基于森林自动机处理XML流数据方法
2018-10-24何志学廖湖声
何志学,廖湖声
(1.北华航天工业学院 计算机与遥感信息技术学院, 河北 廊坊 065000;2.北京工业大学 计算机学院, 北京 100124)
0 引 言
各种传感器应用的发展,移动互联网特别是智能移动终端的普及,使得在环境监测、交通流量监测、金融交易、网络舆情分析和社交网络等场景中产生了海量的数据。而这些数据中80%以上都是半结构化或无结构的数据。如何从如此大量的数据中分析提取出有用的信息辅助决策的制定是大数据研究的一个重要方向[1]。XML是互联网中半结构化数据表示和传输事实上的标准,本文以半结构化XML流数据为研究对象,提出了基于森林自动机的XPath查询处理方法。
XML流查询处理主要分为基于自动机、基于栈和基于数组的方法[2,3]。流数据一般将元素、属性、文本值等都抽象为事件,而自动机由事件驱动运行进行状态转换,是处理流数据比较自然的选择,被很多系统采用,如GCX[4]系统利用静态和动态分析相结合的方式实现了XQuery流处理引擎,该方法采用了文档投影技术和动态垃圾回收机制,使得处理过程中内存占比最小化,与其它引擎相比在内存需求上有明显的优势。文献[5]采用森林自动机[6]处理XQuery的核心查询取得了较好的效果,但文中主要讨论了如何将查询转换为自动机,对于自动机的具体处理方法并未给出,本文在此基础上做了进一步的工作,侧重于自动机的执行和缓存的处理。其它方法多采用各种自动机的变形,如嵌套的字自动机[7]、对自动机投影[8]等。
XML流数据的查询处理过程中面临着查询表达式复杂情况下,自动机状态空间过大,处理效率过低和中间结果暂存占用内存过多的问题。本文在研究组工作[9]的基础上,对森林自动机实现中使用的数据结构和处理过程进一步优化,提出了基于森林自动机处理XML流数据的方法。该方法首先将用户给定的查询转换为森林自动机实例,然后由输入流数据结点驱动该自动机进行结构匹配和状态转换动作。通过抽象语法树维护自动机运行过程中多个函数之间的关系并记录中间结果,使得在对树结点归约过程中产生匹配结果后便可输出,满足了对流数据进行单遍扫描即可获得查询结果的需求,较好地实现了效率和内存占比的平衡。
1 XML查询及森林自动机定义
1.1 XML流数据模型
XML数据一般表示为DOM(document object model)树的方式进行解析,如图1(a)中数据可以表示为图1(b)形式。而对于流数据,数据量可能无限增大,在内存中构建DOM树不具有可行性,且对于某些查询而言,只有部分数据与查询相关,没有必要将全部数据加载到内存中。XML数据的流式处理方法以事件驱动,方法回调的形式实现,对于每个元素的开始标签和结束标签都产生开始事件和结束事件,采用SE(e)表示startElement(),EE(e)表示endElement(e),则解析图1中的XML文档则可产生SE(person)、SE(p_id)、SE(a)、EE(a) characters()和EE(p_id)等事件。

图1 XML数据及其DOM表示
1.2 XPath查询
XPath[10]是XQuery[11]和其它多种XML查询语言的核心和基础,本文进行分析的查询的对象定义为XPath的子集:
Path:=Step|Step Path
Step:=Axis NodeTest|
Axis NodeTest ‘[’Predicate’]’
Axis:=‘/’|‘//’
NodeTest:=name|*
Predicate:=[Step]|[Step] Predicate
其中Path表示查询路径,包含单步查询或者多步查询;查询步中结点之间的关系考虑了常用的父子(Parent-Child,P-C)关系“/”和祖先后裔(Ancestor-Descendant,A-D)关系“//”;谓词可以是单个查询步的判断,或多个查询步的包含或并列。如针对图1中的XML数据,查询“p_id为person0的人员姓名”可表示为
Q1:/person[/p_id[text()=“person0”]]/ name/text()。
1.3 森林自动机
森林自动机[6]将处理的XML文档看作是树的集合,一棵XML文档树可以表示为node(x1)x2的形式,其中node是当前处理结点,x1表示当前处理结点的孩子结点集合,x2表示当前处理结点的兄弟结点集合。
定义1 XML森林:XML文档可表示为t1,t2,…,tn,n≥0的形式,其中ti(0≤i≤n)表示XML子树,由根结点和其下的子树序列组成。形式化定义如下:
forest:=ε|tree forest
tree:=tag(forest),tag∈∑
其中,∑表示结点标记的集合。
定义2 森林自动机:可定义为四元组FM:=(S,F,T,f0),其中
S:状态(函数)的集合;
F:转换函数集合forest×f→{fi|fi是匹配后的状态函数};
T:输入流数据的结点集合;
f0∈F:起始状态函数;
在森林自动机中,状态以函数的形式出现,接收输入的流数据,将数据以森林的形式对待。针对上述XPath定义,由XPath查询转换为森林自动机实例的规则分为数据选择路径规则T1和谓词判断路径规则T2,针对不同的查询表达式形式,定义了如何根据当前访问结点的情况进行状态转换和后续函数调用,具体定义如图2所示。规则中的“%t”是一个特殊标记,表示不同于当前规则目标结点的任意字符串。假定规则匹配的目标结点为“test”,如果当前流数据流入的结点标签名亦为“test”,则选择查询表达式对应规则中的第一条规则,代表当前数据匹配成功,完成状态转换和相应函数的调用;如果流入的结点标签为其它字符串,则选择第二条规则,也就是“%t”所在的规则,表示当前结点匹配失败;如果到达流的结束,则以“nil”表示空输入。由XPath转换为森林自动机的具体实现参见文献[9]。

图2 森林自动机转换规则
例1:给定XPath查询Q1:
/person[/p_id[text()=”person0”]]/ name/text(),
对应的森林自动机实例如下:
q0(person(x1)x2)=(q1(x1)?q3(x1):nil) q0(x2)
q0(%t(x1)x2)=q0(x2)
q0(nil)=nil
q1(p_id(x1)x2)=q2(x1) OR q1(x2)
q1(%t(x1)x2)=q1(x2)
q1(nil)=false
q2(person0(x1)x2)=true
q2(%t(x1)x2)=q2(x2)
q2(nil)=false
q3(name(x1)x2)=q4(x1) q3(x2)
q3(%t(x1)x2)=q3(x2)
q3(nil)=nil
q4(text(x1)x2)=text() q4(x2)
q4(%t(x1)x2)=q4(x2)
q4(nil)=nil
2 流数据处理方法的设计与实现
本节首先介绍基于森林自动机规则构造XPath查询对应的自动机实例处理XML流数据的整体方案,然后给出算法的具体实现和实例,最后对算法复杂度进行分析。
2.1 整体方案
首先根据构造规则,创建用户查询对应的森林自动机实例;然后不断接收XML流数据驱动自动机状态转换。在自动机运行过程中,通过抽象语法树(abstract syntax tree,AST)缓存中间结果并维护状态(函数)之间的关系,在AST的归约过程中得到满足查询的结果即可输出。具体步骤如下:
(1)根据1.3节定义的规则,构造XPath查询对应的自动机实例FT;
(2)初始化森林自动机运行环境;
(3)不断接收XML流数据的结点,驱动森林自动机运行,进行函数目标结点的匹配和状态转换。
(4)通过抽象语法树记录函数匹配过程中获得的中间结果,随着自动机的运行,抽象语法树逐步转换并进行归约,得到满足查询的结果随即输出。
2.2 具体实现
根据以上定义的方案,算法的整体框架如下:
Algorithm:execFT
Input:XML Stream St,XPath query Q
Output:the answer ans
01 convert Q to FTQ
02 funcID=0;
03 S=new Stack();
04 T=new AST();
05 level=0;
06 while(not end of St)
07 n=incoming element
08 case SE(n):
09 n.level=level++;
10 while(S.top.targLevel≥n.level)
11 funcs=S.pop();
12 for each function f in funcs
13 res = res∪execFunc(f, n);
14 fSet=group res by target level
15 push fSet into stack ordered by level
16 case EE(n)
17 level--;
首先根据1.3节定义的规则,将查询Q转换为对应的森林自动机实例FTQ(01行)。然后对运行过程中的全局变量进行初始化(02-05行),其中funcID作为每个状态函数的唯一标识,以便快速访问及找到中间结果与函数之间的对应关系。S为缓存栈,记录当前结点之后需要处理的函数;项为函数的集合,集合中的每一项为一个三元组
分析XML流数据时通过标签的层次值来判断结点之间的结构关系,层次结构关系性质描述如下:
性质1 从一个结点开始标记出现,到该节点结束标记到来之前,所有出现的结点都是该结点的后代,满足A-D关系;如果某一节点和该节点的层次之差为1,则两者之间满足P-C关系。
在自动机运行过程中,具体的状态转换也即函数执行过程如下:
Procedure execFunc
Input:the FT function f, data node n
Output:match result res
01 res=match(f, n);
02 for each function u in res
03 if u.targLevel==n.level
04 res=res ∪ match(u, n);
方法execFunc首先根据自动机实例中的规则将当前结点与函数目标结点进行匹配,获得匹配结果res。因为在森林自动机规则T2-2、T2-3中存在并列谓词的情况下,转换后的状态函数仍需匹配当前正在访问的数据结点,所以通过判断res中是否存在这样的函数,则存在则通过match函数做进一步的处理。
自动机每条规则的处理在match方法中实现:
Procedure match
Input:the MFT function f, data node n
Output:match result set res
01 if f.targetLevel > n.level then
02 res = execute rule f(nil) in FTQ;
03 else
04 res = execute rule f(n) in FTQ;
05 for each function u in res
06 funcID++;
07 add funcID to u;
08 generate subtree st of res;
09 replace f node in T by st;
10 ans = ans ∪ reduce(T);
11 return res;
如果当前处理函数的目标结点层次值大于当前处理数据结点的层次值,则以nil作为输入数据;否则以当前数据结点作为输入进行匹配。
性质2 如果流数据中,层次值从m变化到k,k≤m,则表示在m,m-1,m-2,…,k+1层都不存在数据结点。
匹配结果res中包含3种类型的数据:数据选择查询的结果结点、谓词判断查询的真假值True或者False、转换后的状态函数。为了记录匹配结果中的函数关系和中间结果,将res依据匹配规则右部表达式生成对应的抽象语法树取代T中当前处理函数对应的树结点。基于流数据处理的特点,在得到部分结果时,即对AST进行规约。根据森林自动机处理XPath的规则T1可知,查询结果为多个函数匹配结果的组合,在AST中为第二层的归约结果,所以如果在AST第二层可归约得到结果,即为输出。
例2:针对图1中的XML流数据,给定XPath查询Q1:/person[/p_id[text()=”person0”]]/ name/text(),则程序执行过程如下:
(1)对运行时刻的全局变量进行初始化赋值,funcID=0;S:{<0,q0,1>};
(2)读入数据,S栈顶元素出栈,当前结点与状态函数的目标结点进行匹配;根据匹配结果更新抽象语法树T和栈S。如:
1)读入person结点,其层次值为1,S栈顶元素集合{<0,q0,1>}出栈,依据q0函数的匹配规则,数据结点person与其目标结点相匹配,得到匹配结果(q1(x1)?q3(x1):nil) q0(x2);将T中的q0[0]结点更新为(q1[1]?q3[2]:nil)+q0[3]对应的子树,“+”表示结果连接操作算子;依据目标层次值分组后得到2个集合{<1,q1,2,>,<2,q3,2>}和{<3,q0,1>},按照层次值小的先入栈,层次值大的后入栈的规则,S更新为{<1,q1,2,>,<2,q3,2>}{<3,q0,1>}。
2)读入p_id结点,其层次值为2,S栈顶元素出栈,此时集合中包括q1和q3,根据它们的匹配规则,当前访问结点与q1目标结点匹配,依据匹配结果更新以q2[4] OR q1[5]表达式对应的子树更新T中的q1[1]树结点。q3目标结点与当前访问结点不匹配,依据匹配结果,以q3[6]表达式对应的子树更新T中的q3[2]树结点;新的待匹配函数分组入栈后S情形为:{<4,q2,3>}{<6,q3,2>,<5,q1,2>}{<3,q0,1>};
3)其它结点的处理过程与以上类似,不再给出。注意的是访问到第1个name结点的时候,S:{<8,q2,3>}{<6,q3,2>,<5,q1,2,>}{<3,q0,1>}的栈顶元素中q2函数的目标结点层次值为3,而当前访问结点的层次值为2,所以q2函数匹配时选择以nil为输入的规则。
在初始及以上person,p_id和计算完成后4个时刻抽象语法树T的情况如图3所示。

图3 抽象语法树归约过程
(3)最后得到T如图3中T3时刻所示,根据抽象语法树的计算规则,得到最终结果为JimLi。
2.3 算法分析
基于森林自动机处理流数据的方法,在运行时,随着流数据的到来,对每个数据结点进行分析处理,假设数据规模为n,|Q|为XPath查询Q中的结点数,则算法的时间复杂度为O(n|Q|);在实现中主要采用了栈和抽象语法树两种数据结构,其中栈用以保存后续流数据结点需要匹配的函数,对于XML这样的数据组织结构形式,最大深度为的处理数据嵌套的最大层次值;如果查询结果规模为O(m),则抽象语法树的规模为O(m|Q|),与输出结果相关,而与流数据的规模无关。基于以上分析,可以看出,算法的运行效率和内存占比都与查询和处理结果相关,而与所处理数据规模无关,较好解决了流数据处理中的时空复杂度平衡问题。
3 实验结果与分析
为了验证本文提出方法的有效性和效率,采用通用的XML标准数据集对以下两个指标进行了测试分析:①算法的处理效率也即针对流数据处理的吞吐率;②运行时刻占用内存大小。针对当前XML流数据处理的各种引擎和方法现状,选择文献[4]提供的GCX和文献[5]中的方法命名为FTQ作为对比分析的对象,因为GCX项目的实现表明与其它的流处理引擎如FluXQuery,Galax,MonetDB,Saxon和Qizx/open等相比,GCX在处理速度和内存占比方面都有明显的优势。
3.1 实验环境和数据集
本文以Java语言实现了所提出的方法,具体实验环境配置如下:操作系统为64位Windows 7,CPU Intel i7-4790 3.6 GHz,内存8 G,JDK版本1.7。XML通用数据集选取了DBLP[12],TreeBank[13],XMark[14],通过SAX解析器模拟流数据的到来情形。在吞吐率分析过程中,以这3个数据集的不同规模大小处理时间作对比,程序运行10次,取平均时间作为结果分析。在内存占比分析时,选用XMark作为基准,因为GCX引擎以该数据集作为输入,这样便于对比分析。
3.2 运行效率分析
针对各个数据集的查询用例见表1。这里选择的查询具有一定的代表性,其中QD1和QD2主要考虑的是P-C关系,且DBLP数据量较大,深度较小,主要是横向扩展;TreeBank数据集结构嵌套层次很深,且毫无规律,针对其的查询QT1和QT2主要是考察多个A-D关系的处理情况;XMark数据集属于人工合成数据,兼具了XML以数据为中心和以文档为中心两种类型的文档结构特点,通过其文档产生器不同参数的设定,分别产生了5个不同规模的测试数据,选择的查询QM1和QM2兼具了P-C、A-D和谓词关系,且数据集中符合查询的结果较多,能够对算法进行充分的测试。

表1 测试数据集及查询
图4显示了3个数据集上查询处理的时间,为了节省篇幅,将每个数据集下本文提出的方法FTP和FTQ、GCX两个方法对两个查询的处理放到了一个效果图中。DBLP数据集的规模已经达到1 GB,实验中数据集变化从较小的50 MB开始变化到最大1024 MB;当前能够获得的免费TreeBank数据集最大为82 MB,选取了5 MB起始到最大82 MB的变化范围;XMark通过文档生成器设置不同的参数可以生成不同的规模的数据集,为了充分测试大规模数据集下算法的效率和可扩展性,这里选择了1 GB到100 GB不同规模的数据。从各个数据集的运行时间整体对比看,本文提出的方法与GCX相比,效率上提升在20%-40%之间,因为数据集组织结构的不同,查询表达式的复杂度不同,导致效率比有所不同。但明显的是在TreeBank文档中,因为其深度较大,嵌套结构较为复杂,本文方法在效率的提升更为明显,因为在处理QT1和QT2查询时,表达中包含的均是A-D轴关系,查询处理过程中需要判断的情况较多,这时体现出了森林自动机的优势所在。对于XMark数据量较大时,这种效率优势仍然较为明显,体现出该方法的可扩展性较好。

图4 运行时间对比
3.3 内存占比分析
流数据处理中,内存占比是衡量算法优劣的一个重要指标。流数据可能无限在线到达,算法的空间复杂度应与当前处理数据尤其是分析结果相关,而与历史或未来数据无关。为了分析本文提出方法在运行时刻占用内存的大小,选取了FTQ和GCX引擎作为对比对象。本小节的XMark数据集为输入,针对给定的如下查询:
Q1://site/open_auctions/open_auction[/bidder[personref/personref_person/text()="personXX"]]
Q2://site/closed_autions/closed_aution[/annotation/description/parlist/listitem/parlist/listite/text/emph/keyword]/seller/serller_person
进行处理,运行20次取均值作为结果。这两个查询较长,包含的谓词所需要处理的筛选较多,适合于对于算法内存占比的分析。数据规模选取从100 MB到20 GB,各自运行时内存占比见表2。实验结果表明本文提出的方法FTP及FTQ在处理过程中内存占比随着处理数据量的增加会稍有增加,主要原因是一方面Java虚拟机本身的垃圾回收机制与GCX不同,一些无用的数据会在内存中保留一段时间,另一方面,数据量的增加主要增加了抽象语法树的大小,归约后的查询结果如果不及时转移,会占用部分内存。同时与GCX相比,内存占用也稍高,主要是GCX方法设计了专门的动态垃圾回收机制,能够有效保证内存占比基本保持在常量,这个机制在本文中并没有考虑,这也是需要优化的地方。但整体上看与当前硬件提供的存储能力相比本文方法运行时内存占用还是相当小,数据规模即使增加到GB甚至TB级,该方法也能满足流数据在运行效率和内存占比方面的需求。
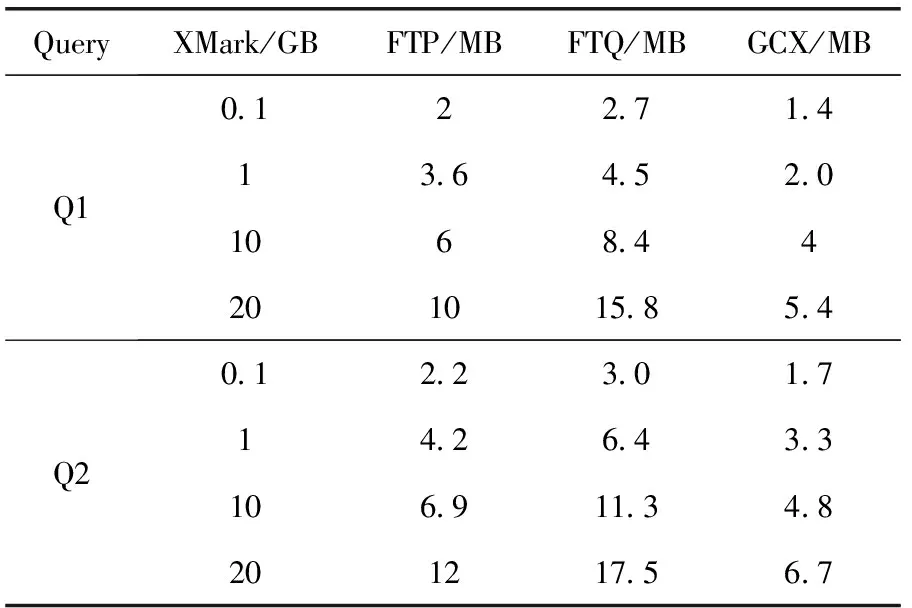
表2 XMark数据集内存占比
4 结束语
XML已经成为Web上多应用、多数据源之间数据交换的标准,流式数据广泛存在于各种监测、分析系统中。针对XML流数据处理过程中数据在线到达,查询处理时效性高,系统可提供的缓存小等问题,提出了基于森林自动机的处理方法。该方法将用户给定的查询根据规则转换为森林自动机,不断接受到来的流数据,事件驱动自动机的状态转换。在自动机运行过程中,通过抽象语法树维护状态函数之间的关系并缓存中间结果;随着抽象语法树的归约,得到结果即进行输出。通过实验分析,与同类算法相比,本文提出的方法吞吐率较高,占用内存缓存量较小,能够满足流式数据处理的需求。
进一步的工作是扩展XPath查询包含操作的范围以及采用相关的优化方法进一步提升森林自动机的运行效率等。
