基于CURE聚类算法的科技情报异常数据检测
2018-10-18柳兆峰霍永华谢志敏
柳兆峰,杨 奇,霍永华,谢志敏
(1.中国人民解放军31001部队,北京 100094; 2.中国电子科技集团公司第五十四研究所,河北 石家庄050081; 3.中国人民解放军海洋环境专项办公室,北京 100181)
0 引言
情报是指按照用户需求,针对特定情景实现特殊作用和价值的信息数据和知识。情报分析亦称信息分析或情报研究,是根据社会用户的特定需求,将分布分散、杂乱的海量信息采用科学的研究方法和技术手段进行收集、整理,生成有价值的情报数据,为不同层次的用户提供科学决策服务。我国提供了良好的情报分析研究工作环境,形成了以高校和图书馆为主导,以科技情报为核心的应用领域和以政府与企业为主导,以路线规划、前景预测、综合决策为目标的应用领域[1-3]。
情报数据质量是进行情报分析并以此做出有效决策的重要基础。互联网和大数据背景下,科技情报研究的数据来源被大大拓宽,因此不可避免地出现数据分类错误、重复、缺失、格式不一致等现象,这些异常数据对于情报分析是无用的,甚至会对分析结果和效率产生很大的负面影响,所以需要对其进行检测和处理,以提高数据的质量[4]。本文重点解决科技情报中数据分类错误问题。
异常检测作为数据挖掘领域的一个重要研究方向,主要用来检测数据集中偏离正常分布模式的异常数据。异常检测技术能够从大量、模糊的复杂数据中检测出异常信息,在大数据处理中得到广泛应用。现有的异常检测技术主要包含基于监督的和基于无监督的2种方法。基于监督的异常检测方法主要包括概率统计、模式预测、神经网络、增量式SVM异常检测等方法;基于无监督的异常检测方法主要包括K-means聚类、基于核自适应的AP聚类异常检测、引入约束条件的密度聚类异常检测等方法[5-8]。
但是这些检测方法仅针对数值型的数据,并不完全适用于情报分析领域。与数值型数据为主要研究对象的大数据分析不同,科技情报分析大多以文本文献作为数据的对象和基础,包括论文、专利、科技报告及网页文本等。目前情报领域的异常检测方法研究成果较少,鉴于此,本文基于无监督CURE聚类算法,提出了一种针对科技情报数据的异常检测方法。
1 科技情报异常数据检测模型
科技情报异常监测过程模型如图1所示,主要分为3个阶段:信息采集与预处理阶段、文本处理阶段以及聚类分析阶段。
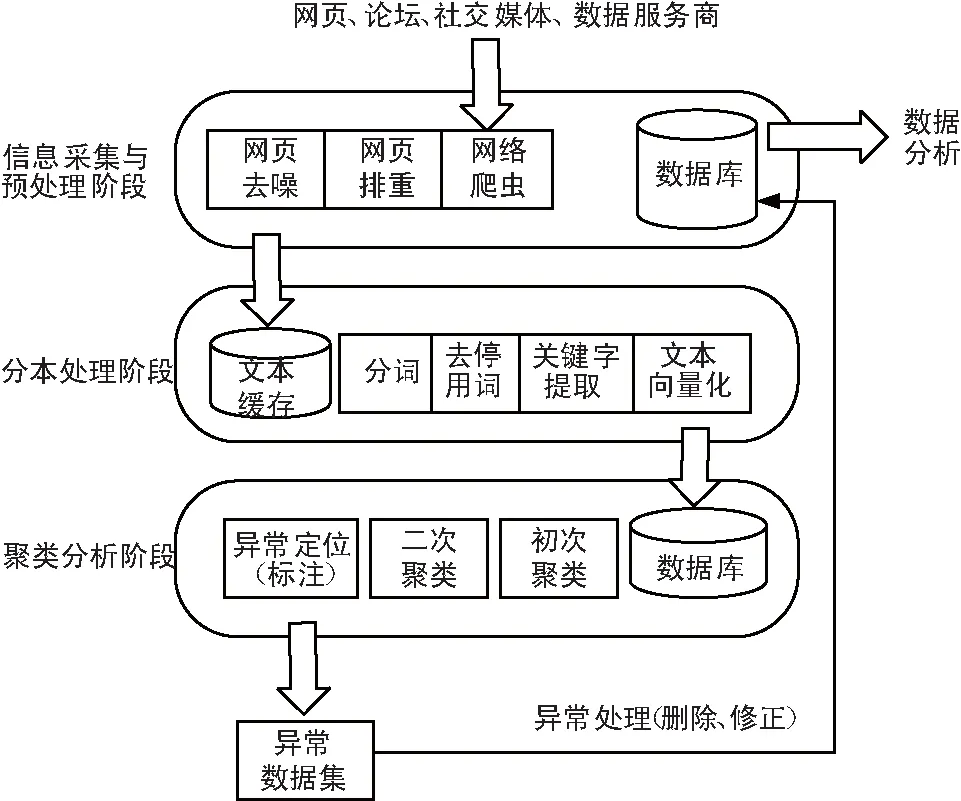
图1 科技情报异常数据检测模型
1.1 数据采集与存储阶段
与传统情报存储和传输方式不同,互联网背景下,各类结构不一的情报流转在网页、博客、论坛以及社交媒体等网络媒介中,依靠人工很难高效地获取这些情报数据,必须依靠技术手段批量获取。
本阶段主要根据情报分析需求,利用主题网络爬虫技术有选择地自动访问互联网上的网页与相关的链接,获取所需要的科技情报。为了极大地减少冗余信息,可以通过网页排重技术去除冗余网页,同时利用网络去噪技术剔除Web页面中如导航条、广告信息、版权信息以及调查问卷等与主题不相关的内容,最后将爬取到的原始情报信息以统一的格式存储在文本缓存区中,实现从非结构化至结构化数据的转换存储。
1.2 文本处理阶段
从互联网或者数据库获得情报信息大多是以文本形式存储,为了实现基于CURE的异常检测和为后续的情报分析提供方便,需要对文本数据进行一系列文本处理,最终以多个特征值表示的形式存储在数据库中。这一过程一般包括以下4个步骤:
① 中文分词
中文分词(Chinese Word Segmentation)技术是将连续的字序列按一定的规范重新组合成词序列的过程。目前流行的中文分词算法主要是基于字符串匹配、统计方法和理解分析3种方式,依靠这几类算法,国内外出现了许多成熟的开源分词软件。如中国科学院计算技术研究所开发了NLPIR软件,清华大学自然语言处理与社会人文计算实验室开发了THU-LAC软件,还有python中常用的结巴(jieba)分词。本文选择THU-LAC软件作为原始情报文本的分词工具。
② 去停用词
情报文本中含有大量的例如“了、呢、的”一类的对情报分析工作没有实际意义的词语,这些词称为停用词,为了降低词典和文本特征向量空间,减少计算量,提升异常检测效率,要在原始的情报文本中剔除掉停用词。
③ 关键词提取
关键词是指反映一段情报文本核心内容的词语。关键词提取是利用降维的方法对情报文本进行特征选择和提取,并对特征项的重要程度用权重加以区分,从而提高后续对信息进行分类、聚类、主题分析等操作的结果精度。因此关键词提取是异常检测的重要前提和基础。
通过爬虫等技术手段采集的情报数据并不会像专业期刊论文一样列出关键词,在海量数据的背景下依靠人工进行关键词提取显然是不可取的。因此,通过技术手段自动提取关键词就成为情报分析研究的重点。目前文本提取关键词算法主要有基于统计、基于词语网络、基于词语共现图3种。常见的有基于布尔权重、词频[8]、TFIDF值[9]等方法。本文采用TFIDF值对特征值进行选取和加权。计算方法如下:

(1)
式中,xi为关键词,N为文档总数,n为该关键词出现的文档数。TFik(xi)表示关键词出现在文档集的频数,分母为归一化因子。
通过预先设定一个阈值,当wik(xi) 低于这一阈值时,可认为该关键词几乎没有处理价值,可以直接将其忽略。剩余关键词保留,权重为wik(xi)。
④ 文本特征表示
特征表示是指用一组特征项来表示文本信息。特征表示模型有布尔模型、向量空间模型及概率模型等。本文利用向量空间模型(Vector Space Model,VSM)对文本进行向量化。VSM的思想是用一组特征项及其特征项对应的权重来表示一个文本信息,将文本简化为特征空间中的一个点。即对于一个含有n个特征值的文本D,可以表示为:
D={(t1,w2),(t2,w2),...,(tn,wn)},
(2)
式中,ti表示第i个特征词,wi为第i个特征词的权重。将分词、提取关键词和特征向量之后的文本信息标记,存入数据库中。
1.3 聚类分析阶段
聚类分析阶段是本文异常数据检测的关键步骤,通过聚类分析的方法对离群数据(即不良数据)进行识别和定位。下一节给出了基于CURE聚类算法的异常数据检测方法的具体步骤。
2 基于CURE聚类算法的异常数据检测
CURE聚类算法是一种自底向上的层次聚类算法,利用该算法对向量化后的情报文本集(即具有n维特征属性的点集)进行聚类,可以对异常数据进行识别和定位。检测出来的异常数据主要来自两方面:一个是在首次聚类时增长较为缓慢的簇;另一类是聚类后期包含对象明显偏少的簇。涉及到的定义如下。
定义 1:初始聚类划分的数据分区可以用若干个分散的代表点来表示。即数据簇s表示为s.mPi(s.mean,s.n),其中Pi为该簇的代表点,m为代表点的个数,s.mean为该簇的中心点,s.n代表簇的容量即数据对象的个数。
代表点的选择方法如下:
① 首先确定代表点的数目m和收缩因子α;
② 选取初始m个代表点。第一个代表点是距离该簇中心点最远的点,其后的代表点是选取距离前一个选出的代表点最远的数据点;
③ 用收缩因子α收缩代表点,调节类的形状,排除孤立点的影响。收缩公式为:
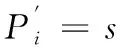
(3)
定义 2:离散度。用欧氏距离表示样本中一个对象点距离代表点的离散程度,离散度越大说明距离该代表点越远。设代表点的集合为P,任一样本数据点xi对于集合P中代表点Pi的离散度如下:
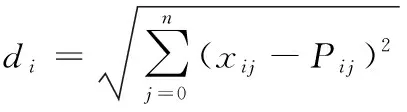
(4)
式中,xij为样本点xi的第j特征值,Pij为代表点Pi的第j特征值,n为VSM模型的维度,该式代表了2个文档之间的距离。
定义 3:设每一个样本点的离散度集为D,取离散度的平均值为该样本数据的离散判定值AD:
(5)
定义 4:设异常判定界限参数为δ:
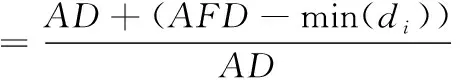
(6)
式中,min(di)为离散度最小值。
定义 5:对于离散度集D中任意di∈D,若di>δ×AD,则di对应的代表点Pi为离散点,其所在的簇中的样本点即为孤立异常数据。
基于CURE聚类算法的异常数据检测方法的基本思想是:首先确定情报分析的主题类别,通过信息采集和预处理阶段得到原始的样本集,然后经过文本处理阶段获得文本向量化后的样本集。之后,对样本集进行聚类。首次聚类先将样本划分为n个规模相同的数据分区(或簇),每个簇的数据容量为m/n。然后计算簇中每个点的离散判定值(AD)及离群参数(δ);对满足di>δ×AD的异常点进行标注,并从样本中删除;之后对距离最近的簇进行合并,然后对「n/q⎤个簇进行二次聚类,同时对包含对象数目明显偏少的簇进行标注和删除,剩余的数据点就是正常数据。最后将标注的异常数据作为异常检测的结果输出。
3 实验结果分析
专利情报分析是科技情报研究的热点课题,本文以专利情报为实例说明情报异常数据检测过程。以国家专利网站专利信息作为研究对象,利用网络爬虫技术爬取了国家专利网站计算机类专利和医疗类专利各200条,原始文档包括专利类别(计算机类/医疗类)、专利名称、专利号及摘要等基本信息,部分原始数据如图2所示。

图2 原始专利数据
受爬虫程序和网页解析等方面的影响,爬取到的专利信息可能存在数据格式混乱、专利内容与主题类别不符和数据重复等问题,这类数据称为异常数这据。图2中编号为5的样本是在医学类主题下爬取的,但是由其专利名称和文摘内容可以推断出,它应属于计算机类,所以该样本属于异常点,其中“类别”一项的描述错误。同理编号205的样本也属于异常点。对上述样本的专利名称和摘要进行分词、去停用词、关键词提取和特征向量化,得到数据向量表示的样本集。然后使用第2节中的基于CURE聚类算法的异常检测方法对样本集进行聚类,最终得到2个点簇(标号为1和2)和1个异常点集合(标号为3),如表1所示。
表1 异常检测结果
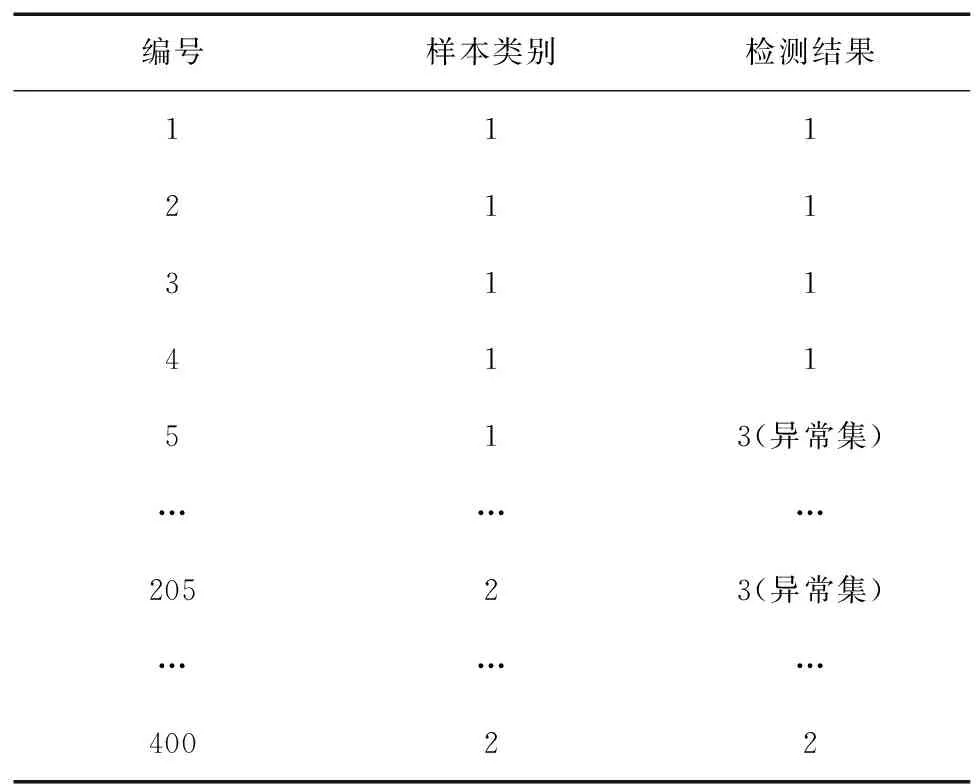
编号样本类别检测结果111211311411513(异常集)………20523(异常集)………40022
其中一个簇代表医学类专利,另一个代表计算机类专利。结果显示,异常点集合包括编号5和编号205,这说明本文算法能够准确识别异常点。
为了进一步说明本文异常检测方法的有效性,避免上述实验结果的偶然性,在原始各200条样本的基础上,继续爬取国家专利网站上计算机类专利和医疗类专利,将每类专利测试样本集的容量扩大至500条、1 000条、1 500条和2 000条。分别进行异常检测实验,测试结果见表2和表3。下面以每类专利样本容量2 000条(即总样本容量为4 000条)为例,给出具体实验步骤:
① 确定专利分析的主题类别为“计算机”和“医疗”,通过信息采集和预处理阶段得到原始的样本集各2 000条。
② 首先用人工标记方法找出其中的实际异常数据,作为测试结果的评判标准。其中计算机类实际异常数据共117条,医疗类实际异常数据共121条。
③ 对原始样本进行文本处理,经过中文分词、去停用词、关键词提取和文本特征表示4个步骤获得文本向量化后的样本集。经反复测试,关键词数目为1 600时就能达到较好的测试精度和效率,部分关键词及其权重如图3所示。所以文本向量空间为1 600维,每条情报样本由1 600个特征词权重表示。
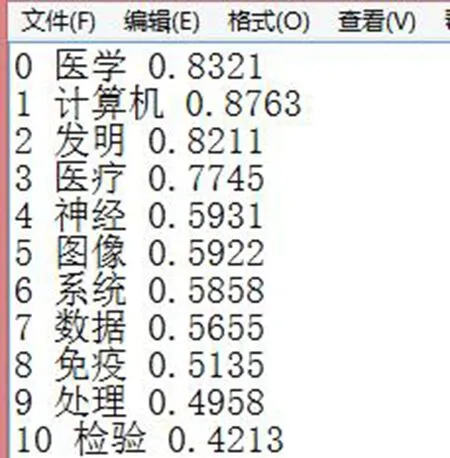
图3 部分关键词及其权重
④ 对向量化后的样本集进行CURE聚类,过程如图4所示。首次聚类先将样本划分为10个规模相同的数据分区(或簇),每个簇的包含400条文本向量化后的测试样本,每条样本记为簇中的一个点。设本次实验的收缩因子α=0.5,代表点个数m=4,按照第2节中介绍的方法,得到最能代表以上10个簇形状的代表点集合。然后计算簇中每个点的离散判定值AD值及离群参数δ;对满足di>δ×AD的异常点进行标注,并从样本中删除。
⑤ 之后对距离最近的簇进行合并,并对包含样本数目明显偏少的簇进行标注并删除,然后对合并后的簇进行再次聚类,即重新选取代表点和识别异常点,重复上述过程直到簇的数目减少至预先设定的目标类个数2。最终经过4次合并得到2个正常簇和1个标注的异常点集合(下面简称为异常簇),合并过程如图4所示。2个正常簇分别代表计算机类和医疗类,异常簇里的数据作为异常检测的结果输出(其中包含表1所述样本5和样本205)。
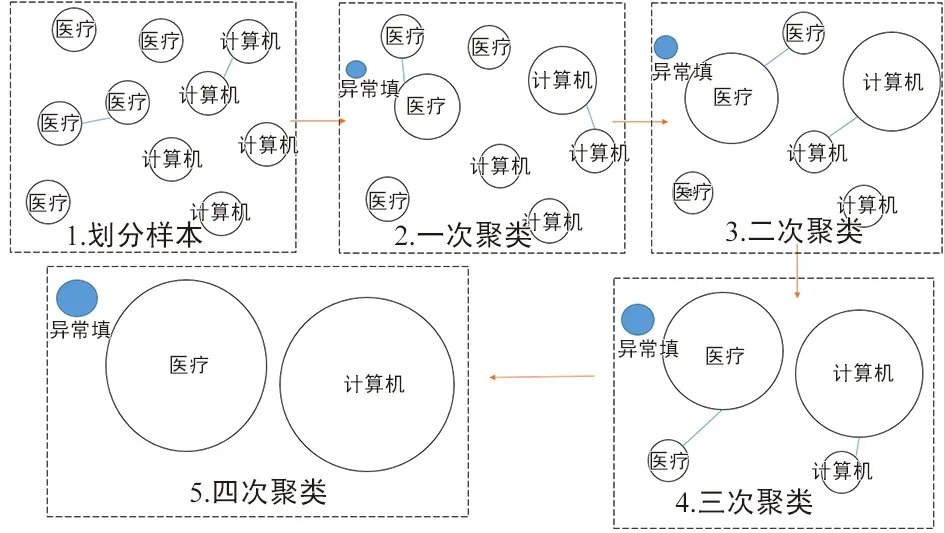
图4 聚类过程
本文定义了2个指标—准确率α和误检率β来衡量异常检测结果的有效性,如式(7)和式(8)所示:

(7)
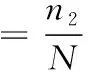
(8)
式中,N为实际异常数据的个数,n1为检测异常数据中正确识别的异常个数,n2为检测异常数据中错误识别的异常个数与未检测出的实际异常个数之和。测试结果如表2和表3所示 。
表2 计算机类专利信息异常识别率

样本数目实际异常数据数目检测异常数据数目正确检测数目错误识别数目未检测的异常数目准确率/%误检率/%5001918180194.745.261 0005856560296.553.451 5008485832198.813.572 0001171181135496.587.69
表3 医疗类专利信息异常识别率

样本数目实际异常数据数目检测异常数据数目正确检测数目错误识别数目未检测出异常数目准确率/%误检率/%5001515141193.3313.331 0004947470295.924.081 5009087870396.673.332 0001211231185397.526.61
实验结果表明,针对不同容量的样本,本文提出的异常检测方法均保持较高的检测准确率和较低的误检率,为后续的异常数据处理打下了基础,同时对于情报数据分析提供了重要的参考价值。
4 结束语
将机器学习应用到情报领域,有助于解决多源异构的海量情报数据所导致的分析时效性低和准确性差等问题。情报数据集的质量是进行情报分析和知识发现的基础。本文提出了一种针对情报分析的异常检测方法,分为信息采集与预处理阶段、文本处理阶段、CURE聚类分析阶段3个部分。通过专利情报实例验证了所提异常检测方法的有效性和可行性,对于企业竞争、图书馆情报学等众多互联网情报研究领域有着一定的借鉴意义。
