基于长短期记忆网络算法的电费回收风险预警
2018-10-12谢林枫钱立军
谢林枫, 钱立军, 季 聪, 江 明, 吕 辉
(1. 江苏方天电力技术有限公司, 江苏 南京 211102;2. 国网江苏省电力有限公司, 江苏 南京 210024)
0 引言
一直以来,电费回收率[1]都是电力公司的重要考核指标,直接关系到电力公司的运营效率和水平。电力大客户合同容量大、用电量大,其是否及时缴费,很大程度上影响着电费回收率。因此,近年来,电力公司一直将电费回收风险[2]作为其运营风险的核心指标之一,也围绕这一主题开展了大量的研究工作,取得了一定的成效。
文献[3—4]采用层次分析法、熵值法建立了电力大客户信用评价体系,用于防范电费回收风险,而本文综合考虑了电力客户电量、电费、工商、司法等数据,建立大客户电费回收风险预警体系。文献[5—6]采用逻辑回归、随机森林等传统数据挖掘算法实现了客户电费回收风险预警,而本文采用长短期记忆(long short-term memory, LSTM)网络算法提取客户风险特征,实现电费回收风险预警。文献[7—8]借助大数据技术、“客户画像”等新技术开展了电费回收风险研究。
电费回收风险受客户生产运营情况、财务经济状况、宏观经济政策等众多因素的影响,相关因素的筛选和量化较为困难。而深度学习[9-11]算法能够自动选取关键因素,目前在电力负荷预测、变压器故障诊断等方面得到了应用[11-16]。因此本文研究了循环神经网络(recurrent neural network, RNN)算法的基本原理,考虑到电费回收风险预警随时间推移存在一定规律,本文进一步研究了RNN算法的特殊类型——LSTM网络算法,用于开展电费回收风险预警工作,取得了较传统算法更精确的预警结果。
1 电费回收风险的指标体系
1.1 指标体系建立
电力大客户电费回收风险受其所在行业背景、自身实力、经营能力等多重因素影响,因此,本文基于电力内部的电量、电费、违约用电等数据,结合外部的工商、税务、法院信息,建立了电力大客户的电费回收风险指标体系,如表1所示。

表1 电费回收风险指标Tab.1 Tariff recovery risk indices
1.2 指标筛选
在进行客户风险预警模型构建之前,需要对客户风险指标进行筛选,过滤掉弱影响指标,并利用相关性分析剔除作用重复的指标。
首先采用熵值法[17]计算表1中的各指标权重,结果如表2所示。

表2 各电费回收风险指标权重系数Tab.2 Weight of each tariff recovery risk index
过滤弱影响指标,剔除表2中权重系数绝对值<1.5%的8个指标,得到27个权重系数较高的指标。对剩余的27个指标进行相关性分析,得到相关性系数较高的指标见表3。

表3 相关性系数较高的指标Tab.3 Indices with high correlation coefficient
剔除实收资本、前年用电量增长情况和最近一年电费回收准时度3个指标,得到最终的24个与客户欠费风险密切相关的指标。
2 深度学习算法的基本原理
2.1 RNN的基本原理
在传统神经网络模型中,输入层、隐含层和输出层之间全连接,而每层的节点相互无连接;序列当前的输出与前一时刻输出相关时,这种连接方式无法体现和处理这种关系。而RNN的隐含层之间也有连接,隐含层的输入不仅包括输入层提供的输出,还包括上一时刻隐含层的输出。通过这种方式,RNN可对前面时刻的信息进行记忆,并应用于当前时刻的计算。RNN的简单结构如图1所示。
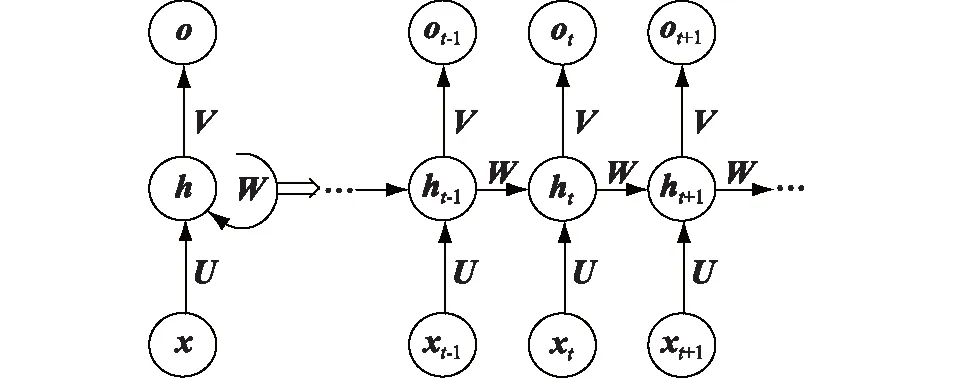
图1 RNN的基本结构Fig.1 The basic structure of RNN
x=[x1,…,xt-1,xt,xt+1,…,xT]为网络的输入,T为RNN网络建模的总时刻数,t时刻的输入即为xt;ht为代表t时刻的隐含层状态,ot为t时刻的输出;U,V,W为输入层到隐含层、隐含层到隐含层、隐含层到输出层的权重系数矩阵。
RNN的Forward过程,在t时刻,网络的输出可以用下式表达:
ot=g(Vht)
(1)
式中:函数g一般为softmax函数;ht为隐含层的状态,其计算公式为:
ht=f(Uxt+Wht-1)
(2)
其中,f一般为tanh、relu、logistic等函数。
(3)
(4)
(5)
3.2 LSTM的基本结构
RNN很好地利用了历史信息来帮助网络进行当前决策,但当回归/分类信息所需的历史信息间隔较远时,RNN就会丧失学习能力,这种问题称为长期依赖问题。对长期依赖问题而言,RNN的Backward过程中梯度会呈指数倍衰减,这种衰减导致RNN无法处理长期依赖问题。为了克服RNN的这种缺陷,国内外专家学者们研究和改进了众多方法,其中LSTM表现最为出色。当误差从输出层反向传播回来时,LSTM可以用记忆元存储下来,以记住较长时间内的信息。
所有的RNN都具有重复神经网络模块的链式形式,在标准的RNN中,这个重复模块结构简单,一般只有一个tanh层;LSTM同样具有这样的重复结构,但其神经网络层有4个,相互直接通过特殊方式进行交互,标准RNN模块和LSTM模块的链式结构如图2所示。

图2 LSTM网络模块的链式结构Fig.2 The chain structure of LSTM network module
LSTM一个重要的概念是细胞状态,它可以通过精心设计的“门”结构来更新细胞状态。LSTM神经网络模块的4层结构中:
第一层为遗忘门层,它决定从细胞状态中丢弃什么信息。第二层为输入门层,一般为sigmoid函数,决定需要更新的信息。第三层为tanh层,通过创建一个新的侯选值向量更新细胞状态。第二层和第三层共同作用,更新神经网络模块的细胞状态。第四层为其他相关信息更新层,用于更新由其他因素导致的细胞状态变化。
通过4层结构模型,LSTM很好地解决了标准RNN对长期依赖问题处理效果欠佳的问题,目前在语言模型、序列标记中取得一定的成功。
3.3 LSTM的工作原理
LSTM神经网络模块的四层结构,使得其工作原理比标准RNN网络更加复杂,本文以图4的LSTM模块为参照,详细介绍了LSTM的工作原理。假设LSTM神经网络模块的各信号定义如图3所示。

图3 LSTM神经网络模块的各信号定义Fig.3 Definition of signals in LSTM neural network module
LSTM神经网络模块中的信号传播规则如下式:
(6)
其中:φ(x)=tanh(x),σ(x)=1/(1+e-x),带下标的各W参数代表两个信号之间的权重系数,带下标的各b参数代表各信号的偏置值。
令xct=[xt,ht-1],则式(6)可以改写为:
(7)
式中:ft为遗忘门,决定从细胞状态的上一个状态中丢弃的信息;it和gt构成输入门,决定新的细胞状态中保存的信息;ot为输出层,决定要输出的信息。
3.4 LSTM的参数设置
LSTM虽然学习能力强大,但也要基于模型要求和人工经验,设置一些超参数,使算法的寻优速度更快、分类准确度更高。
(1) Hidden_Size。隐藏层神经元个数,其个数越多,LSTM网络越强大,但计算参数和计算量会因此急剧增加;而且,要注意隐藏层神经元个数不能超过训练样本条数,否则容易出现过拟合。
(2) Keep_Prob。神经元连接不被切断的概率,在神经元输入端有数据输入时以Keep_Prob的概率正常工作,以1-Keep_Prob的概率输出为0,这种局部连接方式可以降低数据过拟合的概率。
(3) Num_Layers。LSTM网络的层数,层数越多,网络越大,学习能力越强大,同时计算量也会大幅增加,对于电费回收风险这类输入数据类型相对简单的问题,设置为2层一般能够满足需求。
(4) Learning_Rate_Base。学习率初值,会影响各神经元连接的权值更新速度,学习率大,权值更新就快,到训练后期损失函数可能在最优值附近振荡,学习率小,权值更新就慢,过小的权值可能导致优化损失函数下降速度过慢。因此目前常用的方法是在训练初期设置较高的学习率,以确保损失函数以较快的速度向最优值靠拢,随着训练次数的增加,不断降低学习率,使损失函数在局部范围内不断逼近最优值。
(5) Learning_Rate_Decay。学习率衰减速度,与学习率初值搭配,使LSTM网络的学习能力更加强大、智能,具体操作方法见(4)。
(6) Regularization_Rate。正则化率,为了防止LSTM网络过拟合,一般的做法是在损失函数后加一项正则化惩罚项,而正则化率正是该惩罚项的系数,其值越大,对LSTM网络过拟合的惩罚越大。
(7) Train_Times。训练次数,随着训练次数的不断增加,LSTM网络的准确性越高,但当训练次数达到一定值后,LSTM网络的准确性将不再提高或提升很小,而计算量却不断增加。因此在具体操作时,应结合研究问题的需要,选择合适的训练次数。
3 算例分析
为了验证本文所选指标的合理性和算法的先进性,以某区域电网3039户电力大客户为例,进行电费回收风险预警算例分析。选取其中2839户为训练集(其中2809户非欠费客户,30户欠费客户),200户为测试集(其中191户非欠费客户,9户欠费客户)。LSTM参数设置见表4。
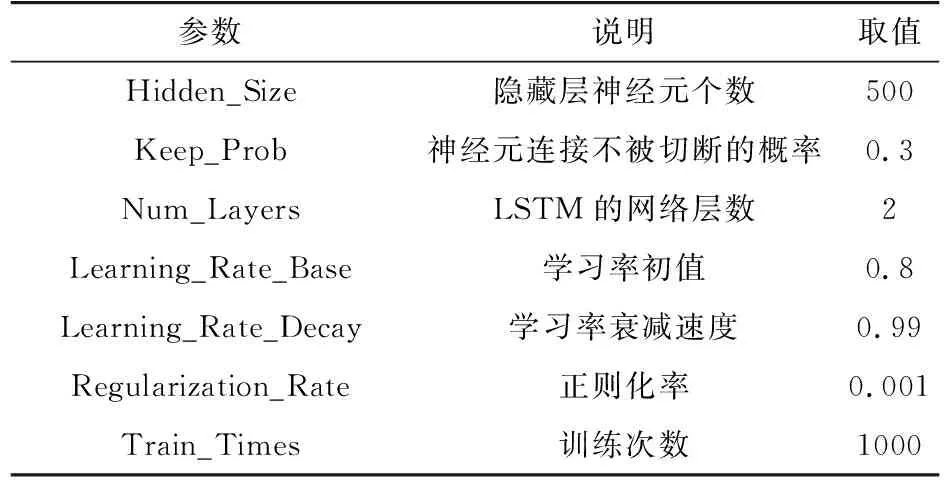
表4 LSTM参数设置Tab.4 LSTM parameter setting
采用训练集对LSTM网络算法进行训练,并将训练好的模型用于对200户测试样本进行电费回收风险预警,并与Logistic回归、C4.5决策树、支持向量机(SVM)的预警结果比较,如表5所示(1表示客户发生欠费,0表示客户未发生欠费)。
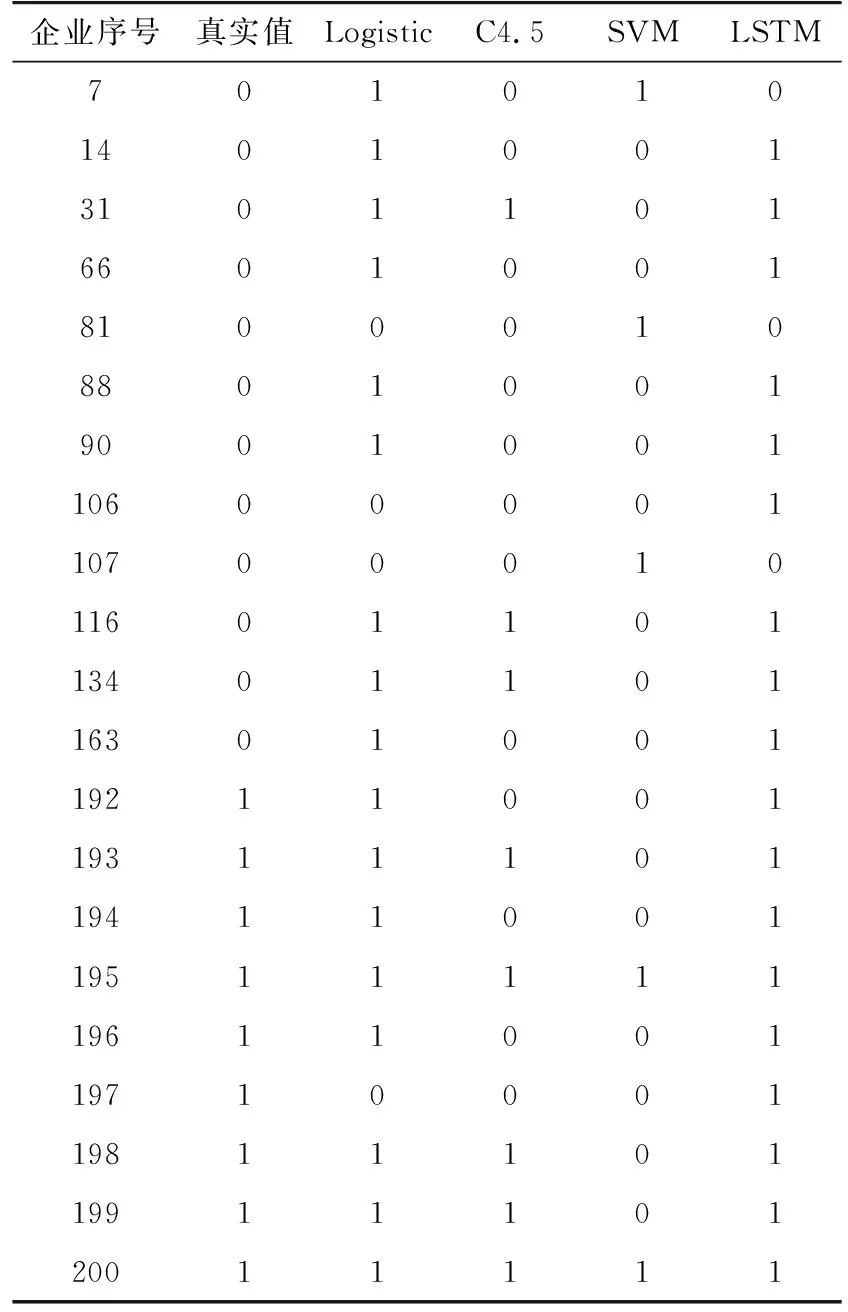
表5 风险预警结果比较Tab.5 Comparison of early warning results of tariff recovery risk
为了更好地对比算法的性能,本文在准确率指标的基础上,引入了预警命中率和覆盖率指标,其计算规则如下:
(8)
式中:Nwarn为算法计算得到的风险预警客户数;Nreal为实际发生电费回收风险的客户数;Nright为算法命中的实际预警客户数;Hr为算法的命中率,即算法预警的客户数中实际发生欠费客户数的比例;Cr为算法的覆盖率,即实际发生欠费的客户数中被算法预警结果覆盖的比例。
各算法准确率、命中率和覆盖率如表6所示。
(1) 准确率而言,各算法都达到了95%以上,其中C4.5决策树准确率最高。
(2) 命中率而言,C4.5决策树命中率最高,其计算得到的风险预警客户8户,其中5户实际发生了欠费;而LSTM计算得到的风险预警客户18户,其中9户实际发生了欠费,查准率50.00%。
(3) 覆盖率而言,实际发生欠费客户9户,LSTM覆盖了全部欠费客户,覆盖率100%;Logistic回归覆盖了其中的8户,覆盖率88.89%;在准确率、命中率方面表现最好的C4.5决策树算法,仅覆盖到5户,覆盖率55.56%。
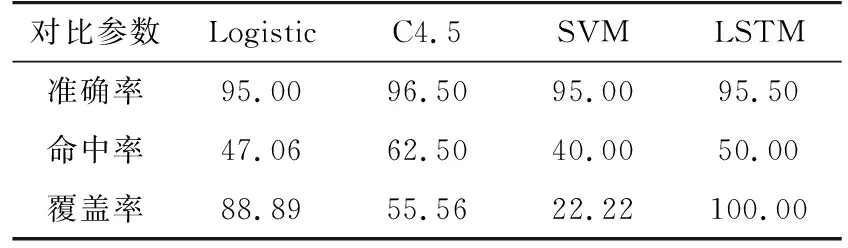
表6 风险预警算法效果对比Tab.6 Comparison of the effect of risk early warning algorithms %
从电费回收工作的实际需求看,首要的要求是能够识别所有的欠费客户,也即覆盖率,以便于杜绝电费回收风险转化为实际欠费;其次,命中率的提高,能够将电费催收对象锁定到了更小的客户范围,减少电费催收的工作量。从这两个要求看,LSTM命中了所有实际欠费客户,而且将催费对象锁定到18户,也即在降低工作量的同时,规避了所有的电费回收风险。
4 结语
电费催收工作一直以来都是电力公司的一项重要工作,消耗了大量的人力物力,但由于电费回收风险的潜伏性、突发性,导致电费催收工作中仍然存在漏网之鱼。因此,本文结合业务人员的关注重点,建立了电费回收风险指标体系,采用熵值法和相关性分析筛选了电费回收风险的关键指标,并采用LSTM进行电费回收风险预警,取得了显著的成效,预警准确率、查准率和查全率全面高于传统方法。研究成果可以精准定位高风险客户群体,提高电费催收的针对性。
