失配性疾病预防档案数据库的构建
2018-09-28赵玮曾奇陈心恬
文 / 赵玮 曾奇 陈心恬
失配性疾病是美国哈佛大学人类进化生物学教授丹尼尔·利伯曼提出的关于非传染性的慢性疾病概念。应该说,现代人体与现代环境的不匹配造成了“失配性疾病”的产生。它主要有两种,即“能量太多”造成的疾病和“用进废退”造成的疾病。因能量太多导致的疾病主要有糖尿病、脑卒中、高血压、高血脂、心脑血管疾病等;因用进废退造成的疾病主要有骨质疏松、肩颈下背痛、关节炎、风湿、心肺功能低下。[1]产生这些疾病的主要原因是文化快速进化和生活方式的快速转变。这些疾病随着人类文化及生活方式的飞速变化,范围在不断扩大,患病几率在不断升高,并逐渐呈现年轻化,死亡人数也在逐年增多。它给病患者及家属造成巨大的痛苦和沉重的经济负担。它不仅降低了家庭幸福指数,也给社会带来沉重的压力,因此致贫返贫的现象已经成为社会扶贫攻坚的重点。我们必须采取多种手段,利用多种渠道进行预防和遏止。
一、失配性疾病预防数据库构建的资源现状
失配性疾病预防数据库资源经历了多年发展、累积和沉淀,不同种类的失配性疾病预防文献已经相当丰富。众多医学工作者特别关注这类疾病的发生发展及它们的严重危害性,如北京大学人民医院心血管疾病研究所专家胡大一提出,弥合临床医学与公共卫生/预防医学的裂痕及如何不失配的对策。北京大学第一医院郭晓蕙教授,中国工程院院士、中华预防医学会会长王陇德等强烈呼吁要防治慢性疾病,[2]还有不少的失配性疾病临床专家对不同类型的疾病预防发表了自己的见解,积累了很多成功的预防经验。这些经验为失配性疾病深化的研究及预防数据库建库的深化研究提供了非常有价值的资源。尽管他们对各种失配性疾病的预防起到了积极作用,但是预防数据资源相对零散,医者大多是站在某一角度针对某一种疾病预防,没有形成深入系统的整合,没有产生全面完善的失配性疾病预防数据库。
基于众多见解和不同领域专家预防的成功经验,本库将以失配性疾病预防基本理论指导下的方法与应用体系为主线,根据失配性疾病预防知识资源的内在联系性,构建针对不同慢性疾病而采取的立体式预防档案数据资源库,为今后的其它各类疾病预防库构建和知识服务研究做前期的基础性数据准备。
二、失配性疾病预防数据库的构建
数据库设计关乎系统功能实现度、稳定性、扩展性等多个方面的内容。[3]
(一) 失配性疾病预防数据库设计框架
根据失配性疾病框架,拟设定预防数据库表,注重表与表之间的内在联系性。本数据库的团队参考教科书和相关的分类方法,按不同的失配性疾病人群非常关心的预防知识,如膳食合理、身体活动、心理健康、未病养生、家居环境和减肥瘦身等,进行了有效编码、存入。结合相对成熟的预防具体实践应用,又把各类失配性疾病预防分为基本理论预防、方法预防、应用预防三大类。从理论、方法到应用三个层面组建预防知识的相关内容。其中基本理论预防主要是为预防对象提供预防思想和原则,预防方法和预防应用是预防理论的基础。预防方法主要是为预防对象提供不同层面失配性疾病的操作与指导方法。预防应用则提供不同阶段的疾病预防思路,是预防方法的应用范围。(见图1)。

图1 预防知识分类框架
(二)失配性疾病预防数据库形式内容设定
本数据库的建立主要是根据各类失配性疾病的不同特点及不同层面来设定相应的预防内容。它将各类非传染慢性疾病不同的预防基础知识、预防方法和预防应用关联在一起。因此,本数据库首先建立失配性疾病预防方法的各类数据表,据此分别建立预防理论表、疾病表、来源表、病证关联表,并根据预防知识分类和特点、疾病表及处理表中的数据(见表1)来进行失配性疾病数据库的不同字段设定。表1中二级知识分类、各种慢性疾病、证候、体质、来源、时节分别与相应的预防知识分类表、疾病表、病症关联表、体质表、来源表、时节相关联(见图2)。具体内容的加工和关系展示见图2。
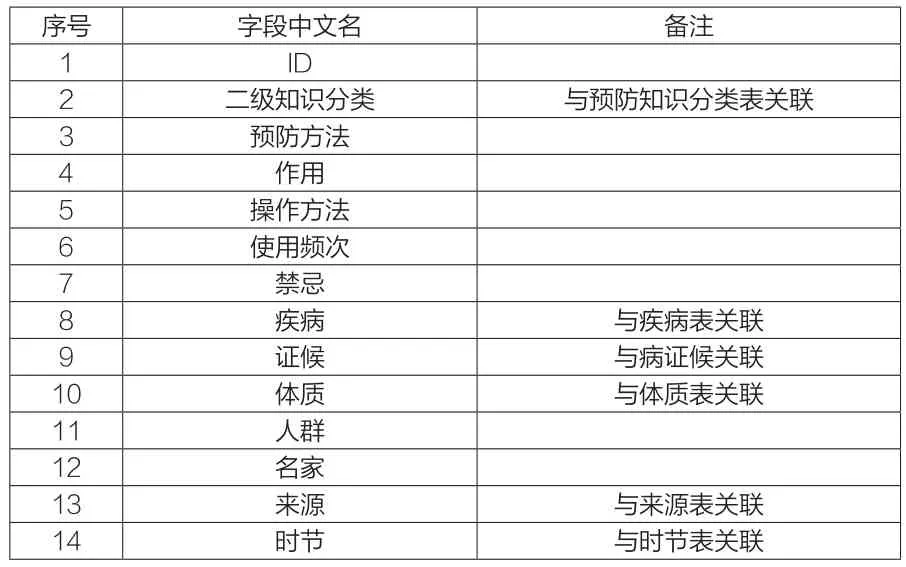
表1 预防方法
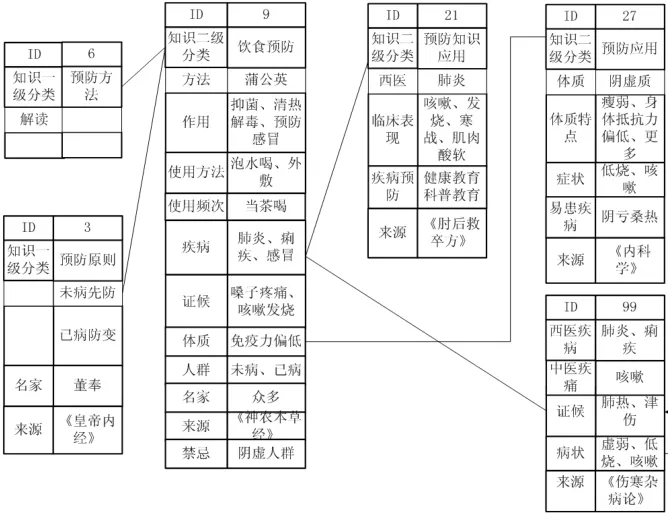
图2 失配性疾病预防数据库构建
(三)失配性疾病数据库功能设定
数据库是存储在计算机上、可共享、具有一定格式的数据集合。数据库中的数据具有多样性,如用户数据、数据字典以及数据存储路径等,通过数据库可以定义、存放和管理这些数据。失配性疾病数据库不仅可以实现数据库的基本功能,如数据库的定义、管理、维护,也可以实现对失配性疾病预防数据的操纵。也就是说,用户可以操作数据库内的数据,如进行数据的存储、查询、插入、修改与删除。此外,也能通过本库所建立的各数据表及表与表之间的关系数据,提取各字段内的所需要数据。本设定的宗旨就是要为用户提供方便快捷的最佳服务。
三、失配性疾病预防数据库构建的具体路径
(一)预防知识获取路径
近年来通过深入的研究已经为失配性疾病预防理论与预防实践积累了大量而丰富的档案资源。这些资源主要保存在失配性疾病书籍以及目前的临床研究文献中。为了获得较为全面的预防知识数据,研究利用大数据库进行文献采集,并将不同类型的失配性的预防思想、预防原则、预防方法等作为关键词,来获取指南或相关标准;利用教科书中所载、健康类报纸、预防类期刊和古籍等等获取文献资源,如从《黄帝内经》《周易》《诸新病源候论·时气病诸侯》等文献中获取。
(二) 预防知识采集
所收集的预防知识量大、数据较为复杂且不易处理,从这些数据中提取出满足要求的数据至关重要,数据库知识发现技术应运而生。数据库知识发现技术在数据处理过程中,会从大量数据中提取有效、可信、新颖且能被人们理解的模式。[4]在文献数据资源基础上,应用数据库知识发现技术梳理、筛选出预防内容相对具体而且比较具有权威性、原始真实清晰、涵盖面大、知识表达相对完整的知识片段。例如,对癌症疾病预防知识的采集,采用世界癌症研究基金会的对癌症预防总结的十四法:合理膳食、控制体重、坚持体育锻炼、多吃水果蔬菜、注意吃些谷类食物、限制饮酒、不过量吃红肉、少吃高脂肪食物、少吃盐、不吃在常温下存储过长的食物、用冷藏或保存方法易腐烂的食物、防止污染食品、不吃烧焦的食物、不过分依赖营养补充剂等预防知识。[5]
(三)预防数据加工处理
经过采集得到的数据往往不能完全满足结构化的处理要求,需要经过进一步严格处理,为后续数据组织入库奠定基础。在数据处理过程中,以常见的失配性疾病预防为主,建立失配性疾病相关的预防病典,规范处理相关知识,如对心脑血管疾病预防数据的加工,从建立预防高血脂、高血糖、血压高等病典开始,再根据数据依赖与规范化要求,对数据进行严格处理,主要是为后期对数据库字段内容进行调取做基础准备。
(四)预防数据审核
数据审核主要从准确性和完整性两个因素来考虑。其主要功能是在整理数据前对原始数据进行审查与核对。在采集加工数据过程中,大多包含了人为的主观因素,如在采集抑郁病档案数据过程中,采集者往往会根据自己的阅历与背景去主观地臆想,夹杂很多复杂不确定成份。为了保证数据的质量,尽管对数据进行了加工,也一定要根据建库的标准做进一步严格审核,以充分确认数据的规范性和科学性。
(五)预防数据入库
数据库与外部进行数据交换可以通过数据的导入与导出来实现。在数据入库过程中,以建立的数据表结构与数据表关系为基础,将Excel、Oracle等其它数据库中的数据转移到当前数据库中,并将失配性疾病预防数据进行保存、处理和审核。
四、结语
构建失配性疾病数据库,是以失配性疾病预防基本理论指导下的方法与应用体系为主线,根据实际需求,以实用性作为主要目标,以数据结构定义的简单性与完整性为侧重点,以便让用户高效地使用本库中的各项数据。失配性疾病数据库建设是非传染性慢性疾病相关知识理论体系趋于完善的基本组成部分,也是后期对失配性疾病知识存储、查询乃至服务与共享的基础。基于预防理论知识的失配性疾病数据库,可以对数据进行相对合理的存储及操纵,能够很好地为用户服务,成为今后的研究目标与发展趋势。本数据库的研究主要目标有两个:一要系统完善失配性疾病领域知识的概念表示,对失配性疾病预防知识进行合理组织,建设失配性疾病预防结构;二是以失配性疾病数据库为底层数据,以失配性预防结构为上层构架建立失配性疾病预防知识库,实现查询、关联预防知识以及知识发现。未来,将实现失配性疾病预防基础知识的信息化与数字化,可以通过手机终端或者网络平台等方式向用户提供慢性疾病预防基础知识,并进一步完善失配性疾病知识库的建设,最终实现失配性疾病知识的共享与知识服务。
