基于Fg-CarNet的车辆型号精细分类研究
2018-11-01余烨金强傅云翔路强
余烨 金强 傅云翔 路强
车牌、车标、车型等车辆特征识别是智能交通领域的重要研究分支,在违法犯罪车辆跟踪[1]、交通流量统计[2]、收费站自动收费等方面发挥着重要的作用.由于盗牌、无牌、污损车牌车辆的存在,使得车牌识别不能发挥应有的作用.车标所占比例过小,用于描述车标特征的像素有限,且实际卡口监控系统中的车标定位是一个尚无成熟解决方案的难题,此外,车标也容易被替换、污损,因此,车标可以作为车辆识别的辅助特征,而不是唯一特征.目前,车辆唯一不易被伪装的特征是“车型”,其发挥的作用不可小觑.车型识别为事故逃逸、套牌、假牌车辆等的发现和追踪提供辅助手段,为交通管理执法部门提供重要判断依据,因此具有巨大的研究价值和应用前景.
对车型的理解有两种,车辆类型和车辆型号,车辆类型一般包含客车、卡车、轿车等分类,车辆型号指车辆的具体款式,例如,轿车中的大众品牌,里面有帕萨特、途观等型号.车辆型号识别是一个典型的精细分类问题,其研究面临很大的挑战,这是因为:1)车辆型号种类繁多.当前路面上常见的车辆型号达1000多种以上,种类越多意味着分类难度越大.2)部分车辆型号区分度小.同一品牌中不同子型号的车辆存在外观差异度极小的情况,且不同品牌中两种子型号的车辆也存在外观极其相似的情况.差异度小意味着类间方差小,需要提取更深层次、更抽象的特征才能实现其分类.3)图像受环境干扰大.实际卡口监控系统中获取的车辆图像,由于受周围环境、天气、光照等影响,干扰较大,增加了车辆型号识别的难度.
传统基于手工设计的特征提取方式往往由于关注点片面、抽象能力不足,无法提取有区分度的特征对车辆型号进行描述.随着Hinton等[3]提出无监督逐层训练方法以来,为训练深层神经网络提供了思路,且随着近年来计算机硬件的发展,运算能力大大增加,使训练更深层次的神经网络成为可能,从而掀起了一股深度学习的热潮.卷积神经网络作为一种多层前馈深度学习模型,由于其可以直接以图像为输入,自动学习特征,从而避免了手工设计特征抽象能力、区分度不足的问题,在计算机视觉、图像处理等众多领域得到了广泛应用,如目标跟踪[4]、图像分类[5]、语义分割[6]和行为识别[7]等.
在车辆型号识别中,考虑到实际智能交通系统中获取的监控图像大部分是车辆正脸的照片,且车辆正脸部分是车辆最具有区分度的区域,因此,本文以车辆正脸照片为数据源,对车辆型号进行精细分类研究.
针对车辆正脸图像的特点进行分析,由于车辆正脸图像特征分布不均,尤其体现在上下两部分上,为避免相同卷积核操作对上下两部分特征提取粒度不同,以造成有用特征损失的问题,针对车辆型号的精细分类,设计了一种多分支多维度特征融合的卷积神经网络模型Fg-CarNet(Convolutional neural networks for car fine-grained classification,Fg-CarNet).Fg-CarNet具有如下特点:1)针对车辆正脸图像上下两部分设计不同的子网络,并对上层子网络单独设置辅助损失函数,使卷积神经网络能够在车脸图像不同区域提取不同的且具有区分度的特征.2)利用上下子网络中提取的不同特征的组合,以及多尺度卷积核特征的组合,进一步提高了卷积神经网络的识别准确率.3)网络中主要使用小尺寸卷积核来优化网络结构,同时加入全局均值池化的方法,使得网络在准确率提高的同时降低了网络参数的数量,从而降低了网络过拟合的风险,提高了网络的实用性.
1 相关工作
与车辆身份相关的识别工作主要分为三类:车辆类型、车辆品牌和车辆型号(如图1所示).三者的分类精度由粗到细,随着分类精细度的增加,分类的难度越来越大,实用性也越来越高.车辆类型识别即根据车辆的大小、形状特征,将其归为轿车、面包车、客车、卡车等类别,主要用于高速路口自动收费、违规车辆检测等.常用的识别方法有:1)基于视频中相邻几帧出现的车辆尺寸和线性特征,结合车道宽度,进行车辆类型的判断[8].2)基于车辆模型的先验知识,通过对各种环境下、各个角度、各种类型模型的匹配和参数调整来进行车辆类型的识别[9].3)使用特征描述子如GABOR[10]、Harris角点[11]和SIFT[12]等提取车辆特征(这里的车辆特征不仅包含视觉特征,也包含声音信号特征),并使用分类器如SVM[13]进行分类识别.4)使用卷积神经网络的方法自动学习车辆特征,并用于车辆类型的分类[14].由于不同类型车辆类间方差较大,且类型种类较少,现阶段对车辆类型的识别已取得了很好的效果,识别率最高可达96.1%[14].
车辆品牌识别又称车辆制造商识别,即判断车辆是大众、奥迪、起亚还是丰田.由于车辆标志是车辆品牌的唯一特征,因此目前车辆品牌主要基于车标的类型来进行判断.文献[15]提出使用增强SIFT特征对车标进行识别,在1200张属于10种车辆品牌的车标样本库上进行测试,平均识别率可达91%.实际监控系统中获取的车标图像受光照影响较大,为改善光照对车标识别的影响,文献[16]提出了一种点对特征对车标进行识别,在对20种车标进行识别时,最高平均识别率可达95.7%.然而,文献[16]并未对车标的定位进行研究.事实证明,大部分车标识别方法都对车标定位有较高依赖,定位好坏直接影响最后的识别结果.为避免这一问题,文献[17]提出使用多示例学习方法为每种品牌车辆找到最具有区分性的特征,可以是车灯、车标、车辆边缘部位特征或其组合,从而进行车辆品牌识别,在包含30种车辆品牌数据集上进行测试,识别率可以达到94.66%.

图1 车辆身份相关的识别工作Fig.1 Recognition related to vehicle identity
与车辆类型识别和品牌识别相比,车辆型号识别难度更大,这不仅因为车辆型号种类繁多,更是因为不同车辆型号之间差异度过小,即类间方差小,难以找到有区分性的特征.文献[18]提出了一种新的级联分类器集合方案,通过加入拒绝策略,尽量减少误分类样本带来的损失,提高了车型分类的准确率.文献[19]将车辆按照固定的网格进行划分,并对每个网格提取SURF特征点和HOG特征后训练弱分类器,最后用贝叶斯平均将这些弱分类器集成实现对车辆的分类,在29类车型上取得了99%的准确率.对于这种精细分类问题,部分方法通过寻找目标上具有区分度的细节部位来进行分类[20−22].文献[23]使用具有部位标定的车辆数据集训练DPM 模型来定位车辆的关键区域,再对每个区域提取特征后实现对车型的精细分类.由于二维图像所包含的信息有限,部分学者提出提取车辆的三维结构信息来辅助车辆的精细分类[24−25],利用车辆三维模型提供的车辆视角、车体各部位位置信息等,提高车辆精细分类的准确率.随着深度卷积神经网络在图像分类中的成功应用[5],人们开始尝试使用它来解决精细分类问题.在这类方法中,通常利用标定好的大量数据来训练一个深度卷积神经网络模型,基于此模型从输入图像中提取高度抽象且区分度高的特征,在网络的全连接层中将提取的特征连接成特征向量,然后用分类器对得到的特征向量进行分类.文献[26]在公布一个大型车辆数据集的基础上,针对卡口监控系统中拍摄的车辆正脸图像,使用 Alexnet[5]、Overfeat[27]和 GoogLeNet[28]等深度卷积神经网络(Convolutional neural network,CNN)模型对车辆型号的精细分类进行了研究.文献[29]提出了一种多任务训练网络的方法,将Softmax Loss和Triplet Loss共同作为训练目标,在同一CNN网络中进行训练,通过在损失函数中嵌入分级标签信息,确保不同等级的类内方差小于类间方差,从而提高了车辆型号精细分类的准确率.文献[30]将车型的精细识别问题视为一个逐步求精的过程,提出了一个由粗到精的卷积神经网络模型,通过融合整体的特征以及局部具有区分度区域的特征实现车辆型号的精细分类.
在利用深度卷积神经网络解决图像分类问题时,一个好的CNN模型提取的特征对提高分类效果起到了至关重要的作用.为提高识别效果,经典的卷积神经网络模型主要通过增加模型的深度和宽度来提取抽象程度更高的特征,如Alexnet、GoogLeNet和VGG-16[31]等.然而更深的网络意味着需要更多的计算资源和更多的样本来训练,会造成训练难度的增加,从而导致网络性能下降的问题.本文针对真实卡口场景下的车辆型号精细识别问题,利用车辆正脸图像特征分布的特点,设计了一个适用于车辆型号精细识别的模型Fg-CarNet,在使用较少网络权值的前提下,获得了较好的车型识别效果.
2 车辆精细分类卷积神经网络模型
2.1 Fg-CarNet模型结构
卷积神经网络是为识别二维形状而特殊设计的多层感知器[32].典型卷积神经网络的输入层为原始图像;隐层由卷积层和池化层组合交替排列组成,以减少网络的权值数量,降低计算量;为逐步建立网络空间和结构的不变性,在卷积层后增加激活函数层以提高网络的非线性抽象能力;将前面几层操作后获得的特征图在全连接层进行向量化,并将提取的特征映射为标签,根据标签进行物体类型的判断.
针对车辆正脸图像特征分布的特点,在基本卷积神经网络结构的基础上进行改进,考虑到车辆图像上下两部分特征的差异,设计了一种适用于车辆型号精细分类的卷积神经网络模型Fg-CarNet,其模型结构如图2所示,图中数字表示特征图的数量,即卷积核的数量,N表示网络最终输出的类别数.
Fg-CarNet的输入图像为分割出的车辆正脸图像,沿图像中线将其分割为上下两部分,分别使用两段不同的分支网络UpNet和DownNet提取上下两部分的特征,然后用特征融合网络FusionNet对UpNet和DownNet中提取的特征进行多维度融合,进一步进行抽象并控制最终得到的特征规模,最后利用全局均值池化代替传统的全连接层,利用分类器得到网络的输出.
UpNet是为了提取车辆图像上半部分粗轮廓特征而设计的一个浅层分支网络.它由四个卷积层组成,每个卷积层后都紧跟着一个ReLU[5]激活函数层、一个Batch Normalize[33]层和一个最大值池化层.ReLU激活函数层进行特征映射;Batch Normalize层对输出的结果进行规范化,以加速网络的收敛;最大池化层则实现对特征的降维.本文将卷积层、激活函数层、Batch Normalize层和最大值池化层四层连在一起的结构定义为一个网络的基本单元,则UpNet由4个这样的基本单元组成.
DownNet是针对车辆下半部分图像设计的深层子网络,是UpNet结构的扩展,由于车辆图像下半部分纹理特征密集,包含更多有区分度的信息,是车辆型号精细分类的关键特征所在,因此,DownNet在UpNet四个基本单元的卷积层后增加了一层卷积核大小为1×1的卷积层,在深层次卷积层对浅层次卷积层学习到的特征进行整合前,对浅层次的特征进行进一步的抽象,提高了网络的表达能力.
FusionNet首先将UpNet和DownNet第一个基本单元和最后一个基本单元提取的特征图进行上下组合,得到两组完整的车辆特征图,如图2中上部虚框线所示.针对第一个基本单元的合并特征图,使用一个基本单元进行特征提取,对应FusionNet中的第二层.此基本单元卷积核尺寸和步长与UpNet中使用的卷积核尺寸和步长不同,详见表1.将FusionNet第二层得到的特征图和UpNet、DownNet中第四个基本单元组合得到的特征图叠加在一起,如图2中下部虚框线所示,再用一个基本单元对融合的特征图学习进一步特征提取,并用两个1×1卷积层进行进一步的特征抽象和降维,最后利用全局均值池化得到最后的分类特征.

图2 Fg-CarNet网络结构示意图Fig.2 Network structure diagram of the Fg-CarNet
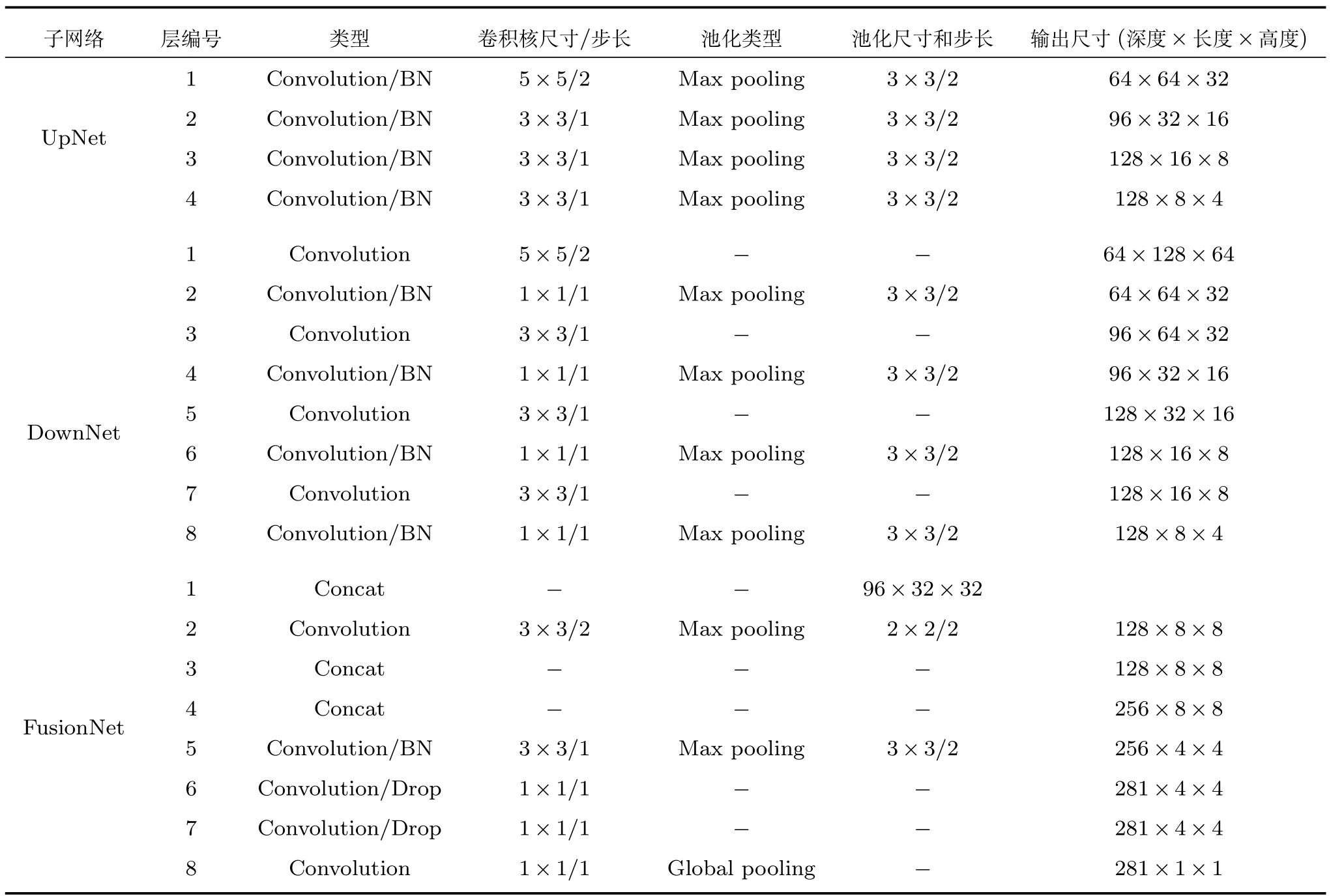
表1 Fg-CarNet模型结构参数Table 1 Structural parameters of the Fg-CarNet
Fg-CarNet网络的具体参数设置如表1所示,Convolution表示单独的卷积层,Convolution/BN表示一个卷积层加一个BatchNormalize层,Convolution/Drop表示一个卷积层加一个Drop层,此外,每个卷积层后都有一个ReLU激活函数(表1中未明确列出).FusionNet中第一层的Concat层,输入为UpNet中第一层与DownNet中第二层输出特征图,融合方式为对应层上下组合;FusionNet中第三层的Concat层,输入为UpNet中第四层和DownNet中第八层输出特征图,融合方式为对应层上下组合;FusionNet中第四层的Concat层,其输入为FusionNet中第二层卷积层和第三层Cancat层输出特征图,融合方式为特征层叠加.
2.2 分块特征提取
实际卡口监控系统中,摄像头通常位于车辆上方,斜向下对迎面而来的车辆进行拍摄.被拍摄到的车辆部位从下到上依次包括车脸(车大灯、车标、雾灯、散热器格栅和车牌)、引擎盖、挡风玻璃和部分车顶,形成车辆正脸图像.车脸是车辆特征最密集,最具有区分度的部位,具有丰富的纹理、形状特征,通常位于正脸图像下方.车辆正脸图像中除车脸外的其他部位也提供了丰富的轮廓、形状和位置信息,这些特征可以作为车脸特征的一个补充.
将车辆正脸图像分为上下两部分,则上下两部分的特征存在如下关系:
1)下半部分的车脸所包含的特征多且细,区分度高,纹理特征密集,车灯、隔热栅等形状特征明显.而上半部分的图像以车辆挡风玻璃、车顶等为主,主要体现为轮廓特征,以及一些能反映细节的位置信息,纹理特征不明显.
2)在夜晚及一些特殊环境中,车辆正脸上下两部分所处的光环境也存在较大差异,且下半部分的车牌、散热器格栅、大灯及车标等通常使用特殊的材质,对光的反射也与车辆上半部分差距较大,这使得上下两部分在成像时存在亮度差异,导致了上下两部分特征的区别.
如果使用卷积神经网络模型直接对整幅车辆正脸图像进行训练,则在训练过程中,卷积核会偏向于提取更有区分度的车脸部分特征来降低损失函数的值,最终学习到的网络权重使网络中的神经元对车辆正脸图像的上下两部分激活不平衡,导致上部分图像的特征提取不足,甚至丢弃,整体学习到的特征区分度不足,从而降低准确率.
图3是利用车辆正脸图像训练AlexNet、Goog-LeNet和本文提出的Fg-CarNet网络模型后,分别用白天和夜晚的两张图像作为输入,将正向传播过程中卷积层的激活值进行可视化的结果.为确保可视化结果具有对比性,这里均选择三个网络结构中,经过一次特征提取和映射且输出大小相近的层进行可视化,分别为:Alexnet的第一个卷积层、GoogLeNet的第一个池化层和Fg-CarNet中两个子网络的第一个池化层.分别提取上述层中特征图的前16张,分为上下两部分进行可视化.
图3最左边一列为白天和夜晚的2张输入图像,右边3列分别为不同网络模型提取的特征图可视化结果,图像中灰度值越高,越亮的部分表明神经元的激活程度越高.从整体上看,夜间车辆图像在神经网络中传播时,神经元的激活度明显低于白天的车辆图像.从单张图像在某个模型中提取的特征图来看,车脸部分对应的神经元激活度明显高于车正脸上半部分对应的神经元,这也证明了前文所述的观点:车正脸具有上下两部分特征分布不均匀的特点.从同一张图像在不同神经网络模型中提取的特征图可以看出,AlexNet中神经元的激活度明显低于另外两种模型,特别是车正脸上半部分对应的神经元,大部分都处于激活度低或没有被激活的状态;GoogLeNet中车脸部位对应神经元的激活度较AlexNet有明显提高,但对于夜间车脸上半部分图像,其神经元的激活度依然较低;而Fg-CarNet由于是对上下两部分分开处理的,所以车脸上半部分图像也能提取出有效的特征,即使是在夜间,也能保证神经元有较高的激活度.针对此类特征分布具有明显空间结构且各部分特征粗细粒度不同的分类问题,一个好的特征提取器需要能够统筹兼顾,将各种有用的信息聚合起来构成最终特征.鉴于此,我们采用了分块特征提取的策略,即针对车辆图像的上下两部分,分别构建分支网络UpNet和DownNet,用于对上下两部分的特征分别进行提取.为在特征丰富的车脸部分提取更具区分度的特征,DownNet使用了比UpNet更长的网络.在训练阶段,对UpNet添加了额外的辅助loss,强制UpNet能学到更具区分度的特征,使得网络能够从车脸上半部分图像中提取到足够丰富的特征.如图3最右边一列图像所示,与AlexNet和GoogLeNet相比,本文提出的Fg-CarNet较好地改善了对车正脸上半部分特征提取的结果,即使是在夜间,车正脸上半部分对应的神经元依然有很好的激活度.值得注意的是,图3中,AlexNet和GoogLeNet在同一车辆正面图像上下两部分进行特征可视化时,使用的是同样的一组卷积核,而本文的Fg-CarNet由于设计了两个子网络分别提取车辆图像的上下两部分特征,所以各自用的卷积核是不同的.

图3 三类神经网络模型中层激活值可视化图Fig.3 Visualization of the layer activations in three neural network models
2.3 多维度特征融合
2.3.1 上下子特征融合
如前所述,为对卡口车辆正脸图像上下两部分分别提取不同的特征,训练阶段Fg-CarNet学习了两个分支网络对其进行特征提取,之后会将两个分支提取的特征合并为一个整体作为车辆的特征.设训练过程中某次正向传播UpNet得到的特征维度为N×C×Hup×W,DownNet得到的特征维度为N×C×Hdown×W,其中N表示每次训练的batch_size,C表示通道数,即特征图的个数,Hup,Hdown表示得到的特征图的高度,W表示得到的特征矩阵的宽度,则合并后的特征维度为N×C×(Hup+Hdown)×W,此处不仅是特征维度的增加,由于上下两层采用了不同的卷积核提取特征,因此,此处更是一种特征的组合.如图4所示,传统卷积神经网络在正向传播过程中,会将前一层卷积层产生结果的全部或部分作为输入,而在Fg-CarNet中,UpNet和DownNet提取的特征之间可以有多种组合方式,设UpNet的特征图数量为Nu,DownNet的特征图数量为Nd,则可获得的组合数为Nu×Nd.通过固定数量的卷积核得到多种组合的完整特征图,提高了特征的利用率.针对车辆型号精细识别,这种组合方式可以将高激活度的车辆上半部分特征图与车辆下半部分特征图进行组合,使得整个车辆特征图上的激活值都处于较高状态.
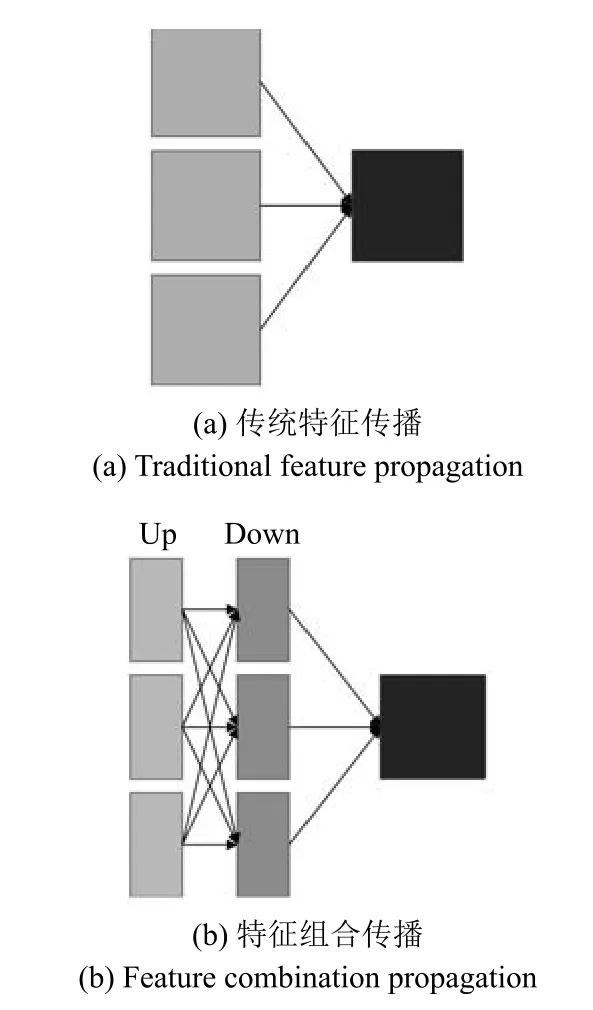
图4 层之间特征传播方式示意图Fig.4 Feature propagation between layers
2.3.2 多尺度卷积特征融合
传统CNN网络结构通常在每一层设置相同尺寸的卷积核,对输入进行计算后得到输出并向下一层传递.不同于这种结构,本文对上下两个子网络提取的特征分别进行了低层(靠近输入层的层)和高层(靠近输出层的层)的融合,即在第2.3.1节上下子特征融合的基础上,针对低层融合后的特征,使用一层具有较大卷积核的卷积层进行一次特征提取和降维,并将得到的特征再次与高层融合后的特征进行叠加,共同作为后面层的输入.
多尺度卷积特征融合(如图5所示)的优点可以从两方面来分析:1)Fg-CarNet网络结构使用不同尺寸的卷积核进行特征提取,对同一输入,一方面使用小尺寸的卷积核,逐层进行特征提取和映射,进行细粒度特征的提取;另一方面,使用大尺寸的卷积核,直接进行粗粒度特征的提取,保留更多的车辆轮廓信息.粗粒度和细粒度特征的融合,从不同尺度尽可能的保留了车辆正脸图像的特征,提高了网络的特征表达能力.2)如图5中Loss标注线所示,在训练网络的过程中,训练误差可以从多个分支反向传播回低层卷积层,优化了信息的流动,可以有效避免因网络过深产生的梯度消散,及导致低层卷积层得不到很好训练的问题.
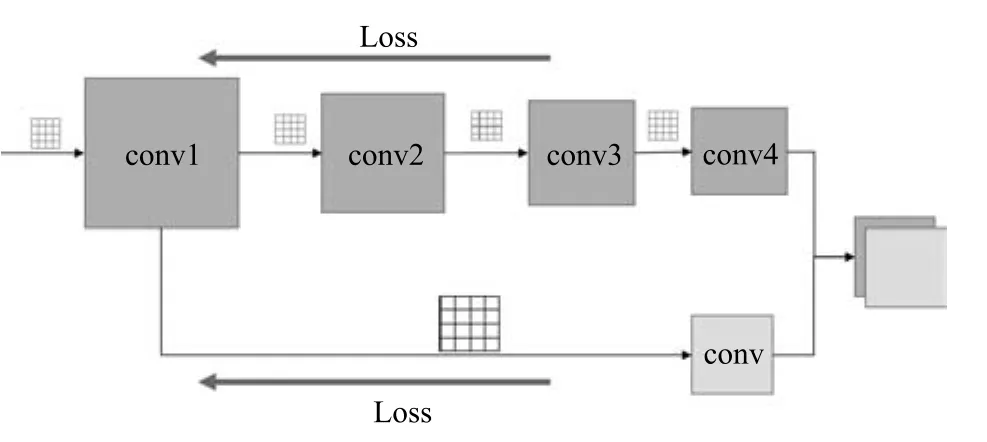
图5 多尺度卷积特征融合Fig.5 Multiscale convolution feature fusion
3 实验结果与分析
3.1 实验数据集
为验证Fg-CarNet神经网络模型对卡口图像中车辆精细特征提取的有效性,本文在文献[26]提出的CompCars数据集上对模型提取的特征进行了分类测试.CompCars数据集是一个大规模的车辆数据集,包含来自互联网和实际卡口监控系统1716种型号的208826张车辆图像.Fg-CarNet神经网络模型主要针对卡口拍摄车辆正面图像进行车辆型号的精细特征提取,故使用了CompCars中的卡口监控数据集进行测试,这部分覆盖了夜晚、雨天和雾天等复杂环境下共281个型号的44481张车辆图像,其部分样例如图6所示.本文使用其中的70%作为训练集,其他的30%作为测试集.

图6 CompCars中监控数据集样例Fig.6 Sample images of the surveillance data in CompCars
3.2 实验环境及设置
实验的硬件环境如下:CPU为Intel Core i7-6700K;内存为32GB;显卡为Nvidia GTX TITAN X;显存为12GB.实验所有模型均在开源框架CAFFE[34]下实现,CUDA版本为8.0.
在对UpNet和DownNet中基本单元提取特征进行融合的阶段,要求两个网络产生的特征图相互匹配,因此Fg-CarNet采用的输入尺寸为256×256,使其更易于控制网络传播过程中特征图的尺寸,便于网络的设计.而实验用到的其他网络皆按网络原有的要求输入为224×224.在训练和测试阶段,各网络都对输入数据按照文献[5]中方法做了除尺寸外相同的预处理,例如:在训练Fg-CarNet网络时,首先将数据集中所有样本的大小归一化为290×290,分别获得图像中心和四个拐角处共5张大小为256×256的图像,再对获得的图像进行镜像操作,获得其水平翻转后的图像,由此,基于每个样本可以获得10张训练图像.最后,所有图像均减去整个数据集的均值.测试阶段仅通过裁剪获得图像中心大小为256的图像,并减去图像均值.实验所用网络模型的优化策略均为带有动量的分块随机梯度下降方法,其中动量设置为0.9,batch-size设置为128,初始学习率设置为0.001.采用分步降低的策略,每100k次迭代降低10倍,训练阶段共迭代300k次,故整个训练阶段学习率降低两次.在测试阶段,本文同样对测试样本进行扩增,截取图像中心和四个拐角处共5张大小为256×256的图像,再对获得的图像进行镜像操作,获得其水平翻转后的图像,对扩增后的10个样本分别求置信度后取平均作为最后的结果.
3.3 Fg-CarNet在CompCars上的性能评估
表2显示了使用本文提出的Fg-CarNet深度卷积神经网络模型以及经典的AlexNet,GoogLeNet和Network in network[35](NIN)深度神经网络模型在CompCars数据集上提取车辆特征,并使用朴素贝叶斯分类器、KNN分类器、逻辑回归分类器、随机森林分类器、SVM分类器和Softmax分类器对车辆进行分类的结果.从表2可以看出,AlexNet和NIN网络模型提取的特征在车辆精细识别方面的识别率较低,GoogLeNet提取特征的表现则要高很多,而本文提出的Fg-CarNet模型提取的特征,除了使用随机森林分类器外,使用其他分类器的准确率都要高于GoogLeNet,达到了98%以上.总体上看,Fg-CarNet的识别准确率是最高的.从分类器效果上来分析,Softmax分类器在各网络模型提取特征上的分类效果都是最好的.
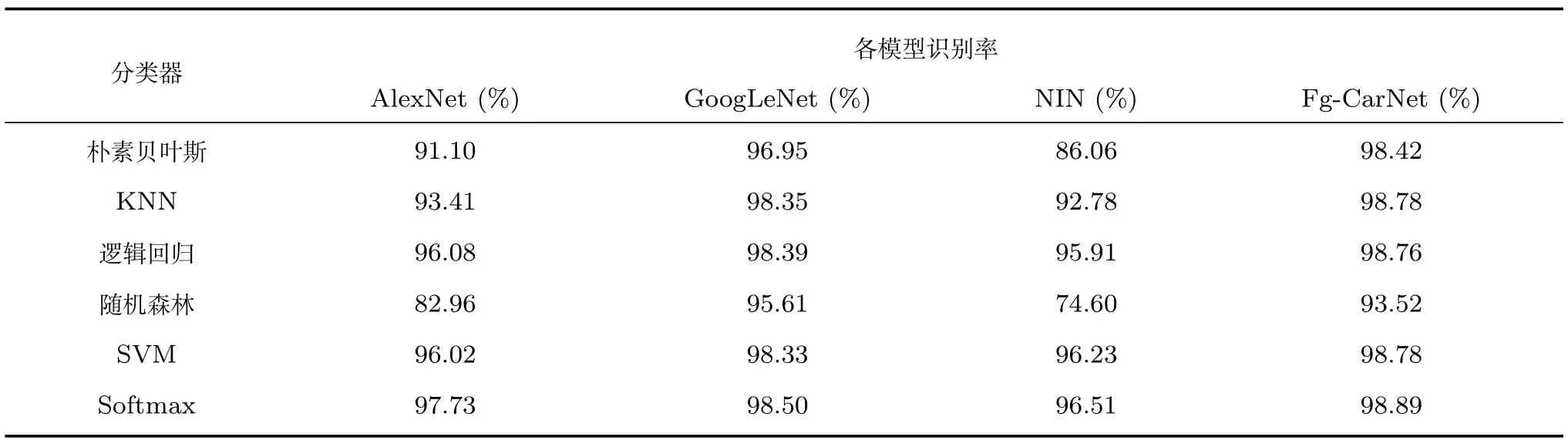
表2 卷积神经网络模型在CompCars上使用不同分类器的识别率Table 2 Recognition rate of different CNN models using different classifiers on CompCars
卷积神经网络中参数的数量反映了模型的拟合能力,参数越多越容易过拟合,泛化能力也越差,此外,参数越多需要的内存也越多,网络的适用性会降低.使用CAFFE框架训练卷积神经网络后生成一个保存网络结构参数的文件,表3以CAFFE生成的模型参数文件大小来反映各个网络的参数规模,从表3可以看出,Fg-CarNet模型的参数数量远低于其他三种模型,与AlexNet相比,参数数量下降了近40倍;与性能表现相近的GoogLeNet相比,参数数量减少了近6倍;与同样采用了全局均值池化的Network in Network模型相比,参数规模也降低了1倍,然而性能却得到了大大提升.

表3 各神经网络模型参数的大小Table 3 The size of each CNN model parameters
3.4 与其他车型分类算法的比较
针对真实卡口拍摄车辆正脸图像的精细分类,与其他针对多视角的车型分类方法有所不同,分类性能也有所差异,因此本文仅与针对卡口图像中车辆正脸图像进行精细分类的相关工作进行比较,比较结果如表4所示.由于CompCars监控数据集中,属于各类别车型的图像数量差距较大,最少的仅14张,而最多的可达565张,为避免会忽略样本数量少的类别中识别率不佳的情况,采用文献[30]建议的用两种评估方式分别对实验结果进行评估.各自的计算公式如下:

其中,ti为每类中正确预测的样本的数量,ni为每类样本的数量,N为样本的类别数.
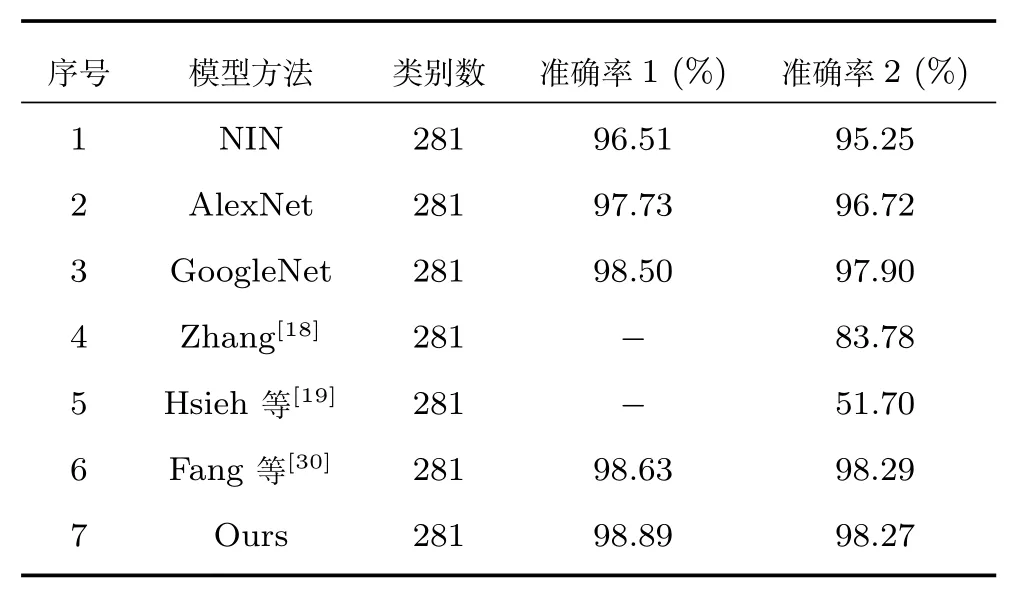
表4 相关工作的识别结果Table 4 Report results of some related works
表4中,第1~3行是采用经典卷积神经网络对CompCars监控数据集进行分类的结果,从中可以看出,GoogLeNet的识别结果最好,其准确率1达到了98.5%,准确率2达到了97.9%.第4~6行是与文献[18−19,30]中车型分类算法在CompCars监控数据集上分类性能的比较,其中,文献[18−19]的实验结果均来自文献[30].为了实验的公平性,文献[30]在CompCars监控数据集上复现了文献[18−19]的实验,实验结果表明,其所提方法在大规模车辆型号精细分类问题上性能不佳.文献[30]提出的方法在CompCars监控数据集上取得了较高的准确率,准确率1达到了98.63%,准确率2达到了98.29%.本文提出的方法与文献[30]方法相比,准确率1更高,准确率2基本持平,说明本文方法在准确率方面优于文献[30]方法.此外,本文提出的Fg-CarNet模型是一个端到端的模型,可以直接快速地实现车辆型号的精细分类,而且由于使用了全局均值池化,大大降低了网络中参数的数量,提高了网络的可使用性.
3.5 分块融合的性能评估
第2.2节指出,对车辆正脸图像分成上下两部分进行特征提取,可以强制特征不明显的上半部分区域也提取出有助于车型分类的特征,并与下半部分区域提取的特征进行融合,以提高车辆型号精细分类的准确率.为验证将车辆正脸图像分成两部分进行特征提取对车型识别带来的影响,本文设计了一组对比实验,实验结果如表5所示.Fg-CarNet-Up和Fg-CarNet-Down分别为以卡口车辆正脸图像的上半部分和下半部分作为输入的网络.为了保证公平性,减少因为网络深度带来的影响,Fg-CarNet-Up和Fg-CarNet-Down分别由Fg-CarNet网络中的FusionNet删除融合部分,保留基本的特征提取部分后与UpNet和DownNet相连接后获得.从实验结果可以看出,仅使用车辆的上半部分正脸图像,准确率1为93.37%,准确率2为89.78%.而仅使用特征更丰富的车辆下半部分正脸图像,准确率1达到了97.38%,但其准确率2较准确率1下降较多,这是因为当用Fg-CarNet-Down进行分类时,存在样本较少的类别其准确率较低,从而导致了准确率2的降低.整体上,Fg-CarNet-Up的准确率均低于Fg-CarNet-Down的准确率,这也证明了本文的观点,即车辆上半部分正脸图像具有一定的区分性,但特征不及下半部分正脸图像明显.Fg-CarNet-Whole与Fg-CarNet-Down模型结构相同,但Fg-CarNet-Whole是以整张车辆正脸图像作为输入,准确率1的结果达到了98.02%,准确率2的结果达到了97.84%,与单独使用上半部分或下半部分图像进行车型分类相比,准确率得到了明显提高.而Fg-CarNet由于对上下两部分单独采用不同的子网络进行特征提取,并将各自提取的特征进行多维度融合,增强了网络对车辆的特征描述能力,最终准确率1和准确率2与上述几种相比均有提高.
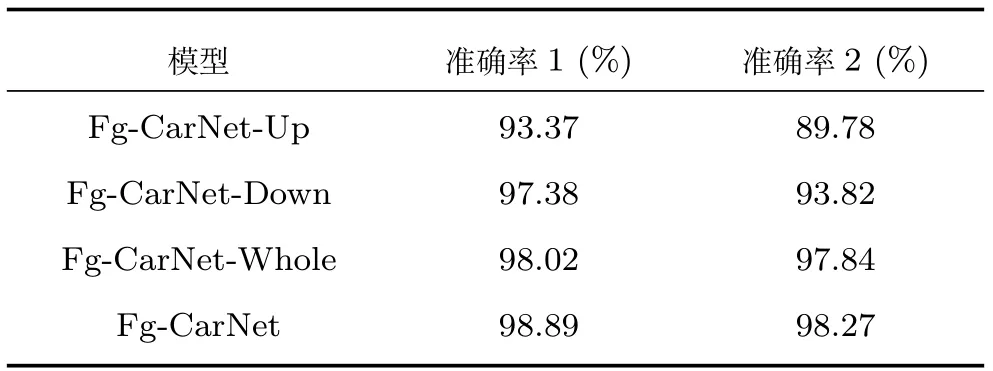
表5 分块融合的性能比较Table 5 Performance comparison of block fusion
3.6 网络特征的可视化分析
为进一步分析分块特征提取的效果,本文将GoogLeNet,AlexNet和Fg-CarNet基于Comp-Cars测试集提取的特征,使用t-SNE[36−37]方法降维到二维进行可视化,可视化结果如图7所示,图中一个点代表一个测试样本,同样灰度点表示同一类样本.由于通常卷积神经网络的最后一层是用于将特征映射到特定类别,因此此处我们选择最后一层的前一层所提取特征进行可视化.图7(a)中,样本点整体呈现一种聚类趋势,但重叠度较高,如图中左下角部分,基本混杂在一起,这说明UpNet针对车辆上半部分图像学习到了可用于车型分类的特征,但区分程度不够;图7(b)中,各类样本能够较好地聚在一起,具有明显的区分界限,但类间距离不够大,这也证明了第2.2节所述,车辆正脸下半部分图像包含更多有区分度的特征,更有利于车型分类;从图7(c)中对AlexNet提取特征进行可视化的结果可以看出,虽然AlexNet提取的特征整体类间差距较大,但类内差距也很大,这并不有利于分类;图7(d)所示是对GoogLeNet提取特征进行可视化的结果,可以看出各类样本点被很好地区分开来,且同一类样本点紧凑的聚集在一起,然而类间差距依然不够大;而融合了UpNet和DownNet的Fg-CarNet提取的特征如图7(e)所示,各类区分明显,类间差较大,说明Fg-CarNet提取的车辆特征能够较好地将类与类之间区分开来,同时类内样本聚合度较高,能够实现较好的分类效果.
3.7 不同特征融合性能评估
在多尺度卷积特征融合阶段,不同层特征的组合可能会产生不同的分类结果,为对不同组合下的分类性能进行评估,分别对不同组合情况下的模型识别率进行测试,测试结果如表6所示.其中,单元编号对应UpNet和DownNet中四个基本单元的编号.从表6可以看出,不同组合下模型的识别率区别不大,第一和第四个基本单元特征图融合后的性能达到最优,为98.906%.模型7融合的参数最多,但分类性能并不是最优,融合了3个参数的模型4,5,6,其性能也没有模型1的性能高,这说明并非融合的特征越多,分类性能就越高.融合的特征越多,可能会导致特征冗余,且网络中的模型参数也会随之增多.
4 结论

图7 特征降维后可视化结果Fig.7 Visualization of features after dimension reduction

表6 不同基本单元特征组合下的识别结果Table 6 Recognition result based on different basic unit combinations
针对卡口图像中车辆型号精细分类问题进行研究,提出了Fg-CarNet深度卷积神经网络模型,以提取有区分度的特征,提高车辆型号精细分类的准确性.Fg-CarNet的主要特点是:1)采用分块并行的方式,分别用UpNet和DownNet两个分支网络对车正脸图像的上下两部分进行特征提取,提高特征提取的有效性;2)对提取的车正脸图像的上下两部分特征进行了两个维度的融合,提高了特征的表达能力;3)网络使用小卷积核及全局均值池化代替了传统的全连接网络实现特征向结果的映射,大大地降低了模型的参数规模.实验结果表明,本文提出的Fg-CarNet能够以较少的参数提取具有区分度的车辆精细特征,在分类性能上表现优异,具有实用价值.此外,本文提出的分区域特征提取和多维度特征融合的方法,对其他不同区域间关联度低物体的精细分类问题也提供了思路.
