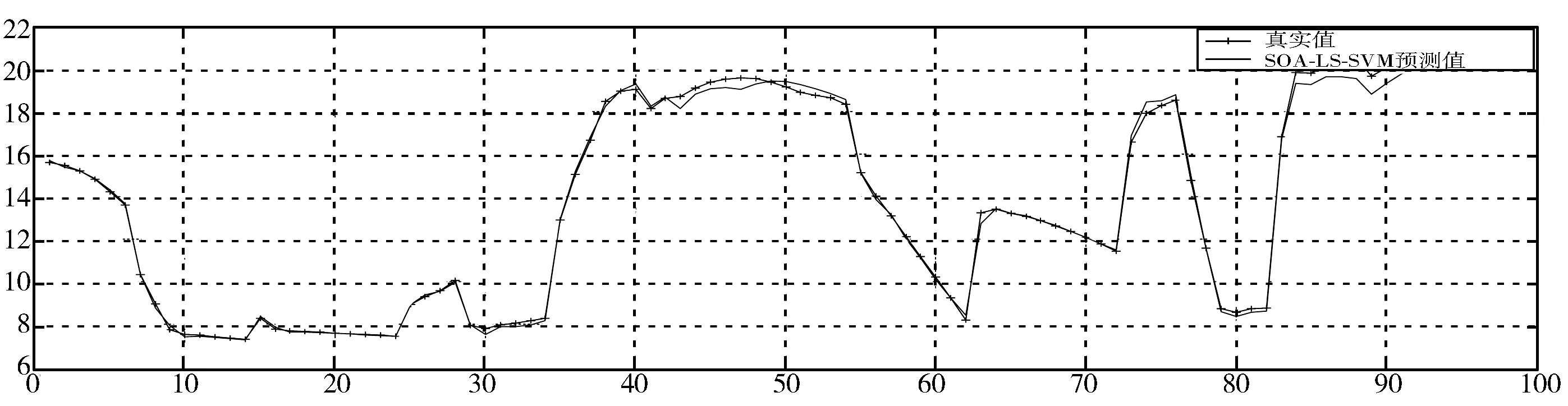
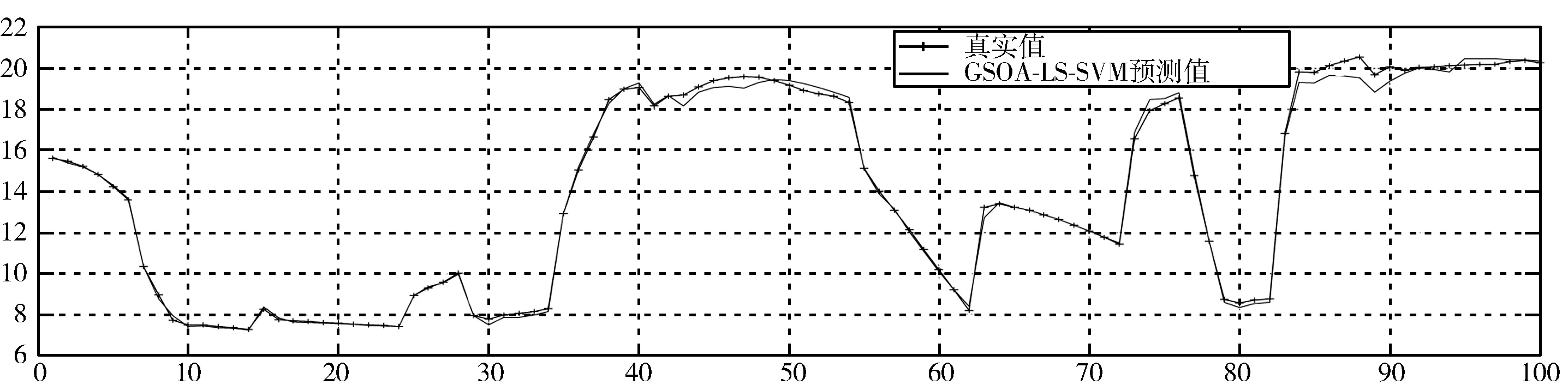
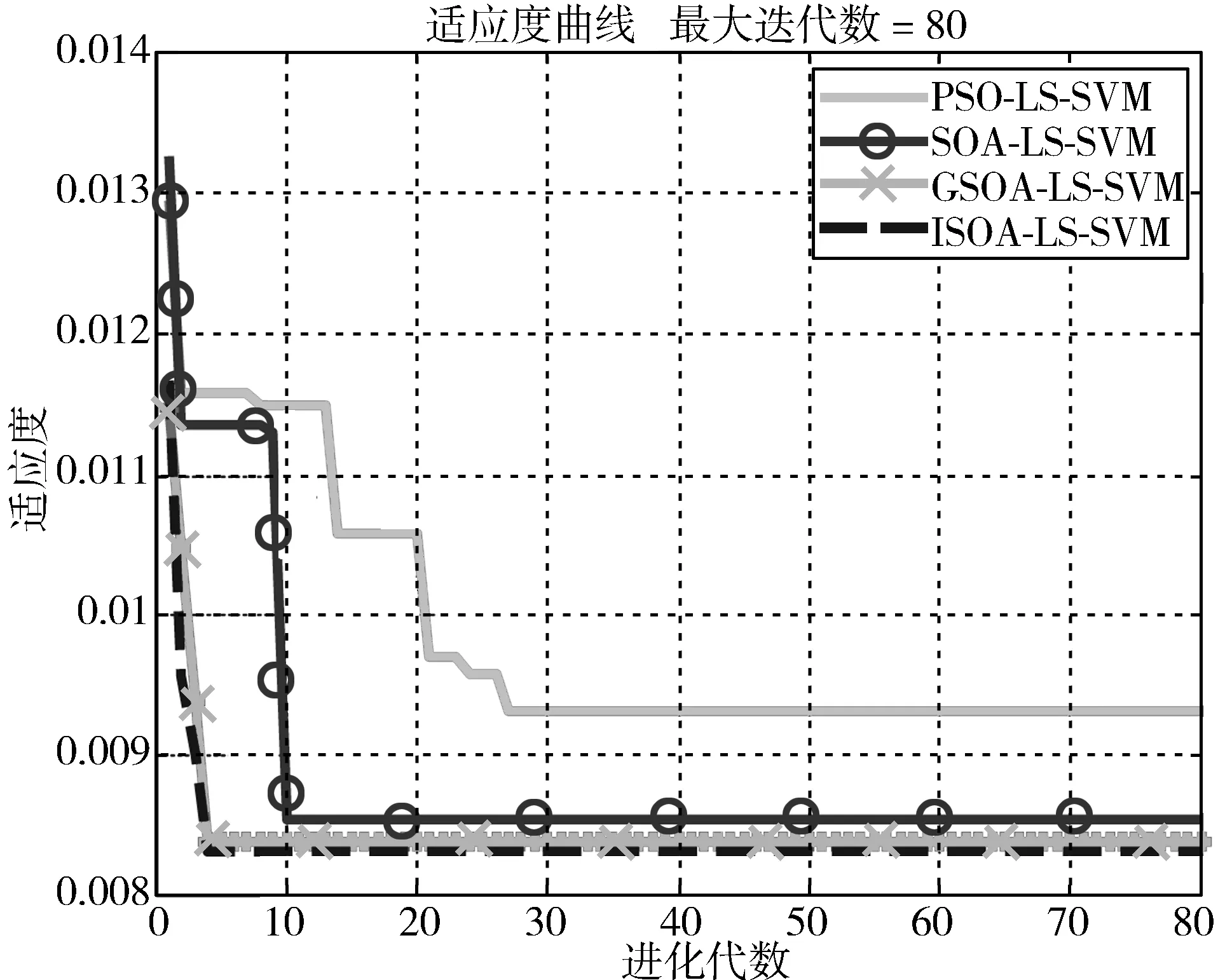
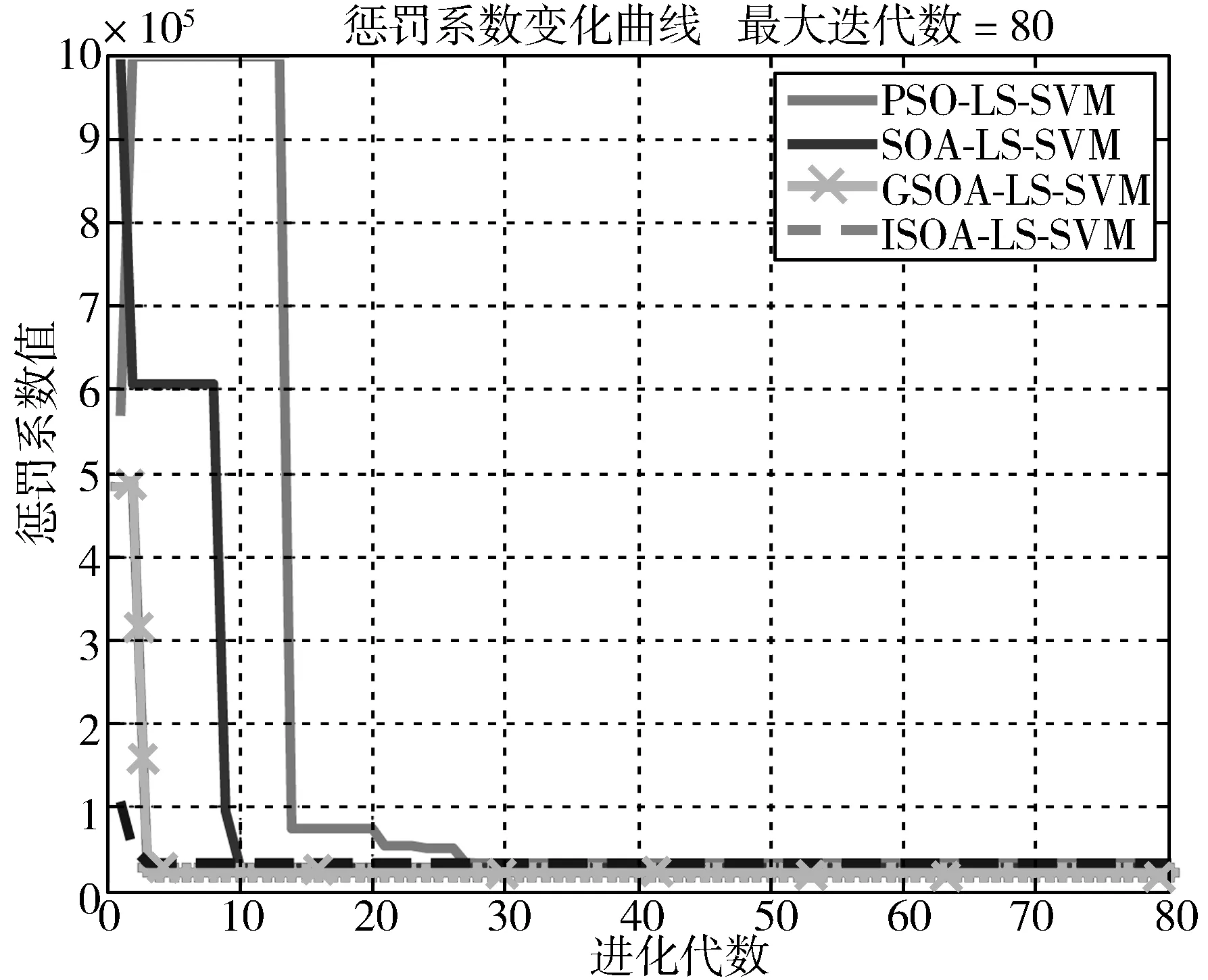
式(10)使隶属度值直接与目标函数值成正比,即在最佳位置(目标函数值最小,排列序号最大s)有最大的隶属度值,在最差的位置有最小的隶属度值,在其他位置umin 为了模拟人的搜索行为随机性,由不确定性推理可得,第i个种群中第j维搜索空间目标函数值的隶属度uij,如式(11): uij=rand(ui,1) j=1,2,…,D (11) 函数rand(ui,1)为均匀、随机地分布于区间[ui,1]上的实数。再根据不确定推理可得搜索步长: (12) 其中,αij为第i个种群中第j维搜索空间的搜索步长;δij为高斯隶属函数参数;xmin和xmax分别为同一种群中的最小适应度值和最大适应度值时的位置;ω为惯性权值,范围为[0.1,0.9];t为当前迭代次数,Tmax为最大迭代次数。 (13) 综合以上3个方向,取它们的随机加权几何平均作为搜索方向,如式(14): (14) 在搜索方向和步长确定后,即可对每一个个体进行位置更新: (15) 1)确定搜索步长。 相比于线性隶属函数来说,采用式(16)和式(17)的高斯隶属函数表示搜索步长的模糊变量可以很好地将第i个搜寻个体的适应度值非线性地模糊到[0.0111,0.95]之间,避免了由线性隶属函数模糊的步长不准确性,可以快速收敛,并且减小计算量。 (16) uij=ui+rand·(1-ui), j=1,…,D (17) (18) 因此步长计算公式为: (19) (20) (21) (22) 预动方向采用个体最优适应度值和当前个体的适应度值比较得出,可以很好地代表当前个体的预动行为,同时减小计算量,提高计算速度。 (23) (24) 空调能耗存在的影响因素众多,本文采用LS-SVM方法对空调能耗进行建模。本文选择径向基核(RBF)函数,与其他4种核函数(线性内核、多项式内核、径向基内核(RBF)、sigmoid核)相比[21],RBF核函数适用范围广,无论是小样本还是大样本,高维还是低维等情况,RBF核函数都适用,并且需要确定的参数少,算法复杂度相对较低。 考虑到LS-SVM算法的正则化参数和核参数对模型拟合精度及泛化能力有较大影响,采用ISOA对LS-SVM的参数C和σ进行优化选择,目的是进一步提高LS-SVM的学习能力和计算速度。 优化问题的目标函数选取如式(25): (25) 综上所述,建模主要步骤总结如下: 1)数据预处理。对所采集的数据进行相关性分析,选择输入输出向量,构造训练集数据。 2)数据归一化。 3)初始化参数。初始化种群规模、最大迭代次数、最小适应度值;确定初始的经验梯度方向、搜索步长、高斯核参数以及利己方向、利他方向和预动方向;确定正则化参数C及核参数σ的寻优范围并随机产生初始种群;令迭代次数t=0。 4)最优模型参数确定: ①建模。基于训练样本集和搜索位置参数,建立LS-SVM模型。 ③判断终止条件。如果迭代次数t大于最大迭代次数或者适应度值小于最小适应度值,则输出最优参数C*和σ*;否则进入下一步,计算搜索方向和位置,并进行位置更新。 ④确定搜索步长如式(16)~式(19)所示。 ⑤确定搜索方向如式(20)~式(24)所示。 ⑥位置更新。在确定出的搜索方向和步长后,即可对每一个个体进行位置更新,公式如式(15),令t=t+1,更新完毕,则返回第①步建模。 5)基于最优参数C*和σ*,按式(5)求解b、α,建立LS-SVM的空调能耗模型。 SOA-LS-SVM的建模流程如图1所示。 图1 建立预测模型流程图 利用北京某高校地铁实训平台的实际数据来验证本文所建立的ISOA-LS-SVM地铁站通风空调系统能耗预测模型的准确性。实际通风空调系统如图2所示。 图2 通风空调系统实际图 地铁实训平台由风系统和水系统组成,通风系统的主要设备包括组合式空调机组2台,组合式空调机组内包含风机1台,额定功率3 kw,8排表冷器1个,板式初效过滤器1个,风阀1个。水系统主要设备包括冷水机组2台,一用一备,额定功率8.81 kw;冷冻水泵3台,一用两备,额定功率3 kw;冷却水泵2台,一用一备,额定功率5 kw;冷却塔1台,额定功率1.5 kw。 数据采集系统由西门子PLC200和DUT4000数据采集模块共同完成。采样间隔为10 s,一次采集18个变量进行监控,表1为18个变量的名称。 表1 数据采集的监控变量 为了验证本文提出的基于ISOA-LS-SVM地铁站通风空调系统能耗预测模型的准确性和实用性,将本文所提算法与使用高斯隶属函数的SOA优化LS-SVM(GSOA-LS-SVM)、SOA优化LS-SVM(SOA-LS-SVM)、粒子群优化LS-SVM(PSO-LS-SVM)和传统的网格搜索优化LS-SVM作对比。以实训平台采集的数据作为模型的学习训练样本和测试样本。 本实验的时间为2016年空调季的7月9日至8月12日,实际实验时间共35天,每天早8:00~晚19:00。将样本间隔为30 min,共840组数据。再将每组建模数据的输入与输出间隔半个小时,则实际数据可以组成839个样本。为了得到验证建模方法的有效数据,回风温度设定值范围为[25,29]℃,送风温度设定值范围为[13,20]℃,步长取0.5℃。 对送回风温度每小时进行交叉组合设置,进行实际实验并及时导出实验数据。 具体方案为:将实际采得的839个数据的5/6作为建模训练样本,1/6的数据作为模型测试样本,进行ISOA-LS-SVM系统建模算法验证。其中优化算法中的初始参数在表2中说明。 表2 优化算法参数说明 4种算法建立的预测效果如图3~图7所示,经过4种算法的建模比较,不论使用哪种优化算法,都可以使LS-SVM进行很好的拟合和预测。 但是每种优化算法的性能却不同,从图8(a)中可以看出,PSO迭代次数最多,SOA迭代的次数次之,ISOA和GSOA的迭代次数最少并且预测误差最小,精度最高。因此本文从测试的平均相对误差、测试的均方根误差、运行时间、迭代次数和优化后的参数值这几个方面对4种优化方法进行评判。详细的性能指标如表3所示。 表3 ISOA-LS-SVM建模性能指标 图3 ISOA-LS-SVM训练对比图 图4 ISOA-LS-SVM测试效果对比图 图5 PSO-LS-SVM测试效果对比图 图6 SOA-LS-SVM测试效果对比图 图7 GSOA-LS-SVM测试效果对比图 (a) 适应度变化曲线 (b) 惩罚系数的优化曲线 (c) 核参数的优化曲线图8 优化曲线 表3中的MAPE为测试的平均相对误差,MSE为测试的均方根误差。从表3中可以明显看出基于网格搜索算法优化的LS-SVM的空调能耗建模方法预测误差1.06%,但是建模的过程耗时396.77 s,同时暴露出LS-SVM针对数据量较大时的缺点,计算精确但是耗时较长;PSO-LS-SVM的预测误差0.93%,较传统的LS-SVM不仅在预测精度上有所提升,而且在速度也有提升,但是耗时较长,达到了275.99 s。SOA-LS-SVM的预测误差为0.855%,预测精度和速度相对于前2种方法都有所提升,并且迭代次数较PSO减少了许多,只是速度相对于PSO来说提升的不高,这是因为在SOA中每次迭代计算过程中搜索向量的计算量较大。相比于使用性隶属函数,使用高斯隶属函数的SOA,性能更好一些,迭代次数仅为4步,而本文提出的ISOA相对于前面4种优化算法,不仅在精度上更胜一筹,而且在计算速度上远远超过前面4种算法。 因此本文提出的ISOA-LS-SVM模型能很好地反映地铁站空调系统的能耗特性,同时该模型参数根据人群搜索算法进行调整,提高模型的精度。实验结果表明ISOA-LS-SVM能耗模型具有较好的预测能力和建模速度。 本文针对建立地铁站空调系统能耗预测模型的问题,提出了ISOA-LS-SVM建模的方法。改进的人群搜索算法计算速度快、迭代次数少,能够更好地实现在线建模。改进后的人群搜索算法优化LS-SVM参数,提高了建模拟合精度。该算法应用到地铁实训平台,与其他优化算法相比建模速度和拟合精度都有所提高,为空调系统预测模型的建立提供了新思路,提升了空调系统节能的空间。
2.2 ISOA算法
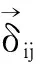
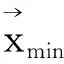
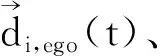
3 ISOA-LS-SVM的空调能耗预测模型
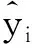
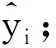
4 应用研究及结果分析
4.1 试验平台简介

4.2 实验设计

5 结束语
