基于双向神经网络的图像分类算法
2018-10-24季思文闫胜业
季思文,闫胜业,王 蒙
(1.南京信息工程大学 江苏省大数据分析技术重点实验室, 江苏 南京 210044;2.南京信息工程大学 计算机软件学院,江苏 南京 210044)
0 引 言
图像分类是模式识别以及计算机视觉领域一个重要的研究课题,提升图像分类性能的关键有两点:①提取优秀的特征;②有效利用特征。主流的研究方向在于如何提取更好的特征来实现较好的图像分类效果。传统的图像特征提取方法有:HOG特征[1]、LBP特征[2]、Haar-like特征[3]等。目前,深度神经网络提取特征成为计算机视觉领域的一个研究热门,众多优秀的神经网络模型被提出和优化,利用神经网络提出的特征也更加优秀。Y.LeCun等提出了LeNet神经网络模型[4],该模型包含两个卷积层,3个全连接层主要设计应用于银行的手写数字识别系统,是早期卷积神经网络的代表。AlexNet[5]网络结构取得了ImageNet[6]分类大赛的冠军,该网络包含5个卷积层和3个全连接层。K Simonyan等提出了VGG网络[7],不同于8层网络的AlexNet,VGG-Net通常有16-19层的网络,并且每一层的卷积核大小3*3,最大池化层大小为2*2,其减少了卷积层的参数并加深网络的深度来提高网络性能,并对网络进行预训练加速网络的收敛。GoogLenet[8-10]获得了ILSVRC-2013的冠军,提出了Inception module的概念,旨在强化特征提取模块的性能。随着网络宽度和深度的增加,神经网络能够提取出越来越优秀的特征,图像分类的性能也在稳步提升。图像在经过卷积层、池化层进行特征提取以后,能够有效地保留特征空间上的结构信息,该特征也有助于图像的分类。上文提到的深度网络模型通过全连接层进行图像的分类。把前几层网络提取的特征拉成向量送入全连接层中进行后续的分类工作,这步工作破坏了原始特征空间上的结构信息,因此不利于图像分类性能的提升。
针对上述原因,本文提出了一种基于双向神经网络的图像分类算法:用Two-Directional层代替原先网络中的全连接层,通过变换矩阵L和R对网络前几层提取的特征进行维度变换处理,并送入SoftMax层中进行分类。Two-Directional层能有效的保留原始特征的空间结构信息,从而提升网络的分类性能。本文通过CaffeNet网络模型和vgg-16网络模型来验证Two-Directional层对图像分类性能的影响,并且以Caltech-256和Oxford Flower-102数据集为基础设计实验进行验证。
1 网络框架
为了减少特征空间结构信息的损失并且提升整体网络分类的性能,本文受2D-PCA[11]、2D-LDA[12]算法的启发,提出了一种基于双向神经网络的图像分类算法。使用Two-Directional层代替原始网络模型中的全连接层,并通过SoftMax层对图像进行最终的分类。本文以CaffeNet网络模型为基础,对比介绍本文提出的双向神经网络框架。
1.1 CaffeNet网络
深度神经网络因为在图像分类领域具有良好的表现而被广泛的应用,其中比较经典的有CaffeNet网络模型。它包含5层卷积层,两层全连接层以及一层SoftMax输出层。网络模型通过前几层的卷积层能够学习低层次的特征,并且通过后面的卷积层把前面低层次的特征转换层高层次的特征能够学习。CaffeNet结构如图1所示。
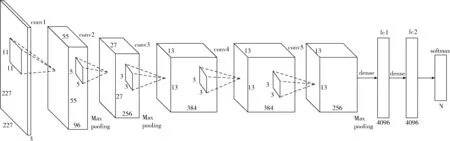
图1 CaffeNet网络结构
CaffeNet包含5个卷积层、3个下采样层、3个全连接层、2个LRN层和2个随机采样层,并且采用SoftMax作为分类器。CaffeNet网络模型把特征拉成向量送入全连接层中进行分类,使得原始特征从原先的矩阵变成了向量,因此不能有效利用特征中的空间结构信息,也因此限制了模型的分类性能的提升。
1.2 基于CaffeNet的双向神经网络
本文提出的双向神经网络框架旨在保证网络的深度和宽度不变的前提下,有效利用特征空间上的结构信息,从而提升网络的分类性能。通过变换矩阵L和R对卷积层提取的特征进行维度变换处理,然后使用SoftMax进行输出分类,基于CaffeNet的双向神经网络如图2所示。
如图2所示,基于CaffeNet的双向神经网络用新的Two-directional层代替原始网络中的全连接层。以CaffeNet网络模型为基础,我们设计了两层Two-directional层并且通过SoftMax进行分类,其中N代表训练样本的类型数目。我们用单位矩阵来初始化权重矩阵L和R,并进行网络的迭代更新。
2 双向神经网络算法
传统的深度网络框架通过全连接层来处理特征,造成特征空间结构信息的损失。为了有效利用特征空间结构信息,使用Two-Directional层代替原始网络中的全连接层,也提出了一种扩展BP算法,用于求解双向神经网络中的特征学习问题。
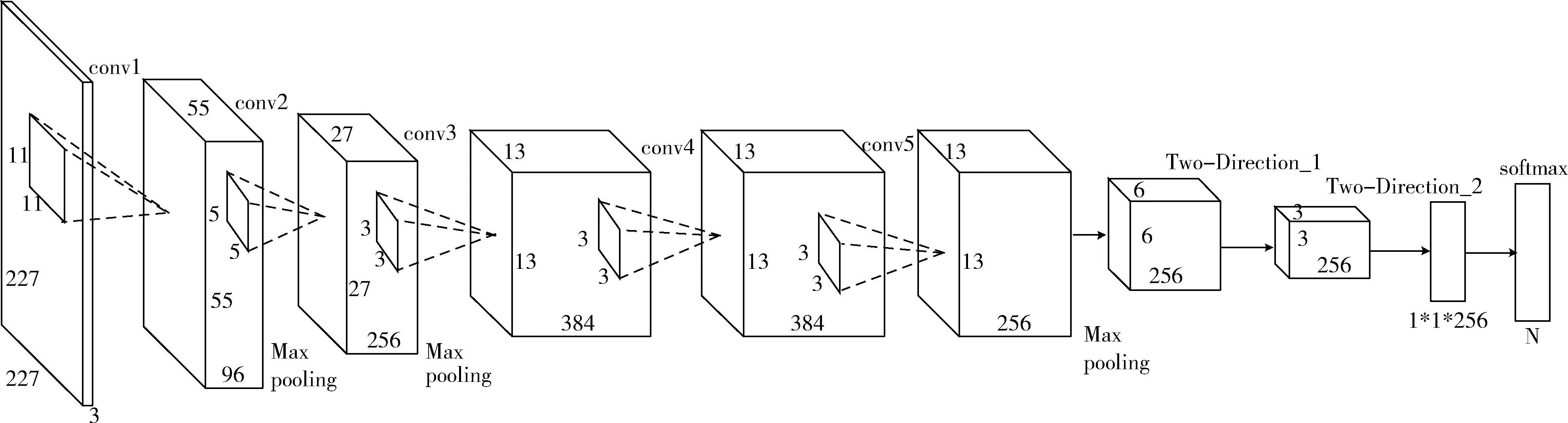
图2 基于CaffeNet的双向神经网络结构
2.1 Two-Directional层
Two-Directional层受2D-LDA算法的启发:2D-LDA的定义参见文献[12],本质是寻找使得原先高维度的样本空间在低维度空间上的投影,通过变换矩阵L和R对深度网络提取的特征进行变换,并送入SoftMax输出层进行分类,下面将详细介绍Two-Directional层的前向传播与反向传播。
2.2 Two-Directional层前向传播
X=f(U)=f(W*X+b)
(1)
(2)
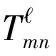
X=f(U)=f(vec(T))=f(vec(LXR))=
f((RT⊗L)vec(X))
(3)
式中:f(·)表示激活函数,本文采用的激活函数为RELU激活函数,RELU激活函数为
f(x)=max(0,x)
(4)
式中:W为第层的权重,通过每次迭代更新变换矩阵L和R,再利用式(3),计算层的输出X。式(4)中的RT⊗L就相当于全连接层中的权重矩阵W。通过Two-Directional层对深度网络前面几层提取的特征进行降维处理,保存了原始特征中的空间结构信息,有利于图像最终的分类。
2.3 Two-Directional层反向传播
全连接层的反向传播需要计算权重矩阵W在每一次迭代时的更新。对于Two-Directional层,则需要对变换矩阵L和R的参数进行更新
Lt+1=Lt+ΔL
(5)
Rt+1=Rt+ΔR
(6)

我们定义变换矩阵L和R为
(7)
(8)
那么中间矩阵W为

(9)
因此W的维度为nm*ba,根据链式法则可以计算出误差对变换矩阵L和R的偏导数

(10)
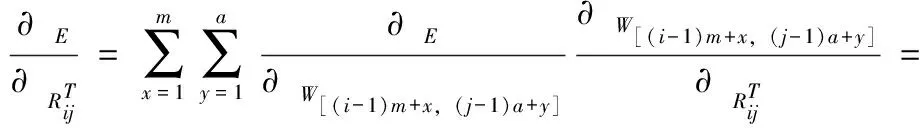
(11)
我们定义输出层的误差为
(12)
式中:c为样本总类别个数,tk为样本的目标输出,yk为网络的输出。那么输出层的敏感度为
δoutput=f′(Uoutput)∘(Y-T)
(13)
进而我们能够计算Two-Directional层和其前一层的敏感度
δ=δ∘f′(U)
(14)
δ=δ1∘f′(U)=
(RT⊗L)δ∘f′(U)
(15)
那么可以计算出误差对整个权重矩阵W的偏导数
(16)
把式(16)带入式(10)和式(11)可以算出每次迭代的ΔL和ΔR

(17)
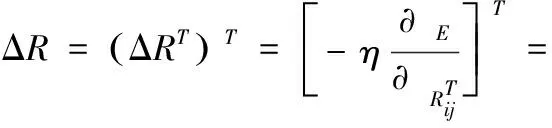
(18)
由此可得Two-Direction层在反向传播中对变换矩阵L和R在每次迭代时的更新
(19)
(20)
2.4 双向神经网络算法总结
本文以CaffeNet网络为基础,对比介绍了基于双向神经网络的图像分类算法。保证CaffeNet网络模型特征提取层不变,对原始网络中的全连接层进行改进。受2D-LDA算法启发,在模型每次迭代的过程中计算出变换矩阵L和R,对原始特征进行维度变换,然后送入SoftMax层进行分类输出。本文提出的Two-Directional层能够有效利用特征空间上的结构信息,有效地提升了网络分类的性能。我们同样也对vgg-16网络结构进行了改进,记改进后的网络分别为2D-caffenet和2D-vgg16,并且在Caltech256和Oxford Flower-102数据集上进行了图像分类性能对比实验,实验内容如下文所示。
3 实 验
本文以双向神经网络框架为基础,对CaffeNet和vgg-16深度网络模型进行重新设计,并且在Caltech256和Oxford Flower-102数据集上进行了图像分类性能对比实验。Zeiler和Fergus[13]证明了利用ImageNet预训练模型在目标数据集上微调网络有利于图像分类性能的提升。Caffe有众多优秀的深度神经网络框架,本文使用在ImageNet上的预训练模型初始化神经网络,并在目标数据集上进行迁移学习,训练出适应于目标数据集的模型。而对于双向神经网络,我们使用预训练模型初始化特征提取层的权重参数,并使用目标数据集对整个网络微调。实验的硬件设备为GeForce GTX TITAN X,Intel(R)Core(TM)i7-6700 CPU @3,40 GHz 3.40 GHz,系统为ubuntu16.04,框架为caffe。本文使用图像分类准确度(acc)和类别平均精度(mAP)两项评估标准对网络分类性能进行评估。
3.1 用Caltech-256数据集实验
3.1.1 实验数据和实验设置
Caltech-256数据集由256种对象类别和背景图像组成,共计30 607张图像,其中每一类别包含80-827张图像不等。我们从每个类别中选取60张图片作为训练集(共15 420张图像),其余的15 187张图像作为测试集。整个实验过程共计10次,每次随机选取训练集的样本,训练多个模型进行测试,最终的实验结果取10次实验的平均值。
3.1.2 实验结果及分析
本文使用改进后的2D-CaffeNet和2D-vgg16网络与原始的CaffeNet和vgg-16网络在Caltech-256数据集上进行图像分类性能对比实验。我们设定网络的初始学习率为0.0001,Two-Directional层的学习率为特征提取层的10倍。每15 000次迭代下降10%,共40 000次迭代,同时我们以单位矩阵来初始化变换矩阵L和R,实验结果见表1。
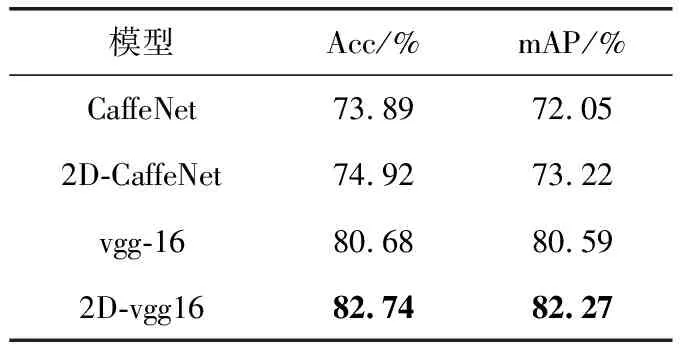
表1 Caltech-256数据集实验结果
实验结果表明,本文提出的双向神经网络算法能够有效地提升原始网络的分类性能。经过10次取样实验,其中CaffeNet模型的准确率提升了1.03%,每一类别的平均准确率提升了1.17%。而vgg-16网络模型的准确率在原来的基础上提升了2.06%,每一类别的平均准确率提升了1.68%。
3.2 用Oxford Flower-102数据集实验
3.2.1 实验数据和实验设置
与Caltech-256数据集不同,Oxford Flower-102数据集属于细粒度的数据集。Oxford Flower-102 包含102类的花,每一类花的数量在40-258张图片之间,图片总数为8189。我们每一类取20张图片作为训练集(共2040张),剩余的6149张图片作为测试集。与Caltech-256数据集一样,我们也是多次抽样训练模型,并进行交叉验证,最终实验结果取多次测试结果的平均值。
3.2.2 实验结果及分析
为了验证双向神经网络在细粒度数据集上对分类性能的影响。使用改进后的2D-CaffeNet和2D-vgg16网络与原始的CaffeNet和vgg-16网络在Oxford Flower-102数据集上进行对比实验。设定网络的初始学习率为0.0001,Two-Directional层的学习率为特征提取层的10倍。每15 000次迭代下降10%,共40 000次迭代并以单位矩阵来初始化变换矩阵L和R,实验结果见表2。
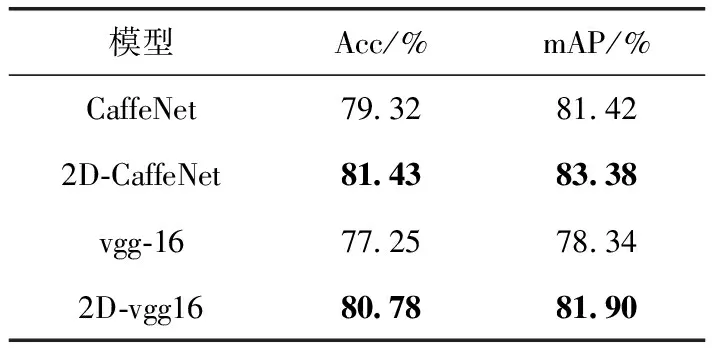
表2 Oxford Flower-102数据集实验结果
实验结果表明,本文提出的双向神经网络算法能有效的提升细粒度数据集的分类性能,其中CaffeNet网络模型分类准确率在原来的基础上提升了2.11%,每一类别平均准确率提升了1.96%。vgg-16网络模型的分类准确率在原本来的基础上提升了3.53%,每一类别平均准确率提升了3.56%。
由此可见,本文提出的双向神经网络算法能有效的提升图像分类的性能。通过imagenet预训练模型在目标数据集上进行微调,能够快速有效地训练出性能优秀的图像分类模型。
4 结束语
本文针对如何减少特征空间信息的损失,提出了一种基于双向神经网络图像分类算法。使用Two-Directional层代替原始网络中的全连接层,通过变换矩阵L和R对网络前几层提取的特征进行降维处理,然后送入SoftMax层进行分类。本文分别以CaffeNet,vgg-16模型为例在Caltech256和Oxford Flower-102数据集上进行对比实验,实验结果表明,本文提出的双向神经网络框架能够有效的提升原始网络的分类性能。将来我们会使用更大规模的数据集,并且使用更多的基础网络来验证双向神经网络的性能与不足之处。同时寻求更加有效的特征处理方法,在保持网络深度与宽度的前提下进一步提升网络分类的性能。
