基于位置的社会化网络推荐技术研究进展
2018-10-15肖迎元郑文广
焦 旭 肖迎元 郑文广 朱 珂
1(天津市智能计算及软件新技术重点实验室(天津理工大学) 天津 300384)2(计算机视觉与系统省部共建教育部重点实验室(天津理工大学) 天津 300384)3(天津外国语大学基础课教学部 天津 300204)
随着移动互联网技术、定位技术和无线传感技术的飞速发展以及智能手机的不断普及,基于位置的社会化网络(location-based social networks, LBSNs)及其带来的应用服务应运而生,并得到了迅速的发展.目前比较流行的LBSNs有Foursquare,Gowalla,Facebook Place,Microsoft GeoLife,Bikely,Flickr,Panotamio、微信朋友圈等.其中,以Foursq-uare,Gowalla,Facebook Place为代表的LBSNs主要提供对兴趣点的签到(check-in)服务,鼓励用户分享其当前位置,通过对用户共享位置信息的分析为用户推荐感兴趣的位置和社交活动;而以Microsoft GeoLife,Bikely为代表的LBSNs则主要记录和分享用户出行轨迹,提供和用户轨迹相关的一些信息,诸如轨迹的总时长、在一个位置的驻留时长、速度、海拔和一些相应的距离等,同时还可以展示用户在轨迹旅程中的留言、标签、照片等以此来反映用户的旅行经验和经历以供其他用户参考;以Flickr,Panotamio、微信朋友圈为代表的LBSNs主要是把位置信息作为一个标签嵌入到照片、视频、文本等媒体信息当中,在此类LBSNs中位置信息只作为一个新的维度被嵌入到媒体信息当中,服务的主体仍然是媒体信息.
LBSNs中蕴含着大量而丰富的信息,在一个LBSN中,用户所关注的可能是某些地点、某些人或某些活动.针对用户的兴趣所在,为用户提供基于位置的个性化推荐服务(基于位置的社会化网络推荐服务),已成为当前LBSNs的一项重要服务,得到工业界和学术界的广泛重视,正成为推荐系统和社会化网络研究领域的一个新的研究热点.
1 基于位置的社会化网络概述
LBSNs不仅意味着在现有社会化网络中添加位置信息以使用户在社交结构中分享嵌入的位置信息,而且包括由他们在现实世界中的物理位置以及他们位置标签媒体的内容(例如照片、视频和文本)产生的相依性连接的用户所组成的新的社交结构[1],这里的物理位置由用户在给定时间戳的瞬时位置以及用户在特定时间段中累积的位置历史所组成.此外,这种相依性不仅包括2个人同时出现在相同的物理位置或分享了相似的位置历史,而且还包括了从用户的位置(历史)和位置标签数据推断出的诸如共同兴趣、行为和活动的知识.
通过对LBSNs的深入理解可以发现该网络是一个异构网络,其中存在着位置与用户2种不同属性的节点.根据这2种不同属性的节点,基于位置的社会化网络存在着3种关系:位置与位置的关系、用户与用户的关系、位置与用户的关系.同时对应于这3种关系还存在着3种不同的距离:位置与位置间的距离、用户与用户间的距离(指用户当前位置间的距离)、用户与位置间的距离(指用户的当前位置与某一位置间的距离).在LBSNs中位置与位置间的距离直接反映着2个位置间的相关程度,例如多家大学就近而形成大学城、多家企业就近而形成工业园、多家商场比邻而形成商业中心;用户与用户间的距离则可以反映出2个用户之间的相似性,例如2个用户各自的出行轨迹中的多个兴趣点都比较接近即轨迹的相似性较高就说明这2个用户具有相似的兴趣偏好或出行模式;用户与位置间的距离直接影响到用户对该位置的访问概率,例如一个用户去超市购物一般都会选择距离其较近的一个,文献[2]基于Foursquare的签到数据做出了关于用户活动模式的实证研究,研究表明用户的签到行为有20%是发生在1 km范围内的,60%是发生在1~10 km范围内的,20%是发生在10~100 km范围内的,5%是发生在100 km以外的,符合幂律分布,即较近的位置拥有较高的访问概率,这也与Tobler地理学第一定律(任何事物都是相关的,只是相近的事物关联更紧密)认为人类行为与所在地区有绝对的影响,此种影响随着距离的增大而递减是完全一致的.由此我们也可以看到在LBSNs中位置与用户相互依存紧密联系,在研究位置的同时无法割裂用户对其的访问行为,而在研究用户的同时也无法忽视其在不同时间所处的地理位置.
位置还具有其自身的独特属性,首先,位置是具有粒度属性的.例如对一家购物超市来说,它位于某个商业中心,这个商业中心属于某个区,这个区又属于某个城市,这个城市又属于某个省份,也就是说描述该购物超市的位置可采用不同的粒度:某商业中心→某区→某城市→某省.我们在不同的粒度上谈及用户分享的位置隐含的效果是不同的,例如一个用户去了天安门,另一个用户去了故宫博物院,在这个细粒度下我们可以推断2人都到过北京的历史古迹,2人都偏好旅游且都喜欢游览历史古迹,2人具有极高的相似性,而如果换作是省份这一级的粗粒度,我们仅能知道2人都到过北京,其推断出的2人的相似性就大打折扣了.其次位置还具有顺序性,例如一条东西向的街道上自东向西依次有A,B,C这3个兴趣点,自驾用户们的访问顺序都是由A到B再到C,说明这条街道极有可能是一条单行路.
2 基于位置的社会化网络推荐所面临的挑战
推荐系统作为有效解决“信息过载”的重要工具早已为用户所熟悉,尤其是在电子商务方面,推荐系统的使用既为企业带来了经济效益也大大方便了用户,例如商品推荐领域的淘宝、Amazon,电影推荐领域的豆瓣、Netflix,音乐推荐领域的Last.fm,新闻推荐更是在各大门户网站广泛使用.相较于基于互联网的传统推荐而言,由于LBSNs中用户与位置关系的相依性以及位置的独特属性,使得LBSNs的推荐变得更加复杂,存在诸多不同于传统推荐的困难与挑战,具体表现如下:
1) 在传统推荐中,通常根据用户的历史行为建模其偏好从而为他推荐物品,比如一个用户曾经购买过食谱方面的书籍,通常表明他可能偏爱美食做饭,自然就应该向其推荐烹饪类的最新书籍,但是在LBSNs中却不一定如此,比如一个广东的用户偏好健身,但当他出现在天安门广场时,我们给他的推荐列表中排在前列的应该是人民大会堂、英雄纪念碑、天安门、故宫博物院等,而不会是某个健身房或体育馆,因为他所处的位置信息(情境)告诉我们该用户到了北京的天安门广场应该是来旅游的.
2) 在LBSNs中需要根据推荐对象的不同选择不同的位置粒度,比如要做兴趣点推荐,就需要选择较细的粒度,细到餐馆、影院这个级别,而如果做新闻推荐,位置粒度的选择可以适当粗一点.
3) 在推荐兴趣点时还要考虑顺序性,比如在给用户做旅程规划时应根据具体的起点和终点位置顺序推荐它们之间的兴趣点,避免让用户来回奔波;此外,如果推荐的多个兴趣点在同一单行路上时更应避免给自驾用户带来困扰.
4) 在传统推荐中,用户显式地表达自己对物品的偏好,例如目前采用较多的是5分制评分,评分由1~5分表达了用户对物品从很不感兴趣到很偏爱的程度,换言之一个用户对物品的评价都集中1~5分这个范围内,然后可以把用户对物品的评分情况转换为一个用户物品矩阵.但是在LBSNs中则不然,用户对地点的偏好是隐式地通过访问频率表达的,用户对某一地点访问的次数越多说明其偏爱此地的程度越高;其次相较于用户对物品的评分,用户的访问频率没有固定的数值范围,比如有的用户对某一位置的访问频率可能多达几百次,而其他用户仅有一两次;此外,将用户对兴趣点的访问频次转换为一个用户-兴趣点签到矩阵后可以发现与传统推荐中的用户-物品矩阵相比是极度稀疏的,因为对于一个用户来说面对现实世界成千上万的兴趣点其去过的毕竟是少数,例如根据Foursquare用户的Twitter报告,文献[3]最终确定了一个包含12 422个用户、46 194个兴趣点与738 445个签到行为的数据集,其对应的用户-兴趣点签到矩阵的稀疏程度达到了99.87%,可以说是极度稀疏了,平均每个用户签到59.44个兴趣点,仅是兴趣点总数极小的一部分,同时对兴趣点的签到频率数值范围为1~786.
5) 用户的社会属性对用户签到行为的影响:传统推荐根据用户的最近邻来对其进行推荐,最具代表性的方法就是基于用户的协同过滤算法,并且取得了不错的效果.然而文献[4]的研究表明,在LBSNs中大约96%的朋友分享少于10%的常访问地点,并且87.7%的用户什么都不分享.由于大多数的朋友不分享常访问地点,这就意味着不是所有的社交朋友都有助于进行位置推荐,这也就说明了用户的社会属性对用户签到行为的影响是有限的.同时作者还发现,距离较近的朋友有较高的分享常访问位置的概率,这是因为他们更容易参与到相同位置的活动当中.这也印证了LBSNs中的用户的社交活动(访问兴趣点)很大程度上受地理接近度的影响.
6) 与传统推荐相比,在LBSNs中用户本身的属性及其所处的情境都会对推荐结果产生重要的影响.比如用户的年龄、性别、收入、职业、当前的位置、心情、当前时间、天气、交通情况等,因为用户的偏好会随着情境的改变而改变.同时用户的偏好也是有粒度的,比如:一个用户偏好旅游→偏好城市旅游→偏好参观各大城市的博物馆.因此,在LBSNs中如何融合各方面的情境来提高推荐的质量是一个挑战.
3 基于位置的社会化网络推荐核心技术
本节分别从推荐对象、推荐方法和评价方法3方面全面地介绍基于位置的社会化网络推荐相关技术.
3.1 推荐对象
在LBSNs中包含各种不同的推荐对象,本文将推荐对象划分为4类:位置(兴趣点)、朋友、本地专家、活动,其中位置和朋友的推荐又根据使用数据集类型的不同进行分类介绍.
3.1.1 位置推荐
位置推荐又可分为兴趣点推荐和旅程规划(兴趣点轨迹推荐),目前的位置推荐主要使用用户在LBSNs中的签到(check-in)数据集或用户GPS轨迹数据集.check-in数据集包含了带有语义信息的兴趣点以及丰富的用户属性与兴趣点属性,同时还包含用户间的好友关系,因此成为许多研究人员的首选,但是用户签到行为的极度稀疏也是check-in数据集无法回避的问题.相较于check-in数据的极度稀疏,GPS轨迹数据集则不存在这个问题,其包含了用户轨迹的总时长、用户在一个位置的驻留时长、速度、海拔和一些相应的距离等地理信息,但要使用GPS轨迹数据集的首要工作就是需要研究人员从轨迹数据中挖掘出兴趣点的地理信息;此外,如何匹配这些挖掘出来的兴趣点的语义信息,也是一项充满挑战的任务.以下将按照使用数据集的不同详细介绍.
1) 使用check-in数据集的位置推荐
用户的签到(check-in)行为往往会受到地理、时间、顺序、社会、评论等多方面因素的影响,本文将从这5个角度分别介绍.
① 地理影响
地理影响对兴趣点推荐是极其重要的,可以说这是其区别于传统推荐最根本的特征,由于用户的签到行为呈现出空间聚类现象,可以用幂律分布、高斯分布、泊松分布、核密度估计的方法来建模地理影响.文献[5]使用幂律分布来模拟被同一用户访问的2个兴趣点的签到概率y:
y=axb,
(1)
其中,x表示2个兴趣点之间的距离,a和b为幂律分布的参数,可以利用观测到的签到数据使用线性拟合的方法获得.文献[6]发现在LBSNs中用户的签到数据具有2个独特属性:1)用户趋向于围绕着几个中心进行签到,在每一个中心用户的签到行为是符合高斯分布的,如图1所示;2)尽管不同的用户对兴趣点有着不尽相同的口味,但是一个用户访问一个位置的概率与其距最近中心的距离成反比,如图2所示.这就暗示着如果一个兴趣点距离用户所在的位置较远,尽管用户喜欢该处,但是也很有可能不会去.基于以上2个特点,文献[6]使用高斯分布来建模用户的签到行为并且提出了多中心高斯模型(MGM).当给定了多中心集合Cu(1≤u≤M),用户u访问兴趣点l(一个位置的经度和纬度)的概率:
(2)
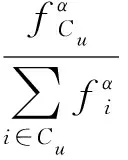

Fig. 1 A typical user’s multi-center check-in behavior[6]图1 典型用户多中心签到行为[6]

Fig. 2 Check-ins probability vs. distance[6]图2 距离相关的签到概率[6]
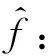
(3)
其中,li=(lati,loni)T是一个经度和纬度组成的2维列向量,K(·)是一个核函数,用式(4)表示,σ是一个平滑参数称为带宽,式(5)给出了其计算方法:
(4)
(5)
给定Lu={l1,l2,…,ln},用户u访问新位置l的概率表示为
p(l|Lu)=
(6)
实验表明CoRe方法的准确性和效率均优于幂律分布、多中心高斯分布和iGSLR.文献[9]对固定带宽的核密度估计进行改进,采用决策的方法自适应当地带宽也取得了不错的效果.
文献[10]认为高斯分布更适合于建模用户的评分行为而不是用户的签到行为,而泊松分布拟合签到频率数据好于高斯分布,提出了基于Ranking的泊松矩阵分解兴趣点推荐算法.首先,为了更加准确地捕获用户对兴趣点的偏好,使用泊松分布来建模用户的签到行为;其次,为解决兴趣点推荐中的隐式反馈问题,利用BPR(Bayesian personalized ranking)标准来优化泊松矩阵分解的损失函数;最后,为了进一步改进推荐算法的性能,利用包含地域影响力的正则化因子约束泊松矩阵分解过程.
② 时间影响
在传统的推荐中,时间影响力是逐步衰减的,比如新闻或者电影都会随着时间的推移其热度大大衰减.在LBSNs中,可以为某一具体的时间状态进行兴趣点推荐,时间影响对于兴趣点推荐的重要作用主要表现在用户签到行为的时间周期性和时间非均匀性2个方面.
用户签到行为具有时间周期性是指用户通常在相同的时间区间内会去访问相同或者相似的兴趣点.例如人们通常白天去图书馆,傍晚去餐馆,夜晚去酒吧,工作日通常在办公地点周围活动,周末通常会去购物中心或者公园.用户签到行为具有时间的非均匀性通常是指用户的签到偏好在1 d中的不同时间、1周中的不同日子、1年中的不同月份是存在差异的.文献[11-17]分别利用时间影响进行了兴趣点推荐,大部分方法都是将1 d分割成多个时间区间,比如分成24 h,或分成上午、中午、下午、傍晚、晚间、深夜等,进而使用协同过滤等一些推荐技术推断用户在每个时间区间的兴趣点偏好.但是由于这些时间区间是离散化的,就会造成丢失一些时间信息,同时缺乏不同时间区间之间的时间影响相关性.为了克服离散化的缺陷,文献[14]提出了一个概率框架来建模连续的时间影响,在向用户推荐兴趣点的同时也向用户建议合适的访问时间,该框架需要预测用户u访问兴趣点l∈L在时间区间T的概率p(l|u,T,D),其中,D为包含所有用户访问所有位置的签到集合,p(l|u,T,D)的计算公式为

(7)
其中,p(l|u,D)是不依赖于时间区间T的用户u访问兴趣点l的先验概率,可以通过任何非时间感知的方法获得;f(t|u,l,D)是以用户u和兴趣点l为条件的时间概率密度,这也从本质上利用了时间影响,对其进行基于核密度的估计:
(8)
tΘti为这2个时刻的时间差,Su,l为估计f(t|u,l,D)的时间样本,Wu,l(ti)为样本点ti的权重.
③ 顺序影响
文献[18]的研究发现:大量的连续签到是高度相关的,超过40%和60%的连续签到行为分别发生在Foursquare和Gowalla中距离上一次签到后的4 h以内.在Foursquare和Gowalla中大约90%的连续签到发生在32 km范围内(0.5 h的车程).这也反映出用户签到行为的顺序影响是时空相关的,它是时间周期性(人们通常白天去图书馆、傍晚去餐馆、夜晚去酒吧)、兴趣点在地理空间上的接近性(游客通常会先后游览人民大会堂、英雄纪念碑、天安门、故宫博物院)、兴趣点的属性与人类习惯(人们通常会先去健身房再去餐馆晚餐,如若相反是不利于人们的健康习惯的)共同作用的结果.为了利用这种顺序影响进行兴趣点推荐,目前的许多方法都是假设下一个可能访问的兴趣点只与访问过的最新的这个兴趣点相关,因而可采用了一阶Markov链进行建模[19-21].然而在实际当中,用户下一个将要访问的兴趣点往往和其之前访问过的所有兴趣点都相关,为此文献[22-23]提出:首先,从所有用户的签到位置序列中挖掘顺序模式作为一个动态的位置—位置迁移图,位置—位置迁移图不仅包括位置间的迁移计数,而且还包括位置到其他位置的外出计数,迁移概率通过迁移计数除以外出计数获得;其次,在给定位置—位置迁移图和用户访问过的位置序列的前提下,使用n阶加法Markov链(additive Markov chain, AMC)预测该用户访问新位置的顺序概率.
④ 社会影响
在传统推荐中就已经使用基于记忆[24-25]和基于模型[26-27]的方法来利用社会影响提高推荐系统的效果.在LBSNs中,基于朋友与非朋友相比会分享更多的共同兴趣这一假设,可以借鉴传统推荐的方法利用社会影响来提高兴趣点推荐效果[4,6,22,28-32].文献[4]使用了基于朋友的协同过滤(friend-based collaborative filtering, FCF)的方法进行兴趣点推荐.由于用户仅仅访问所有兴趣点中的一小部分,协同过滤方法会被用户—兴趣点签到矩阵的稀疏问题所困扰.为此文献[32]利用用户和已访问某一兴趣点的该用户的朋友的社会相关性来推断该用户和未被访问兴趣点之间的相关性,整个方法包含3个步骤:社交频率的聚集、社交频率的分布估计、社交相关性得分的计算.
步骤1. 社交频率的聚集.
给定用户u和未访问过的兴趣点l,聚合用户u的朋友(即u′,Su,u′=1)在兴趣点l的签到频率或评分
(9)
其中,Ru′,l是用户u′访问兴趣点l的频率或评分,Su,u′表示用户u和u′之间是否存在社交链接.
在现实世界中,社交签到频率随机变量x符合幂律分布,概率密度函数被定义为
fSO(x)=(β-1)(1+x)-β,x≥0,β>1,
(10)
其中,β通过签到矩阵R和社交链接矩阵S估计得到
(11)
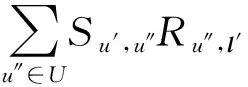
步骤3. 社交相关性得分的计算.
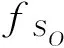
1-(1+xu,l)1-β,
(12)
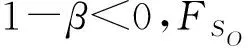

好,我没能力不能代表大多数,我们假设一种极端情况,正好泳池里有100个打着游泳的幌子,专门去撸管的色狼。鉴于他们的伟大能力,我们计划他们同时排出了6毫升精液,每毫升精液都有6000万条精子。且不说这泳池的水会不会变浑,会不会有一种石楠花的味道,这600毫升浓浓的精液也就一可乐瓶,包含约360亿个精子,被释放到这1000立方米水中。
(13)

相应地间接社会群体应满足:
(14)

⑤ 评论内容影响
在LBSNs中以用户对兴趣点的访问频率作为用户对兴趣点的喜好程度的依据,而如果能够有效利用用户在某一时刻对某一兴趣点的评论信息[31,34-35],就能够更加准确地说明用户对该兴趣点的好恶,需要说明的是用户对兴趣点有过评论行为并不意味着该用户一定喜欢该兴趣点,因为用户的评论有可能是负面的,所以要进行语义分析,并量化出情感得分.文献[31]首先做出了利用评论信息提高兴趣点推荐的研究,利用用户的签到信息和评论信息为用户进行统一的混合偏好建模(hybrid preference model, HPM),其中对评论信息分析的首要任务就是将评论信息转化为情感得分.图3展示了一个意大利餐厅的留言,图3(a)是对留言的处理过程,使用了基于字典的无监督情感分析方法仅对英文留言进行了处理.首先在最开始的语言发现部分过滤掉非英语的留言;然后留言被划分为句子和词性(图3中的POS)进行识别,通过在SentiWordNet中查找获取每个词的情感得分,使用名词短语拆分技术提取短语;将留言中的每一个词的情感得分进行累加并归一化到区间[-1,1]获得留言整体的情感得分,-1表示最负面,0表示中性,1表示最正面,图3(b)展示了处理的结果;最后根据用户的签到频率和留言的情感得分建立用户—兴趣点偏好矩阵.

Fig. 3 Sentiment analysis of tips[31]图3 留言情感分析[31]
文献[36]利用3个步骤处理评论信息:首先使用标准自然语言处理工具预处理所有评论数据,删除停用字、标点符号和数字后,为每个评论提取一组术语以表示它;其次通过分析评论预先定义一组主题,为每个主题决定一组种子术语;最后一个跨越多个主题的用户兴趣分布被表示为一个长度为k的向量,元素为通过聚集这个用户所有评论的频率得到的关于某一主题的频率.由此用户的签到信息就有了极性,采用改进的随机游走算法使具有正面评价的兴趣点得到更多的优待和青睐.文献[37]利用潜在狄利克雷分布对评论内容信息进行建模,也取得了不错的实验效果.
此外除了上述5种影响以外,在LBSNs中与兴趣点相关的照片包含了丰富的关于兴趣点属性的独特信息,比如形状、结构、纹理等,而这些关于兴趣点的信息是无法从以上5种影响中获得的.文献[38]提出了利用视觉内容进行兴趣点推荐的方法:首先以照片作为输入,使用卷积神经网络(convolutional neural network, CNN)的VGG16模型对照片进行分析获取其视觉内容,视觉内容是一个长度为4 096的向量;其次基于获取的视觉内容,利用用户的隐含特征区分照片是否为某一用户所分享的,利用兴趣点的隐含特征区分照片是否与某一兴趣点相关联;最后综合利用上一步的分析结果建模照片的图像特征.真实数据集的实验结果表明,该方法有效提高了兴趣点推荐的精度.
2) 使用GPS数据集的位置推荐
相较于孤立的签到信息,用户产生的GPS轨迹数据包含了非常丰富的信息,其包含了用户轨迹的总时长、2个位置间的访问顺序、经过的路径、用户在一个位置的驻留时长、速度、海拔和一些相应的距离等丰富的地理信息,同时避免了签到数据的极度稀疏的问题.利用GPS轨迹数据可以进行兴趣点推荐[39-43]也可以进行旅程规划[44-45].
HITS算法[46-47]是链接分析中非常基础且重要的算法,Hub页面(枢纽页面)和Authority页面(权威页面)是HITS算法最基本的2个定义.所谓“Authority”页面,是指与某个领域或者某个话题相关的高质量网页,而“Hub”页面指的是包含了很多指向高质量“Authority”页面链接的网页.HITS算法的基本思想是相互增强关系,其假设一个好的“Authority”页面会被很多好的“Hub”页面指向,同时一个好的“Hub”页面会指向很多好的“Authority”页面.文献[39]将Hub看作一个访问了许多兴趣点的用户,将Authority看作为一个被许多用户所访问的兴趣点,同时假设在LBSNs中一个有经验的用户会访问很多好的兴趣点,一个好的兴趣点会被很多有经验的用户所访问,这也是一种相互增强关系,于是利用HITS算法可以发现并推荐好的兴趣点.文献[40]发现使用原始的HITS算法存在一定的缺陷,如果一个兴趣点仅仅被一个用户访问过且访问次数很高,HITS算法也会给该兴趣点分配一个很高的Authority得分,给该用户分配一个很高的Hub得分,这显然是不合理的.为此提出了在用户位置图上使用随机游走的随机化HITS模型,该模型具有对小的扰动不敏感且比原始HITS模型稳定的优点.
文献[44-45]利用GPS数据集进行了旅程规划方面的研究,主要分为离线与在线2个部分,如图4所示.离线部分的任务是构建一张位置—兴趣图,分为2个步骤:
步骤1. 从GPS轨迹中发现驻留点然后将驻留点聚类为位置点生成位置图.
步骤2. 在位置图中利用文献[39]提出的HITS方法推断每一个位置的兴趣值并且计算出每一个2长度的旅行序列的流行度得分,最终生成位置—兴趣图.
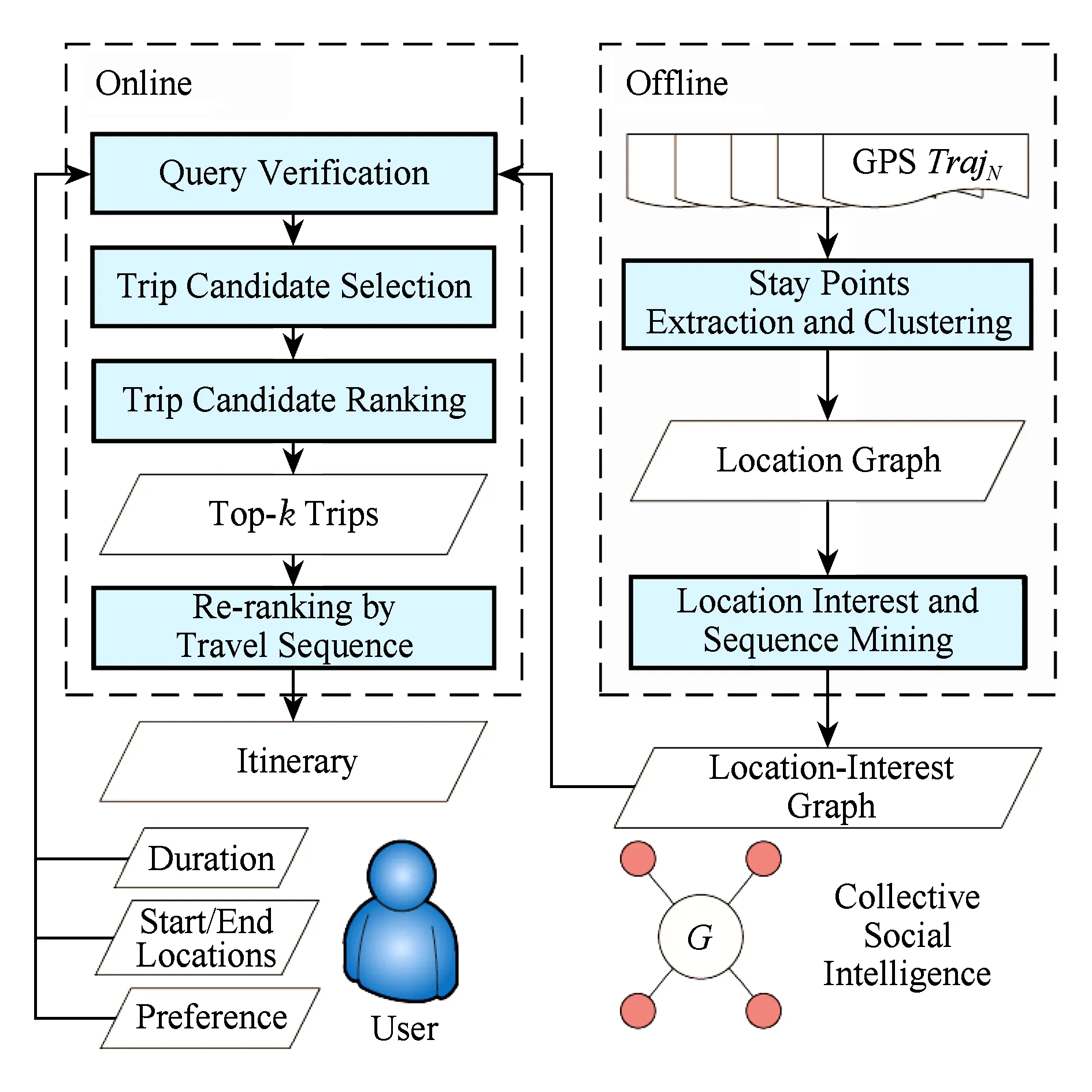
Fig. 4 Architecture of social itinerary recommender[45]图4 社会旅程推荐构架[45]
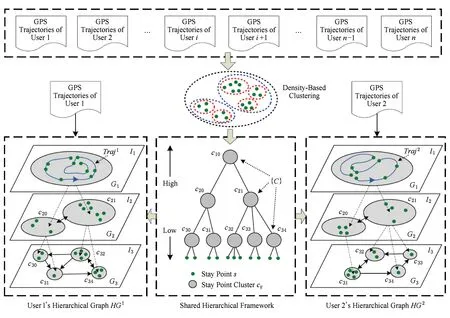
Fig. 5 Framework for modeling users location history in geographical spaces[1]图5 地理空间用户位置历史建模框架[1]
在线部分在接收到用户产生的查询以后要进行3方面的工作:①对用户的查询进行验证,从时间与空间2个方面检查用户查询的可行性;②搜索位置—兴趣图,生成满足用户查询的候选旅程;③对满足用户查询的候选旅程进行排序,排序分为以下2个步骤:
步骤1. 依据ETR(推荐旅程的时长与用户给定时长的比例)、STR(用户在一个位置的停留时长与位置间的迁移时长的比例)、IDR(一个旅程所包含的所有位置的兴趣值的总和)进行排序.
步骤2. 依据流行度得分进行再排序最终得到Top-k的旅程推荐.
3.1.2 朋友推荐
传统社交网络中的朋友推荐利用用户的属性、社会结构、用户的交互等信息为用户推荐潜在的朋友.对于朋友推荐常见的方法是将友谊预测看作为经典的链接预测问题并依赖于社交网络图中的临近度度量,用于测量2个用户之间临近度的方法包括共同邻居法、Jaccard系数和Admic/Adar方法.在LBSNs中,用户的位置历史通常能反映出用户的偏好,因此具有相似位置历史的用户很可能具有相似的偏好,因此也极有可能成为朋友.
1)使用GPS数据集的朋友推荐
文献[1]使用GPS轨迹数据集提出了朋友推荐的方法,其方法的核心是用户间相似性的度量.作者首先提出了新的框架,利用分层图来建模用户个人的位置历史,如图5所示:
在用户的个人位置历史建立以后,分2个步骤来计算2个用户间的相似性:
步骤1. 在分层图的每一个层内寻找2个用户移动轨迹的相似序列.
步骤2. 在给定了相似序列以后计算2个用户的相似性得分.
计算相似性得分时包含3个因素:①用户移动的顺序属性,即2个用户的位置历史所分享的相似序列越长,2个用户的相似度越高;②地理空间的分层属性,即2个用户所分享的位置历史粒度越细,2个用户的相似度越高,比如都去过同一所建筑物的2用户的相似度高于都去过同一个城市的2个用户的相似度;③不同位置的流行度,即都去过一个很少有人访问的位置的2个用户的相似度高于都去过一个很多人访问过的位置的2个用户的相似度,相似度得分的计算如下:
SimUser(LocH1,LocH2)=
(15)
(16)
(17)
(18)
式(15)表示根据2个用户的位置历史得出的相似性得分,其中l表示在分层图中所处的层,fw(l)确保越底层分配到越大的权重.式(16)表示一层中2个相似序列的相似性得分,其中j表示Seq1与Seq2中的第j个最大相似匹配;|Seq1|表示序列Seq1的长度;|Seq2|表示序列Seq2的长度,归一化是为了防止一个有长时间位置历史的用户比短时间位置历史的用户更容易和他人相似.式(17)表示一个最大相似匹配的相似性得分,其中gw(k)根据s的长度k分配权重;ci为s中所包含的位置.式(18)表示位置c的流行度,其中N为数据集中的用户总数,n为访问位置c的用户数.
2) 使用check-in数据集的朋友推荐
文献[48]提出了基于随机游走的上下文感知朋友推荐算法(RWCFR),将LBSNs建模为一个无向无权图,为了给用户推荐朋友,首先根据用户当前的上下文建立一张子图,构建子图的项目包括:①在附近区域用户先前访问过的位置(个人空间上下文);②在附近区域朋友和他们先前访问过的位置(社会空间上下文);③在附近区域专家和他们先前访问过的热门位置(社会空间上下文);④朋友的朋友(社会上下文);⑤访问过当前用户先前访问过的位置的用户(社会空间上下文).在子图建立以后,采用带重启的随机游走(RWR)[49]排序潜在朋友.
文献[50]使用Skyline查询[51]进行朋友推荐,主要分为4个步骤:
步骤1. 基于社交关系链接收集候选朋友和共同朋友的编号.
步骤2. 基于用户的签到信息计算用户与候选朋友间的距离.
步骤3. 基于签到信息和社交关系链接计算位置相似性以及朋友的影响,通过位置相似性和朋友的影响获取相似性得分.
步骤4. 使用Skyline查询获得朋友推荐列表.
文献[52]提出了针对活动推荐同伴问题,作者利用朋友关系可以根据朋友分享的兴趣来聚合的假设,使用签到数据集有效地解决了针对活动推荐同伴问题;为了识别同伴间的友谊类型,使用了潜在主题模型,同时还考虑了用户与所建议的场所位置的地理接近性,得到了很好的结果.
3.1.3 本地专家发现
在传统社交网络中通过分析信息扩散网络中节点的度来寻找意见领袖.在LBSNs中本地专家指的是对某一位置或区域非常了解且拥有很多本地知识的用户,寻找本地专家对于基于位置的社会化网络推荐系统有着重要的意义.
文献[39]基于有经验的用户会访问很多好的兴趣点,好的兴趣点会被很多有经验的用户所访问这样的假设,利用HITS算法推荐好的兴趣点的同时也发现了本地专家.该方法分为2个步骤:
步骤1. 将地理空间划分为基于树的分层图(TBHG),如图6所示.图6(a)表示不同粒度级别下的位置聚类,图6(b)表示每层上位置聚类之间的关系.
步骤2. 基于有经验的用户会访问很多好的兴趣点,好的兴趣点会被很多有经验的用户所访问这样的假设,将Hub看作用户,将Authority看作兴趣点,向每个用户分配旅行经验得分,向每个兴趣点分配流行度得分,如图7所示.由于用户的经验和兴趣点的流行度之间也具有相互增强的关系,因此以利用式(19)、式(20)来对用户经验和兴趣点流行度排序:

Fig. 6 Building a tree-based hierarchical graph[39]图6 基于树的分层图的构建[39]
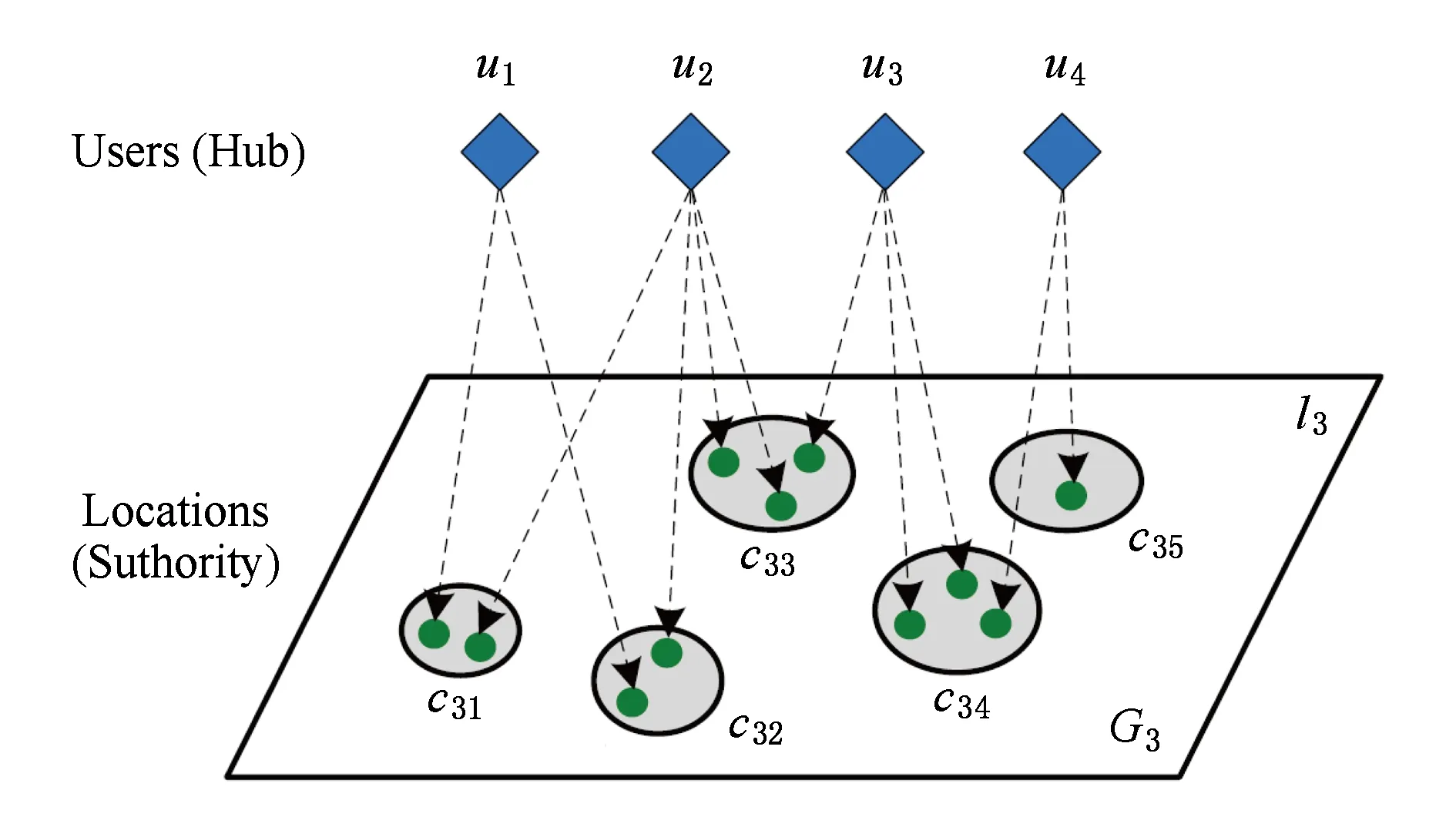
Fig. 7 HITS-based inference model[39]图7 基于HITS的推理模型[39]

(19)
(20)
Fig. 8 Demonstration of model[53]图8 模型演示[53]

3.1.4 活动推荐
在LBSNs中活动推荐为用户解决了2个问题:1)用户有了明确要进行的活动为其推荐活动场所;2)当用户指定一个具体的场所后为其推荐该场所适合的活动.用户通常会分享自己在某一地点所进行的活动,通过对分享内容的学习可以得到位置与活动之间的相关性,以此构建一个位置—活动矩阵,利用这个矩阵就可以进行活动推荐.但是由于用户的活动历史有限,用户分享的活动的位置远远小于实际的位置数量,因此位置—活动矩阵是非常稀疏的.文献[53]利用GPS轨迹数据,提出了协同矩阵分解模型进行活动推荐,为了解决位置—活动矩阵稀疏的问题,作者基于相同类别的位置可能具有相同活动的可能性的假设建立了 位置—特征矩阵,该矩阵表示了位置所属的分类信息(例如餐馆、酒吧、健身场所等等).显然,一个位置可以属于多个分类.为了推断在给定一个用户已进行了一些其他活动的情况下,在同一位置进行某一活动的可能性,作者建立了活动—活动矩阵来建模不同活动之间的相关性.在3个矩阵建立以后,如图8所示,使用协同矩阵分解最终得到位置—活动矩阵,目标函数推断位置—活动矩阵中缺失的值:
(21)

3.2 推荐方法
在对以上对象推荐的过程中,使用了基于内容的、链接的、协同过滤、基于矩阵分解的等多种推荐方法,以下分别做简单的总结.
基于内容的推荐方法主要是指直接将用户的偏好属性与位置的特征进行匹配的推荐方法,该方法的优点是不会被冷启动问题所困扰,但缺点是需要将位置信息与用户信息结构化,在LBSNs中完成这项工作代价巨大;此外,该方法无法利用从用户推测出来的聚类信息.
基于链接分析的推荐方法[39-40,48]主要是指通过对已知网络结构等信息进行分析,预测和估计未链接的2个节点之间存在链接的可能性,其典型代表为PageRank[54]和HITS[46-47].基于链接分析的推荐方法的优点在于不会被冷启动问题所困扰,同时还考虑了用户的经验,但缺点是由于忽视了用户的偏好它只能做通用推荐而无法将推荐个性化.
基于协同过滤的推荐方法[4-5,55-59]主要分为基于用户的协同过滤和基于位置的协同过滤.在LBSNs中使用协同过滤方法主要分为3个过程:1)候选集的筛选,以此缩小计算范围;2)相似度的计算,直接影响到推荐的性能;3)推荐得分的计算,以此排序推荐对象.该方法的优点是不需要将位置信息与用户信息结构化同时还利用了社区意见,但缺点是容易受到冷启动问题的困扰,容易受到稀疏问题的困扰;同时由于用户与位置数量巨大,相似性计算的代价也是巨大的,此外,由于LBSNs增长迅速,该方法的可扩展性也受到了极大的挑战.
自从Netfix大奖赛获得巨大的成功,基于矩阵分解的推荐算法[60-61]受到了学术界和工业界的广泛关注,在LBSNs中也得到了广泛的使用[6,10,53,62].在LBSNs的推荐服务中,基于矩阵分解的推荐算法将用户和位置的特征向量同时映射到低维的隐藏因子空间,在低维的隐藏因子空间中,由于用户偏好和位置特征之间的相关性可以直接计算,矩阵分解的推荐算法利用用户和位置的低维特征向量的内积来预测用户对项目的评分.基于矩阵分解的推荐算法主要包括基本矩阵分解、非负矩阵分解和正交非负矩阵分解3种.其优点是可以发现数据中的潜在结构、具备优雅的概率解释、容易扩展到一些指定特定先验信息的领域,许多优化方法例如梯度下降法可以用来找到一个最优解,适合填充稀疏矩阵.
在LBSNs中,其他的一些推荐方法还包括:基于张量分解的推荐方法[18,20,63-64]、基于元路径的推荐方法[65]和基于神经网络的推荐方法[66]等.
3.3 评价方法
与传统推荐方法使用的评价方法类似,在LBSNs中,目前常用的评价指标有准确率P、召回率R、平均精度均值(mean average precision,MAP)、归一化折损累积增益(normalize discounted cumulative gain,NDCG)、平均绝对误差(mean absolute error,MAE)、均方根误差(root-mean-square error,RMSE)等.准确率P、召回率R、平均绝对误差MAE和均方根误差RMSE的定义:
(22)
(23)
(24)
(25)
其中,yi表示真实值,fi表示预测值.
准确率只考虑了推荐列表中准确的推荐结果的个数,没有考虑推荐结果之间的序.对于一个推荐系统而言返回的推荐结果必然是有序的,而且越准确的推荐结果排序越靠前越好.于是对于一个推荐列表就需要计算其平均精度(average precision,AP),定义为
(26)
其中,k表示推荐列表中的排名,P(k)表示推荐列表中截止到排名k的准确率,rel(k)表示一个指示函数,如果在排名位置k是一个准确的推荐结果其值为1,否则为0,N表示推荐总数.MAP的定义为
(27)
其中,Q表示推荐的总次数.
折损累积增益(discounted cumulative gain,DCG)也是一个衡量排名算法的指标,计算公式为
(28)
其中,reli表示第i个结果的评分.NDCG的定义:
(29)
其中,IDCGp表示理想的DCGp.
在推荐系统中,MAP和NDCG是2个最受欢迎的排名指标,两者之间的主要区别是:MAP认为对象是二元相关性(一个对象是感兴趣的或者不感兴趣的),而NDCG允许以实数形式进行相关性打分,这种关系类似分类和回归的关系.一个推荐方法返回多个项并形成一个推荐列表,NDCG要评价这个列表的优劣,其中每一项都有一个相关的评分值(非负数)这就是所谓的增益(gain),而对于那些没有反馈给用户的项将其增益设置为0,把这些评分值相加,就得到了累积增益(cumulative gain),而在把这些分数相加之前将每项除以一个递增的数(通常是该项位置的对数值)也就是折损值就得到了DCG.在用户与用户之间,DCG没有直接的可比性,所以要对其进行归一化处理,归一化采取计算列表中前k项的DCG,然后将原DCG除以理想状态下的DCG就得到了NDCG.
4 总结与展望
基于位置的社会化网络推荐技术作为推荐系统和社会化网络研究领域的一个新的研究热点受到学术界和工业界的广泛关注,尽管在推荐架构、位置建模、相似性计算、推荐算法等诸多方面基于位置的社会化网络推荐技术都取得了一系列重要研究成果,但随着数据量的爆炸性增长以及计算模式与技术的不断演化,基于位置的社会化网络推荐方面仍然存在着一些挑战和潜在的研究方向:
1) 推荐技术不应该只局限于地理空间,由于地理空间的限制,推荐系统无法利用2个相距遥远但拥有着相同出行习惯和共同偏好的用户信息进行推荐,而语义空间就很好的解决了这一问题,所以如何有效利用语义空间更好地进行推荐是一个重要的研究方向;
2) 一个高质量推荐的产生一定是多方面因素共同作用的结果,为了能让用户得到更满意的推荐结果及时获取用户的多方面需求离不开情境信息,这就要求一个能够整合情境的面向用户查询的推荐系统;
3) 随着数据量的爆炸性增长,目前LBSNs中包含了海量的丰富信息,因此,如何将大数据处理技术与基于位置的社会化网络推荐相结合也是一个值得关注的方向,与此同时,结合并行计算来提高运算效率也是不可或缺的,文献[67]已经做了一些初步的探讨;
4) 为了让推荐服务能随着时间的推移逐步提高自己的推荐质量,接受推荐反馈并不断调整推荐能力也是不可或缺的[68];
5) 深度学习目前在数字图象处理和自然语言处理方面表现出了巨大的潜能,如何将其无缝地应用到基于位置的社会化网络推荐方面是一个很有潜力的发展方向.
