基于蚁群算法的排课系统模型设计
2018-10-23唐崇华
唐崇华
(鞍山师范学院 商学院,辽宁 鞍山 114007)
高校每一学期末均需要进行下学期教学工作计划的制定,制定教学计划是教务管理工作中的首要步骤,是其他各类教学活动有序进行的前提条件.教务管理员根据人才培养方案制定并下达下学期教学任务书,并根据教学任务书进行课表的安排.高校内不同学院、专业的课程多种多样,既有全校各专业均需要开设的通识教育课程,也有根据专业培养方案设置的专业课程.进行课表的安排时需要考虑课程特点、授课教师、开课班级、教室条件等多方面约束,存在着大量纵横交错、相互制约的不确定因素.
排课是基于时间表的多约束、多目标优化问题.在计算机应用范畴内被证明是一个NP完全问题(Non-deterministic Polynomial,即多项式复杂程度的非确定性问题).蚁群算法由于其自身的特点比较适合于解决这类问题.
1 蚁群算法
1.1 蚁群算法简介
蚁群算法是一种用来寻找优化路径的概率型算法,由Marco Dorigo于1992年提出,其本质是一种启发式全局优化算法[1].蚁群在不同的生活环境内,总能在较短的时间内找到距离食物源最近的路径,并能通过信息素的传递和感知形成正反馈机制,引领整个蚁群沿着最短路径行进.抽象蚁群的这种自然行为习惯,用蚂蚁的行走路线表示可行解,整个蚁群的所有路径构成解空间.待蚁群在正反馈作用下集中到最佳路径上时,即为最优解.
1.2 蚁群算法在排课系统中的应用
为将蚁群算法应用于排课系统模型,需将排课问题空间转换为图结构[2].可将排课问题空间用简化观点描述为二部图模型.二部图又称为二分图,是一种特殊的图形结构,由互不相交的两个结点集构成,图中每一条边的两个顶点分别属于这两个结点集[3-5].
由于需要安排的课程在教学计划制定时已经将对应的开课班级、授课教师确定好,所以排课问题解空间就可以简化为<课程,班级,教师>和<时间段,教室>两个抽象结点集合的笛卡儿积,分别用C和P表示.其中,C表示课程、班级、教师所构成的需排课结点,P表示所有可用时间段和可用教室的组合结点集合.
将排课问题抽象为C和P构成的二部图[2],如图1所示.根据实际情况,如教室容纳人数、是否为所需要教室类型、学生和教师是否在同一校区等约束条件,将C和P中的结点连接起来,并用期望值作为权值,即可采用蚁群算法在图1中搜索出最优解.
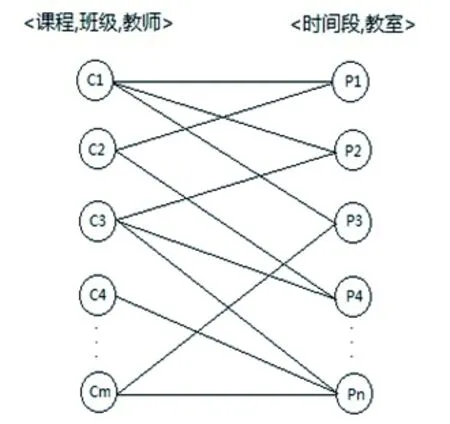
图1 排课解空间的二部图
2 排课约束
排课问题的解空间并不是C、P集合的满映射,需要满足一定的约束条件[2].如:
(1)一个专业的一个班级在一个时间段有且仅有一门课程;
(2)一位教师在一个时间段有且仅有一门课程;
(3)一个教室在一个时间段有且仅有一门课程(可以有多个班级);
(4)教室能容纳的人员数量要大于等于开课班级学生的总数;
(5)课程要安排在具备特定条件的教室内,如多媒体教室、实验室等;
(6)上课的班级与教室尽量在同一校区;
(7)教师个人的需求,等等.
这些约束在构造C和P集合的映射时需要考虑进去,并同时根据实际情况构造权值.
3 排课系统建模
3.1 课程班级教师类

图2 二部图结点类图
由于<课程,教师,班级>记录在教学计划制定时已经确定,所以可将这3个集合的笛卡尔积中的元素简化为一个类,类名称为CLTCObj,类图如图2所示.
图2中,lId表示课程ID号,tId表示授课教师ID号,cId表示班级ID号,sCount表示上课的学生数量,cType表示课程需要的教室类型(如多媒体教室、实验室等),hope表示特殊希望,(比如,教师希望上课的时间等),zId表示学生所在校区.
get和set系列函数用于获取和设置各项属性值.
CLTCObj类用于封装二部图中<课程,班级,教师>结点集中的各个结点.由于教学计划的提前制定,所以CLTCObj类对象的个数要小于等于<课程,班级,教师>的笛卡尔积中全部元素的个数.
3.2 时间段教室类
同CLTCObj相同,将<时间段,教室>抽象为一个类,类名称为CTRObj,类图如图2所示.
图2中,timeForClass为表示时间段的枚举.高校课程一般以2个小节(45分钟或50分钟一节)为分配单位,用枚举表示十分方便.rId表示教室ID;rType表示教室类型,如多媒体教室、实验室等;rCapacity表示教室的容量;zId表示教室所在校区.
get和set系列函数用于获取和设置各项属性值.
基类抽象出结点Id和结点类型,分别表示结点序号和结点所属集合.
3.3 二部图的构造
根据教学计划数据将制定好的每一条教学记录封装成一个CLTCObj对象,组成二部图中的集合C.同理将每个时间段与教室的组合封装成一个CTRObj对象,组成二部图中的集合P.然后根据排课的约束条件对于集合C中的每一个结点,遍历集合P在其中找到所有满足约束条件的结点与C中该结点进行连接.记录二部图的边集合可采用数据结构中的邻接表,也可以采用邻接矩阵.边的权值为期望的函数.
3.4 工作蚂蚁类

图3 工作蚂蚁类图
蚂蚁个体的抽象比较繁琐,如图3所示.蚂蚁个体需要记录一次结点遍历过程中经过的结点情况,记录经过结点所依附边的权值(即通过期望表示的代价),并能通过计算路径选择概率,选择下一个结点进行遍历.一次遍历结束后需计算这次遍历所经过路径总的代价.
本文不涉及算法设计,所以工作蚂蚁选择下一结点的基本状态转移概率计算公式简单表示为:
(1)
其中,τij(t)表示t时刻路径(i,j)上的信息量.ϑij表示边(i,j)的能见度.工作蚂蚁在起始结点读取二部图邻接矩阵,根据状态转移公式计算,选择下一步应转移到的结点进行路径遍历.全部蚂蚁遍历之后,比较各蚂蚁的路径代价,选择最优的路径,并对该路径上的信息素进行更新,进行下一次迭代.
3.5 模型主要时序图
见图4.

图4 工作蚂蚁时序图
4 课表的动态调整
上述部分可完成排课问题的基本需求,即保证教学计划中应该开设的课程都参与排列,保证教室可以满足所安排课程的需求,以及各个课程时间不冲突.而考虑到实际的工作需求还应处理课程的均匀分布问题,教师授课时间的动态调整,以及各不同类型课程的优先级问题.
4.1 课程和教师授课时间的均匀分布
课程的均匀分布是指一个专业(班级)一个教学周内的课程应该尽可能地均匀分布在工作日内,不能出现某一天课程非常集中,而有些天几乎没有课程的现象.按照开课计划的安排可以得知某一专业(班级)这一学期开设的课程门数以及课程的周学时数.经过调查统计,课程一般安排到上午以及下午3点之前的效果是比较好的,即课程主要应安排在第1~6节之间.根据开设的课程门数以及每门课程的周学时数和每一天的有效课时数(一般大学课程2节为一段,共3个时间段)可以得出一个班级一天的总课时上限.系统自动计算并维护专业(班级)的每日课程学时上限,并在可行解的搜索过程中实时更新每个专业(班级)的日学时累计,若超过对应的上限则丢弃当前选择节点.此外课程的分布会受各种因素的制约,不能完全采用算法自动安排,在此部分留有人工调整的接口,以便对于有特殊需求的课程进行人工调整.
教师授课时间要求同课程的分布类似,教师授课时间不能集中到仅有的几天,应该分布均匀.所采用的处理方法同课程的均匀分布,这里不再赘述.
4.2 课程优先级
大学课程一般分为通识课程、专业课程,按照考核的方式又分为考试课、考查课等.不同课程的重要程度不同,所以在课表的安排上需要考虑课程的安排顺序与优先级.
分批排课,即按照不同类型的课程涉及到的学生构成范围情况,分批次进行课表的安排.如第一批次为通识选修课,第二批次为通识必修课程,第三批次为专业课等.在同一批次课程的排课过程中,根据课程性质的不同,对不同的课程设置不同的优先级.计算第i个课程优先级的公式为

×Weight(j),
其中,P(i)表示同一批次内第i个课程的优先级,Item(j)表示该课程的某一个性质,比如,是否为合班课程,是否为必修课程,是否为选修课程,是否为考试课程,是否为考查课程,是否为有特殊需求的课程等.每个课程设定n个性质参数,n可由管理员动态的调整.Weight(j)为赋予该课程第j个性质的权重,这个权重需要由管理员自行设定,即可动态调整.在可行解释的搜索过程中,优先级P(i)高的课程先予选择.
5 主要代码
5.1 构建二部图算法
int baseId = 0;//结点ID基值
nodes = new List
try {
//(1)读取教师课程班级数据,并构建CLTCObj结点
string sql = ”select * from [LessonPlan] where Semester = @semester”;
SqlDataReader dr = DataBaseManager.ExecuteReader(DataBaseManager.ConnectionString,CommandType.Text,sql,new SqlParameter(”@UserName”,semester));
while (dr.Read()) {
CLTCObj ltcObj = new CLTCObj();
ltcObj.NId = ++baseId;
ltcObj.NType = NodeType.课程教师班级;
ltcObj.LId = Convert.ToInt32(dr[”lessonId”]);
ltcObj.CType = TransInt2Enum(Convert.ToInt32(dr[”roomType”]));
… …
nodes.Add(ltcObj);
}
//(2)读取教室数据
sql = ”select * from [ClassRoom] ”;
dr = DataBaseManager.ExecuteReader(DataBaseManager.ConnectionString,CommandType.Text,sql,null);
List
while (dr.Read()) {
ClassRoom classObj = new ClassRoom();
classObj.RId = Convert.ToInt32(dr[”classId”]);
classObj.RType = TransInt2Enum(Convert.ToInt32(dr[”classType”]));
classObj.RCapacity = Convert.ToInt32(dr[”Capacity”]);
classList.Add(classObj);
}
//(3)做<教室>和<时间段>的笛卡儿积,并构建CTRObj结点.
List
foreach(CNodeBase node in tmpCtrObjList) {
nodes.Add(node); }
//(4)建立二部图,连接满足约束的各边
PaiKeBigp = StructBigp(nodes);
//(5)设定权值
SetWeight(PaiKeBigp);
其中,“StructBigp”为构建二部图算法.“SetWeight”算法为设定二部图各边的权值,权值主要根据期望值确定,参见前面论述.
5.2 建立二部图邻接表算法
private List
List
//找到集合中的每一个CLTCObj结点,遍历集合中的全部CTRObj结点,若CTRObj结点满足条件则建立连接
foreach (CNodeBase node in nodesInSet) {
if(node.NType == NodeType.课程教师班级) {
foreach(CNodeBase dNode in nodesInSet){
if(node.NType == NodeType.时间段教室) {
if(CheckCondition(node,dNode)){
gbTNode hNode = getHNodeInAdjacencyById(node.NId);
if(hNode == null){//邻接表内是不存在该节点
hNode = new gbTNode();
hNode.NId = node.NId;
hNode.LinkNodes = new List
bgNode bNode = new bgNode();
bNode.NId = dNode.NId;
bNode.Weight = ((CLTCObj)node).Weight;
hNode.LinkNodes.Add(bNode);} }
else {… …}
} }
else {… …}
}
return nodesList;
}
5.3 周游算法
//将蚂蚁置位到链接表内的第一个表结点
gbTNode curNodeInBgh = bigrapObj[0];
AntNode curNode = new AntNode();
curNode.NId = curNodeInBgh.NId;
this.path.Add(curNode);//记录蚂蚁周游路径的起点
bool visitedFinished = false;
int lastVisitedId = curNode.NId;
while (!visitedFinished){
//遍历该结点的所有邻接点,计算转移概率
float minTransProbability = float.MinValue;
int nextNodeId = 0;
for (int j = 0;j < curNodeInBgh.LinkNodes.Count;j++){
//计算与这个邻接结点的转移概率
float transProbability = BigraphManger.CalculateTransProbability(curNode.NId,curNodeInBgh.LinkNodes[j].NId);
//比较转移概率的大小,保留大值和结点ID
if (transProbability > minTransProbability) {
minTransProbability = transProbability;
nextNodeId = curNodeInBgh.LinkNodes[j].NId;} }
//将蚂蚁选择的结点加入路径,并记录权值
curNode = new AntNode();
curNode.NId = nextNodeId;
curNode.Weight = BigraphManger.GetWeightBetween2Nodes(lastVisitedId,curNode.NId);
this.path.Add(curNode);}
其中,gbTNode 是邻接表的表结点类,其“LinkNodes”属性为该表结点所邻接的顶点列表.AntNode是记录工作蚂蚁选择的顶点类,需要记录顶点ID和与前一个顶点之间的权值.BigraphManger类中提供静态函数“CalculateTransProbability”用于计算转移概率,公式可参考式(1).BigraphManger类中提供静态函数“GetWeightBetween2Nodes”用于获取两个顶点之间的权值.
上述算法完成当前工作蚂蚁的一次路径选择过程,此过程需要重复数次,以完成当前工作蚂蚁对二部图内所有顶点的一次遍历过程.工作蚂蚁用“AntNode”类型的列表记录在一次周游的过程中选择的各个顶点以及顶点之间的代价(权值).若某个表顶点所邻接的顶点与其余没有被访问过的表顶点之间没有路径,则从下一个没有被访问到的表顶点开始继续访问.
CAntWorker类提供“calculateWeight”和“getPath”函数,分别用于支持计算本次周游的代价(可简单理解为所经过路径的权值之和)以及提供周游的路径.当所有蚂蚁周游结束之后,比较各自的代价,选择最优代价的路径进行信息素的更新,然后进行第二次迭代.这个过程不断重复直到完成最后一次迭代,输出最优的路径组合,即得课表安排.
