基于特征向量与SVO扩展的企业生态关系抽取
2018-10-15代江波毛建华刘学锋张鸿洋
代江波,毛建华,刘学锋,张鸿洋
(上海大学 通信与信息工程学院,上海 200444)
0 引 言
企业实体关系抽取旨在从自然语言文本中抽取企业实体及企业实体间关系,以帮助企业获取企业自身或其他感兴趣企业的相关信息。网络文本,尤其是上市公司年报定期披露的上市公司生产经营的相关信息中包含丰富的企业产品生产、采购、销售、市场竞争、行业发展及政策法规等内容,但上市公司定期报告披露的企业关系信息是破碎的。为构建行业企业的关系图谱,有必要研究行业企业关系的抽取方法。企业实体关系的获取是一种典型的信息抽取问题,主要是研究在实体识别的基础上确定文本中实体对所蕴含的关系类型。
然而对于实体关系抽取,企业实体间关系的抽取有如下特殊性:缺乏大规模企业实体关系标注语料;存在企业实体间关系模式的表达与选取问题。由于仅以词法、句法特征抽取实体关系不能获取复杂句子的长距离深层持征,而最短依存路径模式抽取实体关系由于实现了对关系的浓缩表示缺乏语义约束以及相关特征表示容易造成关系实例误检。基于以上问题,文中重在解决如何在缺乏标注语料的前提下,实现企业间实体关系模式的建立及其关系的抽取。
1 相关工作
近年来的研究趋势表明,机器学习方法是目前关系抽取研究的主流方法,主要包括有监督、无监督和半监督三种类型。
有监督方法是通过构建一个监督分类器来实现关系抽取。其主要思想是通过对人工标记的训练样本训练出关系实例的分类模型,然后利用训练出的分类模型测试候选关系实例集合实现对实例关系的分类。在有监督的方法中,基于树核的方法不需要构造特征向量,解决了基于特征向量方法无法充分利用实体对上下文的结构信息的问题。文献[1]将改进的语义序列核函数和机器学习KNN分类算法相结合构造分类器,并对关系类型进行分类和标注;在ACE数据集上,关系抽取的平均准确率提高到88%。文献[2]首先构造一个丰富的语义关系树结构,将句法信息和语义信息相结合,并对上下文相关的树结构进行扩展。实验表明提出的基于树核的方法优于其他先进的方法。文献[3]在实例句的句法树中融入能反映特定领域实体语义关系的领域知识树,相比没有融入领域信息的方法实体关系抽取的性能提高了3.4%。文献[4]通过抽取深层句法特征构建演化关系模式并借助CRF模型识别概念间的演化关系,使演化关系的抽取较传统方法有更高的准确性。该模式具有一定的优越性和有效性,可以有效识别机器学习领域中概念间的演化关系。然而有监督方法训练和测试速度过于缓慢,不适合处理大规模数据。
无监督实体关系抽取方法实际上是一种聚类算法,将相似度高的实体对所在的关系句子实例聚为一类,然后选择评分高并且具有代表性的特征词来标记这种关系。无监督方法无需依赖疏通关系标注的语料,因此可以解决有监督方法中标注困难的问题。文献[5]提出了一种能同时触发关系触发词和关系参数的无监督的生成模型,并通过抽取的实体关系揭示了患者记录中存在的一些隐含的语义结构。文献[6]提出一种基于多层无监督神经网络的分类模型,有效解决了高维特征向量中特征提取以及分类的问题。实验表明在高维空间特征的信息抽取任务中,DBN模型具有较强的处理和分析能力,其效果比SVM和反向传播网络更好。文献[7]提出了一个多级聚类方法来分组语义等价关系,该方法不仅提高了可扩展性,而且通过利用每个初始簇中的冗余来提高聚类结果。无监督实体关系抽取方法在处理大规模实体关系抽取时虽然有一定的优势,但其聚类阈值难以提前确定,并且目前仍缺乏较客观的评价标准。
由于有监督的关系抽取方法需要大量的标注语料库,而无监督的机器学习其聚类阈值难以事先确定,并且目前仍缺乏较客观的评价标准。所以为了减少对语料集的人工标注,实现关系的自动抽取,半监督的关系抽取算法得到了发展和应用。2014年,文献[8]提出一种改进的上下文模式语义分析并结合基于bootstrapping的半监督算法抽取语义关系抽取,在一定程度上加强了语义关系抽取的效果。文献[9]提出一种基于词嵌入的bootstrapping关系抽取模型,并且依靠词嵌入实现了从一组新闻线文档中提取四种关系的任务,获得了较好的表现。文献[10]定义了一种语义约束的bootstrapping关系抽取模型,并提出了语义最短依存路径关系模式语义,使其包含了更丰富的句法特征和语义特征,具有更强的关系指向性,且最终具有较好的表达效果。
基于以上研究,文中建立bootstrapping关系抽取模型以减少对语料集的人工标注,扩充种子关系模式集合,实现关系模式的自动抽取;在关系抽取模型中提出基于触发词的特征向量(T_FVM)关系模式和基于触发词的主谓宾扩展(T_SVOE)关系模式,以解决企业关系抽取中对表格信息处理和对句子语义信息表示不足的问题。
2 基于特征向量与SVO扩展的企业关系抽取
企业关系抽取主要包含预处理、构建种子集、迭代和测试四个子模块。预处理模块是对企业年报原始文本进行正文抽取、企业专有名词识别以及触发词构建。构建种子集则从语料集中选取具有代表性的一部分关系实例进行标注。迭代过程是bootstrapping的核心和重点,首先对训练语料集进行依存句法分析、特征提取[11-13]等产生候选关系模式,然后对候选模板进行相似性分析与评价,将可靠的关系模式保留下来扩展种子集合,最后将扩展的种子集合作为下一次迭代的输入。将得到的关系模式集合对测试预料中的实例进行关系抽取。其核心流程如图1所示。
在候选关系模式模块中主要运用提出的基于特征向量与SVO扩展的关系模式,并在关系模式中引入触发词语义约束机制。
2.1 构建企业关系专有名词
企业关系专有名词是指能够触发一定关系类型的词,具有一定的语义指向性,也被称为关系指示词或触发词。关系指示词常在关系抽取中被用作实体关系发生的指向词;在关系抽取中,主要是指具有某种语义关系并能触发特定关系模式的词[14-15]。
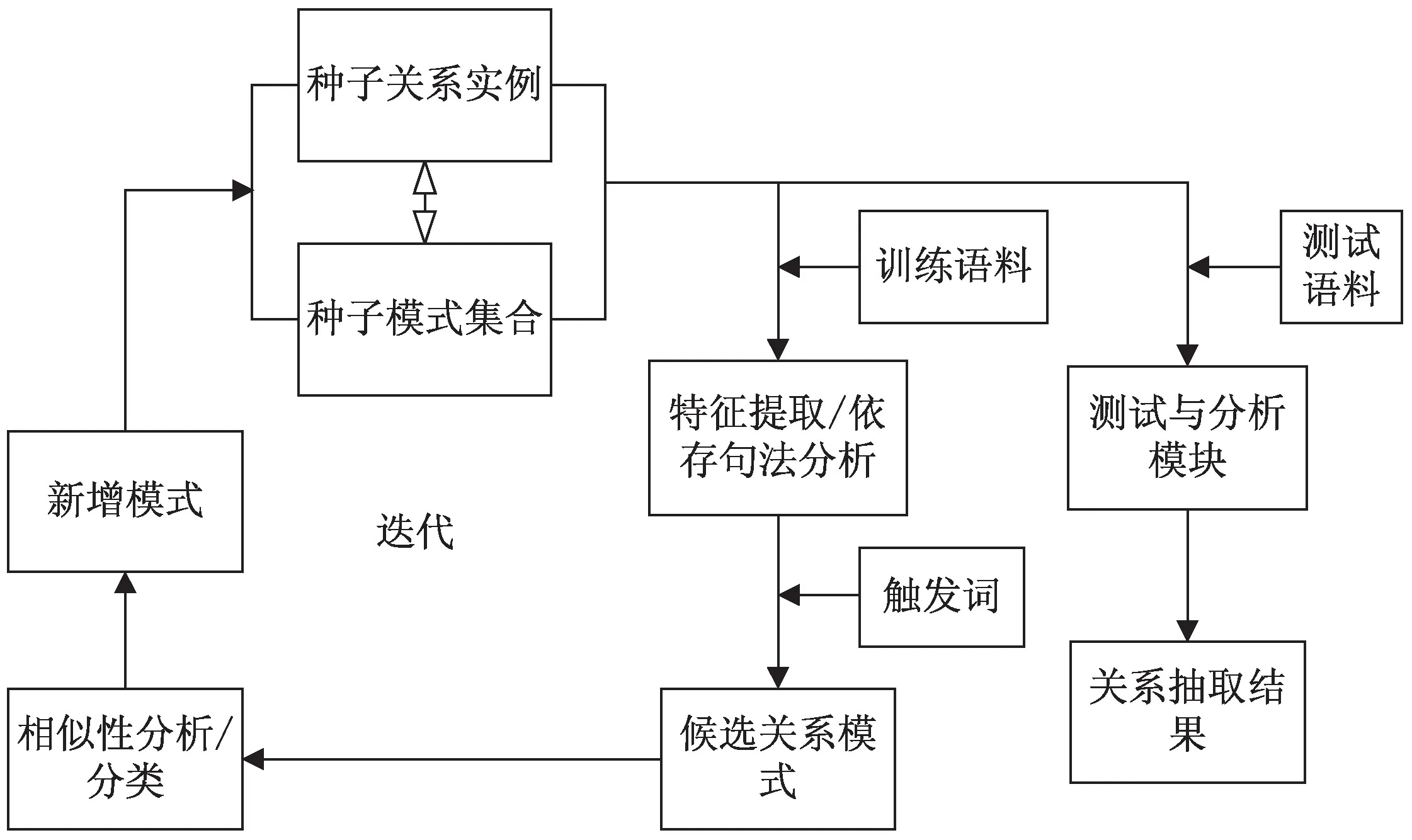
图1 企业实体关系抽取核心流程
通过对关系模式添加触发词特征以实现语义关系的约束和实体关系的准确表达。它作为关系模式的语义锚点,直接关系着关系模式的语义类型,对关系抽取起着重要的作用。文中利用统计方法和人工筛选、添加的方法实现触发词的获取和过滤。定义了5种实体关系:客户关系、供应商关系、研发关系、附属关系、位置关系;各关系的具体定义为:
定义1(客户关系):指企业为达到其经营目标,主动与客户建立起销售与购买的联系。
定义2(供应商关系):指企业为达到其经营目标,主动与供应商建立起购买与销售的联系。
定义3(研发关系):指企业为达到其经营目标,主动提高技术、产品和服务水平,将研究成果转化为可靠,具有成本效益的创新产品的活动。
定义4(附属关系):存在一定隶属关系或合作关系的两个或两个以上组织、机构或者企业。
定义5(位置关系):是指组织、机构以及公司等与地名或地址等存在的特定关系。
针对描述每一种企业关系的专有名词的具体定义情况如表1所示。

表1 企业关系专有名词定义
2.2 关系模式及其表述
关系模式的表达和抽取是实体关系抽取的核心问题,其目前主要是对关系的向量表示和结构化表示。由于关系选择性与关系模式息息相关,好的关系模式具有好的关系选择性,可以提高关系抽取的正确率,因此关系模式的表达和抽取成为实体关系抽取的关键。文中提出基于触发词的特征向量关系模式(FVM based on semantic constraint of trigger words,T_FVM)和触发词的主谓宾(SVO)扩展关系模式(SVO extension model based on semantic constraints of trigger words,T_SVOE)进行实体关系抽取。
2.2.1 基于触发词的特征向量关系模式
对于企业语料中的半结构化表格的处理,需要采取间接方法来获取相应的实体关系;这一部分主要是抽取年报公司实体和表格中企业、组织、机构以及产品实体间的关系而言,对于表格内部实体间的关系并不能有效表示。
表格中的企业实体由于缺乏信息及特征以至于实体间的关系难以表达和获取;但是在企业年报中凡是和年报公司实体含有一定实体关系的表格都会提前对相关表做一个关键性的相关信息描述,因此可以对这部分信息进行详细的分析和信息特征获取。由于这一部分依存句法特征较少,分析结果不理想,因此这一部分采用基于特征向量的关系模式(FVM)进行表示,并使用触发词进行语义约束,即提出基于触发词语义约束的特征向量关系模式(T_FVM)。
定义6:定义四元组
文中在传统浅层词汇特征的基础上,增添触发词特征和实体类型特征以获取实体对之间更丰富的关系特征,并使用KNN算法进行分类预测。选取的实体关系特征有:
(1)关键词汇特征序列。首先使用TextRank[16]算法获取关键词汇特征序列,TextRank算法是利用局部词汇之间的关系(共现窗口)对后续关键词进行排序,直接从文本本身抽取。公式定义如下:
其中,d为阻尼系数,取值范围为0到1,表示从图中某一特定点指向其他任意点的概率,一般取值为0.85。
(2)触发词特征。通过已构建的企业关系专有名词库获取句子中含有的触发词特征。
(3)实体类型特征。能够识别的实体种类有人名、地名、组织机构名等。
2.2.2 基于触发词的主谓宾扩展关系模式
对于纯文本信息,则将含有命名实体的句子作为关系抽取的元实例集,这一部分则采用T_SVOE模式进行模式表示以及关系抽取。对于SVO[17-18]模式,虽然可以利用主谓宾组合表示一定的深层语义信息,但对于长复杂句,由于信息表现过于简单,容易造成对句子关键信息表述的缺失。例如句子“嘉园环保为本公司全资子公司,注册资本6 000万元”,如果是基于SVO模式,则提取的基本句子关系模式为:“嘉园环保:company_name SBV 注册资本 * 元”;则具有语义表述的关键信息成分“控股子公司”出现缺失,结果导致本句子被归类为无关系。
因此文中提出SVO扩展模式;SVO扩展模式的重点在于对主谓宾各个成分含有的并列关系(COO)、定中关系(ATT)以及介宾关系(POB)的句子成分进行提取,并将其依存句法关系也加入结构模式中使之可以完善对句子语义信息的表达。由于关系模式抽取时可能会产生语义漂移问题,因此使用触发词进行语义约束即提出基于触发词的T_SVOE关系模式。
依存语法通过分析语言单元中各成分之间的依存关系,即指出句子中单词之间的句法搭配,分析句子的主谓词,宾语,形式,补语结构,揭示句子成分之间的语义修饰关系。直观地讲,依存句法分析句子中的这些语法成分与这些成分的位置无关,分析各成分之间的语义修饰关系,可以获得远距离的搭配信息。常用的依存句法分析标注关系如表2所示。

表2 依存分析标注关系
定义7:定义五元组
根据依存句法分析获取T_SVOE关系模式主要包括三步:
(1)依据依存句法分析结果,提取包含实体以及触发词在内的主谓宾核心结构,如算法1所示。
(2)提取与主谓宾有直接并列关系、定中关系以及介宾关系的依存关联节点,如算法2所示。
(3)加入依存关系特征并用实体类型替代实体部分,其他无关的成分用*代替即得到最终可以表示一定实体关系的关系模式。
算法1:提取包含实体以及触发词在内的主谓宾核心结构。
输入:实体e,实体所在句子的依存句法分析结果
输出:包含实体以及触发词在内的主谓宾核心结构
Foreach node sentenceNodes
IF(node→relate为SBV,node→relate为HED,node→relate为VOB或者node→name为e)
/*遍历依存句法中每个关系节点,提取主谓宾关系成分到节点关系集合中*/
Add node→relate to nodeSet
ENDIF
Foreach tw triggerWordsSet
/*遍历触发词集合,获取句子关系中含有触发词的关系成分*/
IF(node→name为tw)
Add node→relate to nodeSet
ENDIF
END
END
算法2:提取与主谓宾的直接依存关联节点。
输入:主语S、谓语R、宾语O成分以及实体所在句子的依存句法分析结果
输出:主语S、谓语R、宾语O的依存关联节点集合
p=S,R,O←parent;
Foreach p∈sentenceNodes
IF(p→relate为COO,p→relate为ATT或者p→relate为POB)
Add p tonodeSet
/*遍历依存句法中每个关系节点,如果与主语S、谓语R、宾语O的依存关系为COO、ATT或POB,则添加关系节点到节点集合中*/
ENDIF
END
则句子“嘉园环保为本公司全资子公司,注册资本6 000万元”通过基于T_SVOE的关系模式分析得到T_SVOE关系模式为“嘉园环保:company_name SBV为VOB全资子公司*,注册资本*”;通过和基于主谓宾(SVO)模式的结果对比分析,基于触发词和SVOE模式明显对句子有更完善的语义信息表达。
3 实 验
3.1 实验数据集及预处理
选取2015年1 000家上市公司年报作为语料,其中涉及电子、汽车、药业、食品、房地产五大行业各200篇左右,并定义5种实体关系:客户关系、供应商关系、研发关系、附属关系、位置关系。文中采取半监督的方法,首先构造一个小的种子集,然后从未标记的数据集中提取某些特征的数据,在评估之后,提取最可信的数据集来扩展训练集,然后迭代这个过程,因此不需要进行大量标注构建小规模的种子集合是关键。对每个行业年报选取20%用来建立种子集,其余80%中的60%作为训练语料,40%作为测试语料。
预处理是实体关系识别的基础也是关键工作。选取FudanNLP自然语言处理工具进行分词、停用词过滤,词性标注以及实体识别等基础工作,然后获取包含实体的句子,使用LTP-Cloud进行句子结构解析以及词之间的依存分析。
3.2 实验结果评价指标
准确率(Precision,PR)、召回率(Recall,RR)和F值(F-Measure,F)是信息抽取领域中的三项基本评价指标。准确率是指在某一特定关系类型的实例中被正确抽取的实例占所有抽取为此关系类型的比例,它是从查准率的角度评估抽取效果;召回率是指在某一特定关系类型的实例中被正确抽取的实例占实际属于本类型的实例的比例,它是从查全率的角度评估抽取效果;由于准确率和召回率都是单一方面的评估,实际两者是相互影响、相互牵制的,因此F值则是综合考虑准确率和召回率的影响。计算公式为:
(2)
RR=
(3)
(4)
3.3 实验结果与分析
基于触发词的语义模式企业关系抽取任务中,采用基于T_FVW和基于T_SVOE两种关系模式处理不同情况下的实体关系,同时引用的触发词约束在语义上约束关系模式,以确保新添加的关系模式和关系实例指向当前关系,这大大改善了抽取的准确率。表3显示了5种实体关系抽取的准确率、召回率和F值。
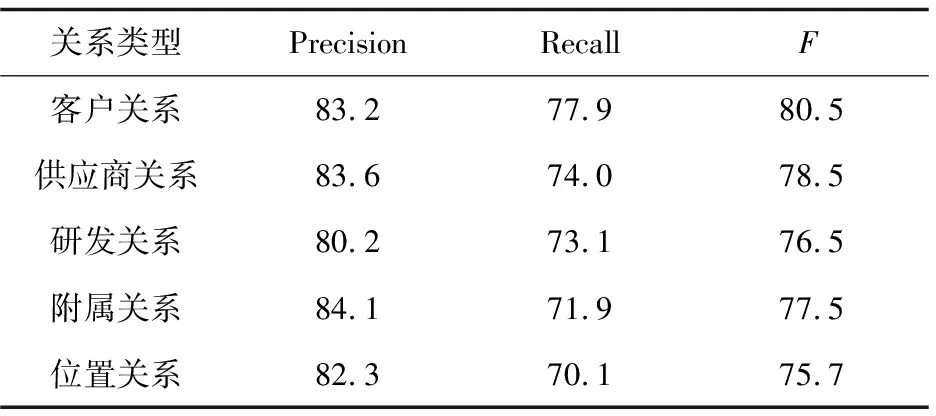
表3 各关系抽取性能 %
同时还实现引入其他三种关系抽取算法进行对比,使用未加触发词语义约束的FVW和SVO关系模式,该方法记为FVM&SVO;使用未加触发词语义约束的FVW和SVOE关系模式,该方法记为FVM&SVOE;同时,还实现未扩展T_SVO关系模式以方便和扩展T_SVOE关系模式进行对比,该方法记为T_FVW&T_SVO;记文中方法为T_FVW&T_SVOE;对比结果如表4所示。
表4 所有关系下的综合性能比较

%
通过比较可以观察到,基于SVO扩展的关系模式其准确率和召回率都有小幅度的提升,这说明基于SVO扩展模式相比单纯的基于SVO模式更适合用于关系的抽取;方法3的准确率明显高于方法2,这主要是因为引入触发词特征对相应的关系模式有一定的语义约束作用,但是召回率下降了0.3%,可能是由于关系模式泛化能力不足导致。
观察表3和表4,对于基于关系模式的半监督学习方法具有较高的或快速增长的准确率,相反召回率却增长缓慢甚至偶尔出现较低的现象,这些主要是由bootstrapping迭代所产生的,因为该过程是通过候选关系模式集来扩大实例集,然后再通过扩大的实例集反过来扩大关系模式集。如果不能保证抽取的关系模式有较高的准确率,则在迭代过程中必然会导致错误的积累和叠加;因此,基于关系模式的半监督学习方法往往具有较高的准确率。
4 结束语
文中提出了基于特征向量与SVO扩展的企业关系抽取模型,并在该模型中引入触发词约束机制。实验结果表明,该方法能够从大规模的企业文本中抽取出企业实体关系,有效解决了企业关系抽取中对表格信息处理和对句子语义信息表示不足的问题;同时使用bootstrapping算法通过种子模板抽取关系模式,不断迭代学习,最终达到需要的数据信息规模,解决了人工干预和语料标注的问题。
下一步将研究跨文档中隐式关系的抽取,以及基于Web的企业关系抽取,从而挖掘出更多的实体关系,自动建立全方位的企业生态关系图谱。
