基于高光谱成像系统的纺织品成分定性鉴别
2018-10-30金肖克朱炜婧蒋晶晶祝成炎
金肖克, 田 伟, 朱炜婧, 蒋晶晶,,3, 祝成炎
(1.浙江理工大学 材料与纺织学院、丝绸学院, 浙江 杭州 310018; 2.浙江科技学院 艺术设计学院/服装学院, 浙江 杭州 310023; 3.国家纺织服装产品质量监督 检验中心(浙江桐乡), 浙江 嘉兴 314599)
目前,纺织品成分种类繁多,通常可分为纤维素类、蛋白质类、合成纤维类等。其中纤维素类纤维包括棉纤维、麻纤维等,蛋白质纤维包括蚕丝纤维、各种毛类纤维,而合成纤维类包括涤纶、锦纶、聚乙烯纤维等。目前日益增多的纺织品种类对纺织品成分鉴别的能力提出了更高的要求。此外,纺织品中各纤维成分的含量是其贸易价值的关键因素,关乎生产者、销售商和消费者的切身利益,而当前纺织贸易市场中存在的以次充好的现象则扰乱了市场规则和纺织行业的可持续发展,缺乏一种适用于在线快速检测纺织品成分鉴别方法也是导致上述问题存在的原因。
为对各类纺织品进行成分分类,传统的定性方法包括手感和视觉鉴定、燃烧法、显微镜观察法、化学试剂法,特别是傅里叶变换红外(FTIR)光谱分析方法等。不同的方法有各自的优点和缺点,如:手感和视觉鉴定是历史最为悠久的一种鉴别方法,但其鉴别精度较低;化学方法鉴别准确性较好,但若要实现鉴别需事先准备多种化学试剂,鉴别效率较低,不便于在线检测且对环境潜在危害较大;对目前在纺织品成分检测机构中最为常用的显微镜观察法,其通过观察纤维的微观结构能够实现纺织品的精确鉴别,但这是一种有损的鉴别方法,且其制样方式较为复杂,需要经过专业训练的检测人员才能实现。传统的FTIR光谱分析方法可以高精度地获得测试试样的平均光谱,且无须对试样进行破坏性处理,并通过所获得的光谱数据对纺织品的成分进行鉴别,但由于FTIR光谱仪的原理和结构的限制,每次只能测量1个样品,所获得的数据仅包含试样的光谱数据而不包括试样的任何空间信息,限制了其推广应用。
高光谱成像技术(Hyper Spectral Imaging,HSI)不同于传统的傅里叶变换光谱分析方法,其光谱数据被存储在所采集的高光谱图像的每一像素点中,因此同时保留了试样的空间信息和光谱信息。高光谱成像技术首先应用于遥感领域,在过去几十年间其应用逐渐扩展到食品科学[1]、农业[2]、医学[3]、历史文物保护[4]和法医[5]等多个领域。近年来的研究人员通过高光谱成像技术分别实现了建筑垃圾中的聚烯烃[6]、植物废料中的涤纶和聚乳酸纤维[7]、纸制品(如纸板、彩色纸板、报纸和打印纸)[8]和废塑料瓶[9]的在线分类。文献[10-12]利用高光谱成像仪采集与多种异物混杂的棉花的高光谱图像,以梳棉表面一些难检的异性纤维,梳棉内部不同深度的常见杂质(包括有色和透明的编织袋丝、有色塑料膜碎片、透明聚乙烯地膜、浅黄色麻丝、黑色和白色毛发、杂色羽毛、各色糖纸等)为研究对象,利用高光谱图像中的空间和光谱信息以及所建立的杂质检测的方法和算法实现棉花杂质检测,为棉花杂质在线分拣奠定研究基础。Mustafic则将高光谱成像仪同荧光光源相结合,分析了高光谱荧光成像技术在鉴别棉花中异物的可行性[13-14]。尽管高光谱成像技术在其他材料的分类鉴别中均得到大量应用,但其在纺织品成分分类中仅局限于杂质检测,关于使用高光谱成像技术以纺织品为对象进行成分定性鉴别的研究几乎没有,其在纺织品成分的定性鉴别中存在的潜力及应用价值并没有得到有效开发。
本文的主要目的是探讨通过高光谱成像技术在900~1 700 nm光谱波段范围内实现纺织品成分定性鉴别的可行性。通过对各类纺织品的原始光谱数据的分析,从理论角度分析了各光谱数据预处理方法的优劣,提出最优化的光谱数据预处理方法,建立了一个偏最小二乘法判别分析(partial least square discriminant analysis,PLS-DA)模型对纺织品成分鉴别并评估模型的预测效果,且提出了以高光谱成像系统对纺织品进行成分定性鉴别的完整的技术路线,为高光谱成像技术在纺织品成分鉴别领域的发展及应用提供参考和借鉴。
1 实验部分
1.1 试样准备
为测试基于高光谱成像系统进行纺织品成分定性鉴别的可行性,本文选择了棉、麻、蚕丝、毛(包括羊毛、羊绒、骆驼毛、牦牛、貉绒、羊驼毛和马海毛)、涤纶、丙纶、芳纶、锦纶、高强聚乙烯和聚乳酸纤维,涵盖了市面上较为常用的10类纺织纤维材料。为保证测试样本的多样性,所选择的试样包括机织物、针织物、纱线、纤维等,试样由浙江省纺织测试研究院提供。
为保证试样测试的准确性,本文将所有纱线试样及纤维试样卷绕于一载玻片(7.5 cm×2.5 cm)上。卷绕过程遵循以下原则:1)要尽量保证试样卷绕平整,如果不平整则会导致试样表面阴影增多,影响光谱数据的准确性;2)尽量卷绕紧密和不透光,如果被扫描的那一面不紧密会出现透光的情况,扫描时光线会透过缝隙采集到背景的光谱数据,从而影响数据的准确性。对织物试样而言,织物试样的折叠层数在难以保证光线不会透过试样的情况下会对所测得的光谱数据有一定影响,因此所有测试的织物试样均折叠2次,保证所测试织物试样层数起码达到4层以避免光线透过。
1.2 高光谱成像系统
本文所使用的高光谱成像系统(五铃光学股份有限公司)由高光谱成像仪(Imspector V17E光谱仪、Raptor EM285CL高感度CCD及f/1.9 35 mm镜头)、光源(Ocean Optics HL-2000线性光导管组)、光源控制器、相关软件(Spectral-image 取像软件和HIS Analyzer分析软件)、步进电动机传输装置和置物台组成,其光谱范围为890~1 728 nm。
由线性光导管组所发出的光线照射到样本表面,经过散射、吸收、反射的光线重新通过镜头进入高光谱成像仪中,并由高光谱成像仪中光谱仪的透射全息光栅所分光,不同频带的光强度经过转换成为准模拟信号,并存储于电荷耦合器件(CCD)中,传输装置带动置物台连续移动,从而获得完整连续的具有空间和光谱信息的高光谱图像,高光谱成像系统示意图如图1所示。
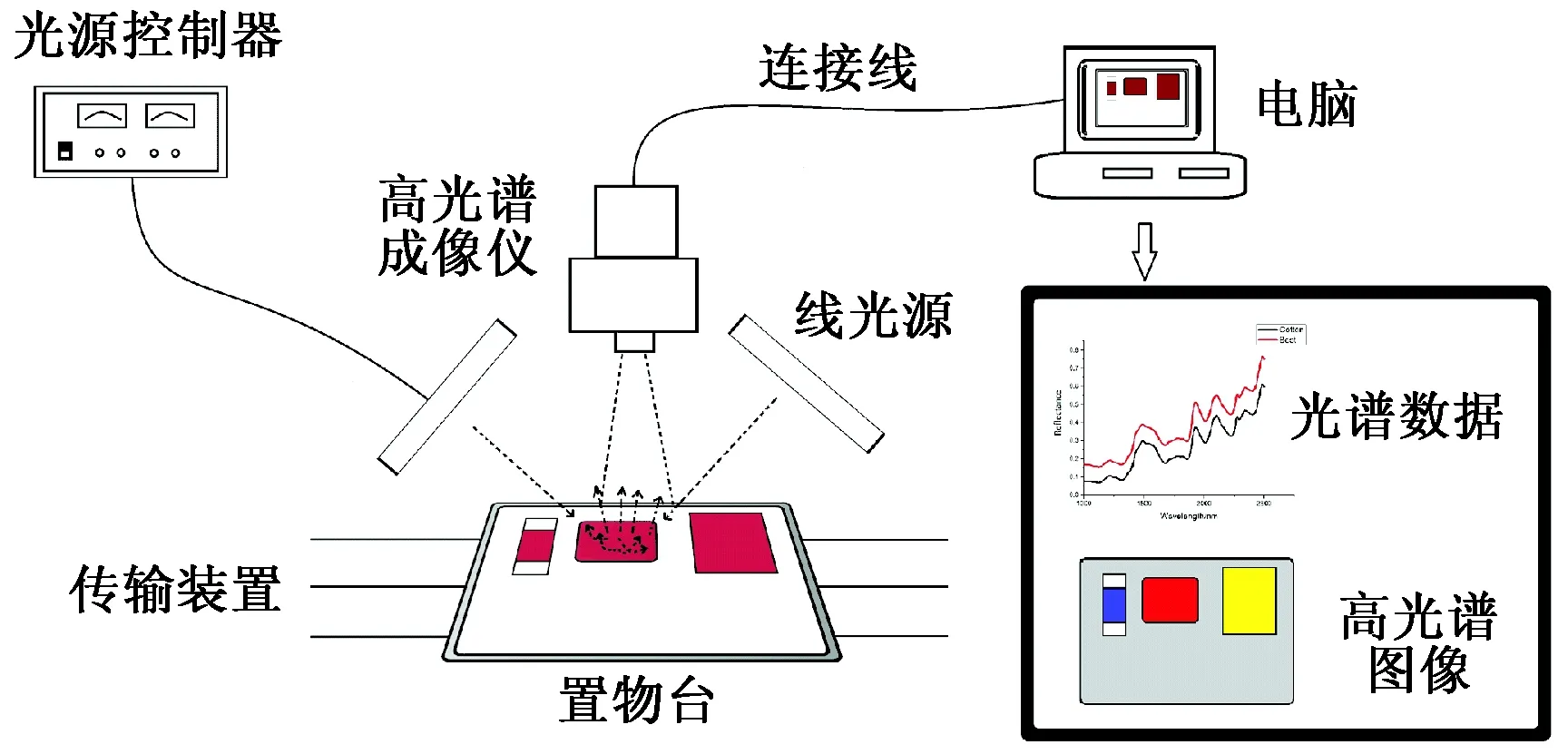
图1 高光谱成像系统示意图Fig.1 Schematic diagram of hyperspectral imaging system
1.3 高光谱图像采集与数据预处理
尽管通过后继的反射率校正可在一定程度上降低光照不均等因素对高光谱图像的影响,但是在外界光照条件差异极大的情况下,仅通过反射率校正仍难以保证高光谱图像的光谱数据能维持一致,因此本高光谱成像系统均放置于一附门的暗箱中,在高光谱图像采集的过程中需要保证暗箱门处于关闭状态,以保证照射在试样表面的光线仅由线性光导管组提供。线性光导管组由光源控制器控制,在正式进行高光谱图像采集前需提前10 min开启电源进行预热,从而保证采集过程中光源稳定。在开始纺织品试样的高光谱图像采集前,需要将标准校正白板放置在置物板上进行预采集以设定合适的采集参数(如前置镜头和试样间的距离、镜头对焦焦距、曝光时间、传输装置传输速度、光照强度等),使标准校正白板中的平均数字量化值(DN)接近于CCD存储最大DN值(4 096)的80%左右(3 200),通过交换式电源供应器来控制调整光照强度,在完成所有初始设置之后,采集白板高光谱图像。之后将白板移去,在置物台上放置待测试样,在相同的测试条件下,采集纺织品试样高光谱图像。
暗电流是流过光敏器件的微小电流,在物理上它是由设备耗尽区内的电子和空穴的随机运动引起的。高光谱成像仪中的图像传感器引起的暗电流噪声是一种固定模式噪声,需要通过暗电流校正处理来排除暗电流在高光谱图像中的存在,暗电流校正需要将原始图像的DN值减去暗电流图像的DN值。在仪器参数同纺织品试样高光谱图像采集相同的情况下,盖上镜头盖,采集高光谱图像,所采集的图像便包含了仪器暗电流信息的暗电流高光谱图像。
由于高光谱图像中的光谱数据是以DN值的形式存储于各像素点中,表示各像素点的光强度,因此受外界光照强度的影响较大,仅仅能在一定程度上代表试样信息,在外界测试条件不同的情况下,所得到的高光谱图像及光谱数据不具备泛化性和重复性,因此需要进行反射率校正,通过反射率校正将高光谱图像中的DN值转换为具备一定代表性的反射率值,该过程是定标的一种方式。
本文中所采用的反射率校正方法为平场域校正法(flat field correction)。通过该反射率校正方法不仅能够实现定标将DN转换为能够代表试样本身特性的反射率值,由于其校正是试样高光谱图像同白板高光谱图像之间相同坐标像素点间一一对应进行校正,因此其同时能够去除试样表面阴影、光源照射不均等因素对高光谱图像产生的负面影响。暗电流校正和反射率校正可通过下式计算
式中:R为校正图像的反射率;D为校正图像的DN值;Ddc为暗电流图像的DN值;Drf为校正白板图像的DN值;Rrf为校正白板的反射率。
由于试样的光谱数据是存在于高光谱图像的像素点中,需要使用ENVI(environment for visualizing images)软件提取经过暗电流校正和反射率校正的试样高光谱图像的光谱数据。通过ENVI打开高光谱图像,并用感兴趣区域(ROI)工具从图像中选取试样的区域,并对ROI区域内的所有像素点的光谱数据进行平均处理并导出,最终获得试样的光谱数据。通过平均ROI区域内的像素点的光谱数据能够进一步减少像素点光谱波动对试样光谱数据的影响,提高信噪比和数据准确性,由于高光谱成像系统在光谱范围边界的光谱数据信噪比较低,因此去除信噪比较低的波段的光谱数据,仅保留960~ 1 628 nm波段范围内的光谱数据进行后续分析研究。本文高光谱图像采集及光谱数据提取的流程如图2所示。

图2 高光谱图像采集及校正流程图Fig.2 Flow chart of hyperspectral image acquisition and calibration
2 结果与讨论
2.1 预处理方法研究
红外光谱来自分子振动(即分子拉伸和弯曲)吸收反映化合物本身结构的特定频率(或波长),化学键所连接的原子和邻近原子的类型是确定辐射吸收的关键因素。辐射吸收的频率(通常用于中红外光谱分析)或波长(通常用于近红外光谱分析)可直接与键和官能团存在联系。近红外区域中的吸收带是光谱中红外区域吸收带倍频和组合的结果。相关的化学键通常为R—H(即C—H,O—H,N—H,S—H)[15],因此,近红外范围的光谱特征可用来对纺织品成分定性分析,但该区域的光谱特征差异并没有中红外区域明显,因此需要光谱数据预处理算法以及分类模型实现鉴别。42个涤纶(PET)试样未经任何预处理的光谱曲线如图3所示。
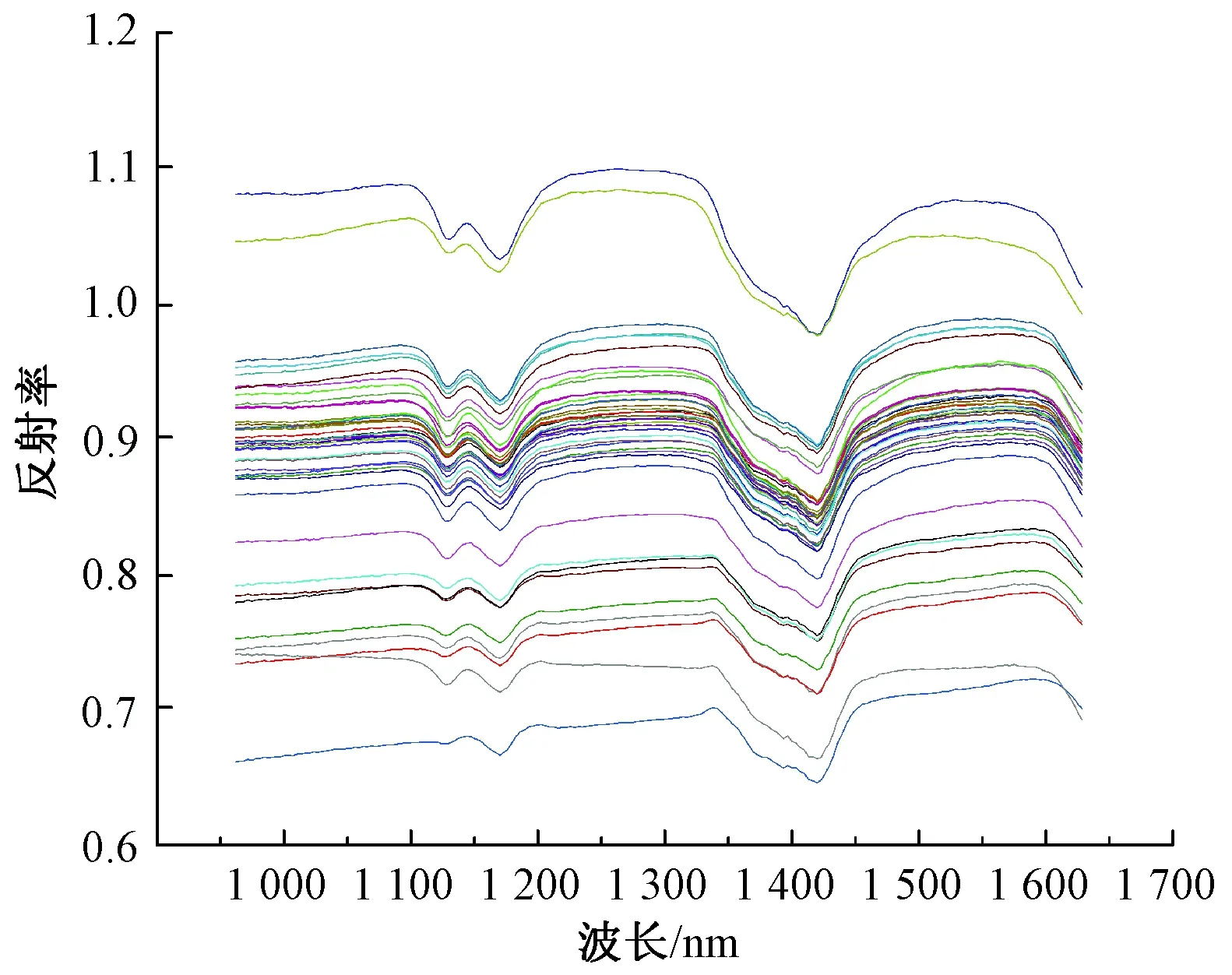
图3 涤纶试样的原始光谱曲线Fig.3 Raw spectral curves of PET samples
可以看出,尽管PET试样的特征峰位置没有变化,但不同试样之间的总体反射率强度存在差异,在红外光谱分析中,上述现象被称为基线漂移,通常由测试仓中探测头在试样之上压力不同所引起的。而在使用高光谱成像系统索取纺织品试样的光谱数据时,试样的颜色、包缠等加工工艺,纱线和纤维试样的卷绕层数、织物试样的折叠层数等因素均会对高光谱图像中所提取光谱数据的总体反射率强度产生影响[16],从而导致PET试样的反射率在0.65~1.1之间浮动。
除上述由纺织品形态、颜色等因素引起的基线漂移现象会对后续纺织品成分鉴别模型鉴别精度产生影响之外,所测试试样的光谱数据同样会无可避免地受到仪器参数、外界测试条件等因素的影响,从而导致信噪比低等问题,因此需要在利用光谱数据进行建模之前,对光谱数据进行预处理,去除同一类别试样间的光谱曲线漂移现象,其不仅仅有助于提高光谱的信噪比,还可实现原始光谱的数据挖掘,揭示其反应机制,此外更能提高所建立定性鉴别模型和定量鉴别模型的检测准确度和稳定性。基于上述原因,本文首先针对各类光谱数据预处理方法进行原理上的比较,以实现预处理方法的优选和改进。常用的预处理方法有归一化、标准正态变量变换(SNV)、多元散射校正(MSC)和一阶导数。
归一化是将数据映射到0~1范围之内的一种标准化方法,在数据挖掘和处理方面具有下列优点:提升模型的收敛速度,在某些情况下能大幅提高模型的运算效率,在纺织品成分的快速在线检测中有重要作用;提升模型的精度,特别是在涉及距离计算的算法时效果显著,而在纺织品成分定性分析模型中大部分依靠距离计算算法。常用的归一化算法为线性函数归一化、0均值归一化。SNV[17]同样也能实现数据的归一化处理,SNV常被用于去除光谱信号变异,在近红外光谱分析、拉曼光谱分析、激光诱导击穿光谱分析等领域内均运用。
多元散射校正是现阶段多波长定标建模常用的一种数据处理方法,用于消除试样表面光散射效应带来的负面影响,同时增强与试样成分相关的信息,不仅消除了试样光谱数据中存在的基线平移和偏移现象,同时提高数据的信噪比。其原理是首先需要建立一个待测样品的“理想光谱”,通过每个样品的光谱与理想光谱进行一元线性回归求得的线性平移量(回归常数)b和倾斜偏移量(回归系数)b0,实现试样光谱曲线的基线平移和偏移校正,实际应用中理想光谱几乎是不存在的,因此以同类试样的平均光谱(标准光谱)作为理想光谱[18]。经由多元散射校正处理的PET试样的光谱曲线如图4所示,多元散射校正具体的步骤及公式如下:


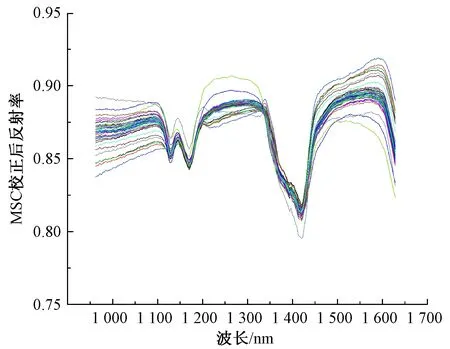
图4 多元散射校正处理的涤纶试样的光谱曲线Fig.4 Spectral curves of PET samples treated by MSC
一阶导数是一个由速度问题和切线问题抽象出来的数学概念。光谱曲线的一阶导数是每一数据点上曲线的切线的斜率,因此一阶导数通常被描述为瞬时变化率,表现的是试样在不同波长上的曲线变化程度,相较于原始数据,其不仅能够实现基线漂移的校正,同时突出了试样光谱曲线特征峰的峰位置及峰强。经过一阶导数处理的PET试样的光谱曲线见图5。
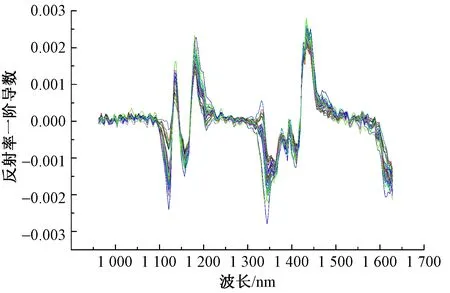
图5 一阶导数处理的PET试样的光谱曲线Fig.5 Spectral curves of PET samples treated by first derivative
由图4、5可知,经过MSC处理的PET试样的光谱曲线相较于未经处理的原始数据,其一定程度上校正了基线漂移,使不同试样的光谱曲线更为集中,但在不同波段范围内校正后光谱曲线的集中程度存在差异,如在1 100~1 200 nm和1 340~1 450 nm波段上通过处理后曲线较为集中,而在其他波段范围内则仍有一定程度的差异。而对一阶导数处理的PET试样的光谱曲线而言,同经过MSC处理的光谱曲线相比,经过一阶导数处理之后的42个试样的光谱曲线非常集中,几乎完全去除了基线漂移现象,同时通过一阶导数放大了光谱曲线特征差异。
2.2 模型建立与分析
在涉及到光谱分析及分类鉴别模型的建立时,由于光谱数据量大,样品种类繁多,各样品光谱数据之间差异大等原因,训练集和测试集中的样本的选择会对模型的分类准确度产生较大影响[19]。如若训练集的样本不具备代表性,尽管样本数量符合要求,但大部分样本均是光谱差异较小的样本,便起不到完全训练模型的效果,测试集中未得到训练的样本则难以正确分类,因此选用合适的样本集样本挑选方法至关重要。目前常用的样本选择方法主要包括:随机挑选法(SR)、Kennard-Stone法(KS)、含量梯度法(CG)、SPXY法(sample set partitioning based on joint X-Y distances)。随机挑选法即以随机的方式将样本挑选进入训练集和测试集,所有总样本集中的样本被选入训练集的概率均不为零且概率相等,以随机挑选法挑选样本的随机性大。含量梯度法将样品集中的样本按某个组分的含量值顺序排列,从中按序抽取样品组成训练集。Kennard-Stone法的原理是将光谱数据差异较大的样本选入训练集,而其余的样本则纳入测试集。SPXY法的原理同Kennard-Stone法几乎完全相同,这2种方法的区别在于SPXY法以新定义的同成分浓度相关的特征参数来替代Kennard-Stone法中的欧式距离。
含量梯度法由于需要对样品集中某组分含量排序,通常运用于成分定量分析中,在成分定性分析中由于不存在成分含量这一参数,若全新定义一新的参数来取代成分含量信息以进行选择,则需要对新定义的参数进行探讨,较为繁琐且可能导致更差的挑选结果,因此含量梯度法更为适合成分定量分析。SPXY法同含量梯度法一样存在相同的问题,同样更适合定量分析。正如本文2.1部分所论述的,即使是同一成分种类的纺织品,其原始光谱曲线同样受到纺织品形态(纤维、纱线和织物)、颜色、其他加工工艺的影响,导致光谱差异较大,以Kennard-Stone法选用样本能够保证训练集中样本的代表性,从而保证所建立模型的泛化性能,但如此便对总样本集中样本的数量和代表性提出了更高的要求,在上述要求难以得到满足的基础上反而会导致模型后继泛化性能的下降,在通过一阶导数对原始光谱数据进行处理的情况下,由于该预处理方法降低了试样间的光谱差异,在光谱差异较小的情况下,Kennard-Stone法并没有之前的优势,且进行此样本挑选方法相较于随机挑选法更为耗时,这也是本文选用一阶导数处理作为预处理方法的原因。
基于上述原因,本文通过随机抽样法以接近 2∶1 的比例对所有样本进行训练集和测试集样本挑选,通过一阶导数对原始光谱数据进行预处理,并将经过一阶导数预处理的光谱数据作为输入数据通过MatLab 2012R中工具箱建立PLS-DA的纺织品成分鉴别模型。训练集和测试集的具体样本数量如表1所示。

表1 训练集和测试集样本数量Tab.1 Sample number of train set and test set
PLS-DA是将偏最小二乘法(PLS)和判别分析(DA)相结合发展而成的一种分类方法,PLS-DA既能利用目前在化学分析中最为常用的回归技术之一的PLS算法实现因子分析和回归分析,且能够在此基础上将经过PLS算法处理的数据进行后续的判别分析以用于分类。
首先,PLS通过因子分析将对经过一阶导数预处理的光谱数据转换成包含原始信息的主成分变量,主成分变量由原始数据的线性组合而成,不同的主成分变量对最终分类鉴别模型有不同的贡献率,通常按照贡献率的比例进行排序,通过主成分的合理选取,去掉贡献率低的主成分(代表干扰噪音信息和同成分不相关的信息),按顺序选取贡献率高的主成分参与建模。参与建模的主成分个数过少,则难以包含所有光谱数据中的信息,造成信息的缺失;若参与建模的主成分个数过多,便会将包含成分无关信息或噪音的主成分纳入模型中,难以起到提高模型精度的目的,同时会降低模型的鉴别运算效率,此外模型的推广能力同样会受到一定影响。本模型所选取的主成分个数为10。
对每一样本而言,经过训练集样本训练的PLS-DA模型将对每一类别均返回一个预测值(介于0和1之间),并最终将样本分配给具有最大预测值的类别,该类别便是样本的预测类别。利用所建立的PLS-DA模型对测试集中62个样本进行纺织品成分定性鉴别,验证所建立模型鉴别的准确性。测试集样本分类结果的混淆矩阵见表2。

表2 预测集试样分类结果的混淆矩阵Tab.2 Confusion matrix of prediction set classification results
由表2可知,测试集中绝大部分的试样均得到正确分类,62个试样中未得到正确分类的试样共有 2个(总体鉴别准确率为96.78%):丙纶试样未被划分到任一类别中和锦纶试样被误分类为涤纶。棉和麻类纺织品的光谱曲线几乎完全相同,仅通过肉眼比较光谱曲线难以实现鉴别分类,通过所建立的纺织品成分鉴别模型能够以较高的精度实现上述二类较难区分的纺织品成分的鉴别(棉同麻的鉴别准确率均为100%)。
以高光谱成像系统所获得的光谱数据经由一阶导数处理所建立的PLS-DA纺织品成分定性鉴别模型,能够以较高的精度实现棉、麻、蚕丝、毛、涤纶、丙纶、芳纶、锦纶、聚乳酸纤维和高强聚乙烯纤维共10种较为常见的纺织品成分种类。纤维、纱线、机织物以及针织物均能实现分类,经过染色工艺且颜色不同的纺织品同样能够得到正确鉴别;带有特殊光谱曲线特征峰的双组分或多组分纺织品能够正确排除,不会被归类到相似的种类中。
3 结束语
本文探讨了使用高光谱成像系统对目前较为常用的纺织品成分种类进行鉴别的可行性。通过纺织品加工工艺及纤维形态多样性对高光谱数据的影响展开讨论,分析并比较了各类预处理方法的效果。从原理上分析比较了训练集和测试集样本挑选方法的优劣,结合预处理方法的分析,建立了基于PLS-DA的纺织品成分鉴别模型,得出了如下结论。
1)不同加工工艺(颜色、纺织品形态等)对其高光谱数据的特征峰位置并没有影响,但光谱基线漂移现象同样存在。若以原始数据进行训练建模,在训练集样本挑选时需要考虑样本的代表性,多元散射校正尽管能够一定程度上校正样本的基线漂移,但效果明显差于一阶导数预处理,以一阶导数处理为预处理方法时能够去除试样加工工艺的影响,较大程度减少试样间光谱数据差异,保证能以随机挑选法选择样本,简化流程。
2)所建立的偏最小二乘法判别分析纺织品成分鉴别模型能够实现棉、麻、蚕丝、毛、涤纶、丙纶、芳纶、锦纶、聚乳酸纤维和高强聚乙烯纤维共10种较为常见的纺织品成分种类的鉴别,不同颜色的试样,无论是纤维形态、纱线形态或织物形态的纺织品均能得到鉴别,且总体鉴别准确率达到96.78%。
3)运用高光谱成像系统对纺织品成分进行鉴别具备可行性,由于该方法能够将空间信息和光谱信息同时存储于高光谱图像中,在精细鉴别中具有应用价值,同时具备快速、无损、能够实现大批量在线检测的优势,针对高光谱图像中像素点的分类是本文下一步重点工作。
