基于对象数量的宽度加权聚类kNN算法
2018-10-16关凯胜李嘉兴
陈 辉,关凯胜,李嘉兴 ,2
1.广东工业大学 计算机学院,广州 510006
2.广东省大数据分析与处理重点实验室,广州 510006
1.School of Computer Science and Technology,Guangdong University of Technology,Guangzhou 510006,China
2.Guangdong Key Laboratory of Big Data Analysis and Processing,Guangzhou 510006,China
1 引言
k最近邻算法广泛用于数据挖掘和数据分析中,这种算法以一个样本集和一个查询对象作为输入,能够找出距离查询对象最近(或相似度较高)的k个对象。kNN算法是一种经典的方法,在不同领域有着广泛的应用[1],例如数据分类[2-4]、空间数据库查询、入侵检测[5-6]、模式识别[7]、异常值检测[8-10]、道路网络查询[11]、文本分类[12]等。目前很多与kNN算法相关的研究已经提出了许多改进方法用于计算得到精确结果或者近似结果。在损失精度的前提下取得近似结果,这种方式效率较高。与此相反,虽然得到精确结果的算法更为复杂,但是能得到精确的结果。传统计算精确结果的方法需要遍历整个数据集,为了解决这个问题,目前很多研究工作都集中在数据的预处理上,其目的是通过计算数据集的一部分来找到查询对象的k个精确最近邻(k-NNs)。
一些研究提出基于树[13-16]的索引结构对数据进行预处理,其索引结构采用二进制分区技术对数据进行预处理,每个树的叶节点中包含距离相近的对象。kNN算法利用树的索引结构对数据进行预处理并使用三角不等式修剪不包含结果的节点。高维数据往往具有稀疏而且不相似的特点,使用基于树的索引结构其内部节点之间将会有较高的重叠度。因此三角不等式将无法修剪大多数的节点。为了解决上述问题,现有工作使用聚类技术将数据集划分为一些数据集群以得到更好的聚类结果。固定宽度聚类(FWC)[17-18]、k-Means[19]和kNNVWC[20]这三种算法是根据特征空间直接将数据集划分为若干个子集群,并使用产生的子集群有效地计算k-NNs。FWC算法生成的每个集群都有相同的半径,这将导致部分集群拥有大量的对象,而部分集群对象数量则很少,这将不利于修剪数据。kNNVWC算法是对FWC算法的一个改进,但是这种方法需要进行复杂的宽度学习,增加聚类的迭代次数,相应的会导致预处理时间的增加。k-Means算法将稀疏分布的对象分给最接近的集群,因此生成的集群可能会有一个很大的半径。
针对上述方法的局限性,本文提出一种新的基于对象数量的宽度加权聚类算法用于kNN查询(NOWCkNN)。该算法能产生分布较好的集群,同时建模时间会明显的减少。本文的贡献如下:
(1)提出一种新的数据聚类算法,在不同分布的高维数据中生成较好的集群。该算法既有基于tree index聚类算法的优点,也继承了基于flat index聚类算法的特点。这样该算法不需要经过大量计算便可得到聚类宽度值,更加有利于划分数据集,能够有效地减少迭代次数,降低聚类时间。
(2)基于对象数量的宽度加权聚类算法,提出NOWCkNN算法用于kNN查询。不同于FWC算法,该算法的宽度值是可调节的,根据其对象数量和调和系数能有效的调节宽度权值,从而减少迭代计算。
2 相关工作
在没有数据预处理的情况下计算一个给定查询对象的k个最近邻需要计算整个数据集,现有的研究工作是为数据建立一个索引结构以避免计算整个数据集。现有的方法大致分为两类:近似搜索算法和精确搜索算法。
2.1 近似搜索算法
kNN近似搜索算法在处理高维数据时具有很好的性能,但是它的结果精确度较差,得到的k个邻居中并不都是最近的。局部敏感哈希算法(LSH)[21]包含几个哈希函数,该方法基于越紧密联系的对象就越有可能拥有较相近的哈希值这样一个假设。基于LSH也提出了很多方法,如多探针LSH[22]和LSH森林[23],前者减少了哈希表的数量但是增加了存储空间,而后者移除了手动调整参数的必要性。最近以空间分区结构为基础的算法被用于kNN的近似搜索,例如随机kd树[24]和k-Means优先搜索树[25],这些算法比LSH算法在近似查询方面有更好的表现。
2.2 精确搜索算法
2.2.1 Tree-Based Index
目前有很多研究使用二叉树[14,26-27](例如KDTree[26])来构建数据集的索引结构,每个树的叶节点都包含彼此相近的对象。这些叶节点的集合组成父节点,其父节点都包含彼此相近的子节点,这个过程被递归的调用,直到根节点包含所有节点。kNN算法利用基于树的索引方法,使用三角不等式来修剪不包含结果的节点。每个基于树的索引以不同的递归调用方式构建索引结构,树型索引的主要不足在于采用二进制分割技术构建索引结构。该方式对于对象分布未知且维度较高的数据集并不是一个很好的解决方法。高维数据往往是比较少而且也不相似的,基于树的索引结构其内部节点之间将会有很高的重叠度,因此使用三角不等式将无法修剪掉大多数的节点,kNN算法通常还是需要遍历整个数据集(或数据集的大部分)。
2.2.2 Flat-Based Index
当树节点之间的重叠度较高时,树结构就失去了作用。受此启发,一些研究提出Flat-Based Index,例如FWC[17-18]、k-Means[19]和 kNNVWC[20]算法,这些方法使用聚类算法直接将数据集分成集群来获取更好的分区效果,并使用这些集群来有效地计算k-NNs。
现有的Flat Index聚类方法可能会产生分布不均的集群,其生成的集群大小差别很大,这会降低三角不等式的修剪效率。例如,k-Means将稀疏的对象分配给其最近的集群,因此这些集群的半径会很大,与其他集群重叠度就会很高,这也就增加了kNN算法的查询时间。同样地,FWC算法生成集群中的对象数量并不均匀,该算法的时间复杂度为O(cs),其中s为对象的数量,c为产生集群的数量。设置一个较小的固定宽度值可以防止较大集群的产生,但是这将会导致产生大量的集群,无疑会增加预处理时间。针对FWC算法的不足,Almalawi等人[20]提出一种宽度自学习聚类算法,该算法把数据集分割成多个不同宽度大小的集群。但是这种方法在集群再次划分时需要进行集群宽度计算,对于生成有较多对象的集群,需要经过多次迭代才能很好的分割数据,这会导致聚类过程需要不断的迭代进行。基于此种情况,本文提出一种基于对象数量的宽度加权聚类算法用于kNN查询,每个集群的宽度在聚类时根据对象数量进行宽度自学习。
3 提出的宽度加权聚类算法
针对上述方法的不足,本文提出一种基于对象数量的宽度加权聚类算法,该算法是在FWC算法的基础上进一步聚类划分。本章首先介绍FWC的聚类步骤,然后介绍NOWCkNN算法的两部分:聚类和查询。
3.1 FWC算法
定义1待聚类数据集DS:DS={O1,O2,…,On},其中Oi为数据集DS的第i个对象,n为对象的个数。
定义2对象O={a1,a2,…,aj,…,am},其中aj为对象Oi的第 j个属性,m为每个对象属性的个数。
定义3聚类输出集群集合C={C1,C2,…,Ct,…,Cn},其中n为聚类生成的集群数,Ct表示第t个集群。
定义4集群C={Cd,Cc,Cw},其中Cd用来存储生成集群的数据,Cc存储集群的中心,Cw存储集群的半径宽度。
固定宽度聚类(FWC)算法[17-18]是将数据集分成多个具有相同半径的集群。算法1描述了FWC的算法步骤,表1是对算法1中一些符号和函数的定义。FWC算法每次分割一个数据集。首先把数据集中第一个对象设为第一个集群的中心(5~8行),对于下一个对象需要先计算距离其最近的一个集群did,并与固定宽度值W比较(第6行)。如果计算距离值did大于W,则需要重新创建一个集群并把此对象插入该集群(第8行);若距离did不大于W ,则把此对象插入到该集群中(9~10行)。比较距离did与该集群的半径wid,若小于半径wid,则需要重新更新其半径值(11~12行)。算法依次循环执行,直到数据集中的对象都被分到不同的集群中。

表1 算法1的符号和函数定义
算法1 FWC算法
1.InputDS
2.OutputC
4.n=0
5.forOiinDS.objects
7.n=n+1
8.addOitoCnew
9.else ifdid≤W
10.addOitoCid
11.ifdid<wid
12.setwid=did
13.returnC
FWC算法的性质限制了它在异常检测中的应用,创建具有固定宽度的集群集合可能无法修剪大多数的数据对象。Eskin等人[17]提出的FWC算法虽然可以将数据集分解成较小的集群,并用这种方法找到查询对象的k-NNs。然而当数据分布不均时,这种分解效果并不是很好,虽然kNNVWC算法[20]对此进行了改进,但是其宽度计算量偏大,算法迭代次数较多,不能很好地控制生成集群的大小,同时该算法宽度的计算会随着维度的升高而增加。
聚类产生较好的集群能够有效的提高kNN算法的修剪率。基于此理论,需要尽可能的生成效果较好的集群。数据的聚类需要经过大量的计算,要产生效果较好的集群还需要避免计算量过大。集群的大小或者集群数量都能影响聚类的效果,集群的宽度决定集群的大小和产生集群的数量。因此需要调整集群宽度的大小,使其能够产生质量较好的集群。每个集群的宽度与集群中的对象数量正相关,根据对象数量调整宽度再设置一个系数调节大小,可以有效地控制不同集群宽度的产生。例如,超过阈值具有相同对象数量的集群,其集群宽度可能会不相同。对于宽度较大的集群,其数据相对稀疏,设置较小的系数,使宽度权值相对较大,这样可以减少集群的数量,避免产生具有极少对象的集群;对于宽度较小的集群,其数据相对稠密,设置较大的系数,使宽度值相对较小,这样可以减少迭代。
3.2 基于对象数量的宽度加权聚类算法
3.2.1 集群宽度加权计算
令D为要进行聚类的数据集,s为数据集中的对象数量,函数Quotien(a,b)返回a/b的整数部分,用ωCn表示第n个集群的半径宽度,p为调和系数。此过程中有一个变量:阈值β,这是用来限定集群大小的阈值,集群中的对象数量不能超过阈值β,其宽度表达式如下:

这里调和系数 p的大小和函数Quotien的范围将会影响到聚类的效果,在4.2节中会分析 p的大小和函数Quotien的范围。
3.2.2 聚类过程
该过程将数据集划分成多个集群,以解决在高维空间中数据对象的聚类问题。但是,数据集中在数据比较集中的区域可能会有大的集群产生,因此需要将产生具有较多对象的集群再次进行划分,直到每个集群的大小都不超过所规定的阈值(最大值)。本文在算法2中总结了聚类过程,表2是算法2的一些符号和函数定义。
算法首先把数据集划分为具有固定宽度的集群(第3行),初始化迭代次数为1。然后循环找出对象数量大于β的集群,把这些对象数量大于β的集群添加到MultiClusters中(5~7行),把对象数量小于 β的集群添加到LessClusters(第9行),同时标记对象数量小于β的集群为不可再分(第10行)。对于对象数量大于β的集群需要重新计算其宽度值,用公式(1)的方法计算集群下一次聚类时的宽度值(第13行),然后继续对该集群进行划分,迭代的划分集群直到所有集群中的对象数量都不大于β(第16~17行)。每次迭代后,迭代次数都要加1(第18行)。

表2 算法2的符号和函数定义
算法2 NOWC算法
1.Input:data
2.Input:β
3.Clusters=Algorithm1(data,W)
4.t=1
5.foreach cluster in Clusters
6.ifcluster.objects>β
7.put cluster in Multi Cluster
8.else
9.put cluster in Less Clusters
10.LessClusters←NonCluster
11.for each cluster in Multib Clusters
12.D←cluster.data
13.w ← equation(1)
14.tmp Clusters← Algorithm1(D,w)
15.put tmp Clusters into new CLusters
16.for new Clusters
17.go to line 4
18.t+=1
19.return
同时设定其迭代上限为t(t通常小于等于3),由于迭代次数越多生成集群的数量就会相应的增加,集群中对象的数量就会越来越少。此时进行kNN查询时,这会增加计算消耗。在每次迭代时,设定迭代聚类产生的集群数量都不大于前一个迭代聚类产生的集群数量,这样可以防止较小集群的产生,提高聚类质量,提升kNN查询时的修剪率。
3.3 kNN查询过程
定义5(k-最近邻(kNN))一个查询对象q的k个最近邻居到q的距离小于数据集中剩余对象到q的距离。设Uqk={X1,X2,…,Xk}是查询对象q的k个最近邻对象,MAXk表示查询对象q与数据中所有对象的距离按从小到大排序的第k个距离值,则其k个最近邻表示为:
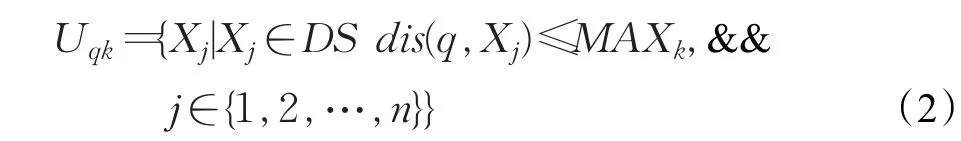
定义6(候选集群)对于给定的查询对象q,其中Li={O1,O2,…,Ok}是q在集群Ci的最近邻对象,wk表示q到其k个最近邻中最远对象的距离,wi是集群Ci的半径宽度,C={C1,C2,…,Cn}是集群的集合,其中,如果,则集群Cm是 q的一个候选集群。

表3 算法3的符号和函数定义
算法3 NOWCkNN算法
1.Input:Clusters
2.Input:k
3.Input:q
4.Output:kNNObjects
6.CluDisID ← SortClustersByq(Clusters,q)
7.foreach{ID,Distance}in CluDisID
8.tmpCluster=getCluster(ID)
9.kNNObjects=kNNObjects∪tmpCluster.Objects
10.If|kNNObjects|>k
11.break
12.{wk,kNNObjects}=kNNDistance(kNNObjects,q,k)
13.foreach CluDisID
14.tmpCluster← getCluster(ID)
15.if(tmpCluster.radius+wk)>CluDisID.Distance
16.put tmpCluster.Objects in kNNObjects
17.go to line 12
18.else(tmpCluster.radius+wk)<=CluDisID.Distance
19.continue
20.return kNNObjects
如图1的B所示,Ci是要进行计算的下一个集群,{O1,O2,O3,O4,O5}是集群Ci的对象,其中O1是集群Ci的中心,集群半径radius为23.5。查询对象q到集群中心的距离为w=32.4,以q为圆心,wk为半径画圆,该圆到集群中心O1的距离小于两个圆半径的距离之和(第15~16行),即32.4<23.5+14.7,则此聚类中可能存在比wk更近的对象,然后把此集群添加到候选集群表中,并把候选集群中的对象添加到候选对象表中,重新计算其k个最近邻和到第k个邻居的距离wk(第17行)。如图1的A所示若两个圆没有相交,则说明此集群中不存在比wk更近的对象了,此集群被修剪。算法循环遍历每个集群,直到所有集群到查询对象q的距离都大于其集群半径和wk之和(如图1的A所示),则算法停止,返回这k个最近邻对象(第20行)。
时间复杂度分析:

4 实验结果与分析
本章中,在各种数据集中验证NOWCkNN算法的性能,实验从三方面分析算法的性能:(1)建模过程消耗的时间;(2)进行距离计算的对象数量;(3)kNN查询所用时间。将四个算法KDTree、kNNVWC、FWC、k-Means与NOWCkNN算法进行比较,每次实验时将整个数据集作为训练集,随机从训练集中选取一些对象作为测试集,所有测试对象的平均值作为总体结果。所有算法都是用Java实现,实验操作系统为macOS,CPU频率为2.9 GHz,内存为8 GB。
4.1 数据集
选用不同维度特征空间的数据集用于测试所提出算法的性能,这些被选择的UCI公开数据集来自各个领域,被广泛地应用于数据挖掘,只是使用它们来验证NOWCkNN算法在k最近邻搜索中的性能。这些数据集的简要描述如下:
shuttle数据集有43 500个对象组成,每个对象有9个数字特征表示,它用于欧洲StatLog项目测试机器学习的性能;
arcene数据集通过SELDI获得的观测数据,用于从正常模式中辨别出癌症,该数据集有900个对象,每个对象有1 000个特征属性;
waveform数据集由5 000个对象组成,每个对象有40个特征,其中有一些噪音数据;
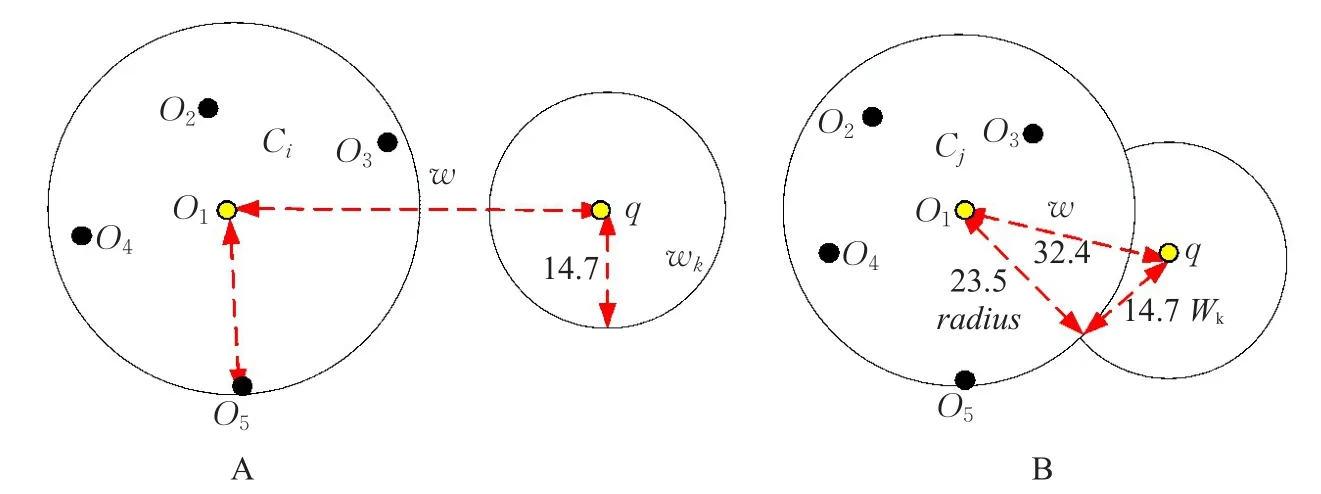
图1 基于三角不等式的NOWCkNN查询实例
spambase数据集有4 601个(电子邮件)对象,其中包含1 443条垃圾邮件,每个对象有57个属性;
optdigits数据集是识别0~9的数字,optdigits数据集训练集有3 823个对象,测试集有1 797个对象,每个对象有65个属性;
madelon是NIPS 2003比赛中5组数据集中的其中一组,共有数据对象4 400个,每个数据有500个属性;
gasSensors是来自16个传感器的13 910个对象,每个传感器提取8个特征,这使每个对象有128个特征属性;
DUWWTP数据集来自城市废水处理厂的传感器的日常测量值,由527个对象组成,每个对象有38个特征。
4.2 参数的设置
不同的算法需要不同的参数设置,对于FWC算法最重要参数的就是集群宽度,而k-Means方法最重要的参数就是k值的选择。文献[19]提出的k-Means方法证明了k值为2时效果最佳,其中s为数据集的大小。对于FWC算法,找到合适的宽度值是非常困难的,因此本文选择产生集群数量尽可能接近2。本次实验中KDTree方法的叶子大小设置为40,该数值对于大多数的数据集能取得最佳效果。由于本文所提方法不确定所产生的集群数,因此测试了β的各种取值,选择在不同维度、不同大小以及不同领域的数据集进行测试。如图2所示,横坐标表示生成的集群数量,调整β值改变生成的集群数量。如图2所示,各个数据集聚类产生集群数大约在到3之间时算法的性能较好,因此把生成此范围集群数量的β值作为最优β值。
式(1)中调和系数 p的大小将会直接影响到生成集群的数量,而函数Quotient的取值范围也会影响到算法的性能。一个较大的 p值会使每次迭代计算得到的宽度值都接近于最小宽度值,这会导致有大量的集群产生。函数Quotient的取值范围越大则迭代的宽度值越小,其取值越小的情况下其迭代得到的宽度值越大,宽度值较小则会产生大量的聚类,较大则会增加迭代次数,影响算法性能,因此产生较好的聚类效果依赖于调和系数p的大小和函数Quotient取值范围。在这次测试中选择的数据集在维度、数据集大小和疏密度方面都有差异。用对象距离修剪率ord表示数据集的修剪效率,其计算表达式为:

其中,s为数据集的大小,Cm为在数据集中找到k个最近邻参与计算的集群数量。
如图3所示,较高维度的数据集arcene中宽度值较大,数据较为分散,p值越大其聚类宽度值在迭代时减小的越快,而产生聚类的对象数量很难影响函数Quotient的取值。从图3(a)中可以看出,提出算法在p=2时各个数据集都具有较高的数据修剪率,而函数Quotient范围在QMAX=6时(即取值范围2至6之间)效果较好。而在数据集shuttle、pendigits和spambase中,p的值为2或3时较好,函数Quotient范围在2与6之间时其数据修剪率较高,效果最优。因此,在聚类时参数 p的值一般设为2或3,其函数Quotient范围为2至6。对于 p值较大时,可能也会取得较好的结果,但是这样会导致一些数据集有大量的集群产生,这样不利于基于三角不等式的kNN查询。同时Quotient函数范围小于2或者大于7时,如图3所示算法的性能明显下降,根据算法的时间复杂度降低迭代次数能够有效地降低计算量。因此,当Quotient函数范围小于2时,宽度值减少的速率较慢,这无疑会增加迭代次数,当范围大于7时宽度值较小,则会产生大量的集群。
从图3中可以设定Quotient(s,β)函数的范围为2≤Quotient(s,β)≤6(即QMAX=6),Quotient函数值大于6的时候,设其值为6,特别地,Quotient函数值为0或1的时候,设其值为2。使用式(1)中宽度计算公式,设定其迭代的子集群宽度权值最小为父类宽度值的0.4倍,最大为父类宽度值的0.8倍。聚类中对象数量越多其宽度值权值则越小,这样可以减少算法迭代的次数,同时能够减少聚类时间。其函数范围表示如下:
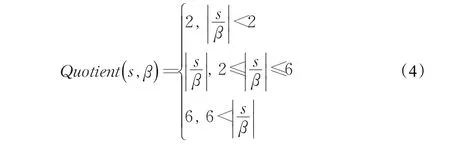
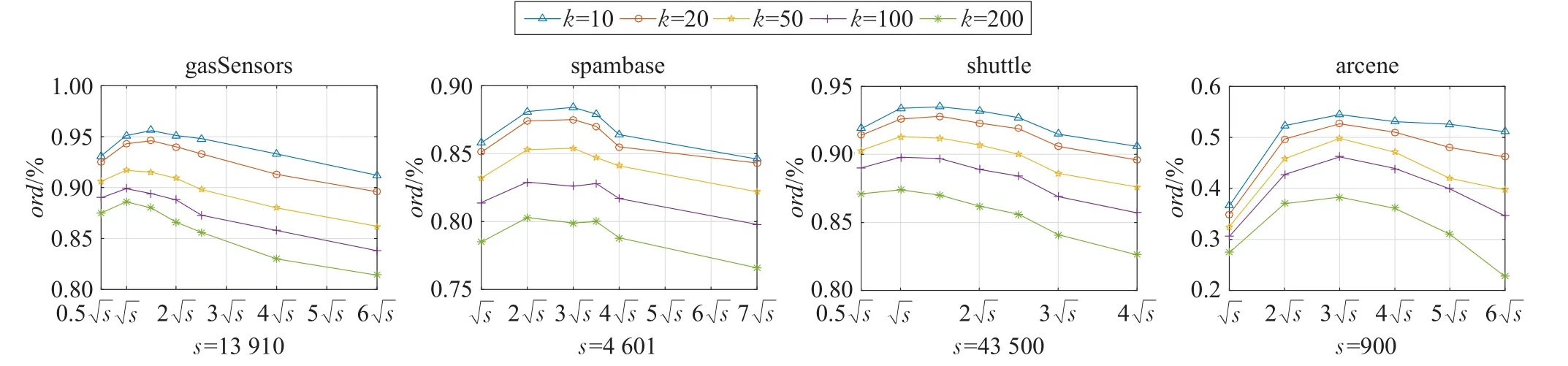
图2 不同β值对应生成的集群数量对算法性能的影响
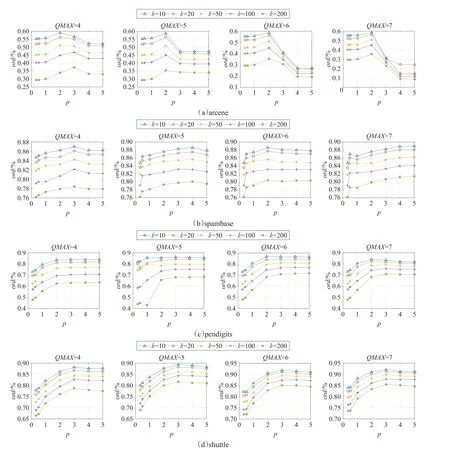
图3 不同p值和不同函数Quotient的范围对本文算法性能的影响
4.3 性能指标
原始kNN查询方法的不足在于它需要一个冗长的计算时间,这是由于对数据集中的每个对象都要进行距离计算。因此现有的改进kNN搜索方法的主要目标就是减少数据集中对象的距离计算,为了衡量这种方法的效率,采用建模时间、kNN查询时间和数据集中参与距离计算对象的数量作为评价标准。
4.3.1建模时间
这些方法都是kNN搜索之前的预处理步骤,每个方法都以自己的分解技术来构建索引结构。图4显示了这几种方法在每个数据集上的建模时间,从图中可以看出k-Means方法是最差的,而且会受到数据大小的影响,固定宽度算法(FWC)则是第二差的方法,相较于kNNVWC与NOWCkNN方法,FWC算法的建模时间通常是比较长的。而KDTree方法在低维度数据集中效果较好,在高维度数据集中建模时间较长。kNNVWC由于每次进行聚类迭代时,宽度计算都会消耗大量的时间。本文所提方法NOWCkNN建模时间相对较短,对比kNNVWC算法,NOWCkNN能减少宽度学习时的对象计算消耗,对于不同数据集都能得到较好的聚类集群。对于高维数据,本文所提方法的建模时间相较于其他方法有明显优势,建模时间低于其他方法,对于其他维度的数据也有很好的效果。
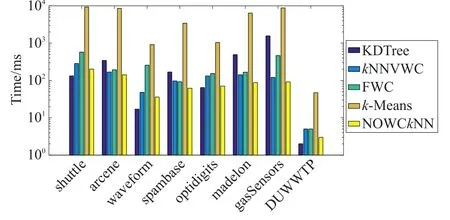
图4 本文方法和其他方法在每个数据集上的建模时间
4.3.2查询时间加速率
对比原始kNN算法评估所提出算法的性能,令ty表示原始kNN算法的查询时间,tn表示运行一个算法的kNN查询时间,算法的查询时间加速率sr表示为:

查询时间加速率反应了改进算法对于原始kNN算法的影响程度,即查询时间加速率为2说明该算法相较于原始kNN算法提高了1倍,加速率为0.5说明算法比原始kNN慢了1倍。同时,当加速率为1时说明,该算法和原始kNN查询时间相同,也就是说对数据进行预处理后并没有减少查询时间,反而有可能增加查询时间。因此把sr=1作为一个分界点,大于1说明该方法效果较好,能够减少kNN查询的时间;不大于1时表示数据的建模没有减少查询时间,说明该数据集不用预处理即可实现查询。
在kNN查询时,把k值设为5种不同的取值,分别为10、20、50、100、200,图5显示了不同方法在不同数据集以及不同k值的查询时间加速率。从图中可以看出KDTree方法在高维数据中效果不佳,但是在维度较低时能够得到较好的结果。在一些大的数据集中(如shuttle、gasSensors),虽然FWC、kNNVWC、NOWCkNN、k-Means方法得到了很好的结果,但是综合来说NOWCkNN是最有效的方法。对于一些中等数据集KDTree方法效果较差,k-Means方法受到数据集分布的影响表现出稍差的结果。在高维数据集(如arcene、madelon)中,数据量较小时,NOWCkNN与kNNVWC其查询时间加速率都能大于1,本文方法相比kNNVWC能够提高10%,而且NOWCkNN在建模时间上明显小于kNNVWC。在中等维度的数据集中,数据量较大时(gasSensors),KDTree查询效率较低,而k-Means受到数据分布的影响每次查询时间并不固定,并且大部分的查询时间加速率都低于FWC,kNNVWC能把数据集分成更小的聚类,其查询时间加速率优于FWC算法。但是NOWCkNN能根据聚类数量的大小设定宽度值的范围,这能得到效果更好的集群,因此其查询时间加速率要略优于其他几种方法。因此在高纬度数据集中,本文方法的查询时间加速率要明显优于其他方法。
5 结束语

图5 本文方法与其他方法在不同k值上的查询时间加速率
本文针对kNN算法计算量大的问题,提出一种基于基于对象数量的宽度加权聚类算法用于kNN的查询(NOWCkNN)。该算法基于集群内的对象数量和调和系数计算宽度权值,然后迭代的将集群再次划分,这种方法能使集群的分离效果更加优化,在不同维度的数据集中分离出效果较好的集群,分类的结果能够在kNN查询时,使用三角不等式最大化地修剪不太可能的对象。在实验中,使用8个UCI公开数据集验证所提出方法,实验结果显示,与现有方法相比所提出的算法能够减少聚类迭代的次数,减少建模时间,增加kNN查询的修剪率,特别是在高维度、数据量较大的数据集中效果更好。同时本文所提方法具有通用性,在不同维度、不同分布的数据集中都有较好的实验结果。在今后的工作中,将重点关注聚类的改进,进一步减少预处理的成本和查询时间,会使用并行计算以降低预处理时间,同时还会选取新颖的距离(相似度)计算公式;同时将会分级控制产生的集群,以便获取更好聚类结果用于kNN查询。
