深度学习大数据分析计算平台
2018-10-13郭泉
郭泉
(四川大学计算机学院,成都 610065)
0 引言
近年来,大数据所隐含的巨大价值越来越受到各行各业的重视。大数据通常是指在可容忍的时间内用传统信息技术和软硬件工具难以对其进行获取、管理、处理和分析的数据集合,具有体量浩大(Volume)、多源异构(Variety)、生成快速(Velocity)、价值巨大但密度很低(Value)的4V特征。大数据分析是将大数据转换为价值的重要一环[1]。大数据计算,则主要是面向大数据分析进行计算。深度学习已经在大数据分析的各个领域取得突破性进展[1,2]。其需要大量计算,得益于GPU等计算资源高效的计算方式。然而如何管理好这些计算资源?本文提出利用Linux操作系统容器技术,通过对系统资源的分割和映射,管理其系统资源,尤其是计算资源,形成基于操作系统容器的深度学习大数据分析计算平台。
1 研究现状
深度神经网络模型成为国际上大数据分析领域中的研究热点。Google、微软等公司利用GPU加速建立的深度学习网络已经在图像识别[3]、语音识别[4]等领域取得重大突破。然而大规模深度学习平台的搭建仍处于摸索阶段,尚缺乏统一的深度学习大数据分析计算的范式和可扩展的计算平台搭建方法。除了传统的CPU、GPU等通用处理器计算方式,还涌现了如FPGA、ASIC等专用处理器设计。中科院计算所陈云霁研究员等人在专用芯片设计上取得突破。基于深度学习的大数据分析计算初露头角,百花齐放,目前的挑战是,如何建立一个深度学习并行计算平台,更好地利用GPU和其他协处理器的计算特性。
2 基于容器技术的计算平台
Linux操作系统容器(Linux Container,LXC),可以看做是实现了一种轻量级的虚拟化,为每个计算节点提供虚拟化运行环境,几乎无额外性能开销,同时便于管理和应用独立性。Docker是一个LXC应用容器引擎,可通过Docker进行系统资源的管理和分配,尤其是GPU等计算资源。
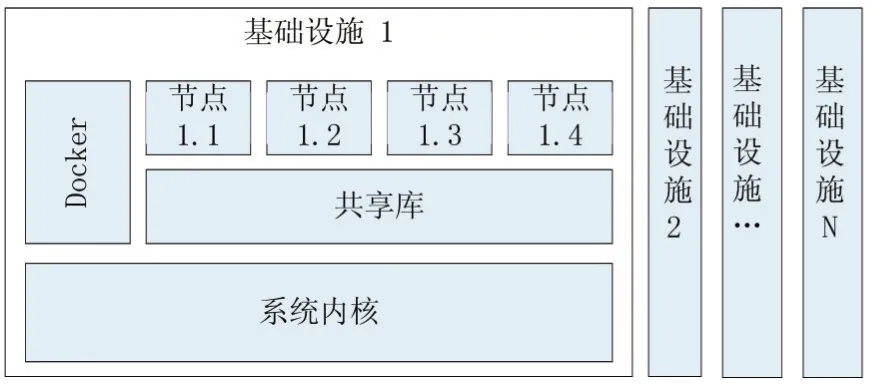
图1 系统架构图
我们在操作系统镜像的基础上,特定映射一个用户工作目录,用于管理该容器的工作范围。其次映射GPU资源,包括设备文件、驱动文件和CUDA库。最后为了方便操作,我们映射一个网络端口方便在容器中通过网络服务进行交互,例如通过Jupyter在浏览器上进行开发和维护工作等。
3 计算性能实验
为了验证本文提出的基于操作系统容器的深度学习大数据分析计算平台的计算性能,我们进行以下几组实验。深度学习中的计算主要是矩阵乘法计算,对于m×k的矩阵A和k×n的矩阵B,其矩阵乘积为m×n的矩阵C,其中元素Cij为A中第i行元素与B中第j列元素对位相乘结果之和。矩阵乘法计算,在无特殊性质无优化的计算方式下,其计算代数操作数为m×k×n,其时间复杂度为O(n3)。我们设计一个大型计算图,包括每个GPU上进行一个大型矩阵乘法,再汇聚到一个GPU上汇总求和。这符合深度学习中通常遇到的计算模式。这里我们令A为5120×10240的随机矩阵,B为10240×7680的随机矩阵,我们让每个GPU计算C=AB,并对全部的C求和。注意,生成随机矩阵也涉及GPU的代数操作,记入其代数计算次数,这也是深度学习训练过程中常涉及到的操作过程。
接下来在提出的基于操作系统容器的深度学习大数据分析计算平台,使用不同数量的GPU进行上述矩阵乘法实验。
使用1块GPU计算,任务包含代数计算805568512000次。重复进行10次实验。

表1 使用1块GPU计算的计算性能
以上实验可以看出,10次实验平均用时0.165秒,标准差0.107,平均计算吞吐量为6.150TFlops,标准差2.135。值得注意的是,第一次实验的时间显著高于其他9次,对应的,计算吞吐量也较后者低。这是因为系统中的计算卡的初始激活和分配被记入了时间统计过程。因此可以认为第一次实验的结果为离群点,在统计中可以将其去除。去除离群点后实验室平均用时0.131秒,标准差 0.042,平均计算吞吐量为6.640TFlops,标准差1.632。后面的实验中我们也将以相同的原则去除离群点,并汇报两种统计结果。
使用2块GPU计算,该任务含有代数计算1611176345600次。重复进行10次实验。

表2 使用2块GPU计算的计算性能
以上实验中,十次实验平均用时0.227秒,标准差0.161,平均计算吞吐量为9.129TFlops,标准差3.255。去除离群点后实验室平均用时0.177秒,标准差0.054,平均计算吞吐量为9.882TFlops,标准差2.470。
使用4块GPU计算,该任务包含代数计算3222392012800次。重复进行10次实验。

表3 使用4块GPU计算的计算性能
可以发现,十次实验平均用时0.302秒,标准差0.288,平均计算吞吐量为 14.499TFlops,标准差4.183。去除离群点后实验室平均用时0.206秒,标准差 0.027,平均计算吞吐量为 15.802TFlops,标准差1.568。
以上四个实验中的代数计算次数基与使用的GPU数量正相关,即每个卡上的平均计算量是一致的,因此我们可以认为这些任务中其卡均计算量是一定的,我们可以横向比较这些吞吐量来观察不同GPU数量下平台计算性能变化情况。

图2 相同卡均计算量下使用不同数量GPU卡的计算性能
这里采用去除离群点的吞吐量平均值反映计算能力。可以看出,在同样的卡均计算量任务的情况下,随着使用GPU数量增加,平台的吞吐量增加显著。这是由于平台利用了计算任务之间的并行特性,通过并行提高了总体计算能力。
4 结语
操作系统容器可以看做是一种轻量级的虚拟化,在划分系统资源的同时,能够较高效地映射系统资源形成一个小的完整操作系统,与当代深度学习相结合,通过映射和管理系统的存储、计算资源,形成一个有效管理的平台,即基于操作系统容器的深度学习大数据分析平台。实验证明,本文提出的平台能够很好地利用GPU进行深度学习计算,对于大规模的矩阵乘法、加法、随机采样复合代数操作计算图,计算性能卓越,随着使用的GPU数量增加,在卡均任务不变的情况下总体计算性能增加。未来可以向多机计算资源管理进行进一步工作。
