基于MS-KCF模型的图像序列中人脸快速稳定检测
2018-10-16叶远征李小霞李旻择
叶远征,李小霞,2,李旻择
(1.西南科技大学 信息工程学院,四川 绵阳 621010; 2.特殊环境机器人技术四川省重点实验室(西南科技大学),四川 绵阳 621010)(*通信作者电子邮箱664368504@qq.com)
0 引言
随着计算机技术的不断发展,计算机性能不断提高,人脸检测技术作为计算机视觉领域中的一个重要分支也取得了巨大的突破,如今,人脸检测在门禁系统、智能监控、智能摄像头等领域[1~3]有着广泛的应用。人脸检测也是一种富有挑战性的技术,如何实时稳定地检测图像序列中角度变化较大、遮挡较为严重的人脸,已成为应用中亟待解决的问题。目前,利用浅层特征的传统方法已经满足不了需求,因此深层次的卷积神经网络(Convolutional Neural Network, CNN)是如今检测技术研究的重点和热点。
传统的人脸检测方法首先需要人工选择特征,例如Haar、局部二值模式(Local Binary Pattern, LBP)、尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)特征、梯度方向直方图(Histogram of Oriented Gradient, HOG)等[4-7];然后对目标进行分类,常用的分类器有Adaboost、支持向量机(Support Vector Machine, SVM)等[8-9]。其中具有代表性的是Viola-Jones等[4]在2001年提出的基于Haar特征的积分图人脸检测方法,大大加快了人脸检测的速度;Forsyth[10]在2007年提出的基于HOG的变形组件模型 (Deformable Part Model, DPM)目标检测算法,利用SVM作为分类器,连续获得2007—2009年PASCAL VOC[11]目标检测竞赛第一名。
传统的人脸检测方法众多,但都具有以下特点:1)需要人工选择特征,其过程复杂,目标检测效果的优劣完全取决于研究人员的先验知识;2)以窗口区域遍历图像的方式检测目标,在检测过程中有很多冗余窗口,时间复杂度高,并且对图像序列中角度变化较大、遮挡较为严重的人脸检测效果欠佳。
近年来,CNN在目标检测领域中取得了巨大突破,成为现如今最先进的目标检测方法。CNN在目标检测上的标志性成果是Hariharan等[12]在2014年提出的R-CNN(Region-based CNN)网络,在VOC上的测试mAP是DPM算法[10]的两倍。自从R-CNN出现以后,基于CNN的目标检测在VOC数据集中的表现占有主导地位,主要分为两大类:1)基于候选区域的目标检测,其中的代表作是Faster R-CNN(Faster Region-based CNN)[13]、R-FCN(Region-based Fully Convolutional Network)[14]和Mask R-CNN(Mask Region-based CNN)[15]等;2)基于回归的目标检测,代表作是YOLO(You Only Look Once)[16]、SSD(Single Shot multibox Detector)[17]等。Huang等[18]详细阐述了元结构(SSD、Faster R-CNN和R-FCN)的检测精度与速度之间折中的方法。除此之外,一些级联的人脸检测方法也具有不错的效果,例如,Chen等[19]的Joint Cascade方法利用人脸检测和人脸的标记点检测进行级联,在传统的人脸检测方法中具有较好的检测效果;Zhang等[20]的多任务级联卷积神经网络(Multi-task Cascaded Convolutional Network, MTCNN)利用三个卷积网络级联,“从粗到精”的算法结构使得多任务地对人脸进行检测,具有较高的召回率,但训练网络时需要用到三种不同的数据集,较为繁琐;Yang等[21]的Faceness网络利用头发、眼睛、鼻子、嘴巴、胡子这五个特征来判断所检测目标是否为人脸,具有较高的检测精度,但不满足实时性准则。
在实际工程应用中,大多数是在图像序列中对人脸进行检测,而不是静态图片,而且要求实时稳定地对角度变化较大以及遮挡面积较大的人脸进行检测。因此本文利用2017年Howard等[22]提出的MobileNet基础网络与SSD网络相结合(MobileNet-SSD, MS),能够很好地兼顾检测速度和精度,并对参数进行调整,使它符合二分类(人脸目标和背景)的人脸检测任务,再利用核相关滤波(Kernelized Correlation Filters, KCF)跟踪器[23]对检测到的人脸进行稳定的跟踪,形成检测-跟踪-检测(DTD)循环更新模型。DTD模型不但能解决多角度和遮挡的人脸检测问题,而且能大大地提高图像序列中人脸目标的检测速度。
1 系统的总体框架
如图1所示,首先读取图像序列,利用MobileNet-SSD网络对图像进行检测;然后更新跟踪模型,将检测到人脸目标的坐标信息传递给KCF跟踪器,将其作为跟踪器的基础样本框,并对样本框附近进行样本采样和训练,用来预测下一帧人脸目标的位置;最后,为了防止跟踪时人脸目标丢失的现象,跟踪数帧后再次更新检测模型,重新对人脸目标进行检测定位。
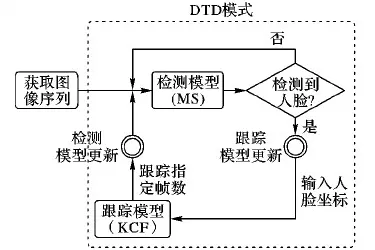
图1 系统总体流程
2 本文主要算法
2.1 MobileNet-SSD结构
在基于CNN的目标检测方法中,用于提取特征图的网络被称为基础网络[13](如VGG、ResNet-101、Inception v2等),而用于分类回归和边界框回归的结构被称为元结构[18]。因此,现存在的基于CNN的目标检测方法可以认为是基础网络和元结构的组合,不同的组合具有不同的分类效果,具体参见文献[18]。在人脸检测任务中,为了兼顾检测速度和精度,本文选用MobileNet-SSD(MS)这种组合形式。
MS网络结构包括四个部分:第一部分为输入层,用于输入图片;第二部分为MobileNet基础网络,用于提取输入图片的特征;第三部分为SSD元结构,用于分类回归和边界框回归;第四部分为输出层,用于输出检测结果。
2.1.1 MobileNet特征提取原理
深度学习正在向手机等嵌入式设备发展,为了满足实时性需求,对基础网络的参数个数有严格的限制,因此MobileNet网络[22]应运而生,它以少量的分类精度换取大量的参数减少。MobileNet 的参数数量是VGG16的1/33,在ImageNet-1000分类任务中具有和VGG16相当的分类精度。
图2为MobileNet基本卷积结构:Conv_Dw_Pw是深度可分离的卷积,深层卷积层(Depthwise Layer, Dw) 使用的是3×3的卷积核,点卷积层(Pointwise Layer, Pw) 使用的是1×1的卷积核,并且每一层深度可分离卷积层后都进行批量归一化(Batch Normalization, BN)和非线性映射(ReLU6)处理。

图2 MobileNet基本卷积结构
本文将MobileNet网络中的激活函数ReLU更改为ReLU6,配合自动调节数据分布的BN算法,以提高训练的收敛速度。式(1)为ReLU6激活函数:
y=min(max(z,0),6)
(1)
其中z表示卷积特征图中每一个特征值。
MobileNet基本卷积结构(深度可分离卷积)的优点有:
第一,深度可分离的卷积结构能大大减少计算代价。两种卷积方式的计算式如下:
(2)
式(2)为标准卷积的计算式,FM为0填充(zero padding)后的输入图像(包括特征图);KM,N为滤波器,M表示卷积时输入图像的通道数,N表示输出的通道数。
(3)
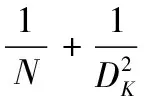
第二,提高了整个检测网络在训练过程中的收敛效率,在卷积神经网络训练过程中,每一层卷积都会改变数据的分布,如果数据分布在激活函数的边缘,将会造成梯度消失,使得参数不再更新。BN算法通过设置两个可以学习的参数来调整数据的分布(类似于标准正态分布),避免了训练过程中的梯度消失现象和复杂的参数(学习率、Dropout比例等)设定。
2.1.2 SSD元结构
SSD网络[17]是一种回归模型,它利用不同卷积层输出的特征进行分类回归和边界框回归,不仅较好地缓解了平移不变性和平移可变性之间的矛盾,而且对检测精度和速度有个较好的折中,即在提高检测速度的同时也具有较高的检测精度。
图3为选自基础网络中不同卷积层输出的特征图,每一个特征图单元都有一系列不同大小和宽高比的k个框,这些框被称为默认框。每个默认框都需要预测b个类别得分和4个位置偏移。因此,对于w*h大小的特征图,需要预测b*k*w*h个类别得分和4*k*w*h个位置偏移,所以需要(b+4)*k*w*h个3×3的卷积核对该特征图进行卷积,将卷积结果作为最终特征进行分类回归和边界框回归。本文是人脸单个类别的检测,因此b=1。
(4)
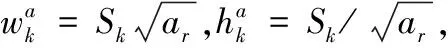
(5)
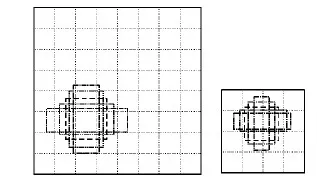
图3 不同卷积层输出的特征图
当默认框与某一类别的标定框(Ground-truth Box)的重合度大于0.5时,则该默认框与该类别的标定框相匹配。
SSD是一个端到端的训练模型,其训练时的总体损失函数包括:分类回归的置信损失Lconf(s,c)和边界框回归的位置损失Lloc(r,l,g),定义[17]如下:
(6)
其中:α用于平衡两种损失;s、r分别表示用于置信损失和位置损失的输入的特征向量;c表示分类置信度;l表示预测的偏移量,包括中心点坐标的平移偏移和边界框宽高的缩放偏移;g为目标实际位置的标定框;N为默认框与该类别的标定框相匹配的个数。
2.2 MobileNet-SSD人脸检测网络
在人脸检测任务中,MobileNet巧妙的结构大大降低了计算复杂度,这也是本文方法满足快速性要求的一个重要原因。但是MobileNet的Pw结构改变了Dw结构输出数据的分布,这是其分类精度降低的主要原因。
为了防止MobileNet的卷积结构带来精度损失,舍去MobileNet的全连接层,额外增加8层标准卷积层,用于扩大特征图的感受野、调整数据分布和加强分类任务要求的平移不变性;为了防止梯度消失,在每一个卷积层的后面加上BN层和激活函数ReLU6;为了满足检测任务要求的平移可变性,分别获取MobileNet中两层特征图和附加的标准卷积层中的四层特征图组成特征图金字塔,再用不同的3×3卷积核进行卷积,卷积后的结果作为最终特征进行分类回归和边界框回归。
图4为MS网络特征金字塔,以300×300大小的图片作为输入,上述六层卷积特征图金字塔中每一个特征单元的默认框个数分别为4、6、6、6、6、6,并且对于不同层、不同任务所用3×3大小、步长为1的卷积核参数都不相同。表1为MobileNet-SSD的总体架构,Conv_BN_ReLU6表示标准卷积层,Conv1_Dw_Pw表示深度可分离卷积层,“*”表示该卷积层输出的特征图将会用于分类回归和边界框回归。由于人脸目标比较小,故本文选取了较浅层的Conv7_Dw_Pw输出的特征图。

表1 MobileNet-SSD总体构架
2.3 KCF算法原理
在图像序列中运动的人脸有姿态、角度的严重变化和部分遮挡,会造成人脸检测过程中出现漏检问题。本文利用快速稳定的KCF目标跟踪模型解决以上问题,并且在人脸检测过程中采用模型更新策略,其具体过程:利用MS模型检测到人脸的同时启动KCF模型进行持续稳定的跟踪,为了避免跟踪丢失,重新启动MS模型对人脸再次检测。因此,KCF算法起到的作用是:1)加强图像序列中人脸检测对姿态、角度等变化的鲁棒性;2)在DTD模型中起到衔接和加速的作用,大大提高整个系统的检测速度。
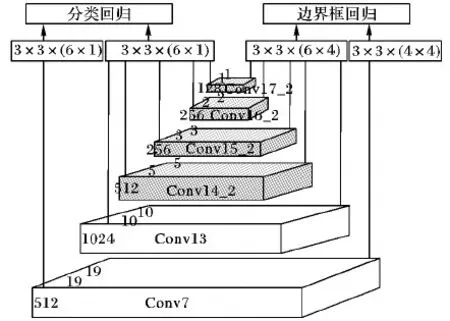
图4 MobileNet-SSD网络特征金字塔

(7)
对式(7)进行最小二乘法求解得:
w=(XTX+λI)-1XTY
(8)
其中:X=[x1,x2,…,xi]T,Y=[y1,y2,…,yi]T。X中每一行表示一个特征向量。式(9)是式(8)的复数域形式:
w=(XHX+λI)-1XHY
(9)
此时求解w的计算时间复杂度为O(n3),式(9)中XH=(X*)T,X*为X的复共轭转置,即XH为X的厄米特转置。
在KCF算法中(具体算法见文献[22]),训练样本和测试样本都是由基础样本xi=[xi1,xi2,…,xin]产生的循环矩阵Xi构成的,即:
(10)
式(8)中,Xi可以通过离散傅里叶矩阵F得到。
(11)
(12)
(13)
(14)

(15)

此时式(15)中w求解的计算时间复杂度是O(n),离散傅里叶变换的时间复杂度为O(nlogn),因此KCF算法能大大降低整个系统的时间复杂度。
KCF算法的目的在于通过傅里叶空间的循环矩阵来降低回归计算的时间复杂度,从而获得速度提升。
3 实验结果及分析
3.1 测试方法及超参数设定
首先在WIDER FACE[26]和FDDB[25]人脸数据基准上验证本文MS模型在静态图片上的检测性能,使用的评价指标是召回率和速度;接着在图像序列中验证本文MS-KCF模型的检测性能。
首先利用ImageNet-1000分类数据库训练基础网络MobileNet,再利用训练好的模型迁移到检测网络中进行边界框回归和分类回归的微调,用于微调的数据库来自WIDER FACE数据库的训练集。选择5种宽高比的默认框,分别为1.0、2.0、3.0、0.5和0.33,并且设定式(4)中默认框的最大尺度为0.95,最小尺度为0.2。六层卷积特征图金字塔中每一个特征单元的默认框个数分别为4、6、6、6、6、6。训练过程中,IOU在[0.5,1]区间内的为正样本,在(0.2,0.5) 区间内的为负样本,在[0,0.2] 区间内的作为难例。另外,本文的学习率是初始化为0.1的指数衰减的学习率,并且随机初始化权重和偏置项。
3.2 WIDER FACE人脸数据基准静态图片检测结果
WIDER FACE人脸数据基准是全世界最具权威的人脸检测评估平台之一,数据集共有32 203张照片,其中有393 703张人脸。测试集为总数据集的50%,人脸按照角度、遮挡等的严重程度分为Easy、Medium、Hard三个等级。检测结果如图5所示。

图5 WIDER FACE检测结果
将本文的MS算法与先进的MTCNN和Faceness算法在WIDER FACE数据集中作对比,精度-召回率(Precision-Recall, PR)曲线结果如图6所示。实验结果证明,MS算法在Easy、Medium和Hard子数据集的召回率分别为93.11%、92.18%和82.97%,其表现均优于MTCNN和Faceness。由此可知MS算法对遮挡和角度变化较大的人脸在WIDER FACE数据集中具有较高的鲁棒性。
3.3 FDDB人脸数据基准静态图片检测结果
FDDB[25]人脸数据基准是全世界最具权威的人脸检测评估平台之一,测试集包括2 845张照片,其中有5 171张人脸,人脸图片具有不同姿势、不同分辨率、多种角度、遮挡以及不同光照等特点。
图7的检测结果表明本文方法对于不同姿势、不同分辨率、多角度、遮挡以及不同光照的人脸均具有较好的鲁棒性。而表2的结果说明本文方法具有较好的召回率,检测速度则是在GTX1080 GPU上进行的评估,输入图片均缩放为300×300的大小。如表2所示,本文MS方法的检测速度较快,分别是MTCNN的2.8倍和Faceness的9.3倍,因此本文方法在静态图片库上测试具有较高的召回率和较高的检测速度。图8是本文方法与一些先进算法的ROC性能曲线对比。
本文MS算法的训练集是WIDER FACE数据集,在FDDB人脸检测基准中测试,结果表明MS算法对于静态图片中人脸的检测具有良好的鲁棒性。但实际工程中大部分应用都是基于图像序列的,因此本文利用MS-KCF模型来解决图像序列中的人脸角度变化较大和遮挡较为严重的问题。

图6 WIDER FACE测试PR曲线

图7 FDDB检测结果

方法召回率/%速度/ fpsMS93.6084MTCNN[20]95.0430Faceness[21]90.999
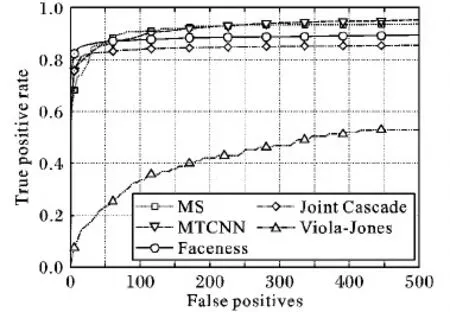
图8 ROC曲线性能对比
3.4 MS-KCF模型在图像序列中的人脸检测结果
利用VOT2016数据集中的Girl和FaceOcc1图像序列来测试MS-KCF模型的性能,其中Girl是人脸角度变化较大的图像序列,FaceOcc1则是人脸严重遮挡的图像序列。
图9中(a)和(b)分别为Girl图像序列和FaceOcc1图像序列,前两排为MS模型的检测结果,后两排为MS-KCF模型的检测结果。显然,MS-KCF模型对于图像序列中人脸的角度变化遮挡具有较好的检测性能。
由图10和11可知,对于图像序列中的人脸检测任务,具有模型更新功能的MS-KCF性能优于只具有检测功能的MTCNN[20]、Faceness[21]等模型,其原因是MS-KCF是针对图像序列中的人脸提出的一种新的自动检测-跟踪-检测(DTD)模式,该模式以跟踪模式作为衔接,能够避免单独的检测模式带来的漏检现象。本文检测速度是在GTX1080 GPU上评估的,输入图片均缩放为300×300的大小,实验结果表明具有模型更新功能的MS-KCF方法是快速的,达到193帧/s,其检测速度分别为只具有检测功能的MS算法的2.3倍,MTCNN的6.4倍和Faceness的21.4倍。
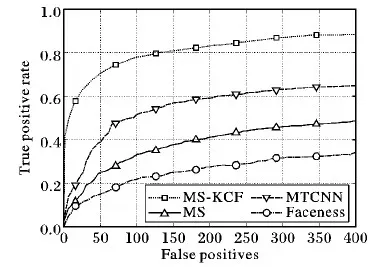
图10 Girl图像序列的ROC曲线对比
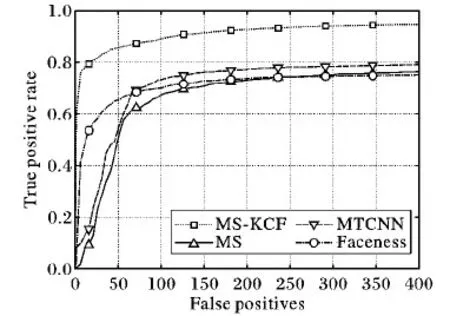
图11 FaceOcc1图像序列的ROC曲线对比
考虑到KCF算法的稳定性和快速性,本文选择该算法作为DTD模式的衔接,它的跟踪性能在文献[23]中已有大量验证,这两个性能加强了本文检测算法的稳定性和快速性,实验结果表明MS-KCF算法在图像序列中对严重遮挡和角度变化大的人脸仍具有很好的检测效果。
4 结语
本文结合快速精确的目标检测模型MS和快速跟踪模型KCF提出了一种新的DTD模式,即MS-KCF人脸检测模型。本文提出的DTD模式具有普遍适用性,研究者可以根据不同需要更换模式中的具体算法。根据MobileNet参数少、精度高的特点,结合改进的符合人脸检测的特征金字塔式SSD元结构构建了快速稳定的MS人脸检测模型,再融合快速稳定的KCF跟踪模型构建适用于图像序列中的MS-KCF人脸检测模型,能够快速稳定地检测出图像序列中角度变化较大、遮挡较为严重的人脸,因此,对高性能嵌入式机器视觉实时应用场合具有较高的参考意义。
