网站新闻全网阅读量统计方法研究
2018-10-21陈泰伟苏国伟程策
陈泰伟 苏国伟 程策
摘 要:网站新闻是网络新闻传播的重要数据源,统计網站新闻在经过网络多次传播后的全网阅读量具有重要意义。然而,目前尚未有成熟的全网阅读量统计方法。本文对网站新闻全网阅读量统计方法展开研究,在分析统计网站新闻全网阅读量面临的各种复杂度的基础上,提出了一个统计算法模型,并分析了该模型的优缺点。
关键词:网站新闻;全网阅读量;统计算法
中图分类号:G203 文献标识码:A
文章编号:1671-0134(2018)08-117-03 DOI:10.19483/j.cnki.11-4653/n.2018.08.048
1.统计网站新闻全网阅读量的意义
在网络媒体、自媒体、移动媒体不断壮大的今天,网站已经在一定程度上成为了传统媒体平台。虽然直接从网站获取新闻的网民在不断减少,但网站新闻一直是各平台网络新闻转发分享的重要数据来源,而且网站新闻在权威性、真实性上相对其他媒体平台具有明显优势。
统计网站新闻传播获得的全网阅读量具有重要意义。从国家层面看,新闻宣传主管机构需要掌握重要政策、权威信息、宣传内容的落地情况;从传媒行业层面看,各新闻媒体单位需要了解自身媒体的影响力,整个行业也需要给出影响力排行;从新闻策划层面看,新时代的策划者已经不能再只凭自身经验和新闻敏感度做出决定,决策必须要有数据参考。以往,各媒体单位更多是依靠自身的网站访问量统计系统获取网站新闻的传播数据,该数据只能代表网站新闻在单个媒体平台的阅读情况,不能反映全网阅读情况。本文提出的全网阅读量,为单个新闻的全网传播效果给出了一个量化指标,进而更能满足各层面对传播效果的统计需求。
另一方面,随着科技的进步,文本相似度计算在信息检索的效率提高方面起到了很大的作用。[1]再加上目前大数据分析技术的日臻成熟,在对全网进行数据挖掘的基础上,能够通过文本相似度算法跟踪一篇稿件在全网的传播情况,这为统计网站新闻全网阅读量提供了技术可能。
2.统计网站新闻全网阅读量的复杂度
与统计单个网站的网站新闻阅读量不同,要统计一篇网站新闻稿的全网阅读量,会受到网站新闻稿所在的空间、时间、传播过程以及统计过程等多方面因素的影响,接下来本文从这四个维度加以分析。
2.1空间复杂度
网站新闻被不断转发后,会出现在网络空间多个位置上。首先,稿件会出现在多个网站上,不同的稿件被转发的网站数量各不相同;其次,稿件可能出现在同一网站的多个位置上,例如在网站首页、网站相关频道首页、网站专题页、网站子栏目页等;再次,稿件还可能在社交网络上有更复杂的存在形式,比如,论坛、贴吧、微博、微信等(关于稿件在社交网络上的阅读数,多可从各平台直接获取,本文统计算法中暂不考虑)。
2.2时间复杂度
不同时间点稿件的传播情况不同。随着时间变化,稿件逐渐出现在多个网络空间位置上,统计时间点不同,稿件的空间位置数量也不同,统计得到的阅读量也就不同。
不同时间点稿件的热度也不同。诸如热度衰减、再次发酵、旧闻新炒等,导致统计的阅读量也不同。如图1是一条真实新闻稿件阅读量随时间变化的曲线图,该图展示了该条稿件从变热到衰减最后到消亡的过程。该新闻稿件从4月30日凌晨发稿后,在当日15点到19点较短时间内阅读量达到最大,然后稿件热度衰减,阅读数也随之逐渐下降。在次日的3点处于衰减期的该稿件由于某种外界因素被重新激活,稿件阅读量重新上升,然后又开始衰减,最后消亡。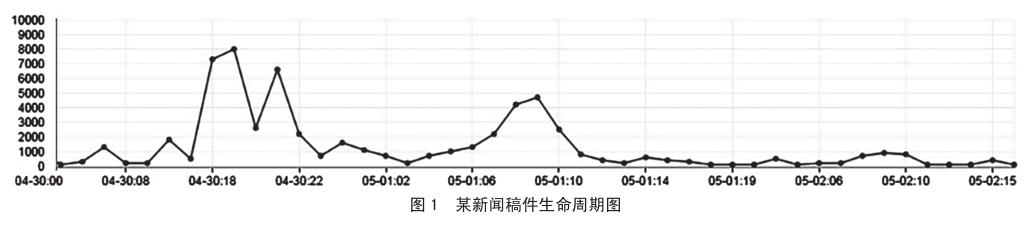
2.3传播复杂度
稿件在传播过程中会面临许多复杂的情况。第一,转载媒体可能会对被转载稿件的标题进行修改,甚至对内容进行增删处理;第二,有的转载媒体并不标注转载来源,造成在溯源统计中稿件传播链的断裂;第三,同一个转载媒体会将同一篇稿件转发到同一网站的多个位置,形成多个传播链分支;第四,稿件被转发后在各个空间位置的停留时长不同,例如稿件在一段时间内出现在某网站的首页大标题上,不久后该稿件从首页大标题上撤下,也就不再具备该网站位置的曝光率和阅读量。
2.4统计复杂度
在实际统计过程中会面临许多复杂的情况,也会增大全网阅读量统计的难度,大致包含以下一些情况:首先,不是所有网站对自己稿件的阅读量都有统计;其次,即使有的网站对阅读量有统计,各网站的统计方法和标准也不尽相同;再次,一般来讲,大部分网站不会对外公布自己的真实统计数据;还有,就算各网站都公布了自己的统计数据,对全网各统计数据进行收集整理的难度也非常大,几乎很难实现;最后,由于很可能不能及时完整地获取各网站统计数据,各网站统计数据又都在不断随时间变化,使得统计周期长,统计时间点很难把握,最后得到统计结果的时效性和真实性都不大。
3.统计网站新闻全网阅读量的算法实现
基于以上复杂度分析,要想获取精确的网站新闻全网阅读量几乎是不可能的。但是我们可以通过一定的算法模型估算稿件的阅读量,使计算出的全网阅读量能在数量级上提供参考价值,从而一定程度上解决这个难题。
3.1统计网站新闻全网阅读量的前置条件
条件一,明确对网站新闻阅读量的定义。本文所指的网站新闻阅读量,指用户通过浏览器打开稿件正文页一次,即算贡献一个阅读量,即页面浏览数(PageView,PV)。
条件二,能够获得被统计稿件在首发网站的阅读量。本算法使用者一般是某个网站媒体,依据本算法计算本网首发稿件的全网阅读量。首发网站通常能够获取自身网站的稿件阅读量,如果不能则可通过在网站后台部署一套访问量统计系统即可实现。本算法将以此作为计算基础,力争提高计算结果的可信度。
条件三,我们假设通过大数据分析,能够获取到稿件被转载的媒体以及该稿件在该转载媒体上所属的栏目。现在大数据技术和网络爬虫技术都趋于成熟,爬取新闻网站的稿件,然后通过相似性算法对比新闻稿件的内容实现对原创新闻稿件的跟踪,从而获取原创稿件被转载的媒体和所属被转载媒体的栏目。
3.2统计网站新闻全网阅读量的算法描述
为了便于说明,本文以中国军网(以下简称“军网”)的首发新闻稿件为例,对网站新闻全网阅读量统计算法展开分析。




3.4算法优缺點分析
算法优点:一是本算法充分考虑了网站新闻阅读量统计的时间复杂性、空间复杂性、传播复杂性和统计复杂性,归纳出了可操作的计算全网阅读量的方法;二是本算法以被统计稿件在某个网站的真实阅读量为基础进行估算其他网站的阅读量,使得计算结果更加真实;三是本算法除了对网站本身、网站日均访问量这些因素进行评估,还考虑了首发网站不同栏目对稿件阅读量的影响;四是使用者可以自己对首发网站不同的栏目设置相应的权值,具有一定的灵活性。
算法不足:一是本算法不能准确的算出一篇新闻稿在全网的阅读量,只是在数量级上提供参考;二是对首发网站不同栏目的权值设置没有一个统一的标准,而是由使用者自己设置,既是优点也是缺点。
结语
一篇网站新闻稿的全网阅读量比在单一网站的阅读量能更好地反映其宣传效果,同时也更适合作为影响力评估、新闻策划的参考依据。本文通过仔细考虑影响全网阅读量的各种因素,归纳出了可操作的全网阅读量算法公式,初步实现了在全网范围内跟踪统计一篇稿件的阅读量,为进一步展开网站新闻传播大数据分析打下了基础。
参考文献
[1]王格,吴钊,李向.基于全文检索的文本相似度算法应用研究[J].计算机与数字工程,2016,44(4):567-571.
[2]焦金涛.基于PageRank的Web挖掘改进算法[J].计算机工程,2009,35(15):284-285.
[3]李秦,郑宏.从Alexa排名的相关参数比较国内3种电子期刊网站[J].情报探索,2009(2):67-70.
