采用放松支配关系的高维多目标微分进化算法
2018-09-18申晓宁薛云勇
申晓宁,孙 毅,薛云勇
南京信息工程大学 信息控制学院,南京 210044
1 引言
近年来,多目标进化算法[1](Multi-Objective Evolutionary Algorithms,MOEA)已经取得了飞速的发展,在许多方面都已有广泛的应用。但现有的多目标进化算法一般是针对2到3个目标问题而设计。在现实生活中,随着研究问题的复杂度越来越高,优化目标的个数也不仅仅局限于2到3个,有时往往会达到4个甚至更多。当优化问题的目标个数达到4个及以上时,称这类优化问题为高维多目标优化问题[2](Many-Objective Optimization Problems,MaOPs)。随着目标维数的增加,传统多目标进化算法(MOEAs)的优化效果大大降低。主要原因有:(1)随着目标维数的增加,传统的Pareto支配关系难以区分出不同解之间的优劣,导致基于Pareto支配关系的多目标进化算法收敛性能下降;(2)随着目标维数的增加,传统多目标进化算法为了保证算法所得解集的多样性,采用的多样性保持机制通常偏好极端个体,这将进一步影响算法在高维多目标优化问题上的搜索能力。因此,如何针对高维多目标优化问题,设计出一种在收敛性能和多样性之间达到较好平衡的进化算法,成为进化计算领域的一个难点和热点问题。
目前所提出的高维多目标进化算法主要分为如下几类:(1)采用基于Pareto支配的方法,在该方法基础上结合其他有效方法以缩小搜索空间或降低目标维数。如在搜索过程中加入决策者的偏好信息以缩小Pareto前沿区域[3],Deb等人提出了基于主成分分析的目标缩减方法[4],并将其结合到NSGA_II[5]算法中。然而,该类方法只适用于能够预知偏好信息或目标主次的问题。与该方法类似,学者袁家伟提出了一种基于Simplex支配的方法[6]。该方法相比于Pareto支配的方法,其优点是远远提高了解的选择压力,缺点是缺少高效的机制用于维持群体的多样性。(2)采用放松的Pareto支配方法,使得原先无法两两比较优劣的非支配个体之间能够进行比较与选择。如优胜关系[7],改进的α-支配[8]等,该方法在一定程度上放宽了非支配个体之间的比较准则,增加了解的选择压力,但同时也降低了支配结果的合理性与可信性。(3)采用非Pareto的支配方法,该类方法采用新的评价准则对个体进行比较。目前该方法主要有两类,一类是基于聚合函数的方法,该方法使用聚合函数,将一个高维多目标优化问题分解成一系列单目标优化问题,典型的算法是MOEA/D[9]。另一类是基于评价指标的方法,该方法采用一个指标作为个体的适应度来评价个体,典型的算法是IBEA[10]。该方法能够解决基于Pareto支配所带来的问题,然而其合理性有待进一步验证,且在实际应用中还存在着计算复杂度高等问题。
微分进化算法是一种简单、高效和快速的演化算法,具有结构简单,易实现,精确度高、收敛速度快、鲁棒性强等优点[11]。它的控制参数少、便于学习、空间复杂度低、便于扩展,可以处理更大范围、更加重要的优化问题。因此,现在越来越多的学者开始将微分进化算法运用到高维优化问题中。王旭提出了一种解决高维优化问题的差分进化算法[12],将协同进化思想引入到差分进化领域,采用一种由状态观测器和随机分组策略组成的协同进化方案。该方案有效地增强了算法解决高维优化问题的搜索速度和能力。
为了进一步提高进化算法在求解MaOPs时的收敛性能和多样性,本文提出采用放松支配关系的高维多目标微分进化算法,简称RDMODE(differential evolution algorithm for many-objective using relaxed dominance relation)。在12组标准测试函数中的仿真对比结果表明了所提算法的有效性。
2 高维多目标优化问题的难点
假设求解具有m个目标的最小化问题,则多目标优化问题的数学模型可以描述如下:


其中,x为决策向量,y为目标向量,X为决策向量x形成的决策空间,Y为目标向量y形成的目标空间。gi(x)≤0,i=1,2,…,h为 x需满足的h个约束条件。当目标维数m≥4时,即为高维多目标优化问题MaOPs。
求解多目标优化问题时,最常采用的是基于Pareto支配关系的比较方法。设Xf为多目标优化的可行解集,F(x)=(f1(x),f2(x),…,fm(x))为目标向量,x1∈Xf,x2∈Xf。称 x1Pareto支配 x2(简称支配,记作 x1≺x2)当且仅当

在MaOPs的求解中存在如下难点:(1)随着目标维数的增加,如果仍采用常规的Pareto支配关系,将导致群体中非支配个体所占的比例迅速上升,个体间难以区分优劣,算法的选择压力过小,进化选择近似为随机选择而失去优胜劣汰的作用。(2)当优化目标大于3个时,算法得到的解集无法在传统的直角坐标系中表示出来,因而增加了可视化的难度,为决策者的最终选择制造了障碍。(3)目标维数的增加使得近似Pareto最优前沿解的个数剧增,不利于决策者在如此庞大的集合中,找出满足其需要的解。(4)当使用大规模的进化种群时,能够在一定程度上缓解因目标维数增加而导致的进化算法收敛性能的下降,也可能得到近似分布在整个最优前沿的解集,但随之而来的是空间复杂度和时间复杂度的剧增。
3 基于放松支配关系的高维多目标微分进化算法
3.1 rel-支配的放松Pareto支配关系
本文提出一种称为rel-支配的放松Pareto支配关系。假设求解高维多目标最小化问题,设x1和x2为MaOPs可行解集 Xf上两个不同的解,F(x)=(f1(x),f2(x),…,fm(x))为目标向量,称x1rel-支配x2当且仅当

其中,m为MaOPs中的目标个数。如果一个解x∈Xf不受Xf中任何其他解rel-支配,则称x为该问题中的rel非支配解。
由于目标维数越高,解之间越难进行比较,因此,所提rel-支配关系对Pareto支配关系的放松程度依据目标维数m的不同取值而作自适应调整,具体见图1所示。图1的纵坐标表示放松程度,该取值越小,说明rel-支配关系对Pareto支配关系的放松程度越大。当给定问题的目标维数m≤4时,此时两两解之间容易比较优劣,故纵坐标的取值接近于1,即rel-支配关系的放松程度很小;当m>4时,此时比较出两两解之间优劣的难度逐渐加大,故rel-支配关系的放松程度随m的增大而逐渐增大。由式(3)也可以看出,随着m的增大,(1-e-20/m)取值减小,即rel-Pareto的放松尺度增大。此外,式(3)未引入额外的参数,避免了ε-支配关系[13]中,参数ε需要事先手工确定的不足。

图1 rel-支配关系中解的放松程度随着目标个数变化的曲线
图2 给出了基于rel-支配关系比较两个解x1和x2的示意图。由图可见,如果基于Pareto支配关系,x1和x2互不支配,但如果采用放松后的rel-支配关系,使得解x1相对于解x2在目标 f1上的值由原来的大于关系变成小于,在目标 f2的值比原来更小,即经过rel-支配关系后,解x1由图中所看到的位置变成了解x′1在图中的位置,则此时解x1显然能够rel-支配解x2。
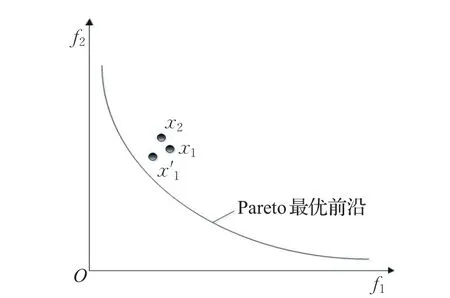
图2 基于rel-支配关系比较两个解x1和x2
综上所述,本文采用rel-支配关系能够更加有效地区分出个体之间的优劣,增加选择压力,以改进常规Pareto支配关系带来的群体中非支配解过多的不足,将其运用到高维多目标微分进化算法中,能够更加有效地引导算法的搜索方向,从而提高算法的搜索效率。
3.2 群体与外部存储器的协同进化
所提算法RDMODE采用一个群体POP和一个外部存储器Archive协同进化的策略。Archive中保存由历代群体搜索到的rel非支配解。在Archive中精英个体染色体信息的指导下,对POP分别采用两种变异方式,生成子代群体。利用生成的子代群体,采用基于指标的方法更新POP使得POP能够较快地向问题真实的Pareto前沿收敛;将子代群体搜索到的rel非支配解对Archive更新,并采用基于Lp-范数距离的多样性维护策略裁剪Archive,使得Archive的规模不超过预先设定的大小,并保持良好的多样性。POP和Archive相互辅助、相互促进,共同推动算法在收敛性和多样性之间维持平衡。
在子代群体生成的过程中,首先对POP采用DE/rand/2变异策略和二项式交叉策略,生成子代群体NPOP1。因为该策略采用随机搜索方式,有利于算法探索到更多的解,提高算法的多样性。DE/rand/2变异策略和二项式交叉策略的表达式分别如式(4)和式(5)所示:

其中,变异策略DE/rand/2中的3个随机个体 xr1、xr3、xr5取自POP,另两个 xr4、xr2取自Archive,,以充分利用Archive中个体的优良遗传特性,并且增强所生成子代个体的多样性。变异因子F是区间[0.8,0.9]内均匀产生的随机数,Vi是经过变异后得到的中间个体,randj[ ]0,1 为[0,1]之间满足均匀分布的随机数。当randj[ ]0,1小于等于给定的交叉概率CR或 j=jrand(Vi,j为中间个体Vi的第 j维,j=1,2,…,n,n为决策变量的维数,jrand为从{ }1,2,…,n中均匀随机产生的整数)时,将变异得到的中间个体Vi的第 j维作为子代个体Ui的第 j维,否则,将原来的父代个体xi第 j维作为子代个体Ui的第 j维。
对POP再采用DE/current-to-best/1变异策略和二项式交叉策略,生成子代群体NPOP2。该策略将群体POP中的当前个体作为初始个体,将外部存储器中的精英个体作为指导个体进行变异操作,有利于增加算法的收敛速度,避免陷入局部最优。式(6)给出了DE/current-to-best/1变异策略的表达式,二项式交叉策略表达式同式(5)。

其中,变异策略DE/current-to-best/1中的两个随机个体xr2、xr3和当前个体xi取自POP,xbest个体随机取自Archive,,变异因子 F1、F2是区间[0.8,0.9]内均匀产生的随机数,该策略生成子代群体的方式同上。
为了加强算法的收敛性能,采用基于指标的方法计算POP∪NPOP(NPOP=NPOP1∪NPOP2)中每个个体的适应度,并对群体进行更新,生成新一代群体POP。令Iε+表示一个指标,该指标描述了在目标空间中,一个解支配另一个解所需要的最小距离[10]。

根据这个指标为个体分配相应的适应值,式(8)给出了个体x1的适应值计算方法[14]:
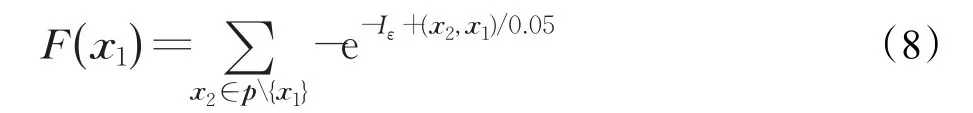
对群体进行更新时,将适应值小的个体依次从群体中移除,直到满足规定的群体规模为止。
在生成新的外部存储器的过程中,采用了基于Lp-范数(0 其中,d表示数据空间的维数,Lp(x,y)表示在d维数据空间中,向量(x1,x2,…,xd)与向量(y1,y2,…,yd)之间的Lp-范数距离。 当Archive中的个体数量超出规定的容量时,首先将Archive中在每个目标上具有最大/最小目标值的个体加入一个空的外部存储器Archive′中,然后每次从Archive中,选择距离Archive′中现有个体最短Lp-范数距离值最大的个体加入Archive′,如此反复直到Archive′中解的个数满足规定的容量为止。该策略能够有效地维护外部存储器中个体的多样性。 所提算法RDMODE详细步骤如下: 步骤1初始化。设置算法的最大目标评价次数为nmb_obj_max。随机产生一个规模为N的初始群体POP并计算其目标值,令目标评价次数计数器nmb_obj=N,规定nArchive为外部存储器最大保留个数,求出POP中的rel非支配解并将其存于Archive中。 步骤2繁殖操作。分别对POP利用不同的变异、交叉策略生成子代群体NPOP1和NPOP2。累计目标评价次数为表示集合中元素个数)。 步骤3求出子代中的rel非支配解。令NPOP=NPOP1∪NPOP2,求出NPOP中的rel非支配解。 步骤4更新与裁减POP和Archive。令POP=,若,则采用基于指标 Iε+的方式更新POP。确定出中的rel非支配解,并赋给Archive,若,则采用基于Lp-范数距离的多样性维护策略对Archive进行更新。 步骤5终止准则判断。如果目标评价次数nmb_obj达到对应问题的nmb_obj_max,则终止算法,把当前外部存储器Archive作为最终的满意解集输出,否则转到步骤2。 在MaOPs中,随着目标个数的不断增多,算法的计算复杂度也越来越大。采用一个含有m个目标,群体规模为N的多目标优化问题作为例子。所提算法RDMODE的计算复杂度主要包括以下几个方面:(1)从生成的子代群体中确定rel非支配解其复杂度为O(mN2);(2)采用基于指标的方式更新POP,它的复杂度为O(N2);(3)采用rel支配关系更新Archive,它在比较个体间支配关系时的复杂度为O(Nlg(m-2)N),在计算个体间的Lp-范数距离以维护多样性时的复杂度为O(mN2)。综上,该算法总的复杂度为max{O(Nlg(m-2)N),O(mN2)}。 为了验证所提算法RDMODE的有效性,将其用于DTLZ1和DTLZ2这两类目标可扩展的测试问题上[16]。本实验在DTLZ1和DTLZ2中,将目标个数m分别取为m=3,5,8,10,15,20。因此,实验中一共包括了12个不同的高维多目标测试函数。 Two_Arch2[14]是近年来涌现出的一种具有代表性的高维多目标进化算法。文献[14]将Two_Arch2与其他已有的高维多目标进化算法Two_Arch[17]、IBEA、NSGA_III[18]、MOEA/D进行比较,以测度IGD[19]作为评判标准,实验结果表明Two_Arch2在收敛性和分布性能方面均优于上述对比算法。NSGA_II[5]是一种经典的快速非支配排序多目标精英遗传算法,已成功应用于多种实际多目标优化问题中。将所提算法RDMODE与Two_Arch2、NSGA_II在4.1节中的测试函数上进行对比实验。所提算法的参数设置依据实验结果调试得到,算法Two_Arch2的参数设置参照文献[14],算法NSGA_II的参数设置参照文献[16],各算法参数具体设置见表1。 表1 3种算法的参数设置 为了体现算法比较的公平性,3种算法的终止准则均采用目标向量评价次数达到给定的最大值,最大目标向量评价次数对不同的测试问题,以及不同的目标个数m,取不同的值,参数具体设置见表2。 使用测度IGD、测度C_Metric[20]以及作图法,将RDMODE与Two_Arch2、NSGA_II进行比较。测度IGD描述了问题真实Pareto前沿中的个体到算法搜索到的解集中个体的平均最短距离,它的值越小,说明算法获得的解集收敛性和分布性越好,即越接近于真实的Pareto前沿。测度C_Metric度量两种算法搜索到的近似Pareto非支配解集间相互支配的程度,C(X1,X2)>C(X2,X1)表明集合X1在C测度上的性能优于X2。 表2 3种算法在测试函数上取不同目标时的最大目标评价次数设置 图3、图4分别给出了各算法在DTLZ1和DTLZ2,取m=3时,由100个解构成的Pareto前沿。由图4可以看出RDMODE和Two_Arch2均能收敛到真实的Pareto前沿,但所提算法RDMODE得到的解的分布性更好。从图5中可以看出,RDMODE和Two_Arch2算法无论是在收敛性上还是在分布性上效果都远比NSGA_II好。由此可见,在MaOPs中,仅靠Pareto支配排序已不能区分出个体的优劣。同时,个体选择压力的丢失也会导致分布性选择策略的失效。Li等人[21]的实验结果表明,NSGA_II中的拥挤距离策略甚至会在MaOPs上对群体的进化起到反作用。 将3种算法分别在12个测试函数上独立运行10次。表3给出了3种算法在测度C_Metric上的平均值和标准差。 从表3可以看出,所提算法RDMODE在12组测试函数中得到的C_Metric值,总体上显著优于其他两种算法得到的C_Metric值。在DTLZ1上,除了在目标个数为5时,算法Two_Arch2得到的C_Metric值较大外,其余情况下所提算法RDMODE均具有更大的C_Metric值,即有更高的支配比例;在DTLZ2中,当目标维数m取3或5时,Two_Arch2的C_Metric值更优于其余两种算法,随着目标维数的不断增加,所提算法RDMODE有最好的C_Metric值,尤其当目标维数m≥10时,所提算法得到的解集,能够支配Two_Arch2解集中解的比例较大,而Two_Arch2支配所提算法解集的比例为0;由于较差的收敛性,算法NSGA_II在所有测试函数中的C_Metric值最差。这也验证了在高维多目标优化问题中,所提算法RDMODE的收敛性总体上较其余两种算法的收敛性要好。 表4给出了3种算法在测度IGD上的平均值和标准差。 从表4可见,在DTLZ1中,当目标维数m取3、5、8时,所提算法RDMODE较Two_Arch2有更好的IGD平均值,其余情况下算法Two_Arch2的IGD平均值更好;在 DTLZ2中,当目标维数 m 取 3、5、8、10时,算法Two_Arch2优于RDMODE,有相对不错的IGD平均值,当目标维数m>10时,所提算法RDMODE得到的IGD平均值最好;由此可见,所提算法对于DTLZ1中目标个数相对较小的函数,能够取得较好的IGD性能,而对于DTLZ2却在目标个数较大时获得更优的IGD性能。由于NSGA_II的进化机制不能适应MaOPs的高维环境,它得到的IGD平均值在12个测试函数上依然最差。此外,所提算法RDMODE在绝大部分测试函数上得到的标准差均最小,表明了所提算法具有较稳定的搜索性能,在不同运行次数中得到数据集的IGD值变化幅度较小。 图3 3目标DTLZ1问题中Pareto前沿的比较 图4 3目标DTLZ2问题中Pareto前沿的比较 表3 两两算法在DTLZ1、DTLZ2上的C_Metric值 表4 各算法在DTLZ1、DTLZ2上的IGD值 由上述结果可见,所提算法RDMOEA是一种高效的高维多目标进化算法。在大部分测试函数,尤其在目标维数较高的函数上,得到的解集较已有的代表性高维算法Two_Arch2具有更好的收敛性和多样性。这主要归因于所提算法RDMOEA采用了一种新的放松支配关系,有效地增加了群体的选择压力,提高了算法的收敛速度;同时,所提算法RDMOEA采用群体和外部存储器协同进化的方式,由于外部存储器能够给群体的进化方向提供指导信息,而生成的子代群体采用基于指标的适应度评价机制更新进化群体和采用Lp-范数距离的多样性维护策略更新外部存储器,两者相互合作,共同促进,使得所提算法RDMOEA能够在收敛性和多样性之间维持较好的平衡。 本文提出了采用放松支配的高维多目标微分进化算法RDMOEA,该算法设计了一种rel支配关系放宽解的比较准则,该关系能够依据目标个数自适应地调整对Pareto支配的放松程度,且未引入额外的参数;采用群体和外部存储器协同进化的方案增加了算法的搜索速度和搜索效率,并使用混合微分进化算子搜索解空间。将所提算法RDMOEA和其余两种优秀的多目标进化算法在目标可扩展的标准测试函数集DTLZ1和DTLZ2上进行了对比,实验结果表明所提算法RDMOEA在求解MaOPs时,能够产生一组收敛性能和分布性能均较优的非支配解,从而表明算法所设计的策略是可行而有效的。今后的工作将进一步研究所提算法RDMOEA中参数的自适应控制方法,并将它应用于实际优化问题。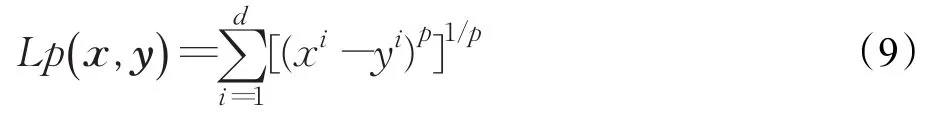
3.3 算法步骤
3.4 算法的计算复杂度
4 仿真实验
4.1 优化问题描述
4.2 参数设置

4.3 实验比较





5 结束语
