多源信息融合的双人交互行为识别算法研究
2018-10-15金壮壮曹江涛姬晓飞
金壮壮,曹江涛,姬晓飞
(1.辽宁石油化工大学 信息与控制工程学院,辽宁 抚顺 113001;2.沈阳航空航天大学 自动化学院,辽宁 沈阳 110136)
1 概 述
在信息技术高速发展的今天,机器视觉越来越受到研究者的关注,其中双人交互行为识别算法研究已成为热点问题。相比单人行为模型,双人交互行为更为复杂,因此,如何有效地提取运动特征和合理地建立交互运动模型是双人交互行为识别与理解的重要研究内容。国内外科研工作者们已经展开了相关项目的研究[1-5]。对双人交互行为进行自动的识别不仅对计算机视觉、人工智能和模式识别的理论研究具有很高的价值,而且在解决公共场合暴力冲突和实现智能视频监控等方面具有现实意义。
在过去的十几年中,双人交互行为识别主要针对RGB视频序列进行。Kong等[6]提出一种基于补丁感知模型的双人交互行为识别方法,该方法从包含双人交互的视频中提取时空兴趣点,构造视觉词汇直方图,然后从直方图中采样非重叠的3D补丁,使用提出的补丁感知模型来推断潜在补丁变量的标签并对交互动作进行分类识别。Zhang等[7]使用鸟瞰图摄像机的空间线索来识别发生交互的时间间隔,然后从分段视频中检测时空兴趣点,利用K-means构建视觉码本。在视觉码本上投影每个视频,构造视觉词汇直方图来实现交互识别。这些算法具有较好的性能,但RGB视频将人体及人体运动投影到二维平面,导致深度信息的缺失,因此对于复杂交互动作识别的准确性很难得到保证。
近年来,微软推出一种可以同时拍摄视觉图像(RGB图像)与深度图像的Kinect设备,大大降低了深度信息的获取成本,在智能监控、人机交互等领域受到了重视,一些研究者将其引入到双人交互行为识别的研究中。Yun等[8]采用文献[9]中的几何特征提取方法并设计多种相关的距离特征(如关节距离、关节运动、平面特征和速度特征)来进行双人交互识别,发现关节距离特征和关节运动特征在双人交互行为识别上优于平面特征和速度特征。该类方法依赖于Kinect设备对关节点信息的准确估计,对于复杂行为识别的准确率不高。Ji等[10]通过提取关节点运动与关节点距离特征来进行交互身体部位描述,然后构建对比特征分布模型(contrastive feature distribution model,CFDM)实现双人交互行为识别。该方法依赖骨架模型的构建及关节点信息之间的准确联系,尽管识别准确率较高,但其计算复杂度也较高,不适于实时应用。
目前基于RGB视频和深度视频的双人交互行为识别研究均取得了一定的进展,但结合两者进行的研究还处于起步阶段。Ni等[11]对传统时空兴趣点检测算法做了相应改进,提出了一种基于深度信息分层的时空兴趣点特征描述算法。其算法主要思想是把深度图像按灰度级分成M层通道,将RGB视频构建的K维视觉词典与每一层通道进行匹配,生成M×K维特征矢量。该算法在一定程度上提高了识别的准确性,但当K值较大时才能得到较好的效果,且特征矢量维数增加会降低动作识别效率。
根据以上分析,综合考虑到基于RGB图像与深度图像各自的优点且具有信息互补的特性,文中提出一种多源信息融合的双人交互行为识别算法。算法框图如图1所示。

图1 算法结构框图
算法实现步骤如下:
(1)RGB视频的特征表示:时空兴趣点特征(spatio-temporal interest point,STIP)在RGB视频上已成功应用,因此在RGB视频方面首先进行时空兴趣点检测,用三维尺度不变特征转换(3-dimensional scale invariant feature transform,3DSIFT)对兴趣点进行描述,采用BOW模型对RGB视频进行直方图表示。
(2)深度视频的特征表示:在深度视频方面,首先进行深度图像检测分割处理。考虑到一般情况下前景和背景之间在深度方向存在一定的距离,因此在深度图像中,前景的边缘信息明显,选取方向梯度直方图(histogram of oriented gradient,HOG)特征对每个视频帧中的检测区域进行特征表示,然后采用关键帧统计特征对整个深度视频进行表示。
(3)决策级融合识别:使用最近邻分类器计算待测试视频与动作模板的相似性概率,之后对RGB图像上提取时空兴趣点特征的识别结果与深度图像上提取HOG特征的识别结果进行加权融合,得到待测视频的最终识别结果。
2 RGB视频特征表示
在人类交互行为视频里,时空兴趣点能够用较少的信息量正确地定位视频序列中具有明显运动的区域,对环境的变化、局部的遮挡具有较强的鲁棒性[12-13]。基于时空兴趣点表征行为的算法被广泛应用于人类行为识别领域,因此文中使用时空兴趣点与视觉词袋(bag of word,BOW)模型结合的方法对RGB视频进行特征表示。
如图2所示,使用时空兴趣点和词袋模型相结合的双人交互行为表征算法由时空兴趣点检测、特征描述、词典建立三个部分组成。
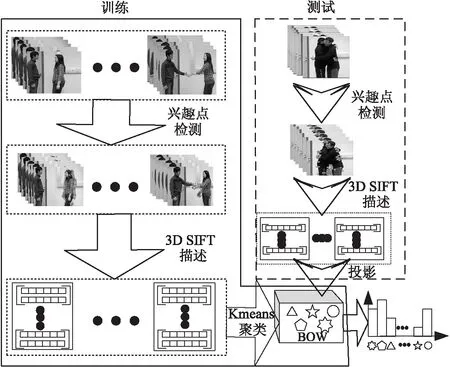
图2 生成BOW描述符的图形表示
2.1 时空兴趣点检测
广泛使用的兴趣点检测方法是由Dollars等[14]提出的基于Gabor滤波器和高斯滤波器组合计算函数响应值的方法。将空间和时间两个单独的线性滤波器应用在检测器上,从视频序列中提取出丰富的时空兴趣点,用来充分捕捉视频序列中的人体行为特征。这里把它应用在彩色视频双人交互局部特征提取上,其表达式为:
R=(I*g(σ)*hev)2+(I*g(σ)*hod)2
(1)
其中,g(x,y;σ)是二维高斯平滑核函数,用于空间域滤波。
(2)
其中,hev和hod是一维Gabor函数的正交分量,用于时间域滤波。
hev(t;τ,ω)=-cos(2πωt)e-t2/τ2
(3)
hod(t;τ,ω)=-sin(2πωt)e-t2/τ2
(4)
其中,σ和τ分别对应空间和时间尺度。
被检测为兴趣点需满足两个条件,响应函数R大于设定阈值且在某一邻域内取得局部极大值,阈值大小的选取可以控制检测出的兴趣点数目[15]。
2.2 3D SIFT描述时空兴趣点
采用3D SIFT方法进行兴趣点描述,步骤如下:
(1)在兴趣点周围的邻域内提取时空立方体并将其划分为固定大小的单位子立方体;
(2)使用多面球计算每个单位立方体的时空梯度直方图;
(3)组合所有单位立方体直方图,形成时空兴趣点的3D SIFT描述符[16]。
文中X×Y×Z像素大小的立方体被划分为M个子立方。采用P个面对Q个梯度方向进行描述,因此每个点的特征维数是R×S,用以描述交互行为的时空兴趣点特征[17]。
2.3 词典构建
使用简单有效的K均值聚类算法对所有特征向量进行聚类,其处理过程是:先在数据集中随机选择K个样本作为聚类中心,根据一定的相似性度量把所有样本划分到与之距离最近的聚类中心所代表的类中,形成K个聚类,然后对这K个聚类重新计算聚类中心,并按照新的聚类中心重新划分样本类别,如此迭代进行下去,直到式5准则函数收敛为止。
(5)
其中,E为所有研究对象的平方误差总和;p为空间的点,即数据对象;mi为簇Ci的平均值。
把每个聚类中心作为词典中的一个单词,每个特征向量用与之距离最近的单词表示,然后对词典中的单词在视频中出现的频率进行统计,构建视频的直方图表示。
3 深度视频特征表示
深度图像也称为距离影像,是指将图像采集器到场景中各点的距离(深度)作为像素值的图像[18]。当人体前景与背景存在一定的距离时,深度图像可以通过灰度值信息直观地体现。考虑到HOG可以较好地对人体周围的边缘信息进行提取和表示,因此选用HOG特征进行深度视频全局表示。文中采用帧差法[19]检测深度图像中的运动目标。
HOG特征[20]的构建通过计算和统计图像局部区域的梯度方向直方图来实现。针对梯度进行提取操作,不但可以捕获轮廓和纹理信息,还可以减小光照变化的影响。像素点(x,y)横坐标和纵坐标方向的梯度可表示为:
(6)
其中,Gx(x,y)、Gy(x,y)、H(x,y)分别表示输入图像中像素点(x,y)处的水平方向梯度、垂直方向梯度和像素值。
像素点(x,y)处的梯度幅值和梯度方向分别表示为:
(7)
将运动目标所在区域进行HOG特征提取。即梯度图像均等划分为P×Q个不重叠子区域,并计算每个区域中像素点的梯度对K个不同方向的贡献权重大小,将其叠加到所有的梯度方向上,构建梯度方向直方图,如图3所示。最终得到每帧图像中运动目标的P×Q×K维特征向量。
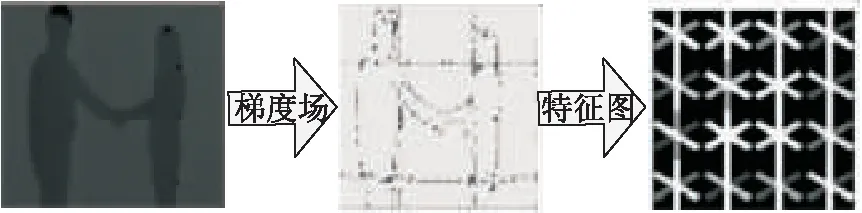
图3 HOG特征图形表示
为了与兴趣点特征进行有效融合,使用关键帧统计特征对深度视频进行表示。即采用K-means聚类方法,对训练视频的HOG特征生成关键帧特征库。然后根据相似度量函数对一个待测视频中的所有帧特征在关键帧特征库中出现的频率进行统计,得到深度视频的统计直方图表示[21]。
4 分类器设计
最近邻分类器是一种结构简单、识别效果良好的识别方法[22]。文中采用最近邻分类器对两种视频特征进行识别,并融合两种特征的识别概率对交互动作进行最终识别,具体方法如下:
获得RGB视频与深度视频的识别概率后,通过加权融合的方式可以得到融合后的识别概率及结果:
PFinal=w1×Prgb+w2×Pdepth
(8)
其中,PFinal为加权融合后的最终识别概率;Prgb和Pdepth分别为RGB视频和深度视频的识别概率;w1、w2
为RGB视频和深度视频识别概率的加权参数。
5 实验与结果分析
5.1 数据库
实验采用公开的SBU Kinect interaction[8]双人交互动作视频数据库。该数据库是运用微软Kinect传感器创建的一个拥有深度图像、彩色图像和骨架图像的双人交互动作数据库。数据库记录了八类双人交互动作(approaching,departing,kicking,punching,pushing,hugging,shaking hands,exchanging),共有七人在同一实验室环境中参与行为动作拍摄,每一类动作都由不同的动作执行人完成,整个数据库有260组交互动作。库内的行为不仅是非周期性行为,而且不乏有非常相似的身体动作,因此对库中的行为进行识别具有一定的挑战性。
5.2 不同特征识别结果
在实验过程中,每类动作随机选取10个视频作为测试数据,余下的视频作为训练数据。参数选取如下:兴趣点附近12×12×12像素大小的立方体被划分为2个子立方,采用32个面对32个梯度方向进行描述,即每个点的特征是256维用以描述文中交互行为的时空兴趣点特征。在深度图像上,将梯度图像均等划分为不重叠子区域,每一幅运动区域做4×4的分割,方向个数为12。在进行决策级融合之前,使用最近邻算法计算测试视频动作模板的相似性概率,为确定决策级融合时加权数值的分配提供参考识别结果。

表1 不同特征的识别结果
由表1可以看出,RGB视频上采用的BOW特征表示相对于深度视频的HOG特征表示“推搡”和“远离”交互动作识别效果较差,而“握手”识别效果较好。对于双人交互动作识别,深度图像携带更多动作信息,因此基于深度图像的识别率较RGB视频有了大幅提高。上述结果表明,文中将BOW特征和HOG特征识别结果进行决策级融合是有意义的。
5.3 决策级融合识别结果
针对BOW和HOG各自的特征优势和特点,分别将它们的最近邻识别结果进行决策级融合,根据上面得到的结果,运用遍历的方法得到最优权值分别为0.45和0.55,深度视频的融合系数较高一些。最终的识别结果采用归一化后的混淆矩阵表示,如图4所示。

图4 决策级融合后的混淆矩阵
从混淆矩阵可以看出,决策级融合后的正确识别率为92.5%,远远优于单一特征的识别结果。对比单一识别结果,“靠近”、“远离”和“握手”识别效率得到明显提高。由于数据库有些动作存在相似性,导致融合后有20%的“打拳”动作视频被识别成“推搡”交互动作。
5.4 实验比较
为了验证文中算法的有效性,对同样在SBU Kinect interaction数据库上进行实验的相关文献使用的算法与文中算法进行比较和分析,如表2所示。
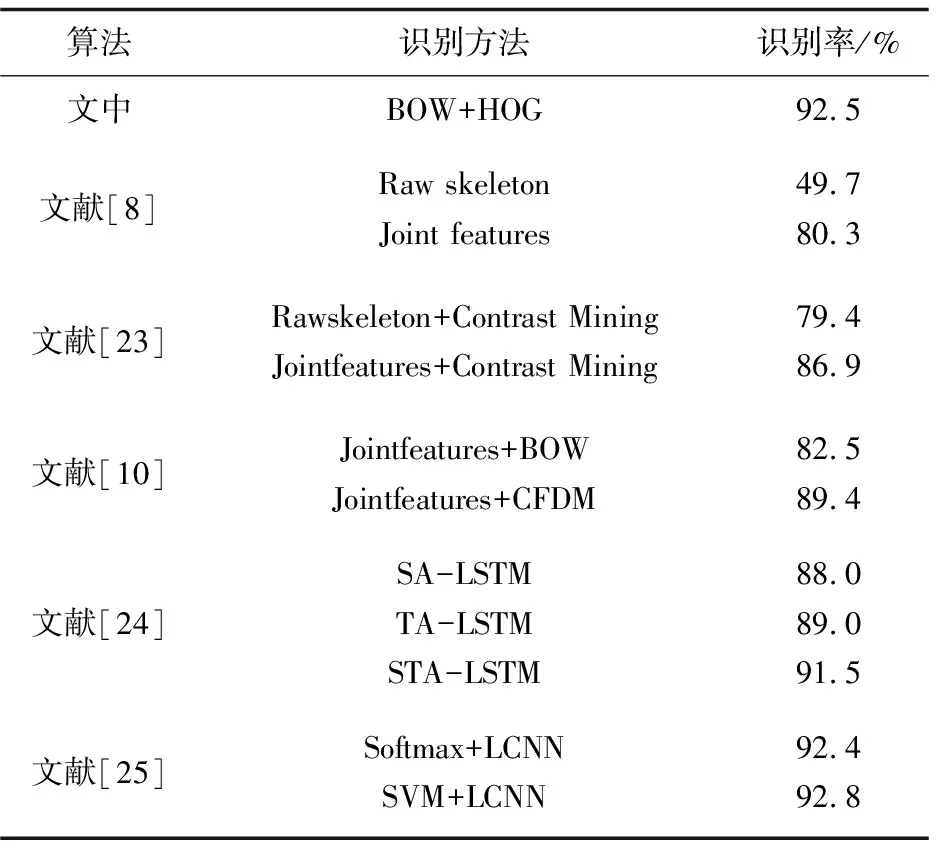
表2 不同方法的识别结果
由表2可以看出,文献[8,10,23-25]选取了骨架结构模型进行双人交互动作识别。从识别率上看,文中多源信息融合方法得到了较高的正确识别率,并且文献[24]中的算法需要获取人体骨架节点信息之间的关联,而且LSTM存在训练复杂度高、解码时延高的问题。文献[25]的LCNN算法存在训练需分多个阶段,步骤繁琐,速度慢,对硬件要求高的问题。而文中算法直接在RGB和深度图像上提取特征,简单易实现。
6 结束语
根据RGB图像与深度图像特性,提出一种RGB视频与深度视频特征在决策级加权融合的交互动作识别算法。该算法充分利用了两种视频信息各自的优点及信息互补的特性,并采取了适用于两种视频的特征表示方法。在SBU Kinect interaction数据库的测试结果表明,该算法对于复杂的双人交互行为取得了良好的识别结果,并且实现简单,不依赖于Kinect设备对骨架模型的估计,为双人交互行为识别提供了一种新的解决方案。为了进一步提高算法的准确性,下一步的研究重点是更好地构建联合特征模型,研究两种视频信息的特征级融合。
