基于云计算的智能电网大数据处理平台
2018-10-24徐胜超
李 佳,徐胜超
(1.江苏食品药品职业技术学院 信息工程学院,江苏 淮安 223003;2.钦州学院 电子与信息工程学院,广西 钦州 535011)
0 引 言
保证智能电网正常运行的数据包括电压、用户负荷、电量等信息,早期的处理技术有MPI集群计算、Globus网格计算等[1,2],这些技术在十几年前都可以满足电网公司的应用需求[3-5]。然而,这几年随着电网数据,软件容量的增大,早期的技术已经不能满足电网公司的需求。随着云计算和大数据处理等技术的出现与发展,它们被应用到智能电网状态安全与检测等领域[6-8]。
云计算是软件即服务(SaaS)、平台即服务(PaaS)、基础设施即服务(IaaS)、虚拟化Virtualization等技术的跃进或者商业实现的结果[9],而且云计算的某些商业实现部分开放源代码的,所以我们可以采用更加先进、速度更加快的云平台来处理智能电网大数据[10]。
云计算是近年来各大IT公司比较热门的研究内容,因为它提供给客户端的是一种有偿的商业服务,企业有利可图,这些云平台的源代码版权属于各大IT公司,并不对外完全公布,只有少量的开放源代码。通过比较得知云计算的MapReduce规范[11]最早被Google公司用于大规模数据集的并行处理。这一方法构造成本低,搭建容易,而且软件比较先进,因此近年来在大数据处理领域得到了广泛应用。
通过上面的分析,本文提出一个基于云计算的智能电网大数据处理平台SP-DPP(smart power system big data processing platform in cloud environment),结合智能电网大数据的状态安全分析的特点,详细描述了该平台的设计思想与实现过程,然后利用云计算Apache的Hadoop中的MapReduce规范开源代码实现了该平台,最后的案例程序与测试结果验证了智能电网大数据处理平台SP-DPP的正确性与高性能。
1 智能电网大数据处理的数学模型
1.1 大数据处理的数学模型
判断一个智能电网的状态,最常用的数据模型是潮流计算[12,13]。经典的潮流方程的极坐标形式为
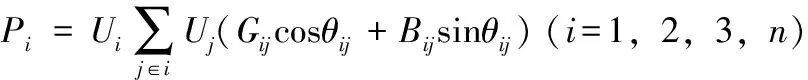
(1)

(2)
其中,Pi,Qi,Ui,Uj,Gij,Bij,θij分别是智能电网的参数,对电网的状态进行判断,往往是设置P,Q,U,θ这4个参数中的任何两个,然后通过方程组的约束条件,求解出其它的另外两个参数。如果方程组中的n很大,那么智能电网的规模也很大,近年来各个电网公司的调度中心经常需要判断电网的运行情况,如果规模很大,该方程组的计算量将十分巨大,如果能够在规定的时间内求出潮流计算的结果,是具有很大的现实意义[14]。本文的智能电网大数据处理就是基于上述数学模型。
1.2 智能电网大数据的划分
我们可以考虑主-从模式的编程模型的思路进行智能大数据的任务划分。如果每次设置不同的电网异常状态的预想事故,把每一个预想事故都划分为一个子任务形式,这个子任务类似于MapReduce中的Mapper,Mapper子程序代码通过串行潮流计算就可以得到不同一组电网运行状态。不是每个预想事故都可以导致智能电网出现异常,所以还需要进行汇总判断。Reducer这种汇总归约功能正好完成状态的判断汇总。
如图1所示为面向MapReduce的智能电网大数据处理的划分模型。每个Map分别解方程组约束中的潮流子结果,得到一个特定的电网运行状态,每个Reduce对应于潮流计算的判断各个参数指标是否越界或者异常,最后由一个主程序控制整个应用程序的运行流程即可完成整个智能电网的运行状态异常检测。
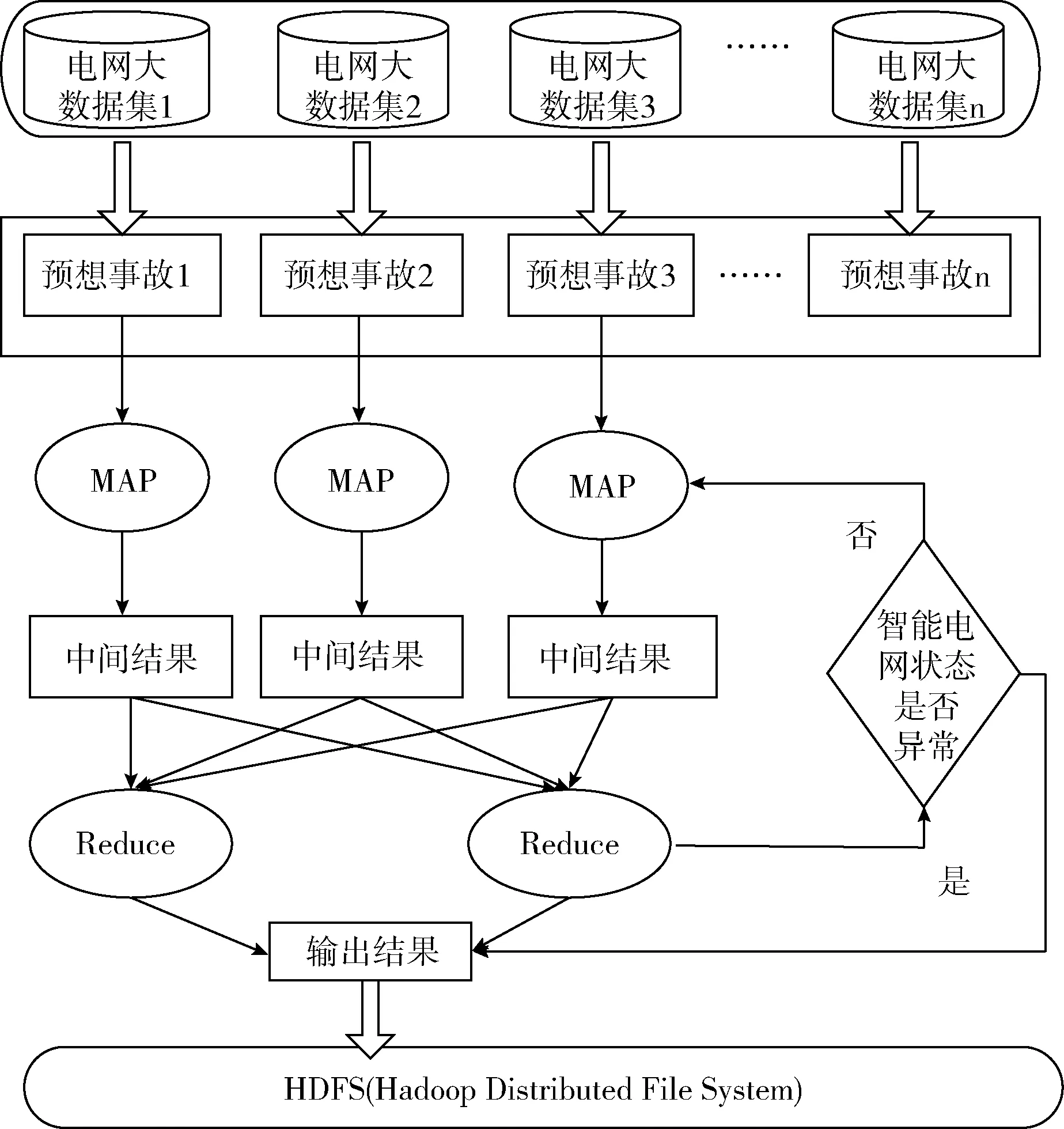
图1 智能电网大数据的任务划分
2 SP-DPP平台的设计
2.1 平台的总体设计思路
我们设计SP-DPP云平台主要基于下面3点考虑:①SP-DPP云平台与之前老旧的计算平台不同之处在于它是把互联网上的IT相关的能力以服务的方式供用户使用,用户是通过注册服务,访问服务的形式来使用云平台;②SP-DPP云平台中具有存储智能电网大数据的稳定可靠的中心节点,主要以集群服务器组成;③SP-DPP平台在提交和分配大数据处理任务的时候,是把任务往大数据中心节点上调度,这点与传统的网格不一样,网格平台中往往是把应用相关的数据(参数文件、配置文件、代码文件)往工作机节点上调度[15];按照这3个原则与思路,我们设计的SP-DPP云平台中网络体系结构如图2所示。
智能电网大数据处理云平台SP-DPP逻辑上划分成4个模块:大数据存储与管理模块、任务分配与调度模块、大数据执行模块和客户端模块。该SP-DPP云平台的主要功能是满足智能电网海量数据处理的需求,通过计算出潮流计算的结果,对智能电网的状态安全进行分析与监控。
2.2 大数据存储与管理模块
大数据的存储与管理功能是对要处理的大数据采用分布式文件系统DFS(distribute file system)进行存储,同时对文件系统的名空间进行管理。DFS的设计与选取必须比以前的集群并行文件系统更加先进与方便,这里我们充分利用云计算的虚拟化技术[16],DFS自动为系统管理这些TB到PB级的海量数据,程序设计中看到的是一个文件系统而不是很多文件系统,对用户透明。例如SP-DPP云平台要获取/dfs/tmp/file1的数据,程序设计中引用的是一个文件路径,但是实际的大数据存放在很多不同的物理节点上。
另外对DFS,该模块还需要对文件系统的命名空间进行管理,这样大数据处理的任务分配与调度模块、工作机模块就可以访问到这些数据。

图2 基于云计算的智能电网大数据处理平台SP-DPP
2.3 任务分配与调度模块
对于SP-DPP平台来说,要完成一个大数据的处理,首先是大数据存储,然后就是任务分配与调度,最后是大数据处理的执行。任务分配与调度是最关键的模块。任务分配与调度模块主要功能是对平台的大数据处理的大任务进行划分,然后调度这些子任务到空闲工作机上执行。虽然其功能比较单一,但是其考虑的问题是很多的。
首先是任务划分的问题。并不是所有的大数据处理类应用都可以在SP-DPP平台上运行,要根据应用的特点进行划分。由于智能电网的潮流计算的大数据处理在划分任务时,可以把每一个电网预想异常情况的初始参数设计为一个子任务,并作为最基本的工作单元进行处理,任务调度模块的功能就是要高效地调度这些工作单元到工作机上执行。
其次是调度策略问题,调度策略的设计需要综合考虑工作机的硬件配置情况与软件信息。硬件配置情况包括CPU的主频、内存大小、空余磁盘空间等。软件信息包括CPU的利用率高低、网络带宽情况、负载大小情况、可靠性情况。最终目标是使工作单元在各个物理节点之间的迁移方法更加灵活,目前IBM公司的“蓝云计划”中的虚拟机软件就做到了这点[17]。
然后就是容错的问题。这里SP-DPP平台使用冗余的方式和分布式存储来处理,这是云计算的特点。容错策略还必须自动检测到失效节点,将失效节点排除,不影响SP-DPP平台的主控任务的正常运行。
最后是负载均衡问题,即将多个负载不是很重的虚拟机计算节点合并到同一个物理节点上,提高各个真实的物理节点的硬件资源的利用率。
另外任务分配与调度模块设计中还必须根据当前文件系统中文件所在的位置和大小决定如何创建其它的工作机,并对工作机大数据处理的执行状态进行监控。
2.4 大数据处理执行模块
由于SP-DPP云平台使用虚拟化技术,虚拟化技术包括桌面虚拟化、系统虚拟化等,桌面虚拟化是用户使用云资源的重要方式。SP-DPP云平台中的智能电网大数据处理的都是在虚拟机上运行的,执行模块的主要功能就是负责接收调度模块分发的工作单元,采用虚拟机的方式执行,并将执行状态和临时结果向上传递给调度模块中的主控程序。执行模块中子任务的数据是从大数据存储与管理模块中获取的,其执行完后,结果继续存储在大数据服务器中。
2.5 客户端模块
客户端是互联网上的用户访问SP-DPP云平台的方式,SP-DPP云平台可供客户端访问。客户端可以按照服务等级协议(service level agreements,SLA),采用按时付费(pay-per-use,PPU)的模式来管理。
3 SP-DPP平台的实现
3.1 编程模型的实现
对于一个并行大数据处理问题,其编程模型主要有主-从模式(Master-Slave)、映射归约模式(MapReduce)、分治模式(Divide-Conquer)等,这类编程模型中都有类似工作单元(Work Unit)的独立子任务执行功能,随着云平台中数据存储技术、数据管理技术的发展,云平台处理的大数据之间还存在依赖关系,现有的先进软件都允许子任务节点之间进行交互,这样使得云平台可以处理的应用类型大大增加。
在实现的SP-DPP智能电网云平台时,我们利用了Apache的开源的云计算平台Hadoop中的MapReduce规范。值得说明的MapReduce只是云计算的编程模型的一种,微软公司提出的DryaLINQ是另外一种并行编程模型,DryaLINQ局限于.NET的LINQ(language integrated query)系统同时并不开源,从而限制了它的发展前景。Google公司的MapReduce软件更加先进与成熟,但是其代码不对外界公布。
MapReduce编程规范[18]是分布式大数据存储、任务调度、任务执行、容错、负载均衡的整合体,在SP-DPP平台中,应用程序编写人员只需将精力放在Mapper和Reducer程序的编写上即可完成智能电网大数据状态安全的分析。
3.2 各个模块的实现
首先是大数据的存储与管理的实现,其实Google公司和IBM公司都有云计算的内部大数据的存储与管理的实现项目,例如Google File Sysyem项目、BigTable项目,IBM公司的基于块设备的存储区域网络SAN等。前面这些都不开放源代码,这个功能的实现我们选择了开源的Hadoop的HDFS,SP-DPP平台中利用HDFS可以部署主控服务器NameNode、数据服务器DateNode、作业服务器JobTracker和任务服务器TaskTracker等角色,我们选择两个角色DateNode、NameNode即可完成大数据的存储,同时对文件系统的命名空间进行管理。
其次是任务分配与调度模块的实现。根据我们上一节描述的原则,我们也选择了Hadoop的规范中的JobTracker角色来完成。在任务分配的时候,首先需要对电网大数据的分片进行设置,预先放置在HDFS中。各种调度策略、负载均衡策略、容错策略都是Hadoop中原始策略,如果改进这些策略需要对开源代码进行分析与更改才可以达到更好的效果。值得指出的是Hadoop的MapReduce规范里JobTracker是用于调度和管理它下属的TaskTracker,TaskTracker负责执行工作单元(Work Unit),它运行在DataNode上,即大数据存储的物理节点上要同时部署TaskTracker和DataNode。
工作机模块的实现使用了Hadoop的规范中的TaskTracker角色来完成。相对于JobTracker的主控任务来说,TaskTracker是从属任务,运行在从属节点上,主要负责接收JobTracker分发的子任务并执行,并将执行状态和结果向上传递给JobTracker。最后在Hadoop的规范中还有一个作业(Job)的提交者,即是客户端。
我们实现的SP-DPP云平台中各个功能模块的逻辑关系如图3所示。实线框Master是一个实际的物理节点,实现的是智能电网大数据任务分配与调度模块,实线框Slave也是一个实际的物理节点,它实现了工作机模块和大数据存储与管理模块,虚线框都是虚拟的节点,Cilent客户端是用户与SP-DPP云平台的交互服务窗口,是实际的物理节点。
3.3 电网大数据处理的编码
前面我们通过配置MapReduce编程环境,即可完成SP-DPP平台基本软件环境的搭建。接着需要利用MapReduce对智能电网的潮流计算程序进行编程。需要分别书写Map函数的代码和Reduce函数的代码。
Map函数相应的伪代码如图4所示。
Reduce函数相应的伪代码如图5所示。
上述代码的编写需要一定的MapReduce的知识,Map函数的代码主要是针对潮流计算的串行计算的代码按照Mapreduce的语法进行移植。Reduce函数的代码书写需要采用简单的主-从并行程序设计的思路。
另外由于Hadoop的MapReduce是采用跨平台的Java语言,由于历史的原因很多潮流计算的串行源代码是C++语言书写,这里我们还利用了JNI技术在Java环境下调用的C++代码。把这些代码输入到Mapreduce环境下,Hadoop就可以利用NameNode、DateNode、JobTracker和TaskTracker等角色透明的执行。
3.4 SP-DPP平台的优势
本文搭建的SP-DPP云平台比以前的网格计算、P2P计算、集群计算软件上要先进,本文的大数据处理的任务分配与调度模式还改变了传统的计算模式,使大数据处理可以自动地更加靠近存放智能电网数据的节点。早期的并行编程都是数据将往任务往上调度,SP-DPP平台是将任务往数据上调度,因为数据容量太大,移动与传输速度太慢,将计算尽可能“本地化”以节约网络带宽而获得高效的计算速度[19]。

图3 SP-DPP平台实现模块的逻辑关系

图4 Map函数的伪代码

图5 Reduce函数的伪代码
4 SP-DPP平台的搭建与测试
4.1 智能电网大数据的选取
本文选择了IEEE 118节点的智能电网的基本数据,按照式(1)和式(2)的方程组约束来计算电网的运行状态,要处理的电压U,功率P,用电负荷Q等预先设置电网的预想事故为5*104个。这些数据的容量为15 GB,相当与每个预先事故容量大为0.3 MB。
4.2 大数据处理平台硬件的配置
根据前面几节分析的SP-DPP的设计与实现思路和网络体系结构,网络拓扑结构,我们选择了学校的一个机房内的机器组成。SP-DPP平台中共有9个实际的PC机物理节点,这9个机器在处于同一个局域网内,云服务器主机的配置为:Intel Xeon E3-1220 v5 3.0 GHz四核,内存:8 G DDR4,硬盘:1*Intel企业级SSD,1*SATA 1T,网卡:2*千兆网口;工作机节点的硬件配置如下:CPU型号Intel Xeon E5 3.0 GHZ;内存为8 GB。硬盘容量为1 TB;这些节点之间通过局域网内的1台千兆交换机相联。
4.3 大数据处理平台的软件环境的建立
9台PC机都安装RedHat Linux操作系统,Hadoop版本为1.0.4,JRE环境为1.6,用户只要继承MapReduceBase,分别实现Map和Reduce的两个类,即可编写Map和Reduce的程序[20]。
根据Apache的Hadoop规范,对于1个Master机器,部署NameNode和JobTracker,8个Slave机器全部部署DataNode和TaskTracker。值得注意的是Google公司的MapReduce规范里数据服务器DataNode与任务服务器TaskTracker是部署在不同的机器上的,Apache的Hadoop规范里Data-Node和TaskTracker是同一个节点,这一点在搭建SP-DPP云平台的时候必须注意,详细软件配置见表1。
4.4 吞吐量的测试
吞吐量是在相同的时间内,我们调整SP-DPP云平台的实际物理节点个数,完成预想事故个数的情况比较。实验结果见表2,我们设置了运行时间为2000 s。表2可以看出SP-DPP平台完成预先设置的电网故障个数随着物理节点的增加稳定增加,基本成线性变化,这个实验结果和MapReduce主-从模式的编程模型在预想性能增加上相符合。
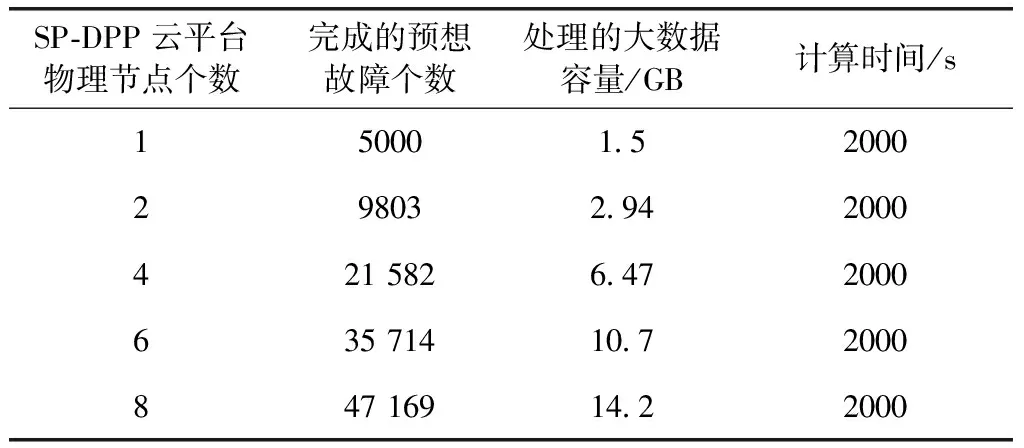
表2 智能电网大数据处理吞吐量的测试
4.5 执行时间与加速比
执行时间测试在SP-DPP平台中是指通过调整和改变物理节点个数,设置一个固定的预想电网故障数量,测试执行时间的长短。加速比的计算公式如下
(3)
执行时间测试结果见表3。加速比测试结果如图6所示。
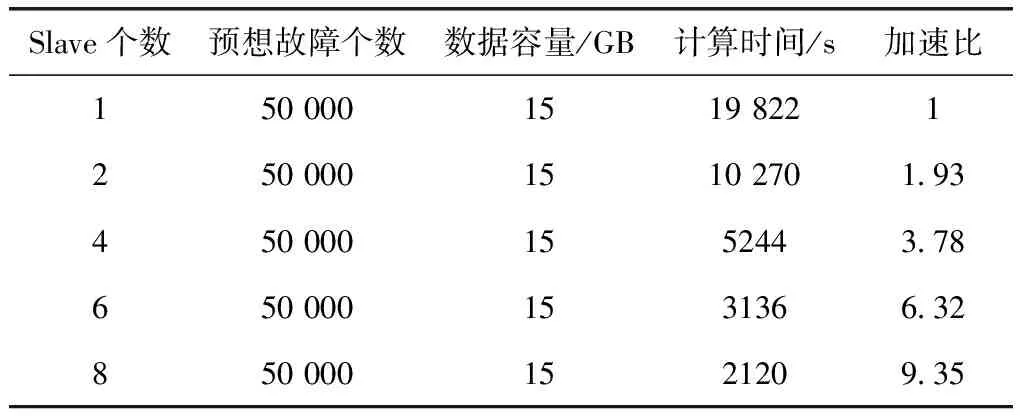
表3 调整物理节点的Slave个数执行时间测试
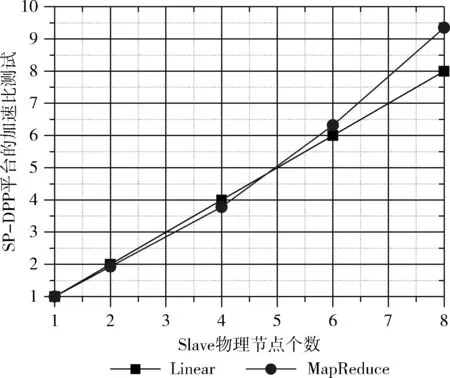
图6 SP-DPP上智能电网大数据处理的加速比测试结果
从表3中可以看出,整SP-DPP平台进行智能电网状态安全分析的执行时间随着Slave物理节点的增加而稳定的缓慢降低,根据式(3)Speedup随着物理节点数n保持稳定的增加,接近于线性Linear,当节点个数继续增加时甚至超过了线性增长,如图6所示,如果在云平台上部署更加多的物理节点,SP-DPP可以在很快的时间内完成所有工作单元的计算,也就是说电网公司的调度中心可以在可以接受的时间范围内判断整个智能电网是否安全运行。
5 结束语
本文提出了一个基于云计算的智能电网大数据处理平台SP-DPP。通过对电力系统潮流计算测试,实验结果表明SP-DPP云平台具有良好的吞吐量和加速比。值得说明的是SP-DPP平台不针对特定的应用而设计,SP-DPP平台上可运行的应用不局限于潮流计算,任何具有Master-Slave特色的并行应用都可以通过任务划分与数据划分,利用Map-Reduce的编程思想在SP-DPP平台上完成计算。下一步的工作是利用Spark或者更新版本的Hadoop的MapReduce规范完成平台搭建[21]。
