基于迁移学习的语义推理网络
2018-10-31刘文洁孙承杰
刘文洁, 林 磊, 孙承杰
(哈尔滨工业大学 计算机科学与技术学院, 哈尔滨 150001)
引言
语义推理理解作为自然语言处理研究的基础任务,在很多领域中都有重要的应用,例如:问答领域、信息检索、指代消解等。语义推理理解任务一般包括2类信息:前提信息和推论信息。任务的目标是判断前提句和推论句之间的推理关系——蕴含、中立、矛盾。
语义推理理解主要分为2个阶段:语义向量表示和推理关系表示。其中,在语义向量表示方面,本文使用深度学习的方法将前提句和推论句表示成文本向量的形式,并且使用了注意力机制提升文本的语义向量表示。在推理关系表示方面,本文重点使用双线性函数来抽取不同文本之间的推理关系。为了使神经网络能够充分表达文本的语义向量信息,本文使用迁移学习将从大规模源语料中学习到的语义向量表示和推理关系表示应用在小规模任务的数据集当中。同时,本文还使用了集成模型,融合机器学习和深度学习的语义推理理解机制,取得了不错的效果。
1 国内外研究现状
在早期阶段,研究者大多使用机器学习的方法来进行语义推理理解。使用逻辑公式[1-2]进行语义推理是一种常用的方法。此外还有建立语法分析树、提取句子中需要对齐的单词信息等都是提取语义特征常用的方法。随着深度学习的发展和在自然语言处理方面的应用,研究者开始使用循环神经网络(RNN)[3-4]来求得语义向量表示。循环神经网络能够很好地处理自然语言当中的时序信息,但是容易出现梯度消失和梯度爆炸现象,导致神经网络无法训练。长短期神经网络(LSTM)[5]在循环神经网络的基础上增加了控制门—输入门、遗忘门、输出门,在一定程度上解决了这个问题。
注意力机制在自然语言处理当中的应用是将更多的权重放在重要的单词或者短语上,用以提高文本处理的准确率。Rocktäschel等人[6]将注意力机制应用在文本蕴含领域,增加前提句和推论句相关联单词的权重。Cui等人[7]将注意力机制应用在阅读理解领域,通过建立文档-问题矩阵,提高阅读理解的准确率。Liu等人[8]提出了自身的注意力机制,用来挖掘文本内单词之间的关联信息。
迁移学习(Transfer learning)[9]就是把已训练好的模型参数迁移到新的模型中来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型,从而加快并优化模型的学习效率,而无需类似大多数网络那样从零学习。微软[10]提出了2段式的迁移学习网络并成功应用在阅读理解领域中,旨在变换至一个新的领域中生成问题答案对。
2 基于注意力机制的语义推理网络
本文实现了基于注意力机制的语义推理网络。使用LSTM对前提句和推论句进行语义向量编码。为了获得更有效的前提信息,本文在进行前提句编码时,使用了注意力机制,融合文章的推论切入点信息,使得前提句中包含更多的语义特征。本文使用双线性来获取前提句和推论句的语义推理关系。由于本文使用的实验数据集数据量比较小,使用迁移学习让语义推理模型在大规模数据集中充分学习语义向量表示和语义推理关系表示。再将语义推理模型迁移到小数据集上展开训练。系统整体框架结构可如图1所示。
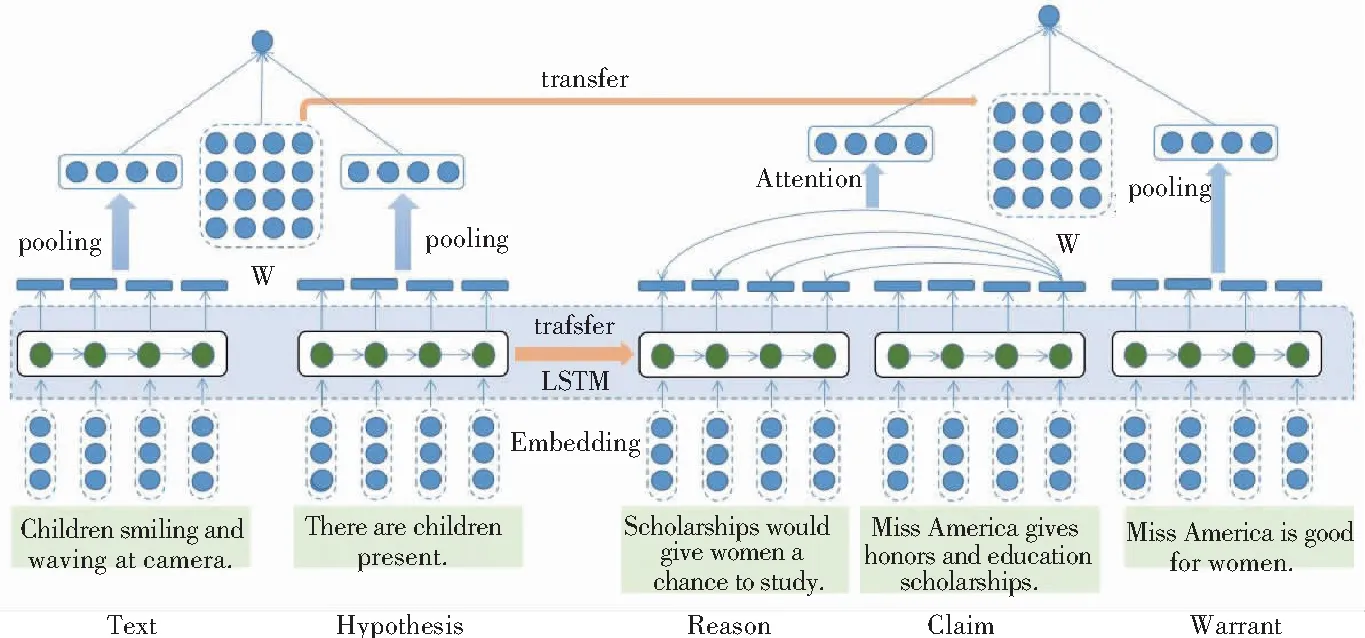
图1 基于注意力机制的语义推理网络
2.1 数据集介绍
本文使用SemEval 2018 Task 12 The Argument Reasoning Comprehension Task[11]的数据集。数据格式可见表1。数据包含四元组——推论(Warrant0、Warrant1)、前提(Reason)、切入点(Claim)、标签(CorrectLabel),和2个额外信息——文章标题(DebateLable)、文章内容(DebateInfo)。数据集包含1 210对训练集、316对验证集和444对测试集。本文使用Stanford Natural Language Inference(SNLI)[12]数据集作为迁移学习的源任务。重点学习语义推理中的语义向量表示和推理关系表示。
2.2 基于注意力机制的语义向量表示
研究中使用LSTM模型完成语义向量编码。输入是文本的单词序列T={t1,t2,…,tm},其中ti表示文本中第i个单词的词向量,m表示文本的长度。LSTM模型的输出信息为H={h1,h2,…,hm}。通常,将会对LSTM模型的输出信息进行平均池化或者最大池化处理来获得文本的向量表示。为了捕捉到更加丰富的语义向量,本次研究中使用了融合前提句和切入点信息的语义向量。将切入点句子的LSTM模型的最后一个时刻的输出作为其语义编码向量,与前提句LSTM模型每一时刻的输出做注意力机制的计算。计算结果为融合了前提句与切入点句子的语义向量编码。同样,将推论句输入到LSTM模型中,平均LSTM每一时刻的输出结果作为推论句子的语义编码向量。

表1 The Argument Reasoning Comprehension 数据集
2.3 基于双线性的推理关系表示
双线性可以计算2个文本向量的语义推理关系。其中,X∈Rm,Y∈Rm表示前提句和推论句的语义向量,双线性矩阵W∈Rm*m是抽取2个向量关系的参数矩阵。双线性的数学表述则如式(1)所示:
V=X·W·YT
(1)
本文使用双线性分别计算前提句与2个推论句之间的蕴含概率关系,选择蕴含概率较大的作为最终的答案。
2.4 迁移学习在语义推理网络中的应用
为了增强模型的语义向量表示和推理关系表示能力,本文使用了SNLI语料对任务模型进行了预训练。首先将前提句和推论句输入到LSTM模型当中,对LSTM模型的输出做池化处理获得前提句和推论句的语义向量表示。使用双线性函数获得前提句和推论句的推论关系表示。由于SNLI语料库规模比较大,使LSTM模型和双线性矩阵能够得到充分的训练。将LSTM模型和双线性矩阵迁移到目标任务当中,使得目标任务在开始训练时就具备一定的语义表示能力和语义推理能力。
3 基于模型融合的语义推理网络
基于模型融合的语义推理网络则引入了传统特征和深度学习模型,全方位、多角度地挖掘文本之间的语义推理关系。语义向量表示与之前相同,将文本的词向量输入到LSTM中,对输出结果做池化处理,获得文本的语义向量表示。传统特征就是提取了前提句和推论句单词的上下位关系、编辑距离、Jaccard距离等多种性能模式。集成模型使用拼接的方式融合传统特征和深度学习的特征,即将融合了前提句和切入点句子的注意力向量和推论句的文本向量进行拼接,再与传统特征实现拼接。最后将拼接的向量输入DNN网络进行分类处理。基于模型融合的语义推理网络如图2所示。
4 实验结果与分析
实验的损失函数使用均方误差MSE,数学运算公式如下:
(2)
评价指标使用准确率,具体如式(3)所示:
(3)
表2显示了ARC数据集的准确率。表格前三列为其它队伍模型取得的最好成绩,第四列为组织方使用随机选择取得的基线结果。研究对比了拼接、双线性和集成模型使用迁移学习和未使用迁移学习的实验结果。结果显示,使用了迁移学习模型的准确率要比未使用迁移学习模型的准确率高。双线性在语义推理关系上的表现效果比拼接要高出许多。使用了迁移学习的集成模型在测试集上的准确率基本与参赛队伍齐平,由此证明本文提出的模型是有效的。

图2 基于模型融合的语义推理网络
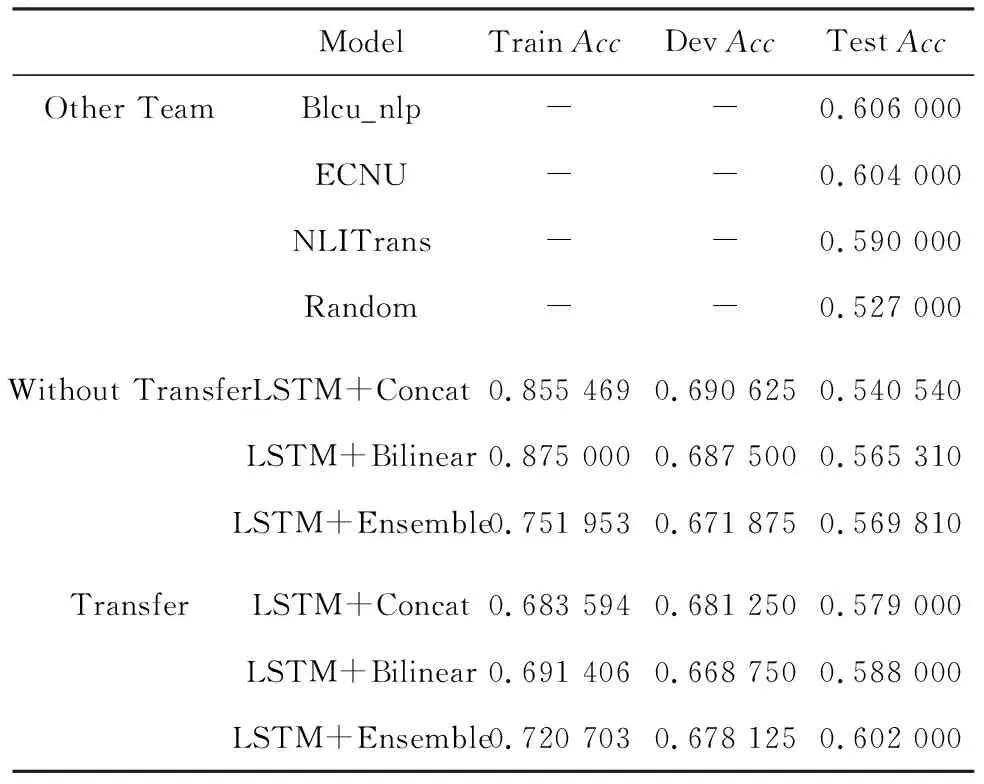
表2 ARC数据集的准确率
图3展示了语义推理任务的不同模型是否引进了迁移学习的拟合曲线。图中对比了使用LSTM模型、LSTM+Attention模型、应用了迁移学习的LSTM模型和应用了迁移学习的LSTM+Attention模型。从折线图中可以推得如下2点结论:
(1)由图3可以看出,如果模型没有使用迁移学习,在开始训练时,目标任务的准确率比使用了迁移学习模型的准确率要低很多。因为没有使用迁移学习的模型参数是随机初始化的,而引进了迁移学习模型的目标任务是部分使用了源任务训练好的目标参数。
(2)对比有无使用迁移学习的模型准确率,还可以看出使用了迁移学习的模型拟合曲线较为平缓,说明模型在最初找到了一个较好的初始化参数,在训练的过程中则仅仅只是需要微调模型有关参数。而未使用迁移学习的模型拟合曲线相对波动较大,分析原因可知是由于随机初始化了模型参数,使得模型在训练过程中需要不断调整参数降低损失,且调整幅度较大。

图3 迁移学习拟合过程对比曲线
5 结束语
本文主要实现了基于迁移学习的语义推理网络。研究中先后提出了2个模型,分别是:基于注意力机制的语义推理网络和基于模型融合的语义推理网络。其中,基于注意力机制的语义推理网络使用注意力机制融合前提句和其它信息,更好表示了前提句的语义向量。使用双线性函数充分挖掘前提信息和推论信息的语义推理关系。基于模型融合的语义推理网络集成了传统特征和深度学习的方法。通过实验结果可以看出,本文提出的2种模型均在ARC数据集上取得了良好效果。
