求解大规模TSP问题的带导向信息素蚁群算法
2018-10-09顾竞豪王晓丹
顾竞豪,王晓丹,贾 琪
(空军工程大学防空反导学院,西安 710051)
0 引言
蚁群算法具有鲁棒性强、简单易行、易与其他方法融合的优点,在解决TSP问题中得到广泛应用[1-2],但在处理大规模数据时,存在时间、空间复杂性大,搜索过程导向性不强等问题。文献[3]采用并行计算策略,减缓计算复杂度过高的不足,并提出了一种自适应的信息交换方式,防止算法陷入局部最优,但搜索策略未考虑全局信息,搜索过程导向性不强;文献[4]引入C-均值法和近邻函数法划分问题规模,减少了算法时间复杂性;文献[5]使用GPU并行运算同时优化数据存储方式,极大地减少了算法运行时间,实验结果表明,算法准确性有待提升。
针对以上问题,本文提出具有导向信息素的蚁群算法(Ant Colony Algorithm With Oriented Pheromones,OPACA),OPACA 算法以蚁群系统[6](Ant Colony System,ACS)为基础算法融入了3个改进策略,分别是:1)采用稀疏矩阵存储信息素表,在蚂蚁路径选择时可有效减少算法时间复杂度,同时节省存储空间;2)利用自适应密度聚类算法获取全局导向信息,使算法在初期便能朝最优解方向收敛;3)改进状态转移规则,并采用2-opt局部搜索策略,加速算法迭代时间与提升算法的与准确率。算法分两步进行,首先通过聚类求解出“骨干网络”并以导向信息素形式体现,后利用改进的状态转移策略及2-opt策略的蚁群系统求解原问题。
1 蚁群系统原理
OPACA算法采用蚁群系统作为基础算法。其中,Jk(i)表示从城市i可以直接到达的且又不在蚂蚁访问过的城市序列 Rk中的城市集合,η(i,j)是启发式信息,(i,j)是信息素浓度。
参数qo确定进行开发还是偏向搜索。当产生的随机数q>qo时,算法使用轮盘选择策略,式(2)是位于城市i的蚂蚁k选择城市j作为下一个访问对象的概率。
2 具有导向信息素的蚁群算法
OPACA算法为进一步提升蚁群系统在处理大规模TSP问题时的性能,在蚁群系统的基础上,通过采用稀疏矩阵简化运算,添加导向信息素及改进状态转移策略共3个方面的改进,使算法在减小问题复杂性的同时,有效引导算法朝全局最优方向进行搜索。
2.1 采用稀疏矩阵存储信息素表
传统蚁群算法中,信息素表以二维矩阵形式进行存储,算法时间复杂性随问题规模的增加而急剧上升。
通过对不同实例的解空间进行统计分析,发现对最优解中的每一个节点i为中心,作半径为R的圆,圆的半径R从零开始逐渐地增大,一直到取得节点i的近邻节点为止,记录下此时圆内的节点数目P,设Max(P)为实例中P的最大值,那么有如下统计结果如表1所示。
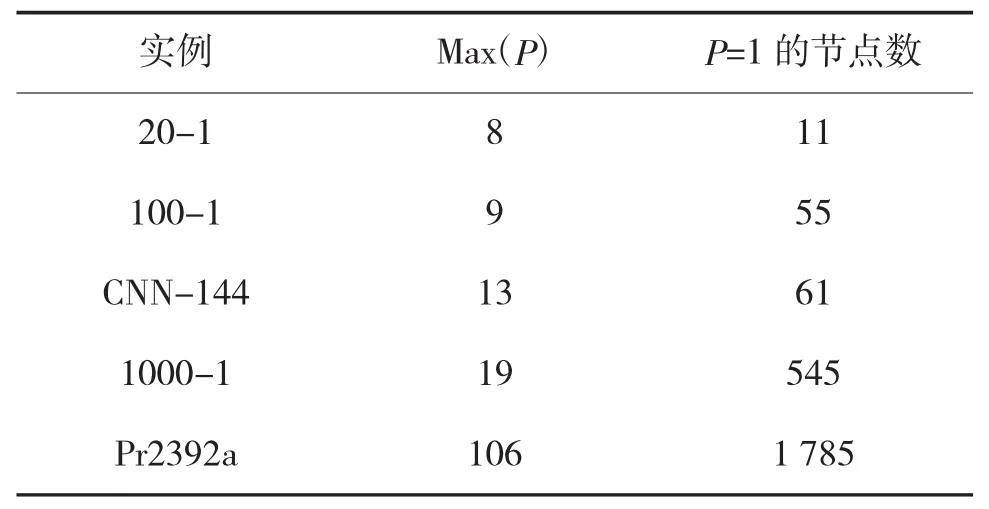
表1 最优值节点近邻数目
因此,无论实例规模大小,P=1的概率基本为50%以上,即对任一节点i,选择由i为起点的最短边的概率极大。在算法中通过限定节点选择范围,能将解空间范围由 n!缩小为 nmax(p)。
采用稀疏矩阵存储信息素信息,并规定稀疏信息素矩阵中每一节点的元素初始值为30,上限为50,即稀疏信息素表大小小于50×N,不会影响算法得到最优解的能力,而且能通过采用策略3中改进的状态转移策略简化运算提升效率。
2.2 自适应密度聚类算法获取全局导向信息
2.2.1 粗划分
从标准数据集中引入混合分布TSP实例a280。粗划分采用自适应密度聚类[7]的方法,该方法可以自动确定簇的数量,并能够发现任意形状的簇,算法将被稀疏部分隔开的稠密区域视为一簇,形成“省”的概念,称其为“巨型城市”。因此,粗划分可划分任意形状和大小的簇,且不受孤立点的影响。结果如图1所示。
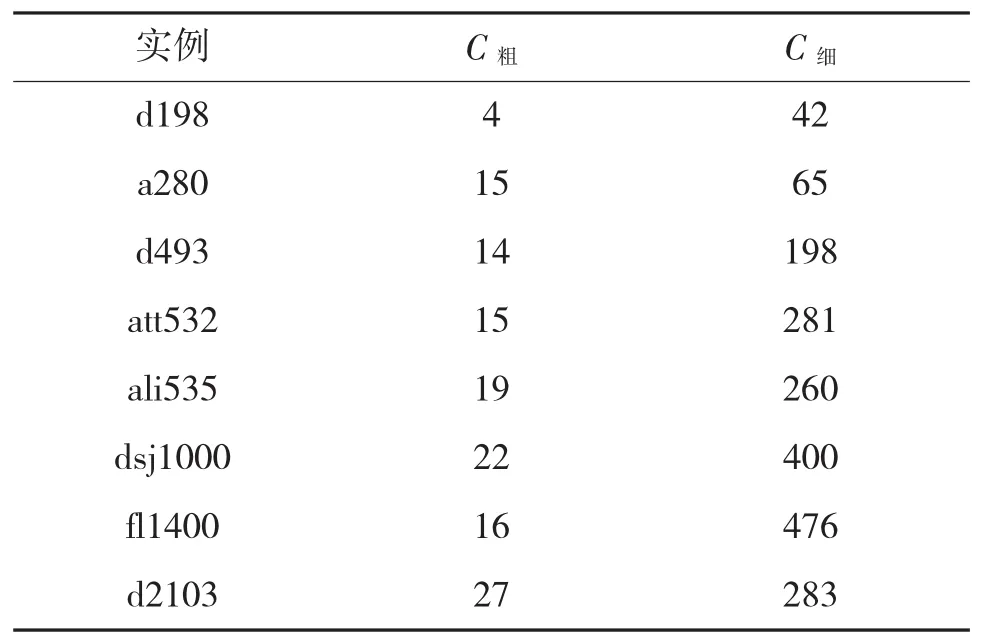
表2 粗、细划分结果对比
2.2.2 细划分
粗划分后,巨型城市此时区域密度连续且不可再划分,对节点数目超过200的实例进行仿真,结果如表2所示,C粗表示粗划分的实例分类数,C细表示细划分后实例分类数,实验表明粗划分不能有效划分原问题,有时会出现节点聚集的现象。为解决此问题,引入节点细化分进一步划分原问题。
细化分通过K近邻法(KNN,K-Nearest Neighbor)实现,指定城市上限,将巨型城市划分形成若干城市集合。对a280实例细化分,并用改进的蚁群系统求解初始路径。
在自适应密度聚类算法中,KNN不方便自动确定聚类数目,通过改用自适应的DBSCAN[8]算法,通过分析节点之间的最大最小间隔,自适应得到E领域大小,从而确定聚类数目。
在确定聚类数目后,各簇的连接规则通过蚁群算法完成,首先计算各个簇的中心点坐标,然后将中心点坐标带入原蚁群算法进行运算得到初始路径,最后以初始路径作为粗划分后各簇的最优连接顺序,供下一步运算使用。
2.2.3 建立导向信息素浓度矩阵
在获取城市集合最优连接顺序后,开始初始化导向信息素浓度矩阵,初始化方法如式(4)所示,其中|m-n|表示在最优路径中的序列编号差,Length代表初始化路径总长度,N为问题规模。
式(4)的物理意义:在求解出各簇的最优连接顺序后,需要通过建立导向信息素浓度矩阵来指导算法在一定程度上按照该顺序进行连接和遍历,为此,根据最优连接顺序,依次在粗划分连接顺序的前后节点上赋予不同簇之间的浓度值,使算法偏向于在相邻簇之间寻找最优遍历点。
考虑利用问题的局部性简化运算,配合策略1应用于算法中,导向信息素浓度矩阵也利用稀疏矩阵的方式存储,并规定稀疏信息素矩阵中每一节点的元素上限为50。
2.3 策略3,改进状态转移规则
建立候选集合Vi,将节点i所有访问过的下一节点序号加入集合Vi中,下次遍历时优先考虑集合中的元素。当且仅当Vi中所有节点都不满足条件时,遍历所有节点。
在蚂蚁每次完成迭代后,采用2-opt策略,进一步提升算法准确率。
Vi作为限制条件,并加入导向信息素后,新的状态转移规则如式(5)所示。
OPACA算法具体步骤如下所示:
Step1 城市总数为N,用自适应密度聚类算法进行粗划分,设得到巨型城市G个,孤立城市L个;
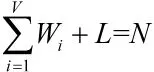
Step3求出城市集合的中心城市C(ii=1,2,…,V),中心城市可以不是TSP问题中的城市,将孤立城市与城市集合合并成新TSP问题,利用基本蚁群算法计算最优连接路径M(jj=1,2,…,V+L);
Step4 按照连接顺序,求解出边界城市,并根据边界城市初始化城市集合内最短连接顺序。此时,对城市集合为最优路径下的边界城市,表示除去边界城市后所剩普通城市的连接顺序,最优全局路径作为算法初始化路径;
Step5 利用Step4中的初始路径初始化改进的蚁群系统,完成稀疏信息素矩阵与稀疏导向信息素矩阵的建立,确定参数及蚂蚁数目,开始迭代;
Step6 判断是否到达最大迭代代数或停止条件,若达到则算法结束,停止迭代,返回最优解,否则进行下一步;
Step7 判断所有蚂蚁是否均完成所有节点的遍历,若完成,迭代次数加1,返回Step6,否则进行下一步;
Step8 判断当前蚂蚁是否遍历完成所有节点,若完成,代表蚂蚁完成个数的临时变量加1,并利用2-opt策略,改进当前结果,取最优值,并进入下一步;若未完成,利用改进的状态转移规则,寻找下一节点,而后继续执行Step8;
Step9 利用新的稀疏信息素表更新方式,更新全局信息素信息,完成后返回Step7。
3 实验结果
实验环境采用Matlab 2016a,在内存为8G,Inter(R)i7-4790 3.60 GHz处理器的PC,选用标准TSP库[9]中实例完成对比实验。
3.1 参数设定
根据式(5),并由于本文所提导向信息素是以和原有信息素浓度相加后的结果作为两节点之间最终取值,因此,在数量级上因保持不变,所以选定α 为 1、β 为 2。
对蚁群系统,通过实验对比[6]当α为1、β为2、qo为0.9时性能最佳。为保证算法最大性能,参数ρ与 ξ(ρ,ξ∈(0,1))的设置需要通过实验得出,取 TSP数据库中 4 个典型实例 a280、d657、pr1002、pr2392,初始时将 ρ与 ξ设置为 0.1,令步长 Δρ=0.1,Δξ=0.1,每个取值计算得到的最优路径(COST)10次,结果取平均值。结果如图2所示,Z轴表示最短路径长度,实验表明,算法中,当ρ与ξ分别取值为0.1与0.7时性能最佳。
3.2 3个策略有效性实验
将OPACA算法与标准蚁群系统进行对比,参数设置如如表3所示。
实验表明,3个策略在处理大规模问题时对OPACA算法性能的提升均有帮助:策略1在效率上缩小了算法迭代的时间,当规模增大时将算法终止时间缩短了2倍以上,采用稀疏矩阵对算法结果准确性的影响几乎可以忽略;策略2略微增加了算法运行时间,在处理大规模问题时准确性提升了5至10倍,导向信息素的加入使蚂蚁在初期就能进入寻找全局最优的过程中去;策略3的局部搜索策略提升了算法寻找全局最优解的能力,同时提升了算法的稳定性使其更易朝最优路径中收敛,结果如图3、图4所示。
3.3 对比实验
将OPACA算法与蚁群算法的改进版本TSIA-CO[10]、MMAS[11]、ESACO[7]、CPACA[4]及 ACS[6]进行对比,参数设置如表3所示,规定终止迭代次数为1 000代,蚂蚁数量10只。各算法均运行10次,统计算法停止时所得最优路径的方差与平均值,结果如图5及表4所示,实验表明OPACA算法在处理大规模问题时,相比同类改进算法性能更优且稳定性好。
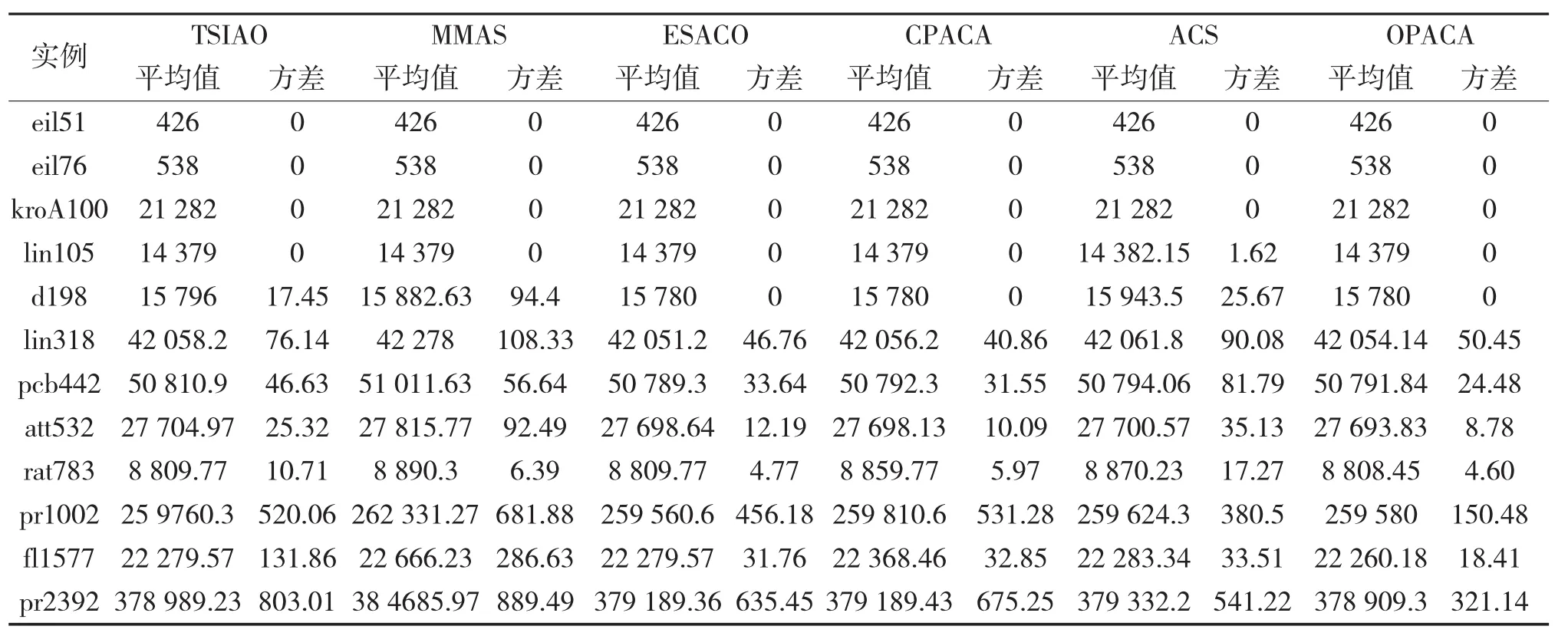
表4 不同实例下算法平均值与方差
4 结论
本文分析蚁群算法在求解大规模TSP问题时关键点,给出了3个改进策略,提出了OPACA算法,OPACA算法在蚁群系统的基础上通过采用稀疏矩阵简化运算,聚类算法产生导向信息素及改进状态转移策略共有3个方面的改进,在减小问题复杂性的同时,有效引导算法朝全局最优方向进行搜索,稳定性高,克服了基本蚁群算法在解决大规模问题时,存在的易停滞在局部最优导致准确率低、收敛时间过长、最优解偏差较大等问题。最后,采用标准TSP数据库,对3个改进策略及同类算法分别进行对比实验,通过实验验证了算法性能,结果表明OPACA算法性能更佳,实现了针对大规模TSP问题的优化,有利于蚁群算法的应用与推广。
