基于SVM的单手指语识别方法
2018-10-24张慧静任相臻
王 巍,张慧静,任相臻
(1.河北工程大学 信息与电气工程学院,河北 邯郸 056038;2.江南大学 物联网工程学院 物联网技术应用教育部工程中心,江苏 无锡 214122)
0 引 言
根据手语输入介质的不同,手语识别系统大致分为两种:基于数据手套的手语识别和基于视觉的手语识别。前者是通过数据手套这一可穿戴式传感器来捕获手势原始数据,然后对这些数据进行分析处理来识别出用户的手部姿态[1],后者是基于计算机视觉通过摄像头捕获手势图像数据,然后运用各种图像处理技术进行分析,最终达到手势识别的目标[2]。由于数据手套需要通过多组不同类型传感器识别确定用户手指的真实位置,所以具有其它识别设备无法匹敌的高精度、低误差的特性。但考虑到数据手套佩戴繁琐、价格昂贵、普适性低、抗干扰性差等因素,逐渐受到“冷落”。后者则以其自然、直观、易于学习等优势逐渐成为近几年手语识别领域的青睐[3],但识别精度又差强人意。
1 国内外研究现状
微软Kinect是一款消费级的姿态传感器,它能够允许用户在非控制条件下进行交互[4]。Kinect最初设计应用于体感游戏[5]。然而,随着Kinect版本不断地更新和技术的提高,也被应用到人体骨骼追踪、人脸识别和手势识别等领域[6]。将测试的准确度和精度作为Kinect的评估标准,Gonzalez-Jorge等[7]将Kinect与Xtion传感器进行了比较,发现准确度和精度并不受传感器类型或是测试目标与设备间的入射角度的影响,而距离则会引起测试准确度和精度成倍降低。当测试距离超过7 m后,传感器已无法测量。测试距离在1 m范围内,测试准确性是5 mm~15 mm,两米范围内为5 mm~25 mm,在1 m和2 m范围内测试精度分别为1 mm~6 mm和4 mm~14 mm。这些结果证实Kinect在工程实际应用中的测试范围很小,而且测试准确度也不太严格。
相比Kinect,另外一款消费级别的姿态传感器是Leap Motion Controller(LMC),于2013年中旬上市[8,9]。LMC致力于手势识别,允许用户通过手势与电脑实现交互[10]。这款设备将高精度的手和手指追踪作为一个自然交互界面来改善人机交互。根据制造厂商提供的信息,LMC能够识别手势和手的坐标位置,精度可达0.01 mm。而实际测试发现测试精度只能达到0.7 mm[11],并不适用于专业的目标追踪研究,但它为简捷手语识别提供了一种更加自然、舒适的体验效果。
由于手部运动有益于儿童的脑部发育,Cho和Lee[12]利用Leap Motion基于蜜蜂之舞为孩子开发了一款游戏,这款游戏充分利用了LMC的优势,为历险游戏提供了一个新的发展方向。Chuan CH等[13]提出一种基于Leap Motion的美国手语方法,他们使用K-临近算法和支持向量机对美国手语中26个字母指语进行了分类,实验结果显示两种分类方法的最高平均识别率分别是72.78%和79.83%,该方法的提出对聋哑教学有巨大影响。任磊[14]提出一种基于Leap Motion动态手势研究系统,主要通过追踪目标手指的运动轨迹作为手势识别特征对中国手语的26个字母进行识别的,平均识别准确率为96.57%,但是在实验设计过程中并没有使用到Leap Motion检测到的高精度手势信息。
本文针对以往基于视觉手势识别存在的手势分割难、环境干扰大、识别准确低等弊端,提出一种基于支持向量机(support vector machine,SVM)的单手指语识别方法。之所以选用单手指语,是因为它简洁、通用,非常适用于有限空间范围内。本文将从Leap Motion提取的特征训练生成手势模型,使用SVM对预测手势完成分类。实验结果表明,本方法具有较高的识别精度和良好的可拓展性。
2 系统介绍
本文中指语识别主要分为数据采集、特征提取、数据预处理和分类识别4部分。首先,数据采集部分使用由Leap公司提供的一款价格低廉、便于携带的姿态传感器Leap Motion获取视野内手势特征。其次,Leap Motion采集得到的手势数据含有大量的冗余信息不可以直接使用,因此需要对采集的特征进行提取,整理出更具有价值的手势特征以便分类使用。再次,考虑到特征样本含量大、特征维度高,影响识别准确率和运行速度,在建模前需要对特征数据进行了预处理。最后,利用网格搜索寻找最优参数,训练模型完成分类。指语识别具体流程如图1所示。

图1 指语识别流程
图中左侧虚线框内为Leap Motion数据采集流程,采集到的手势特征以数据集的方式封装在软件开发工具包(software development kit,SDK)中。每个手势姿态可以细化成很多帧,每一帧都有其特定的ID与之区别开,对于视野内持续存在的ID将保持追踪,提取帧中的手势数据进行存储,对于丢失ID将结束本次追踪,重新采集。Leap Motion最大频率可达每秒200帧,保证了手势数据采集的实时性。右侧虚线框内是对特征提取后的手势数据进行预处理,包含:归一化和主成分分析(principal component analysis,PCA)降维。
3 指语识别
3.1 获取手势三维数据
Leap Motion采用的是右手笛卡尔坐标系,反馈给用户的为手势三维空间信息,封装在系统内部。从文献[15]了解到Leap Motion通过Frame类作为程序入口来捕获视野内的手与手指的数据集合,再通过调用Frame类的成员函数得到视野内一只手的三维信息,如图2所示:图(a)为视野内手的骨骼坐标和名称,图(c)为视野内手的指尖方向和法线方向。表1根据图2列出了本文从Leap Motion的应用程序接口(application program interface,API)可以获得的手掌和手指的特征。手掌特征包括:法线、手掌的中心坐标和速度。手指特征包括,每根手指的名称、方向和长度,远端骨节、中间骨节、近端骨节和掌骨的三维坐标等。同时,API还提供一些手势信息,图2并没有显示出的浮点型数据(本文并没有涉及到),例如:抓力、捏力、球心和求半径。

表1 从Leap Motion API获取的手势特征

图2 Leap Motion API提供的手势特征
3.2 特征提取
本文只针对静态手势,因此API提供的一些手势信息并不完全适用,例如手掌及指尖速度,如果不进行特征提取,必将引入大量的冗余信息,影响识别结果的准确性。尽管手和手指的绝对位置对指语识别影响不大,但是可以通过它们获取其它有意义的特征,例如计算指尖距离、向量夹角。因此,本文特征向量将基于API提供的手势空间信息计算得来,使得到手势特征具有较强的鲁棒性[16]。
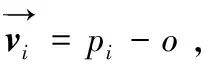
(1)
第二个特征向量f2包含两两手指间夹角,可由两向量间夹角公式求得,令j∈(thumb, index, middle, ring, little),i≠j
=arccos
(2)
则特征向量f2可表示为
(3)
特征向量f3为每个手指与手掌法线间夹角,夹角大小也可由式(2)求得
(4)
同时,还将视野内手指的伸张个数作为第4个特征向量,即
f4=[extendi]
(5)
5根手指根据extend的0,1状态判断手指伸曲状态。加入特征向量f4后,此时共计25组特征数据,将其以.txt格式保存作为本文指语识别特征,保证了手势在实测过程中的旋转不变性和放缩不变性,同时提高了测试精度。
3.3 数据预处理
本文设计9种指语分类,每种指语样本包含25组特征数据,样本数量是识别准确性的重要保障,但是样本数量太大会影响识别速率,样本数量太少又无法保证识别准确性。在保持样本数量充足的情况下,可以通过降低特征矩阵维数来提高识别速率。
在降维前,考虑到提取的特征值数值之间相差较大,很容易导致大数值区间属性过分支配小数值区间属性的现象出现,造成降维过程中损失主成分特征,所以需要先对特征数据进行归一化处理。本文将数据归一到[0,1]区间,采用训练集和测试集同时归一化的方式。图3为训练集归一化前后数据分布图,灰度值的深浅变化代表训练集中特征值的范围变化。
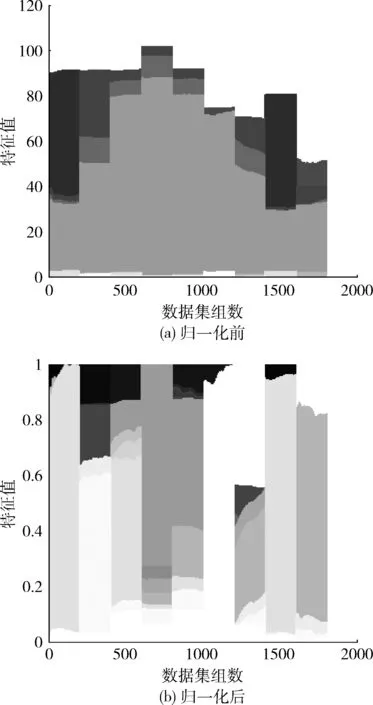
图3 训练集数据归一化前后对比
从图3(a)可以看出,原始数据数值分布跨度较大,部分数据数值较小,分布在0-5范围内,也有部分数据数值较大,分布在100-120范围内。归一化后图3(b)中,数值规范在[0,1]区间后,数据分布相对均匀,避免了大数的变化会掩盖掉小数的变化的现象,同时也加快了收敛速度。
主成分分析(PCA),是常用的降维方法之一[17]。降维就是将原来的样本数据投影到一个新的空间,通过坐标转换得到一个新的坐标系下,在这个坐标系中不再需要原始空间中那么多的变量,只需找到原来样本的最大的一个线性无关组的特征值对应的空间的坐标即可。降维后的主成分分析如图4所示。
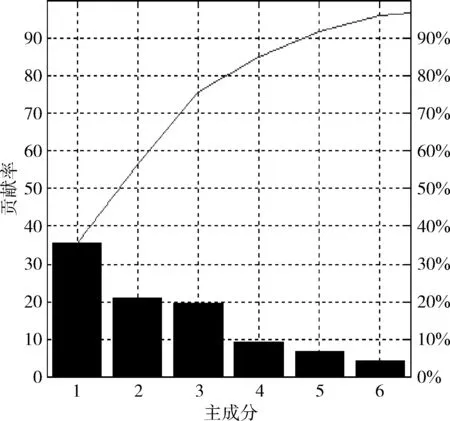
图4 PCA降维后主成分分析
图中横坐标为主成分维数,纵坐标为主成分的贡献率。从图中可以看出特征维数从原来25维降为现在的6维,此时主成分仍然可以达到对原始变量95%的解释程度,不但大大降低特征矩阵的空间维度,还保留较多的原始数据特征。
3.4 分类识别
支持向量机(SVM),作为一种统计学上的分类方法,主要用于解决二分类中涉及到的线性可分与线性不可分的分类问题,对于线性不可分的则需要依靠核函数,核函数的选择是SVM的关键,选择哪种核函数训练分类器关乎到分类结果的精度。由两类分类器得到多类分类器,完成对9种指语的分类,本文则采用文献[18]提到的一对一的方法,相对于一对多的分类方法这种方法用时更少,效率更高。
本文选用径向基核函数(radial basis function,RBF),它不仅具有线性核函数和Sigmoid核函数的优点,而且数值计算简单,不会出现溢出之类的计算问题。由SVM原理可知,核函数参数g和非负惩罚因子C对SVM分类起着至关重要作用,因此,本文利用网格搜索结合交叉验证的方法对RBF核参数g和惩罚因子C寻优。网格参数选择结果如图5所示。
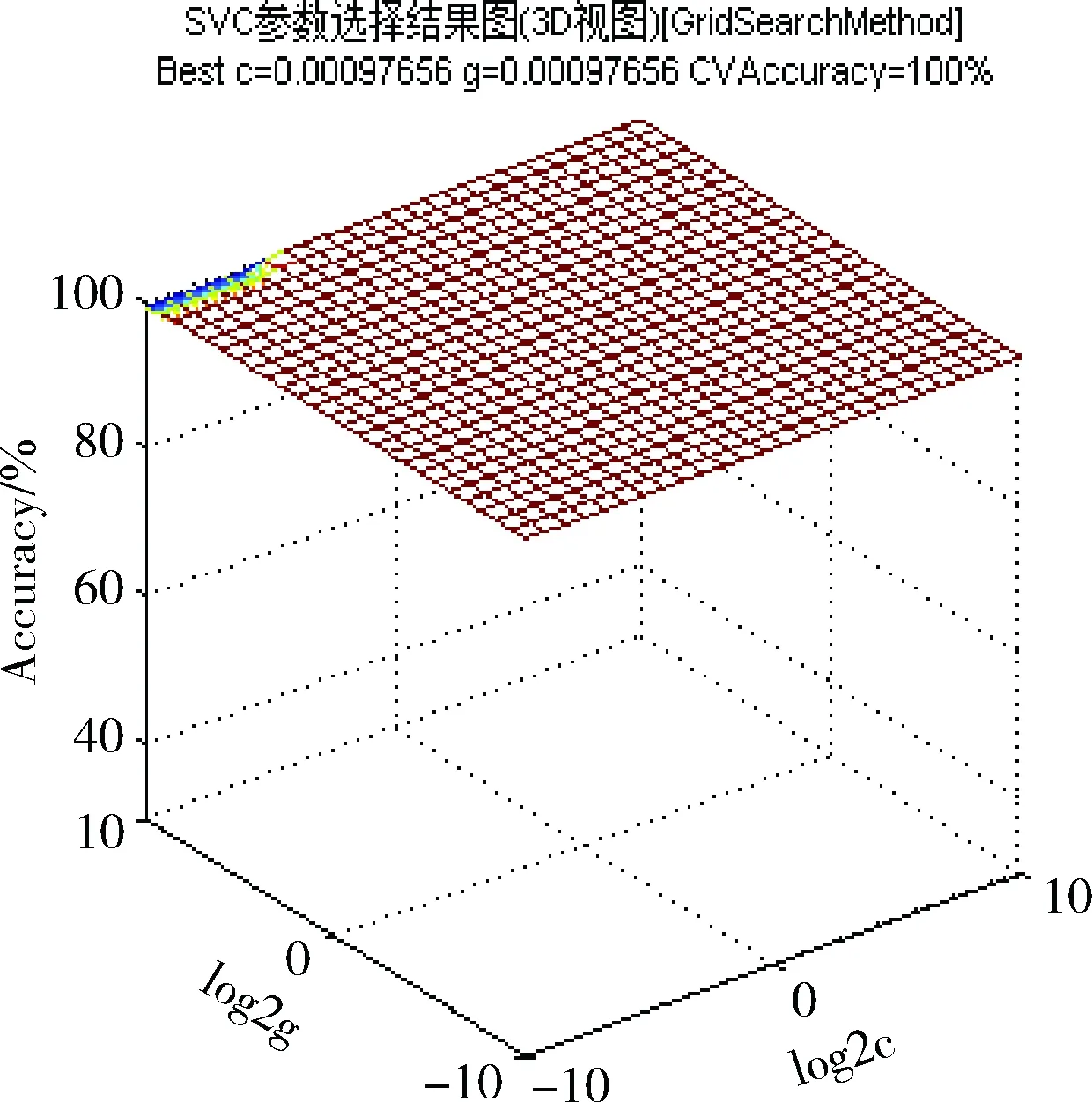
图5 网格参数选择结果
图5中满足交叉验证的最佳分类准确率为100%对应的参数对(c,g)较多,根据参数寻优的一般原则,最终选择了C值最小的那组,对应的最佳参数C=0.00097656,最佳参数g=0.00097656。
将利用网格搜索结合交叉验证的方法得到最佳RBF核参数g和惩罚因子C代入到svmtrain()中训练model,实现对测试集指语的预测分类。
4 实验结果与分析
本节所使用的硬件平台:DELL笔记本电脑(Inter(R)Core(TM)i5-4460,4.00 GB内存)一台和Leap Motion设备一台。软件环境:Leap_Motion_SDK_Windows_2.3.1驱动结合Visual Studio 2013编程环境安装在Windows8.1系统下使用C和C++语言进行特征提取,Matlab2014b结合Libsvm工具箱完成分类。测试条件:实验者伸出右手手势保持在Leap Motion视野上方60 mm~300 mm范围内,此范围内得到的数据值最为理想。
为了验证本文指语识别方法具有良好的旋转不变性和放缩不变性,本文对4名实验者(两男两女)进行了手势数据采集,将4名实验者分为两组,每组男女各1名。其中一组要求数据采集过程中手势姿态相对设备静止,作为训练集。另一组则进行两轮数据采集,第一轮要求采集过程中手势姿态相对设备静止,作为测试集1,第二轮要求采集过程中手势可以适当旋转或者上下移动,作为测试集2。本文涉及到9种指语类型,为了保障测试样本充足,要求每人每种指语需要采集200组数据,从中随机抽出100组进行实验。那么,训练集和测试集的样本数量都是1800组,避免了因为测试集样本数量过少发生“数值偏置”。实验过程中两组测试集共用同一组训练集,使得预测结果对比性更具说服力。实验结果如图6所示。
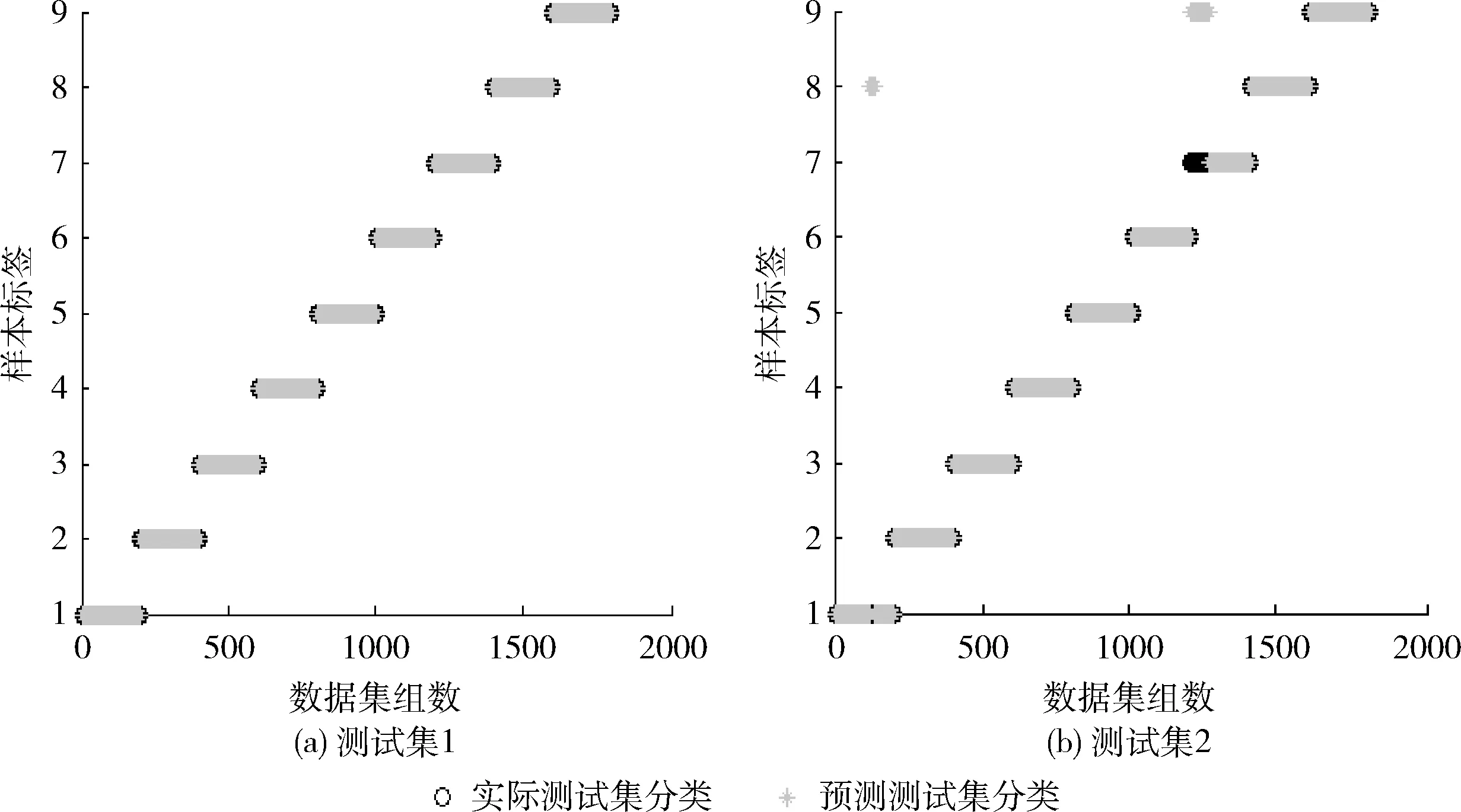
图6 测试集的实际分类和预测分类
图6中(a)、(b)分别是测试集1和测试集2的实际分类和预测分类的实验结果。图中黑色“o”表示实际测试集分类,灰色“*”表示预测测试集分类。横坐标是数据集组数,每200组是一种指语类型,共计1800组,纵坐标为数字指语1-9类型标识。从图(a)中可以看出当手势姿态相对静止时,9种指语全部预测正确,识别准确率为100%;当手势在采集过程中不断发生旋转、上下变换时,图(b)中仅指语1有一小部分误测为指语8,指语7数据集中前面一部分误测为指语9,其余指语实际分类与预测分类完全相符,9种指语的平均识别准确率达到95.56%,两次实验结果都验证了本文方法的可行性。
5 结束语
本文借助Leap Motion完成了对9种静态单手指语的识别过程,相对于以往的基于视觉的手语识别,不仅在识别准确度、识别速度有很大提高,而且选用Leap Motion控制器进行实验,对测试者的要求更低,通过手势特征的精确选取,使得测试过程中手势的适当旋转、缩放不会对识别结果造成太大影响,增强了用户体验效果。但是考虑到Leap Motion设备识别范围只限于60 mm~500 mm,无法定位人脸及上肢动作,使得目前识别只能局限于手部,同时手势旋转、缩放过程中的遮挡和细节微小差别识别不明显等缺陷,致使部分指语9误识别为指语7,导致识别准确率降低,希望在未来的新一代设备上加以解决。
本文方法主要针对静态手语识别,目前识别种类较少,但是本文方法易于手势库的拓展。因此,在以后研究中将会加入字母指语,并尝试利用Leap Motion追踪手势的运动轨迹实现动态指语识别。
