基于统计诊断的大坝监测数据合理性检验
2018-10-09李子阳马福恒
李子阳,郭 丽,马福恒,胡 江
(1.南京水利科学研究院水文水资源与水利工程科学国家重点实验室,江苏 南京 210029;2.南京体育学院附校部,江苏 南京 210024)
在大坝安全监测中,受大坝性态演化和作用环境[1]、观测随机因素及仪器本身监测精度等的影响,监测数据不可避免地存在误差[2]。大样本的自动化监测数据,一般存在显著的随机特征,即数据本身存在随机误差;受监测过程中的不确定因素影响,如仪器的不稳定或监测基点发生位移,还可能产生系统误差等。误差的存在影响模型分析的准确性,因此,对大坝监测数据进行合理性检验,以获取更为合理有效的基础分析数据,是监测资料分析和工程性态评估的首要工作。
基于统计分析的假设检验(如PauTa准则、t检验法及Dixon判别法等)是监测数据误差检验的常用方法[3-5],对自变量数据(基础环境量数据)的误差分析是有效的,如通过测值范围和方差对传感器数据进行误差检验等[6]。但大坝监测数据受水压、降雨、温度、时效等环境因素的综合影响,监测数据为因变量数据,若只对数据本身或模型参数进行常规的统计检验分析,极有可能会把因环境突变而引起的监测数据改变误判为误差数据,导致有用数据被误删。另外,常规统计方法在分析数据对模型的影响程度和趋势性方面也有所欠缺[7]。
引入统计诊断的方法进行数据的检验分析,可以很好地解决上述问题。统计诊断[8]首先根据因变量和自变量之间的影响关系构建统计模型,进而借助统计诊断量检查数据、模型及推断方法中可能存在的问题,其在综合考虑大坝监测中自变量数据与因变量数据内在关联性方面具有优势,可为监测数据的合理性检验提供更符合工程实际的方法。统计诊断已在滑坡体位移监测数据异常值检验中有所应用[9],本文在此基础上,从大坝监测数据的异常数据类型分析出发,进一步研究基于均值漂移模型的统计诊断方法,对监测数据的误差数据和强影响数据的统计检验进行分析研究,并以大坝位移监测数据的合理性检验为例进行验证。
1 监测异常数据分析
根据统计诊断中的异常数据分类,结合大坝工程自动化监测数据特点和误差形成原因的不同,将监测数据中的异常值分为随机误差、粗差和系统误差(如图1所示)[2, 8]。随机误差主要由各种随机和偶然因素引起,符合均值为零的正态分布,在连续大样本的自动化监测数据中普遍存在,一般不影响正常的统计和时序分析。粗差是指含有粗大误差、严重偏离真实值(或既定统计模型)的数据,常常是由观测过程中的操作疏忽和数据的记录、复制和计算处理过程中的过失错误引起。系统误差是指由相互独立的偶然因素作用引起的监测仪器或监测点故障等所造成的误差,严重偏离真实值(或既定统计模型),常表现为单侧点数据异常波动的现象,并可能具有一定的连续性和阶段性。如观测基点因基础或外力作用产生明显扰动,则会引起观测数据的系统误差。
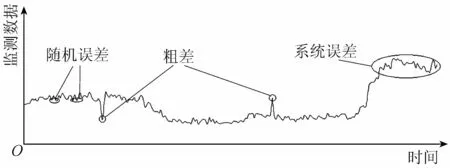
图1 监测异常数据示意图
在数据表现上,粗差具有突发性,在相邻监测数据中通常以个别形式出现,一般不具有连续性;系统误差由于系统故障难以自行修复,往往表现为多个数值接近的测值连续出现,并在均值附近摆动增大,具有一定的趋势性。粗差一般表现为污染正态分布,可采用统计诊断方法进行分析;系统误差往往可通过同类监测数据的综合过程线对比辨识[10],本文不作重点讨论。
在误差分析的基础上,为对监测数据的重要程度进行区分,定义统计诊断中的强影响数据为对统计推断(如统计模型参数、拟合预测值等)影响特别大的监测数据。由于强影响数据对统计诊断结果具有较大影响,需要特别关注。
2 均值漂移模型
大坝监测数据合理性检验的主要目的是删除粗差,并辨识强影响数据。一个很重要的方法就是逐个计算每组数据对回归分析的影响,进而通过考察统计诊断量的方法来获取不同误差的来源。这里采用均值漂移模型对数据进行统计诊断,即在第i个数据上增加一个扰动(附加值),这相当于因变量的均值有所漂移,研究这个扰动对估计量及其他统计量影响的显著程度。
对含有自变量xi(xi=(xi1,xi2,…,xi(k-1)))与因变量yi的n次监测资料序列建立线性回归方程:
(1)
其中θ=(b0,b1,…,bk-1)Tφi=(1,xi)T
εi∈N(0,σ2)
式中:θ为回归参数;εi为随机误差项,服从方差为σ的标准正态分布;k-1为自变量xi所包含的元素个数。
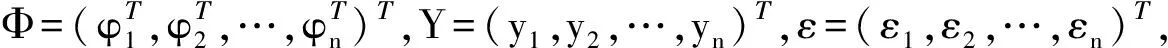
Y=Φθ+ε
(2)
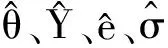
(3)
(4)
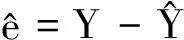
(5)
(6)
式中:e为残差。
记Ρ=Φ(ΦTΦ)-1ΦT(帽子矩阵),其对角元素pii有[11]
(7)
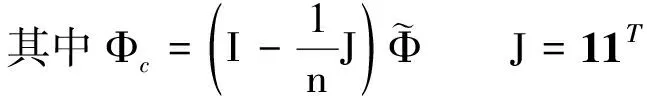
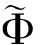
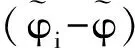
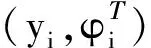
(8)
其矩阵形式为
Y=Φθ+diγ+ε
(9)
式中:di为n维单位向量,其第i个分量为1,其余均为零;γ为扰动值。
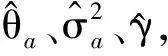
(10)
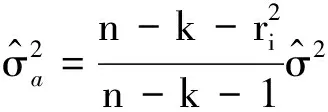
(11)
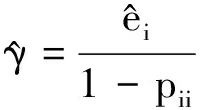
(12)
式中:ri为学生化内残差。
3 基于均值漂移模型的统计诊断
3.1 粗差检验
(13)
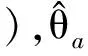
H0:γ=0;H1:γ≠0
(14)
假设检验式(12)的检验函数可由下式给出[12]:
(15)
3.2 强影响数据检验
由线性模型的理论可知,模型式(2)中参数θ的1-α置信域可表示为一个椭球的形式:
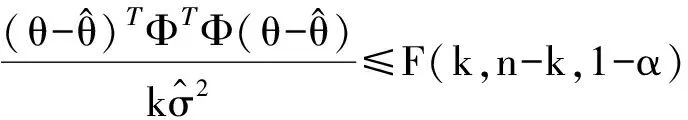
(16)
式中:F(k,n-k,1-α)表示F分布的1-α分位点。
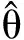
(17)
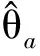
将式(10)和式(12)代入式(17)中,Di又可表示成如下形式:
(18)
4 实例分析
选取某重力坝坝顶引张线测点顺河向位移自动化监测数据为例,采用上述统计诊断方法进行监测数据的合理性检验。分析选用的典型测值过程线如图2所示,时间序列为2006年12月22日至2012年9月20日,测值以向下游为“+”,向上游为“-”。
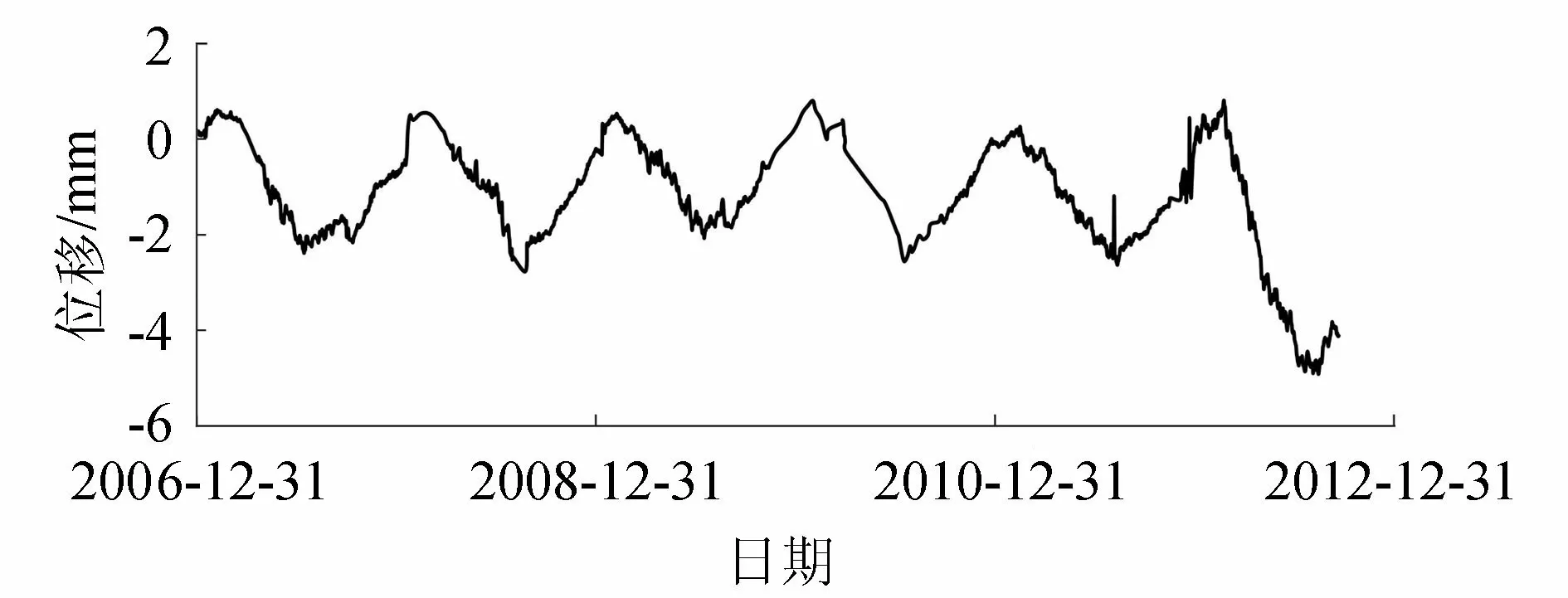
图2 坝顶测点顺河向位移过程线
根据测值过程线可以看出,坝顶顺河向位移呈较为明显的年周期变化,受水位、温度影响显著,考虑时效因素影响,其位移监测资料的统计模型可表征为如下形式[14]:
c1(t-t0)+c2(lnt-lnt0)+a0+ε
(19)
其中ε∈N(0,σ2)
式中:yH,yT,yθ分别为水压分量、温度分量、时效分量;Hu,Hu0分别为监测日、始测日所对应的上游水头;ai为水压因子回归系数;t为位移监测日至始测日的累计天数;t0为建模资料系列第一个监测日至始测日的累计天数;b1i,b2i为温度因子回归系数;c1,c2为时效因子回归系数;a0为常数项。
比照式(1),监测数据向量为
(20)
未知参数为
θ=(a0,a1,a2,a3,b11,b21,b12,b22,c1,c2)T
(21)
监测数据组数n=1 634(部分时段无测值),k=10。
根据测值变化规律,2012年第二季度开始,测值减少较为显著。综合同类测点监测资料及同期环境量变化分析,认为测值显著变化是由右岸观测基点的位移造成,属系统误差数据,一并对其进行计算分析。
对所有监测数据采用本文检验方法进行统计诊断,部分异常数据检验结果如表1所示。
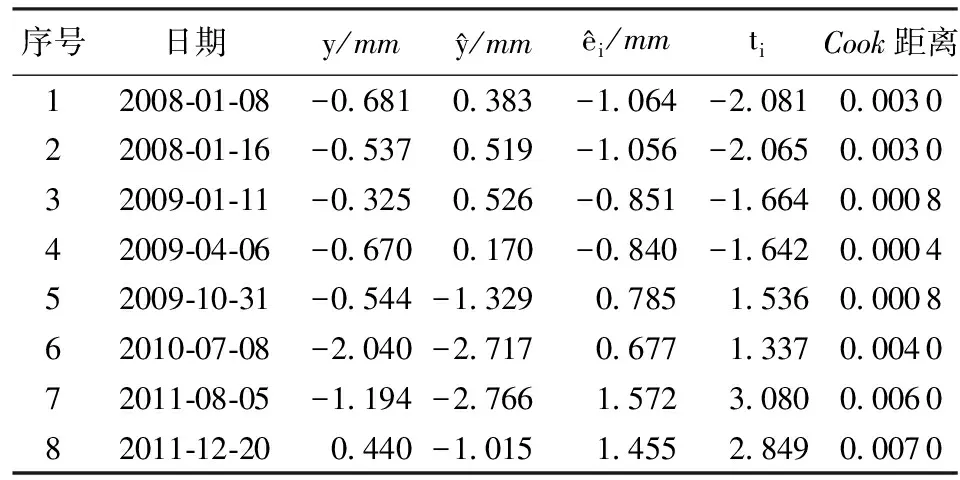
表1 部分数据异常情况的检验结果
如取α=0.05,由检验函数可得t0.95(1 634)=1.679。由此对数据检验结果进行评判,将ti绝对值大于上述临界值的数据判断为粗差。对第一次检验粗差剔除后的数据再重新建模检验,直到剩余数据满足t检验(2012年系统误差数据暂不处理),由此共删除粗差13个,删除率0.8%。
按照式(3)~(6)对模型拟合效果进行计算分析,实测值、拟合值过程线如图3所示。删除粗差后,模型拟合精度与原始数据精度相比有所提高,复相关系数R从0.904提高到0.912,剩余标准差S从0.512降低到0.468,说明了统计诊断识别粗差的有效性。
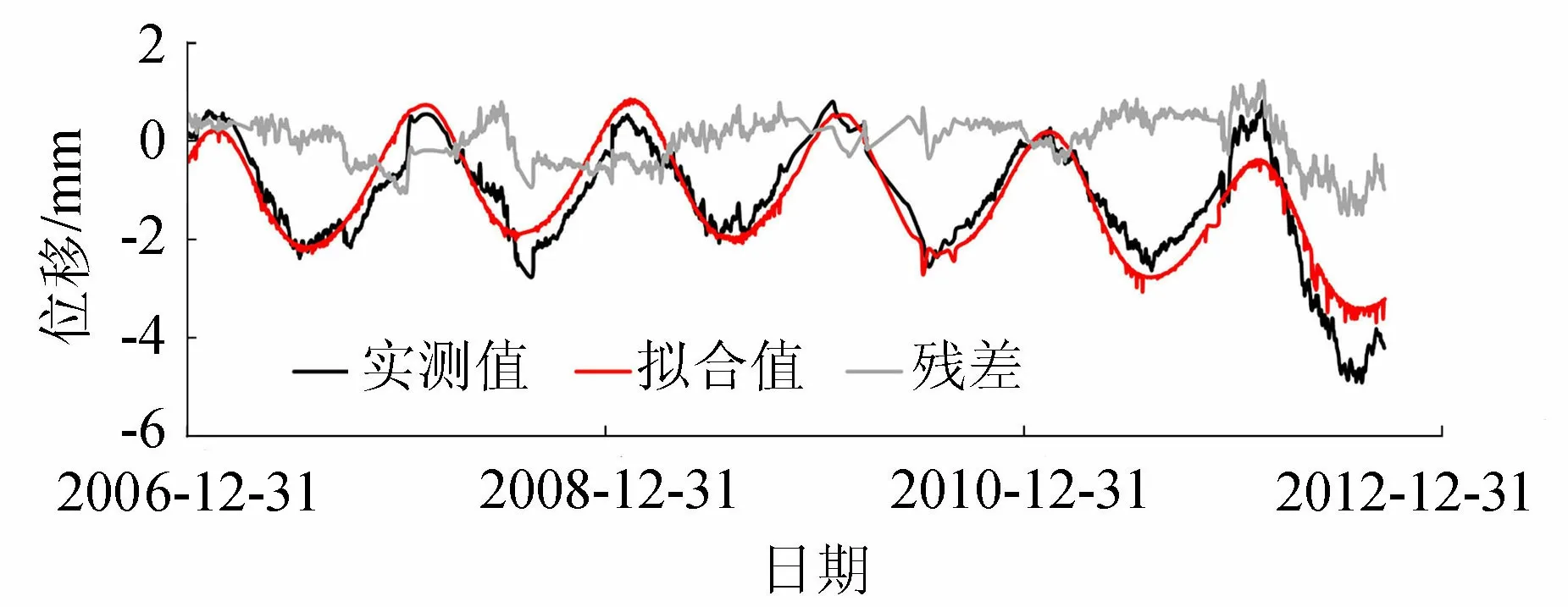
图3 测点实测值、拟合值及残差过程线
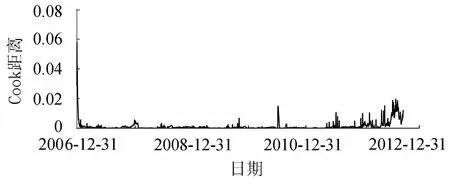
图4 各测值Cook距离计算值过程线
删除粗差后各测值的Cook距离如图4所示。可以看出2012年后的Cook距离计算值较大,与该时段存在系统误差数据的原因相符。监测资料的初始阶段Cook距离计算值也较大,说明初始阶段测值对建模的影响较大,应尽量减少该时段的观测误差。而在运行期,Cook距离计算值较大区域一般出现在每年的七八月份,该时期受强降雨影响,水库水位变动较大,计算值较好地反映了环境变化对大坝位移的影响。
5 结 语
a. 对大坝安全监测的异常数据分类进行分析,结合误差数据形成原因的不同,划分为随机误差、粗差、系统误差等,并辨识强影响数据。
b. 基于统计诊断的均值漂移模型,研究了不同异常数据的处理方法,包括以模型扰动值为依据的粗差的t检验法和以模型扰动对拟合参数的影响为依据的强影响数据的Cook距离检验法。
c. 以典型大坝的位移自动化监测数据为例,采用本文统计诊断方法对监测数据进行了合理性检验,结果表明该方法可有效辨识粗差和强影响数据,能提高数据建模拟合的精度和进一步分析的准确性。
