一种高效的Redis Cluster的分布式缓存系统①
2018-10-24刘利娜刘学敏张士波
李 翀, 刘利娜,2, 刘学敏, 张士波
1(中国科学院 计算机网络信息中心, 北京 100190)
2(中国科学院大学, 北京 100049)
随着Web2.0和大数据时代到来, 单机缓存系统已无法承受当下大型互联网应用高并发、大数据、快速响应的需求.分布式缓存[1]是学术界和工业界公认的解决方案, 通过将数据和请求分布到不同节点, 实现水平扩展和负载均衡, 进而提高并发数、数据吞吐量和快速响应能力.目前分布式缓存系统的主流实现方式主要有两种:基于Memcached[2]和基于Redis[3]的分布式缓存系统.Memcached是一种开源高性能分布式内存对象缓存系统, 通过减少数据库负载来实现对动态Web应用加速.但由于其支持数据类型单一、客户端实现分片方式导致集群扩容困难、一致性维护成本、不支持数据持久化和内存管理方式导致内存浪费等问题.Redis是一种开源基于内存键值对存储数据库, 具有分布式缓存、高并发快速访问、丰富的数据类型、数据持久化及备份机制、消息队列机制、高扩展性和可维护性等优点, 使得基于Redis构建分布式缓存系统开始成为热点, 其分布式主要通过分片实现, 具体方式主要有三种:基于客户端、基于Proxy和基于Redis Cluster[4,5]的分片方式.
基于客户端的分片方式, 因其水平扩展困难、业务变更导致不可控等原因, 实际应用较少.而基于Proxy的分片方式在开发简单, 运维便捷, 对应用几乎透明, 相对比较成熟, 例如 Twemproxy[6]和 Codis[7].但是随着系统规模增大, 逐渐暴露出代理影响性能、组件较多复杂, 对资源消耗较大、扩展复杂、代码升级困难、硬件环境要求高等缺点.
Redis Cluster成为研究热点.Redis3.0 以后开始支持 Redis Cluster, 目前最新稳定版本 Redis4.0于2017年7月发布, 因刚发布不久, 可借鉴解决案例不多.同时, Redis4.0 Cluster官方给出的 Redis Cluster部署方案比较单一, 集群数量很大时部署不便, 也没有较好的可视化监控和管理工具, 当业务扩大, 集群节点成百上千的时候, 命令行运维工具将会十分困难.基于以上原因, 本文基于Redis4.0研究并实现了一种Redis Cluster分布式缓存系统[8,9], 集成了CacheCloud[10]开源可视化工具进行实时监控和管理, 并进行了功能和性能验证.实验表明, 该系统各功能高效运转, 管理便捷,可扩展性强, 体现了高可用、高性能和高扩展的特点.
1 Redis Cluster技术研究
Redis Cluster是基于 Redis 的一个分布式实现, 由Redis官网推出;它引入了哈希槽的概念;支持动态添加或删除节点, 可线性扩展至1000个节点;多个Redis节点间数据共享, 部分节点不可达时, 集群仍然可用;数据通过异步复制, 不保证数据的强一致性;具备自动Failover的能力;客户端直接连接Redis Server,免去了Proxy的性能损耗.
1.1 工作原理
Redis Cluster是一种去中心化结构, 如图 1 所示,所有节点之间互相连接, 通过Gossip协议来发布广播消息, 每间隔时间内互发PING/PONG心跳包来检测其他节点状态, 来保持信息同步.客户端直接连接任意Redis Server, 并由 Redis Cluster路由转发客户端请求到真正请求数据的节点.
Redis Cluster中每个Redis节点需要打开两个TCP连接, 一个是为客户端提供服务的常规端口, 另一个是节点间互相通信所需要的端口.这两种端口之间偏移量是 10 000.对于分片, Redis Cluster并没有使用一致性哈希来实现, 而是引入了哈希槽的概念.Redis Cluster共有 16 384个哈希槽, 每个 Master节点只负责一部分哈希槽, 每个Key通过公式(1)计算出属于哪个节点.
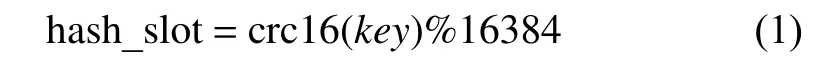

图1 Redis Cluster拓扑图
1.2 设计目标
CAP 即 Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)[11,12], 在分布式系统中不可兼得.Redis Cluster的设计目标主要是高性能、高可用和高扩展, 但牺牲了部分的数据一致性.
(1) 一致性
是指对所有节点数据访问一致性.Redis Cluster无法保证强一致性.由于集群使用异步复制, 在某些情况下, Redis Cluster可能会丢失系统向客户确认的写入.性能和一致性之间需要权衡, Redis集群在绝对需要时支持同步写入的时候, 可以通过WAIT命令实现, 但是这使得丢失写入的可能性大大降低.
(2) 可用性
可用性是对集群整体是否可用的衡量, 即当集群中一部分节点故障后, 集群整体是否还能响应客户端的读写请求.Redis集群在分区的少数节点那边不可用.一个由N个主节点组成的集群, 每个主节点都只有一个从节点.当有一个节点被分割出去后, 集群的多数节点这边仍然是可访问的.当有两个节点被分割出去后集群仍可用的概率是 1–(1/(N×2–1)).如一个拥有6个节点的集群, 每个节点有一个从节点, 那么在两个节点从多数节点这边分割出去后集群不再可用的概率是1/(6×2–1) = 0.090909, 即有大约 9% 的概率.
(3) 高性能和线性扩展
当操作某个 Key 时, Redis Cluster节点不会像代理一样直接找到负责这个Key的节点并执行命令, 而是将客户端重定向到负责这个Key的节点.通过对Key的操作, 客户端会记录路由信息, 最终客户端获得每个节点负责的Key最新信息, 所以一般情况下, 对于给定的操作, 客户端会直接连接正确的节点并执行命令.Redis Cluster不支持同时操作多个键值, 避免了数据在节点间来回移动.但普通操作是可以被处理得跟在单一Redis上一样的, 这意味着在一个拥有N个主节点的Redis集群中, 由于Redis的设计是支持线性扩展的, 所以同样的操作在集群上的表现会跟在单一Redis上的表现乘以N一样.
节点定时向其他节点发送ping命令, 它会随机选择存储的其他集群节点的其中三个进行信息“广播”,广播的信息包含一项是节点是否被标记为PFAIL/FAIL.如图 2 所示, 超过一半的 Master节点也就是A和B节点同时判定C节点失效, 那么C节点将会被标为FAIL, 这个节点已失效的信息会被广播至整个集群, 所有集群中的节点都会将失效的节点标志为FAIL, 即失效.又如图中B节点收到A节点判定失效,此时被标为PFAIL状态, 等待其主他节点共同判定后才能决定是否失效.

图2 Redis Cluster容错图
如果集群任意Master挂掉, 且当前Master没有Slave, 该 Master对应哈希槽无法使用, 集群不可用.如果有Slave节点, 将会进行 Slave选举, 最终选择Slave成为主节点.如果集群超过半数以上Master挂掉, 无论是否有Slave集群进入fail状态.
2 系统设计与实现
2.1 集群架构设计
Redis Cluster搭建于 4 台虚拟机上, 虚拟机具体信息见2.2运行环境中的表2.由于Redis是单线程模型,一个Redis服务进程只会使用一个内核, 为了减少线程切换的开销, 提升Redis的吞吐量和优化Redis性能,同时考虑到虚拟机内核数和内存大小, 因此集群设计为12个主节点, 每个节点对应Maxmemory为512 MB, 每个主节点对应两个从节点, 集群共36个节点,任意节点之间通过 Cluster Bus, 即集群总线, 互相连接.集群主从节点详细信息见表1, 图3是集群架构缩略图, 其中数字, 如:8000, 为虚拟机端口.

表1 Redis Cluster节点信息
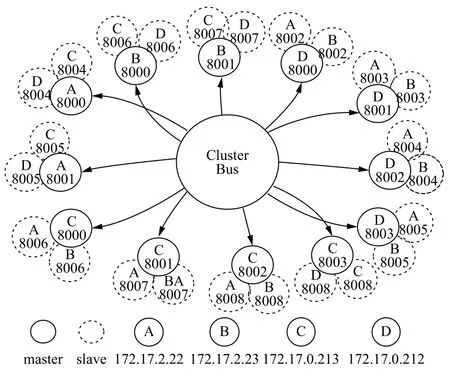
图3 Redis Cluster架构缩略图
搭建 Redis Cluster是基于 Redis最新版本 4.0, 具体版本为 Redis 4.0.1, 由于 Redis Cluster搭建依赖Ruby环境, 所以使用了Ruby2.5.0版本.
2.2 运行环境
系统运行环境通过4台服务器模拟, 虚拟机信息如表2所示.
2.3 配置信息
(1) Linux 系统性能配置
1) sysctlvm.overcommit_memory=1, 该设置用来防止内存申请不到发生卡死, 造成fork失败的情况.
表2 服务器集群环境
2) sysctlvm.swappiness=20, 当 swappiness 为 20 时表示内存在使用到80%的时候, 就开始出现有交换分区的使用.Redis运行时根据此数据来选择是否将内存中数据swap到硬盘.
3) Transparent Huge Pages (THP)[13]Linux kernel在2.6.38内核增加了THP特性, 支持大内存页(2 MB)分配, 默认开启.当开启时可以降低 fork 子进程的速度, 但 fork操作之后, 每个内存页从原来 4 KB变为2 MB, 会大幅增加重写期间父进程内存消耗.操作命令如下:

4) sysctl -w net.ipv4.tcp_timestamps=1, 表示开启对于TCP时间戳的支持, 若该项设置为0, 则下面一项net.ipv4.tcp_tw_recycle=1设置不起作用.
5) sysctl -w net.ipv4.tcp_tw_recycle=1, 表示开启TCP 连接中 TIME-WAIT sockets的快速回收.对于Redis客户端连接数比较多时, 释放连接数.
6) sysctlnet.core.somaxconn=65535, 结合 Redis 配置参数tcp-backlog, 当系统并发量大并且客户端速度缓慢的时候, 设置这二个参数.主要为了提高Redis的并发数.
(2) CPU 绑定
Redis是单线程模型, 一个Redis服务进程只会使用一个内核, 为了减少线程切换的开销, 提升Redis的吞吐量和优化Redis性能, 因此, 选择将Redis进程绑定到固定CPU上.以下是具体绑定步骤:
1) 从获取 Redis 节点 PID:ps -ef | grep redis;
2) 查看 CPU 信息:cat/proc/cpuinfo;
3) 绑定 CPU:taskset-cp x PID
(3) Redis配置信息
以172.17.0.213:8000节点为例, 其他节点配置除了端口号、bind绑定的IP和PID、RDB、AOF、log等文件名称不一样外, 其他信息一致.

#考虑安全性问题
port 8000#节点监听端口, 安全起见, 不使用默认6379
bind 172.17.0.213#绑定内网 IP, 防止外网访问, 防攻击
protected-mode yes#当开启后, 禁止公网访问Redis
tcp-backlog 65535#确定TCP连接中已完成队列长度
tcp-keepalive 300#周期性检测客户端是否还处于健康状###态, 避免服务器一直阻塞
maxclients 1000000#最大客户端连接数, 提高并发量
cluster-node-timeout 15000
##集群节点的不可用时间(超时时间), 超过这个时间就会##被认为下线, 单位是毫秒
cluster-slave-validity-factor 1
#集群主从切换的控制因素之一, 若大于0, 主从间的最大#断线时间通过node timeout*cluster-nodetimeout来计算
cluster-migration-barrier 1
##与同一主节点连接的从节点最少个数
cluster-require-full-coverage no
#默认值为yes, 全部hash slots都正常集群才可用,若为##no, 那么可以允许部分哈希槽下线的情况下继续使用
maxmemory512M#节点最大使用内存
maxmemory-policy volatile-lru#超出最大内存后替换策略
requirepass, ./z#2kknsl;aksKm-0q8%^&#提升安全性
##########################################
2.4 集群管理
CacheCloud是用来监控和管理Redis Cluster的一个开源工具.在172.17.0.212虚拟机上搭建CacheCloud,并将Redis Cluster36个节点作为一个应用导入至CacheCloud, 开始收集 Redis Cluster节点数据, 进行实时监控Redis Cluster整个集群状态.图4、图5和图6展示了Redis Cluster接入CacheCloud之后的部分功能图, 可以实时在图形化界面查看Redis Cluster拓扑图、节点流量监控、客户端连接统计等信息, 还可以进行相关管理.
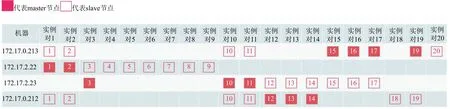
图4 Redis Cluster – CacheCloud 应用节点拓扑图

图5 Redis Cluster – CacheCloud 应用网络流量图
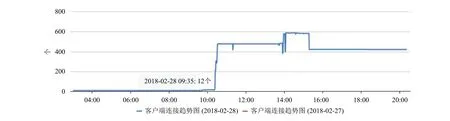
图6 Redis Cluster – CacheCloud 客户端连接统计图
3 测试与分析
本部分工作分别以Redis Cluster功能验证和性能测试展开.功能测试主要针对系统可用性、故障自诊断和智能恢复、动态扩展、配置管理等管理功能进行验证, 验证工具采用管理工具CacheCloud.性能测试分两个部分:基于 Redis-Bechmark 对 Redis Cluster本身进行不同命令请求数的QPS测试;和业界较成熟的Codis分布式缓存系统进行并发响应时间对比测试实验对比.
3.1 Redis Cluster功能验证
CacheCloud可以查看Redis Cluster实时全局信息, 包括应用主从节点数, 运行状态等, 如图 7.在基准测试时, 整个集群的命令分布及命中率都实时反映在了页面上, 说明了系统的可用性和高效性.图8展示了CacheCloud对Redis Cluster具体节点的动态扩展、Master/Slave动态切换、添加和删除节点、实例的启动和下线、以及故障转移相关操作等, 实验表明, 各指标状态稳定、功能正常.

图7 Redis Clsuter全局信息图
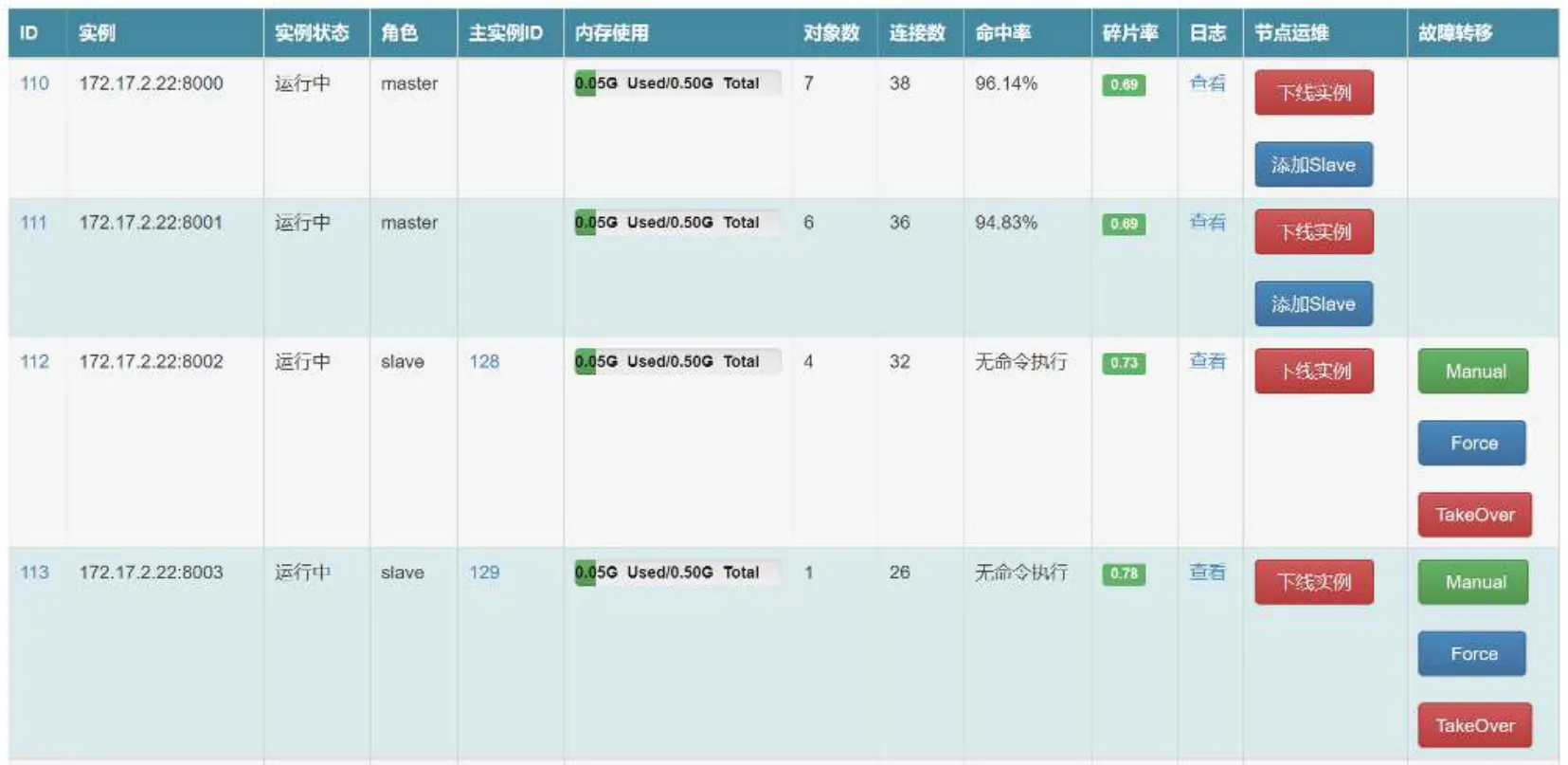
图8 RedisCluster-CacheCloud 应用实例管理
3.2 Redis Cluster性能测试
Redis-benchmark是官方自带的Redis性能测试工具, 可以有效的测试Redis服务的性能.图9、图10和图11分别为使用redis-benchmark对Redis Cluster节点主要命令的QPS统计信息, 当请求数Requests数分别为 100、101、102、103、104、105、106、107和108时, 基准测试命令 PING_INLINE、PING_BULK、GET、SET、INCR、LPUSH、RPUSH、LPOP、RPOP、SADD、HSET、MSET等对应的QPS趋势图,表3是各命令 QPS具体值, 从而从实验验证了Redis读和写的高效响应速度.
3.3 性能对比(Redis Cluster vs Codis)
为和业界较成熟的Codis作性能对比, 在4台虚拟机上同时搭建了Codis集群.Codis成员详细信息见表4, Codis-group中主从节点详细信息见表5.
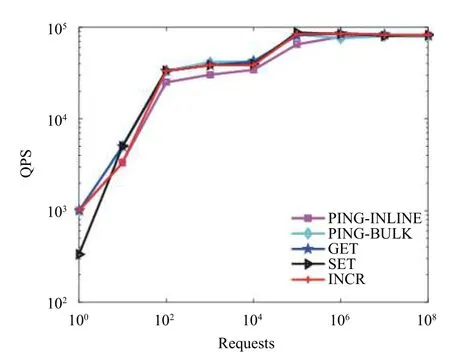
图9 Redis Cluster各命令 QPS (a)

图10 Redis Cluster各命令 QPS (b)
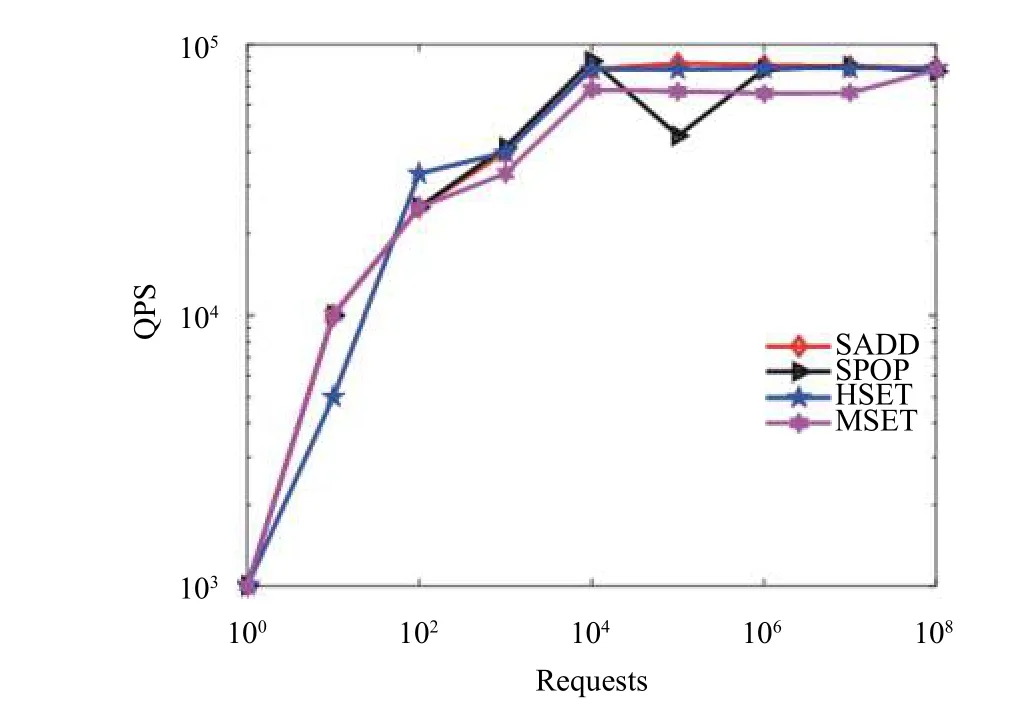
图11 Redis Cluster各命令 QPS (c)
Codis集群成员为:36个redisserver(其中12个Master节点, 24 个 Slave节点, 分 12 组, 每组 1 主 2 从),3 个 codis-proxy, 3 个 Zookeeper, 1 个 codis-dashboard,1 个 codis-fe, 1 个 codis-ha.
对Redis Cluster和Codis分别以客户端并发数为100、101、102、103、104、105、106和 107时, 测量Redis Cluster和 Codis集群响应时间.图 12 为 Redis Cluster和Codis响应时间对比图.实验结果表明, 当并发请求数为 10 000 及以上时, Redis Cluster的响应时间明显优于Codis, 这是因为Codis通过代理连接, 性能有所损耗.因此, 基于 Redis Cluster的分布式实现方式简单且高效.

表3 Redis 各命令 QPS
4 结论与展望
本文主要做了三个方面工作:研究了分布式缓存系统并基于最新版Redis4.0构建了Redis Cluster分布式缓存系统, 对其可用性、水平扩展、数据一致性及故障转移做了验证;基于Redis自身特点, 从Linux层面、Redis Cluster本身做了配置优化;集成了开源工具 CacheCloud 对 Redis Cluster进行监控和管理, 弥补了其本身在可视化管理方面的欠缺.实验表明, Redis Cluster在高并发时响应速度要明显优于Codis, 这一定程度上牺牲了数据强一致性.同时, 其丰富的数据类型、数据持久化及备份、消息队列、高扩展性等特性,使得Redis Cluster分布式缓存更加先进和完善.
Redis 4.0新增了模块机制、部分复制(PSYNC2.0)、混合RDB-AOF持久化策略、更优的缓存驱逐策略,兼容NAT和Docker, 但在有些方面还有待验证和提升.下一步将结合实际应用, 在数据一致性、消息队列和Docker相结合方面做进一步研究和提升.

表4 Codis集群组成成员信息

表5 Codis-group 主从节点信息

图12 并发请求响应时间对比图
