基于Spark的推荐系统的设计与实现
2018-10-15李星,李涛
李 星,李 涛
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
在当今大数据时代[1]背景下,处在互联网浪潮之中的人们能够以前所未有的方式获得更多、更全、更丰富的信息。当前逐步从信息匮乏的阶段慢慢过渡到信息爆炸的阶段,从而进入到一个信息过载的时代,人们在享受丰富信息福利的同时,也经常陷入到数据的海洋中无所适从。信息过滤是人们必须要面对的问题,而推荐系统一直发挥着至关重要的作用。推荐系统不仅可以使用户更方便快捷地发现切合自身需求的有用信息,而且能够保证信息更加准确地推送给潜在用户,达到企业与消费者的共赢[2]。在推荐系统中影响其性能高低最重要的因素就是其推荐算法的效率,而推荐系统中最为经典的算法就是协同过滤算法[3],该算法是基于用户-物品行为历史数据集,利用其中的相似性计算或者用户兴趣模型训练的办法进行过滤推荐。
在信息泛滥的互联网世界中,不仅需要过滤海量数据,而且要力求在最短时间内响应用户的需求,推荐系统必然要具备大数据处理能力。目前这一领域的框架有很多,其中Spark作为主流的内存计算框架,具有很强的大数据处理能力,运行于Spark平台[4]的推荐系统有望获得极高的运行效率和处理能力。文中即是基于Spark分布式计算框架进行推荐系统的研究和实现。
1 Spark平台
1.1 Spark简介
Spark是一个通用的大规模数据快速处理引擎[5],是美国加州大学伯克利分校AMPLab于2010年开发的大数据计算平台。不同于Hadoop MapReduce[6],Spark Job计算的中间输出结果可以直接缓存在内存当中,不再像MapReduce那样频繁读写本地磁盘。基于以上特点,Spark在分布式迭代运算方面的速度要远远优于经典的Hadoop MapReduce框架。
AMPLab还基于Spark Core开发了大数据处理一体化的技术生态系统BDAS(the Berkeley data analytics stack),即伯克利数据分析软件栈。除了基础的Spark计算框架,它还具有更高层级的计算能力[7],主要包括Spark Streaming流处理框架、SparkSQL结构化数据的查询及分析的查询引擎、GraphX图计算框架和MLlib机器学习库等等。恰是因为上述子项目的存在,使得Spark能够提供更全面灵活的计算能力。
1.2 Spark设计思想
Spark对数据的核心抽象是弹性分布式数据集(resilient distributed datasets,RDD[8]),其实就是分布式的元素集合。有别于普通的数据集,RDD中的数据是分区存储的,以达到数据的并行处理。因此,Spark处理数据的过程即是通过需处理的数据创建RDD,然后对RDD进行相应的Transformation和Action操作并最终得到运算结果。RDD通常缓存在内存中,父RDD的输出结果可以在内存中直接作为子RDD的输入,迭代计算的效率因此大大提高。使用Spark编程无需关注底层的数据切分和存储过程以及计算过程的容错机制,只需集中于业务逻辑处理,提高了编程效率。
1.3 Spark的运行架构
在Spark集群部署后,Master进程和Worker进程分别在主节点和从节点启动运行。在Spark应用程序的执行过程中[9],每个Spark应用都由一个Driver程序来负责作业的调度,即分发Task任务,而Worker负责监控本节点的资源状况以及创建Executor进程。在执行阶段,Driver程序会将Task和Task所依赖的数据文件和程序jar包等分发给对应的Worker节点,同时Executor进程对分区RDD进行运算处理。
Spark工作的流程如图1所示。用户首先向Spark集群提交应用程序,Master进程会在一个Worker节点上启动Driver程序来进行任务管理,Driver根据任务情况向Master申请到资源(CPU、内存等),并初始化Executor。然后SparkContext中的DAGScheduler会将任务生成有向无环图(DAG)并提交给TaskScheduler,TaskScheduler再根据DAG生成相应的TaskSet并分配任务给Executor并发执行。
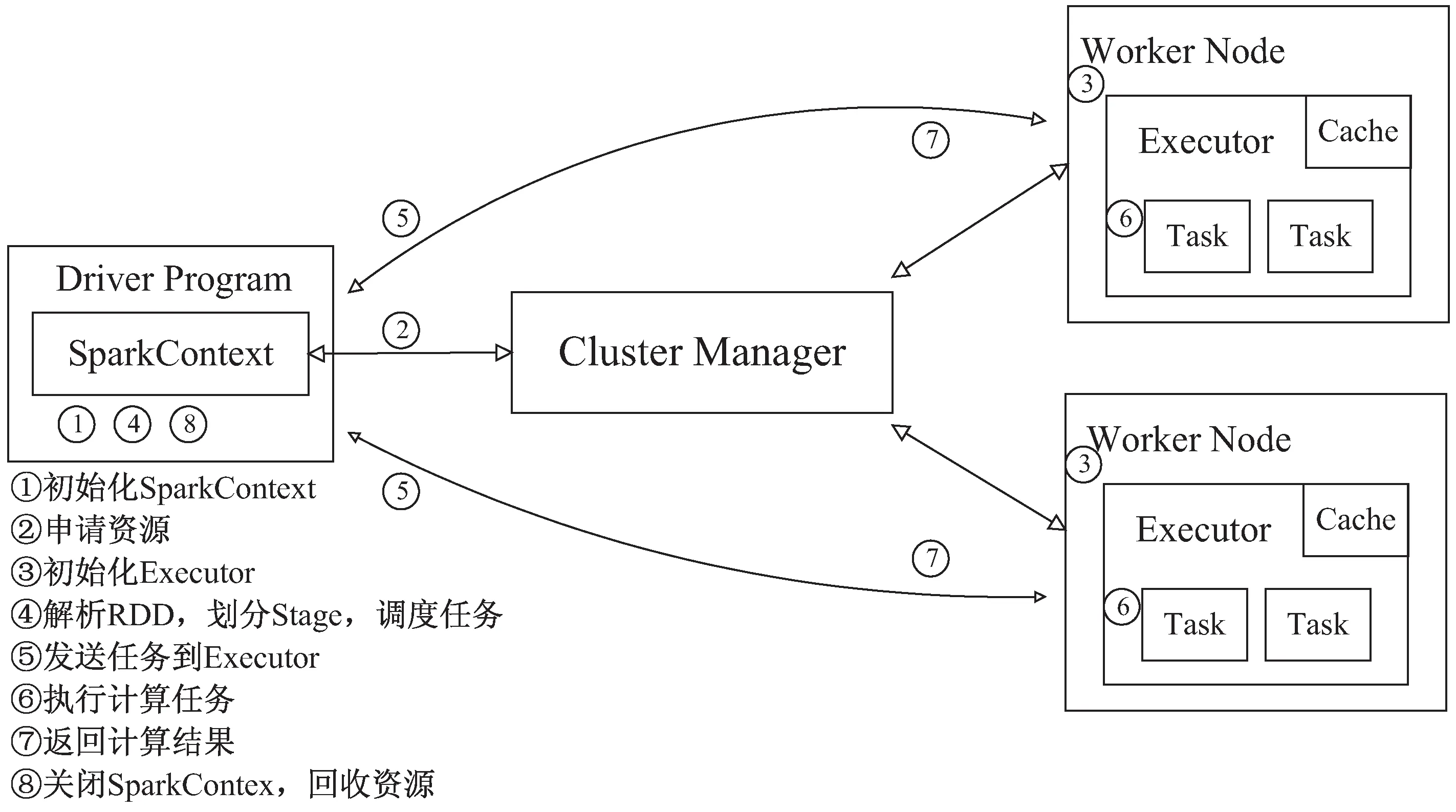
图1 Spark工作流程
1.4 环境说明
文中搭建的Spark集群[10]采用了实验室中的四台普通计算机,组成了一个Master主节点和三个Slave节点的运行环境,节点均采用Centos6.5 Linux系统,节点之间使用局域网进行网络连接,同时以上节点还运行了分布式文件存储系统HDFS的服务。具体情况如表1所示。
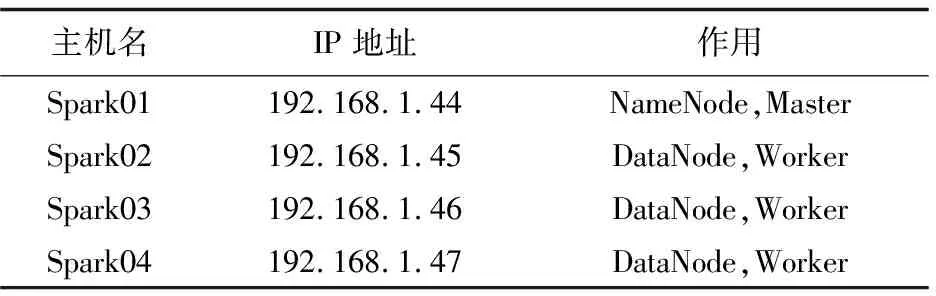
表1 节点具体说明
1.5 软件安装
本系统Java JDK的安装包采用jdk-7u79-linux-x64.tar.gz,Scala的安装包采用scala-sdk-2.10.4.tar.gz,Hadoop安装包采用hadoop-2.5.0-cdh5.3.6.tar.gz,在系统软件安装过程中最重要的一点就是要配置安全外壳协议(SSH)以便实现远程无密码登陆与管理。在完成Hadoop集群的配置安装后,在此基础上进行Spark的安装,Spark安装包采用Spark 1.5.1.tar.gz,软件开发环境采用IntelliJIDEA 2017.2.1。集群所有软件在安装并配置完毕后即可启动Spark分布式集群进行测试。
2 推荐系统
2.1 推荐系统概述
如今推荐系统已经普遍应用于电商、新闻、地理位置等诸多领域。比如在电商领域,推荐系统实现的功能就是根据已有信息,如物品信息、用户信息、用户行为信息等,将相应的物品推荐给用户。常见的推荐任务主要有两种;评分预测和Top-N推荐。对于用户U,评分预测的任务是预测U对某物品可能的打分,而Top-N推荐则是为用户U推荐N个他可能感兴趣的物品。这两种推荐都是依据用户、物品自身的信息及用户过去的行为记录做出的预测。
2.2 协同过滤算法
协同过滤(collaborative filtering,CF)算法的核心思想就是利用群体的智慧来进行事物推荐。协同过滤按照参照物的不同主要分为基于用户的协同过滤(user-based CF)和基于物品的协同过滤(item-based CF)[11]。user-based CF在推荐时首先根据行为记录找到相似用户(即人以群分),然后根据相似用户进行推荐。item-based CF最初由Amazon提出并应用,基于物品协同过滤算法不是计算用户间的相似度,而是计算物品间的相似度(即物以类聚),将与目的用户偏好过的商品的相似商品作为候选推荐列表推荐给目的用户。对于大型电子商务平台而言,商品更新速率较慢并且商品的数目远小于用户数目,计算物品相似度开销远远比计算用户相似度开销小,因而item-based CF的稳定性比user-based CF的稳定性更高[12]。故该系统采用基于物品协同过滤的Top-N推荐。
2.3 基于物品协同过滤算法的基本思路
item-based CF的基本思路和流程如下:
(1)收集用户的历史行为数据,进行初步的减噪和归一化处理。统计得出物品-用户评分矩阵,用以表示具体每件物品被哪些用户评分过,该表其实是由用户-物品评分表(如表2所示)转置得到,而用户-物品评分矩阵则是每位用户对物品的历史评分记录。

表2 用户-物品评分表
推荐系统中主要有显式评分与隐式评分两种评分方式。其中显示评分指的是用户对物品的评价直接用具体分数来表示,比如平时比较常见的用户对某种物品的喜好程度,可以由1至5分来量化;而隐式评分则只是依照用户对于某种物品有没有购买、是否浏览过、评论过等行为,如果有相关行为则评分为1,无则评分为0。于是,可以得到一个N×M矩阵R:
(1)
其中,N表示用户数量;M表示物品数量;rij表示用户ui对物品mj的评分。若用户ui对物品mj进行了评分,则rij≠0,否则rij=0。由于文中采用隐反馈方式,所以rij的取值只能是1或0。
(2)计算物品之间的相似度。
找到与物品最相似的N个物品集合,物品m和n的相似度可使用以下余弦相似度公式计算:
(2)
其中,N(m)表示所有拥有物品m的用户集合;N(n)表示所有拥有物品n的用户集合。使用相似度计算公式可计算出示例表2中物品m1、m2以及m1、m3的相似度:
(3)
(4)
由结果可知m1、m2间有更大的相似度,因此在一位新用户购买m1时,可优先将m2商品推荐给他。
在示例计算过程中可发现此方法实际上会对比物品空间中的所有物品,致使其时间复杂度较高,为O(n2)。然而一个大型数据集中,会出现很多物品并没有共同用户交集的情况,因此在实际操作中,建立用户-物品倒排表可以优化计算,如图2所示。其中矩阵W'中的值为式2中分子的值。
图2 用户-物品倒排表生成过程
(3)计算出物品之间的相似度后,根据用户的历史物品表再计算出用户-物品兴趣度,以此进行物品推荐。用户u对物品m的兴趣度为:
(5)
其中,interest(u,m)表示用户u对物品m的兴趣度;N(m,k)表示与物品n最相似的K件物品集合;N(u)表示用户u现已拥有的物品集合;simmn表示物品m和物品n之间的相似度;run表示用户u对物品n的兴趣值(若只考虑隐式反馈数据,run为1)。
2.4 推荐系统评价指标
一个推荐系统的性能好坏可以用以下评测指标[13]来评定:
(1)准确率(precision)。
准确率是一个非常重要的性能指标,直接关系到推荐系统服务质量的好坏。若推荐系统向用户u推荐了N件物品,推荐集合可记为R(u),而用户在测试集T上的喜好物品项集合记为T(u),则准确率计算公式如下:
(6)
准确率指的是向用户推荐的集合项R(u)中,有多少件物品属于正确推荐,即推荐正确项占推荐列表的比例。
(2)召回率(recall)。
召回率指的是用户喜好的集合项T(u)中,含有多少推荐系统正确推荐的物品,即推荐正确项占真实喜好列表的比例。召回率反映了推荐系统推荐项的覆盖率,具体公式为:
(7)
(3)覆盖率(recover)。
覆盖率指的是推荐集合项R(u)在供应商提供的物品总量中所占的比例[11],具体公式为:
(8)
其中,U表示所有被推荐用户;I表示供应商提供的所有物品项。覆盖率描述了推荐系统对物品长尾的发掘能力。
(4)均方根误差(RMSE)。

(9)
依据准确率和召回率公式定义可知,准确率和召回率往往是两个相互矛盾的指标参数[14]。系统推荐并且用户真实喜好的物品项集与系统推荐的物品项之间的比值越大,准确率越大;系统推荐的物品项集中用户真实喜欢的物品越多,召回率也越大。如果推荐系统推荐的物品很多,虽然召回率可能提高,准确率也会有所下降;因此如果希望推荐系统更加准确,推荐物品数量一定要适当。
3 Spark平台推荐算法并行化实现
3.1 基于物品的协同过滤推荐算法的Spark并行化实现流程
item-based CF算法的核心思想是对用户推荐与其已喜欢物品相似的不同物品。其中比较关键的几个参数及公式为用户-历史评分矩阵Rm,物品之间的相似度计算公式simmn及用户对物品兴趣度计算公式interest(u,m)。本系统以电影推荐为背景,测试数据集选取经典的MovieLens[15],该数据集记录了用户评分记录。文中采用100万条记录作为实验数据集,将数据集文件下载并解压后,其中的users.dat文件记录所有用户相关信息;movies.dat文件存储的是电影自身信息,包括电影名、类型、年份等。ratings.dat文件记录用户-电影的评分信息及时间戳;每条评分记录的格式为userid::itemid::rating::timestamp,前三项是需要的数据资源。基于物品的协同过滤推荐算法具体流程如图3所示。

图3 基于Spark的商品协同过滤算法流程
输入:userid、itemid、rating
输出:用户最感兴趣的N个物品项
(1)计算用户对物品的喜好:采用隐反馈数据原则对每个用户给物品的评分进行预处理操作。数据处理如下:用户评分的物品记为1,反之记为0;
(2)统计每个物品数好评总数;可设置阈值,低于指定数的物品不参与后续计算;
(3)统计物品-好评键值对,对两个相关联的物品之间的共同用户数进行统计(也可设置阈值);
(4)计算任意两个有关联物品的相似度;
(5)根据兴趣度向用户推荐N个最感兴趣的物品。
3.2 实验结果与分析
系统基于Spark平台推荐算法并行化实现,并测试计算推荐系统的相关评测指标:准确率、召回率、覆盖率等。实验中训练集占数据量75%,测试集占25%。根据不同的参数设置,每个实验均进行4次,并求得4次结果的平均值作为最终的测试结果[16],如表3所示。
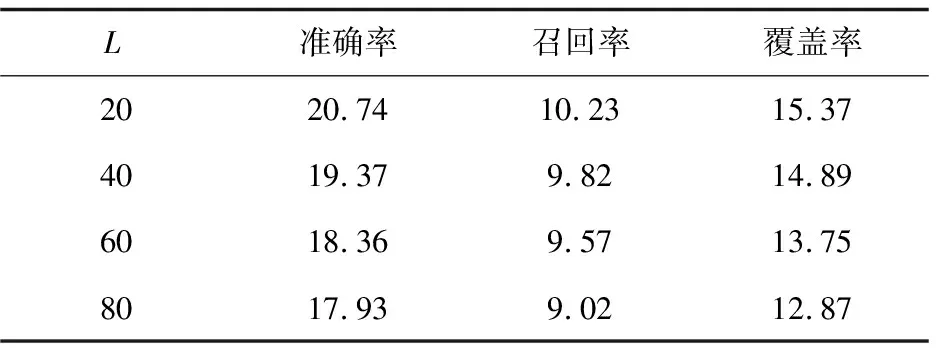
表3 基于物品协同过滤推荐算法在不同推荐列表长度(L值)时的性能 %
从表3可以看出,基于物品协同过滤推荐算法中的准确率与召回率并不是和推荐列表长度呈线性关系,并且当推荐列表长度为20时,系统的准确率与召回率会比较高,由此可以看出,推荐列表长度的选择是基于物品协同过滤推荐系统性能的重要影响因素。而对比覆盖率可发现覆盖率随着L值的增长越来越低,是因为当推荐列表长度不断增加时,推荐算法越来越倾向于推荐比较热门的电影所致。
4 结束语
大数据时代互联网中蕴藏着海量富有价值的信息资源,如何更加快速有效地从中挖掘有用信息正是大数据应用平台需要考虑解决的问题。而用户推荐这一应用场景,正是从海量数据中挖掘有用信息的典型案例。研究表明,Spark计算框架相比传统的MapReduce框架具有更强的并行计算能力。并且推荐算法中需要进行连续迭代计算,这一需求也恰好使之非常适合运行在Spark平台之上。文中以设计并实现一个大数据环境下的推荐系统为主线,介绍了大数据相关技术和推荐系统的相关概念,实现了基于Spark的Item-CF推荐系统,并在数据集MovieLens下进行了相关指标的测评。结果显示,该系统能够较好地完成推荐任务,达到了设计前的预期。下一步的工作将针对电商平台中日益多样化的用户行为,设计多种的数据处理方式,优化推荐算法引擎,提升系统的通用性和可靠性。
