基于Scrapy技术的数据采集系统的设计与实现
2018-10-15陈春玲
杨 君,陈春玲,余 瀚
(南京邮电大学 计算机学院,江苏 南京 210003)
0 引 言
互联网在人们的生活中无处不在,通过互联网,人们可以便捷、高效地获取所需要的各种各样的信息[1]。然而在信息大爆炸式发展的今天,互联网上的网络数据量以其惊人的速度呈几何级增长。就网页数据而言,每天都如雨后春笋般涌出。互联网上的各种信息在带来便利的同时,因其数据繁杂且数据量众多,也带来了信息过载的问题。因此,面对互联网上的海量数据,如何快速且高效地获取所需要的数据是一个迫切需要解决的问题。
基于Scrapy框架设计的数据采集系统,可以高效、准确地获取所需要的数据资源。根据用户指定的主网及数据类型关键字,爬取所需要的数据,并且可以将获取到的数据进行清洗和分类。高效地数据获取、数据的实时性、数据的准确性对用户来说都具有十分重要的实际意义。
1 关键技术
1.1 Scrapy
Scrapy是用Python编写实现的网站数据异步爬虫应用框架。用户可以根据需求进行修改,使用起来简单轻巧因而用途十分广泛,可以应用在包括数据挖掘、信息处理或存储历史数据等一系列领域。Scrapy内部实现了包括并发请求、免登录、URL去重等多种复杂的操作。Scrapy设计理念先进而简单,效率高,可扩展性好,可移植性高,在主流的操作系统平台上都具有良好的性能[2]。
Scrapy主要由5个部分组成:Scrapy Engine(Scrapy引擎)、Scheduler(调度器)、Spiders(蜘蛛)、Item Pipeline(数据处理流水线)和Downloader(下载器)[3]。爬取过程是调度器把初始URL交给下载器;下载器向网络服务器发送服务请求,得到响应后将下载的数据转交给蜘蛛;蜘蛛-般是用户自己定义的程序,蜘蛛会对网页进行详细的分析,分析得到的待爬取链接会请求调度器;调度器再次调度处理这些URL,分析得到的数据,会转交给数据处理流水线继续处理[4]。Item会定义数据输出格式等,最后由Pipeline输出到文件中,或者存到数据库中等。总之数据处理流水线对数据进行的后期处理包括过滤、去重和存储等[5]。
1.2 Django
Django框架是基于Python语言编写的一个开源免费的Web应用框架。Django具备较为完美的模版机制、对象关系映射机制,还能够创建出动态管理后台信息的界面。相较于其他基于Python的框架,Django框架更加注重组件之间的可重复利用性和可插拔性,可以相对简单地开发出功能复杂的带有数据库驱动的网站,以及遵守敏捷开发原则和DRY法则[6]。
Django框架是一个松耦合、高内聚的框架,每个由Django驱动的Web应用都有着明确的目的,并且可独立更改而不影响到其他部分,可以让开发人员更专注于编写清晰、易维护的代码和应用程序的开发。它可以运行在启用了mod_python或mod_wsgi的Apache2上,或者任何兼容WSGI的Web服务器。一个Django工程中,主要分为3个Python的文件(urls.py、views.py、models.py)和html模板文件(index.html)。urls.py指出了URL调用views.py中所调用的视图;views.py用来定义程序的业务逻辑,主要实现URL的分发处理和定义处理Web请求的函数;models.py定义了程序的数据存储结构。index.html是html模板,它描述了这个html页面是如何设计的。
Django的基本结构是MTV(model,templates,view),其中模型模块(model)负责与数据有关的全部事务处理,包含数据存取、数据验证、数据行为以及提供访问数据库的API[7]。视图模块(view)是业务逻辑处理模块,负责模型的存取和正确调用模板,用来定义如何渲染Templates,是联系模型和模板的纽带。模板模块(templates)用来定义数据的显示格式,负责与展现相关的事务[8]。Django的MTV模式实际上只实现了普通MVC模式中的M和V。Django的控制器是框架本身,框架将根据Django的URL配置向合适的视图函数发送请求。
2 系统设计
2.1 系统分层架构设计
系统采用典型的B/S(browser/server)架构(见图1),分为三层:前端、后端、数据库。
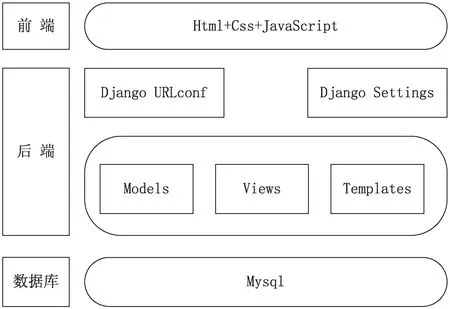
图1 系统分层架构
前端采用典型Html、Css、JavaScript技术来呈现网页,Css使用bootstrap样式库,JavaScript使用jQuery,并且使用Ajax异步刷新技术。
该系统的架构设计完全基于Django的MTV架构实现。Django URLconf实现了Http请求的URL匹配功能,寻找对应的视图函数。Django Setting配置了整个系统的设置。
Models与数据库Mysql实现ORM关系映射,不需要关注数据库中数据的结构层次,直接通过Models对象来操作数据库。
2.2 系统功能设计
按照用户使用的方便性和对系统需求的分析,基于Scrapy的数据采集系统包含服务器端和浏览器端功能模块,如图2所示。
2.2.1 服务器端功能模块
(1)网页解析模块:当抓取网页数据时,需要从访问到的HTML源码中提取数据。Scrapy提取数据有自己的一套机制,它们被称作选择器(selectors),因为它们通过特定的XPath或正则表达式来“选择”HTML文件中的某个部分。而这里每个字段的XPath表达式和Python正则表达式都是在任务新建模块进行配置的。
(2)数据处理模块:当一个任务完成后,该模块会将得到的数据进行简单清洗,比如删除重复的数据,并且将数据关联到它们所在的任务种类,方便后面的数据查询。
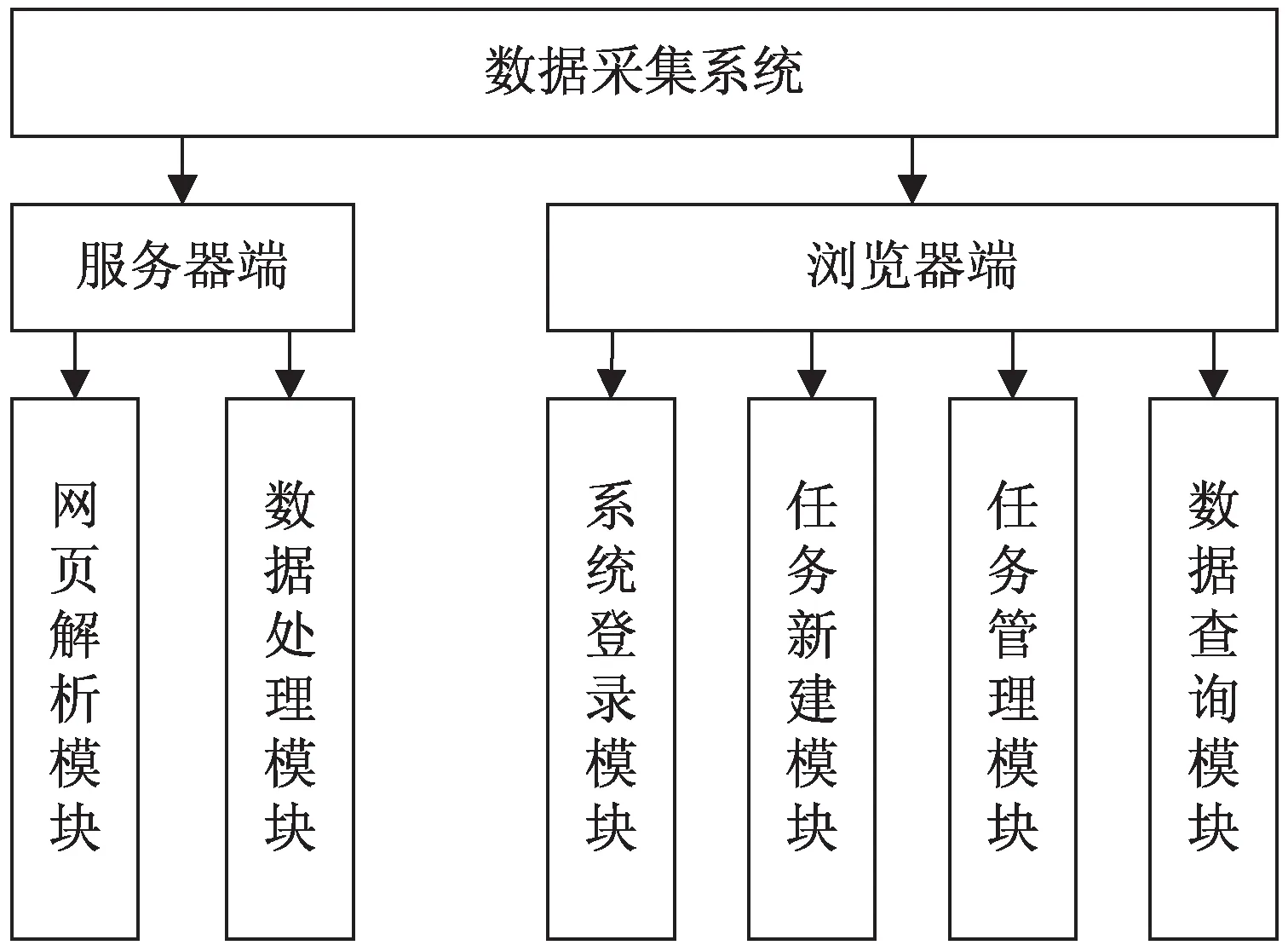
图2 系统功能结构
2.2.2 浏览器端功能模块
(1)系统登录模块:判断客户端用户的合法性,如果输入的用户验证信息正确,就可以进入自己的任务管理模块。新用户可以点击“用户注册”进入注册界面,完成自己信息录入。
(2)任务新建模块:在该模块可以新建自己的子任务,并且归类到自己的任务树中。需要配置的信息包括任务名称、任务的主网地址以及该任务所属父节点,然后新建需要爬取的字段,包括字段名称、XPath表达式和正则表达式。
(3)任务管理模块:在该模块,所有的任务和任务类名会形成一棵任务树。根节点是用户名,用户可以根据自己的需要,手动新建或删除叶子节点,以增加、删除任务类别。当删除父节点时,所有的子节点都会被删除,其中的任务类别和子任务都会被删除。还可以通过手动拖动节点,改变任务间关系。
(4)数据查询模块:用户可以通过输入任务名以及数据关键字进行组合搜索,搜索到的数据可以根据需要设置成一页展示的数据条目数,如一页五条、一页二十条或一页一百条等等。
2.3 数据库设计
在当前应用环境中,运用合理的方法设计并抽象出最佳的数据模型,并且在此基础上搭建上层应用系统,在此基础上创建的数据库能有效地存取数据,满足系统需求和用户需求。根据该数据采集系统中的设计,采用MySql数据库。
用户信息表中包括用户名、用户邮箱、用户号码、用户创建时间和更新时间,如表1所示。

表1 用户信息表结构
任务信息表包括任务英文名、任务中文名、任务目标网址、网址关键字、任务创建时间和任务更新时间(见表2),其中网址关键字用于任务进行时url的爬取筛选,这样爬取的url具有针对性,可以过滤大量冗余的url。
字段表结构包括字段英文名、字段中文名、XPath表达式、正则表达式、创建时间和更新时间(见表3),其中XPath表达式用来定位网页数据位置,正则表达式是根据需要解析数据的。
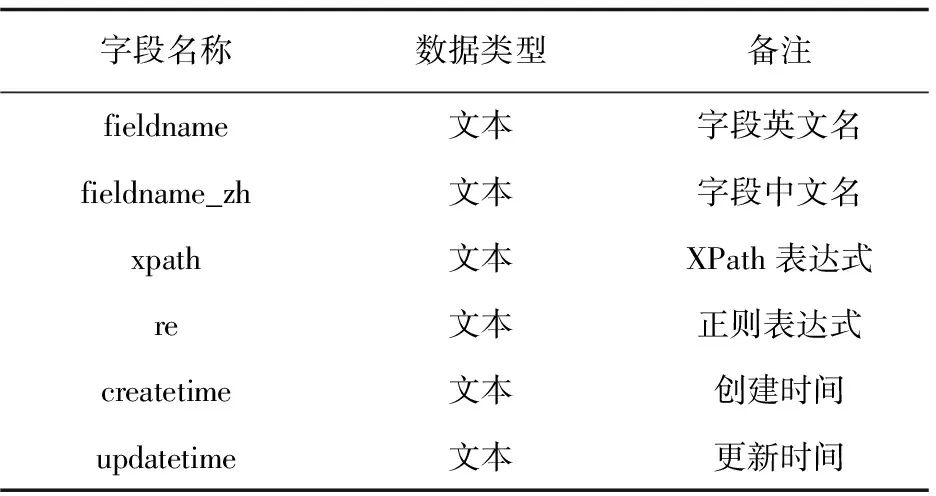
表3 字段表结构
任务树表包括节点名称、父节点名称、创建时间和更新时间(见表4),其中根节点就是用户名,剩余非叶子节点的父节点是用户的任务类型,叶子节点是用户的单个采集任务,名称即任务名。
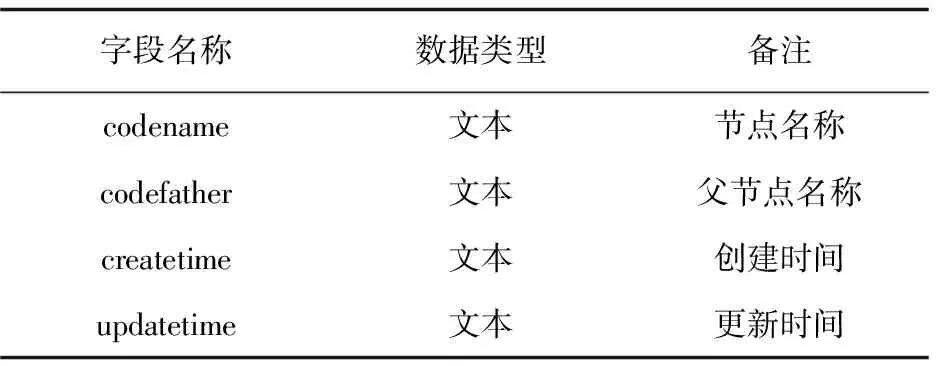
表4 任务树表结构
3 系统功能实现
3.1 浏览器端与服务器端数据交互的实现
Django采用MTV开发模式,在该数据采集系统中,一个完整的请求处理过程如图3所示。
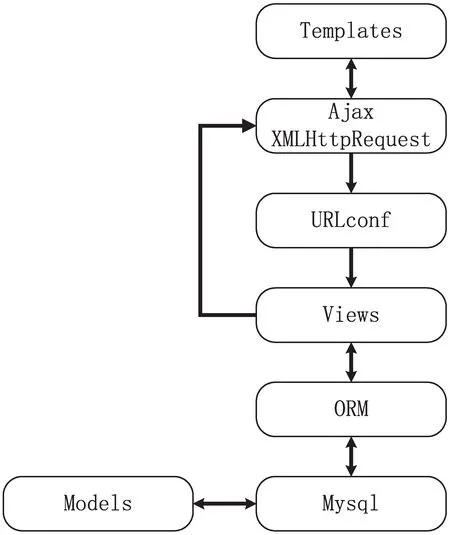
图3 数据交互处理过程
(1)用户在浏览器端填写好表单,前台使用jQuery进行表单验证,验证通过后将表单数据做成Json格式;
(2)jQuery启动Ajax引擎,使用XMLHttpRequest发送Http请求;
(3)请求通过Django框架的urls.py中定义的路由表,匹配对应URL,请求到达URL对应的视图;
(4)调用视图中的相关请求处理函数,对获取到的请求数据进行处理;
(5)视图中的方法可以通过ORM访问底层数据库,进行操作;
(6)再次通过XMLHttpRequest对象获取服务器数据;
(7)模板获取数据,浏览器端使用JavaScript操作,将数据渲染在页面上。
Django的URL映射非常灵活,URLconf中保存了URL模式与所调用视图函数之间的映射表,系统拥有六大app应用,分别对应六个功能模块,每个app应用都有自己的URL映射表,包含的URL几个到几十个不等,通过正则表达式进行匹配。每个URL都含有自己的视图函数,视图函数中包含如常见的POST、GET的HTTP请求,请求数据及请求类型在HTTP的报文中携带。Django的视图负责处理用户请求并且返回响应,一个视图函数就是接受了Web请求并且返回Web响应的Python函数,通过使用Python强大的类库,用户可以在视图函数中处理各种复杂的逻辑[9]。Django通过使用对象关系映射(ORM)将模型同关系数据库连接起来,并提供给用户易于使用的数据库API[10]。主要的数据库ORM包括数据库表结构的创建和数据的增删改查,其中字段类型包括CharField、EmailField、URLField、GenericIPAddressField等,字段参数包括null、default、primary_key、db_column、db_index、unique等。提供了Ajax请求方式,不需要刷新整个页面,仅仅更新需要的数据,降低了服务器的处理时间,带来了更好的用户体验。
3.2 网页数据定位与解析的实现
以新闻出版广电总局(http://www.sapprft.gov.cn/)网站为例,用户想要获取所有新闻出版物的信息,包括音像、图书、电子期刊等。首先定义新闻出版物的7个信息字段(名称,前缀,地区,主办单位,主管单位,类型,网址)。Scrapy根据定义的字段表,生成用来装载数据的7个items容器,该容器会在spider中用到,用来承载其抓取下来的实际数据。
Scrapy的整个数据处理流程由Scrapy引擎进行控制,引擎打开第一个域名,在这里就是任务信息表中的start_ulr,即http://www.sapprft.gov.cn/,然后创建一个http.Request请求,并把请求放入任务队列中,并且构建parse_request方法来处理请求[11]。这里的parse_request是一个回调函数。
请求执行之后,http.Response作为执行结果被返回。请求结果就是response.body,即网页请求响应内容。然后根据任务信息表中定义的url_xpath来解析response.body获取需要的urls,可能会获取0个到几百个,然后通过allowed_url约束条件,将不符合正则表达式的urls剔除,然后将合理的urls放入任务队列中,给引擎执行下一步抓取[12]。
同时使用Scrapy Selectors,即字段表中的XPath表达式和正则表达式来解析response.body获取相应字段的数据转载进入items容器[13]。XPath在配置时尽量使用html的id、class或者属性值去定位,这样既准确又方便,正则表达式是为了去除冗余的数据,匹配需要的数据。
使用yield将items内容传递到ItemPipeline[14],引擎将在该处判断传递来的数据是否完整,内容是否重复,最后根据定义的字段表按设定输出,存储到相应的数据库中。
网页访问的速度直接影响了抓取的速度,有些网站本身结构清晰,访问快,自然数据抓取的速度也会非常快[15]。选取的新闻出版广电总局,网站结构统一,响应速度快,所以在系统开启任务后,用了短短6~10 s的时间就将几十万条出版物信息抓取下来,并且放入数据库中。当第二次启动该任务时,时间会缩短,因为系统不需要再去创建数据库和数据表,也减少了一些任务话费的时间。有些网站访问速度较慢,如土地交易网,系统花费了28分钟抓取了200万条数据,这样的效率确实不尽如人意,这个问题将在后面的开发中进一步改善。
4 结束语
通过对Scrapy爬虫框架和Django Web开发框架技术的研究,设计了一种基于Scrapy技术的数据采集系统,并对浏览器端和服务器端的功能进行了编码实现。在系统的设计和实现过程中,对系统的整体设计框架、系统功能设计和数据库设计进行了详细说明,采用了模块化的设计方法,使系统具有良好的可扩展性。通过Django框架中的MTV开发模式实现了浏览器端和服务器端的数据交互,利用Scrapy技术实现了网络爬虫,jQuery树插件zTree技术实现了任务管理。通过对该系统的测试,用户可以根据需求爬取数据,并将数据保存下来,进行数据处理和数据查询,达到了系统开发的要求。
