优化PSO-BP算法及其在校园网安全日志分类上的应用
2018-09-12梁师哲梁京章梁成国
◆梁师哲 梁京章 梁成国
优化PSO-BP算法及其在校园网安全日志分类上的应用
◆梁师哲 梁京章 梁成国
(广西大学计算机与电子信息学院 广西 530004)
伴随着传统教育步入大数据时代,高校对于大数据安全平台的部署和数据挖掘变得越来越广泛和深入。为了提高高校海量安全日志的识别分类准确率,预测网络攻击行为,避免高校校园网因网络攻击造成更多的损失,本文提出了一种改进的基于粒子群优化的BP(back propagation)神经网络强学习算法,用于校园网安全日志的分类,提取日志中的属性值作为BP神经网络的输入值,利用粒子群优化算法(PSO)初始化BP神经网络连接权值和阈值,结合Adaboost算法的思想将多个BP神经网络弱学习算法组合构建为一个强学习算法,并针对校园网海量日志存在的非平衡数据及算法本身等问题提出改进,设计基于Adaboost优化的PSO-BP算法的校园网安全日志分类模型。利用真实校园网安全日志数据进行验证,实验结果表明经过改进的算法可以提高BP弱学习算法的分类性能,适用于识别安全日志,预测攻击行为。
校园网;安全日志;PSO-BP;神经网络;Adaboost
0 引言
随着国家对网络安全宣传的逐渐重视,作为信息化建设的主体,高校网络安全问题逐渐成为建设的焦点问题。校园网对于网络攻击事件的安全防范通常都是以日志记录以及告警的形式输出数据,并管理控制潜在的风险,分析这些校园网安全日志是通过收集分析各种安全日志文件以识别出入侵和入侵企图,是网络安全防御系统的重要组成部分,在网络安全中起着重要作用[1]。在大数据时代,各高校部署的安全平台更趋于完善,对于海量安全日志的收集和分析手段更加丰富,人们对校园网的安全防范意识也逐渐加强。校园网的海量安全日志不仅记录了一段时期内针对校园网的攻击和试探行为,同时也蕴含了大量攻击行为的特征,这些特征和规律更值得我们关注、分析和挖掘。
数据挖掘技术是在海量数据环境中收集并分析数据的技术,目的是发现未知的关系和以数据拥有者可以理解并对其有价值的新颖方式来总结数据[2],又称为数据库中的知识发现(KDD),即从大量数据中提取或“挖掘知识”。针对日志文件的数据挖掘技术主要有统计分析[3,4]、序列模式分析[5,6]、关联规则[7,8]、分类和聚类[9,10]等。一般校园网日志的关键词有Web访问、流量信息、被屏蔽的网络访问、攻击、各种服务(Web、FTP、Email、VPN等)以及网关登录、维护信息等等[11],校园网安全日志分析是通过对校园网安全日志文件的数据进行统计分析,发现有关访问者连接的特征。上述方法中,统计分析方法虽能提高性能但无法对特征进行深层次的分析,序列模式更注重时间顺序上的数据项,更适用于Web日志的挖掘,关联规则和聚类方法则更关注于访问者的行为挖掘,因此针对于具有攻击行为的日志识别,这些方法都不适用。
本文采用机器学习中的神经网络分类算法对校园网安全日志进行分类识别预测。传统的BP神经网络学习采用梯度下降算法,通过学习得到的误差值反向传播调整整个网络的权值和阈值,因此合理的初始值会影响到整个算法的性能。为避免出现学习过程中易陷入局部最优解、泛化能力差等问题,本文采用基于粒子群优化的算法,通过神经网络学习的误差值找到使得群体适应度最小的粒子,利用该粒子的位置矢量设置神经网络最合适的初始权值和阈值;同时,结合Adaboost算法的思想,将优化后的BP神经网络作为弱学习算法,组合构建由多个BP神经网络输出的强学习算法,以提高对安全日志的识别准确率,使校园网安全日志的分类更加可靠。
1 PSO-BP算法
1.1 粒子群算法
粒子群算法(PSO算法),也称为粒子群优化算法或鸟群觅食算法(Particle Swarm Optimization),是由J. Kennedy和R. C. Eberhart[12]等于1995年提出并应用于函数优化的进化算法(Evolutionary Algorithm - EA)。PSO 算法和其他进化算法相似,通过随机初始化的粒子迭代进化寻找最优的位置矢量,并依据适应度来评价解的品质[13]。PSO算法基于粒子群体,采用实数求解,且需要调整的参数较少,通过追随当前搜索到的最优值来寻找全局最优,因此广泛应用于函数优化、神经网络和其他遗传算法等领域。
PSO算法通过将鸟的飞行空间看作为问题的解空间,将每只鸟的个体看作为一个粒子,粒子规模为N,每个粒子i在N维空间中都有其空间位置Xi=(x1,x2,⋯,xN)和速度Vi=(v1,v2,⋯,vN),并依据自己的飞行经验和群体全局的飞行经验动态地调整自己的飞行轨迹。每个粒子在进化中通过由目标函数决定的适应值(fitness value)知道自己目前位置的好坏。当每轮进化结束后,粒子可以知道自己能发现的最好位置(pbest),并通过更新全局获得粒子群全局最好的位置(gbest),这也决定了每个粒子在下一步进化中的飞行方向和粒子群总体的飞行方向:
vi=w*vi+c1*rand()*(pbest[i]-x[i])+c2*rand()*(gbest-x[i]) (1)
xi=xi+vi(2)
上式中粒子迭代寻找最优解,利用找到的最优位置pbest[i]和粒子群全局最优解gbest这两个极值来更新自己的速度和位置。其中,vi为粒子的速度,xi为粒子的位置,rand()产生0到1之间的随机数,w为惯性权重,c1和c2为学习因子。在进化迭代过程中,需根据实际需要为vi和xi指定范围。
1.2 BP神经网络
BP神经网络是人工神经网络的一种,它模拟人类大脑的神经元工作,是一种按照误差逆向传播算法训练的多层前馈神经网络[14]。因为BP神经网络有很强的非线性映射能力且结构相对简单,所以如今已被广泛应用于各行业的研究。三层BP神经网络如图1所示,即输入层、隐藏层(中间层)、输出层,各层之间的神经元实行全连接,同层内的神经元无连接,各层神经元的个数可以根据实际情况决定,其训练的效果也会因此有所不同。
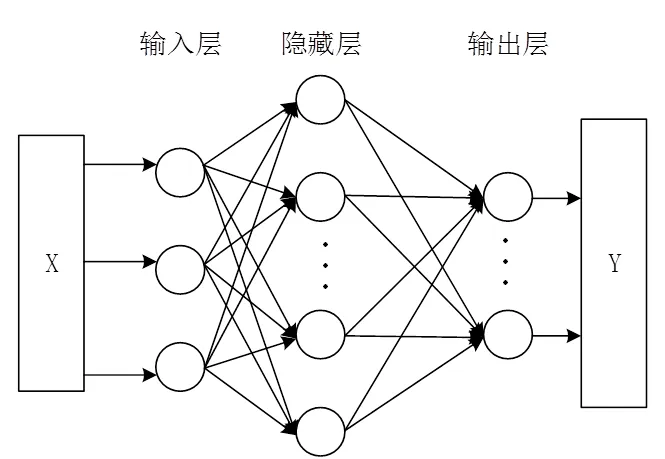
图1 BP神经网络结构
输入样本数据从网络输入节点向前传播后,分别经由隐藏层和输出层的线性函数作用和非线性函数的变换,最终从输出节点得到结果。如果输出的结果与训练结果预期有差别,则定义网络输出结果与期望输出的误差信号,并将误差信号逆向传播,反复修改每层网络的权值和节点的阈值,直到输出误差减小到一定的范围。
1.3 基于PSO优化的BP神经网络
BP神经网络虽然已得到成熟的应用,但也存在一些缺陷,其中最主要的就是学习速度慢,有时对于一个神经网络的多次训练也有可能得到较差的收敛效果。其次,BP神经网络采用误差反向传播来调整网络连接权值,也会陷入粒子寻优过程中局部最优解的问题,从而导致无法找到全局最优解,本文引入了基于PSO改进的算法以解决这个问题。基于PSO优化的BP神经网络算法步骤如下:
(1)处理数据。对训练数据进行预处理并归一化;
(2)确定参数。确定BP神经网络的结构以及PSO粒子的相关参数;
(3)初始化粒子。随机初始化粒子位置和速度;
(4)进化粒子。训练神经网络,将输出误差作为粒子的适应度,并得到该粒子的个体最优值和全局最优值;
(5)更新粒子。根据(1) (2)式更新粒子的位置和速度;
(6)判断是否大于迭代次数,如果大于,保存参数,进行步骤(7),否则跳转到步骤(4);
(7)赋值参数。将获得全局最优值的粒子的位置参数作为BP神经网络的权值和阈值;
(8)输出结果。对神经网络进行训练直至结束,输出分类结果。
上述步骤中,步骤(4)通过将适应度值设置为使用该组权值时的网络输出误差,在预设的迭代次数内搜索最优的网络权值,这样可以提高神经网络的学习速度,同时也有效避免了BP神经网络学习时陷入局部最优解的问题。
2 基于Adaboost改进的PSO-BP分类模型
2.1 Adaboost算法
AdaBoost算法是基于Boosting思想的机器学习算法[15],其基本思想是通过迭代寻找合适的弱学习算法,并将多个弱学习算法组合构建为一个强学习算法以减小学习误差。Hansen和Salamon[16]证明了组合多个BP神经网络训练后的输出可以提高算法的识别能力。
Adaboost算法主要是通过每次训练样本集的分类结果情况,以及之前总体分类的准确率,以确定每个训练样本的权值。将修改权值的新数据传送给下次迭代的学习算法进行训练,然后将每次训练得到的弱学习算法融合起来,组合构建成最后的强学习算法。Adaboost强学习算法的步骤如下:
a)选择数据。训练集中每个样本有一个权重D,也称为样本权重。α为弱学习算法的权重。对于样本的训练集{(xi,yi)}(i=1,2,…,N),初始化时设定每个样本数据的权重:
D1=(w1,1,w1,2,…,w1,N) (3)
w1,i=1/N,i=1,2,…,N (4)
b) 训练弱学习算法。利用h1弱学习算法对数据进行学习,学习后计算错误率:
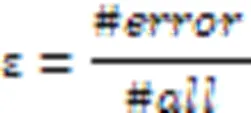
其中#error为错误分类数,#all为分类总数。
c) 计算序列权重。将错误率ε作为计算弱学习算法的权重的一部分:

d)训练数据权值更新。更新训练数据集的权值分布:

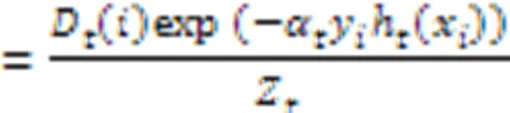
其中,Zt是归一化因子;
e)判断是否大于迭代次数,如果大于,进行步骤f),否则跳转到步骤b)继续训练弱学习算法;
f)强学习算法计算。经过t轮的学习后,得到t个弱学习算法{h1,h2,…,ht}及其权重{α1,α2,…,αt}。分别计算t个弱学习算法的输出{h1(X),h2(X),…,ht(X)},最终得到Adaboost算法的输出结果为:
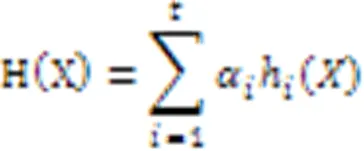
2.2 基于改进的PSO-BP的校园网安全日志分类模型设计
基于Adaboost算法原理对PSO-BP算法做出以下改进:针对BP权值初始化问题,采用先用PSO算法优化后得到效果较优的权值和阈值后再进行BP神经网络的初始化;并将PSO优化后的算法作为弱学习算法,结合AdaBoost算法进行多次弱学习算法训练,最终加权组合成强学习算法,以提高模型预测准确度。改进后的算法学习模型如图2。
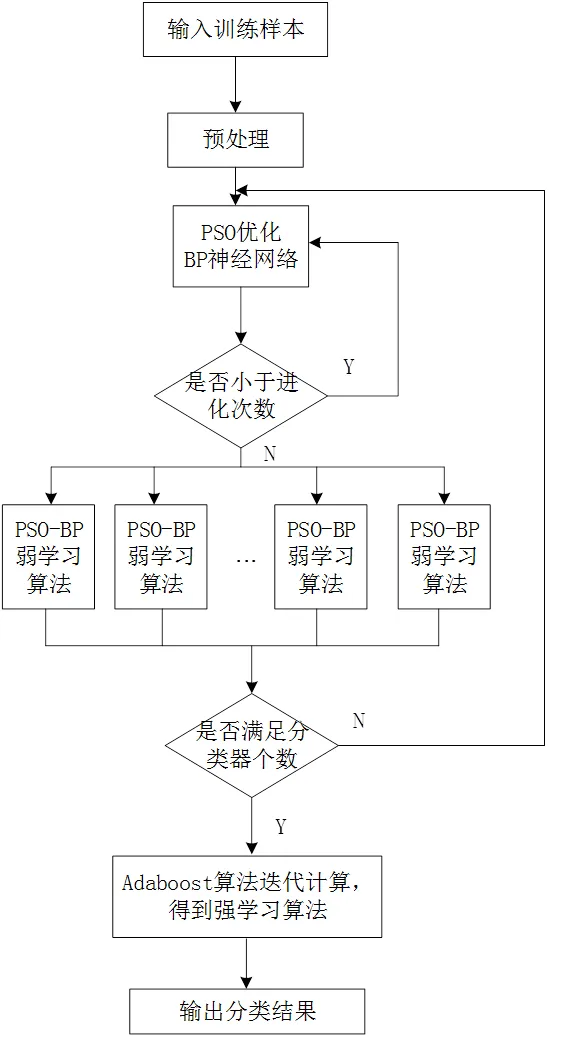
图2 改进的学习算法流程图
2.3 主要问题及改进
(1)由于校园网安全日志中多数记录了无攻击行为的正常访问数据,而记录攻击行为的日志占极少数,所以是非平衡数据集。非平衡数据集在普通的学习过程中会因分类器更加倾向于多数类数据而导致在稀有类数据上的分类效果很差[17]。针对这个问题,采用随机过抽样技术,通过将攻击日志数据随机复制样本集增加到非平衡数据集中,以获得更好的分类性能;
(2)虽然大多安全日志数据的属性值为标称型数据,都是合法数据且可以作为分类算法的输入值,但基于网络安全的常识,有的属性值如端口号、协议等存在多值问题,这些数值中大部分对于攻击行为的识别没有帮助,反而会降低学习的效率。因此需要依照经验预先设定阈值,清理这些无效的数据,保留阈值范围内的属性值;
(3)针对PSO优化的过程中易陷入局部最优解的问题,采用自适应变异的方法。在PSO算法分别中,两个学习因子分别控制粒子自身和粒子群全局这两个部分对粒子速度的影响。在粒子寻优过程中,我们希望算法初期能在整个粒子空间内搜索解,从而避免提前陷入局部最优解中,因此在进化过程中控制rand()的值,当rand()值大于阈值而使得粒子或全局部分的比重过大时,重新赋予粒子均匀的随机值。
3 实验及结果分析
本文采用Matlab R2016a软件,实验用计算机配置为Intel Core i7-4790 CPU,3.60GHz主频,8GB内存。
3.1 实验数据集
本文采用广西大学信息网络中心某一月份的校园网安全日志,约有300万条日志数据,其中约2000条记录了带有攻击的行为,将这些数据标识为安全日志和攻击日志两类,随机选取其中70%作为训练数据,30%作为测试数据。校园网日志文件包括时间、源地址、源端口、目的地址、目的端口、URL、MAC地址、协议等属性,将数据预处理后的属性值作为特征属性。
本文通过对单个弱BP神经网络学习算法、PSO-BP神经网络算法和改进后的强学习算法入手,对日志数据进行训练。从训练数据集中随机选取1500组数据用于训练,之后逐渐增加训练集的数量,利用验证集数据验证三种算法的分类准确率。通过将输入数据转换为数值的方式,将BP神经网络弱学习算法输入节点设为5个,输出节点设为2个,根据多次实验比较,将隐藏层节点数设为10个时分类效果最佳,同时采用梯度下降算法更新权值和阈值;设置粒子规模为30,最大进化次数为100次,惯性权重为0.5,学习因子c1和c2均为1.5;强学习算法使用5个相同BP神经网络弱学习算法组合。下表1为三种算法在10次不同数量验证集下分类的准确率。
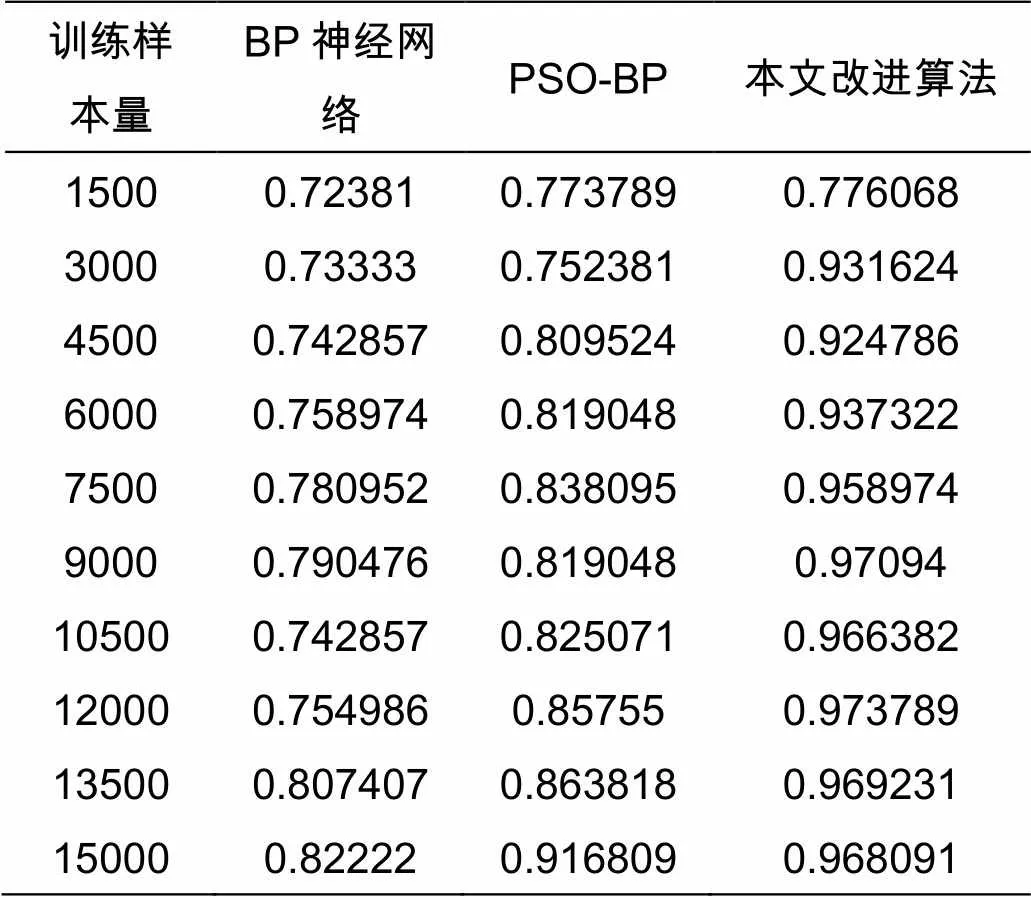
表1 三种算法的分类准确率
将表1映射到图3中,可知三种算法在训练集样本量很小的情况下分类效果并不理想,但随着样本规模的增大,PSO-BP神经网络算法的分类准确率明显大于BP神经网络的分类准确率,如图4即为PSO优化过程中适应度最优的个体的变化曲线,PSO算法使得BP神经网络多次跳出局部极小值;同时,改进后的强学习算法的分类准确率也明显大于其他两类算法;BP神经网络算法和PSO-BP算法的分类误差变化幅度较大,而改进后的强学习算法的分类误差较小且相对平稳。图5为改进后的强学习算法和单个弱BP神经网络学习算法分类准确率的差距,可见其准确率有较大提升,提升率达到5%~20%左右。
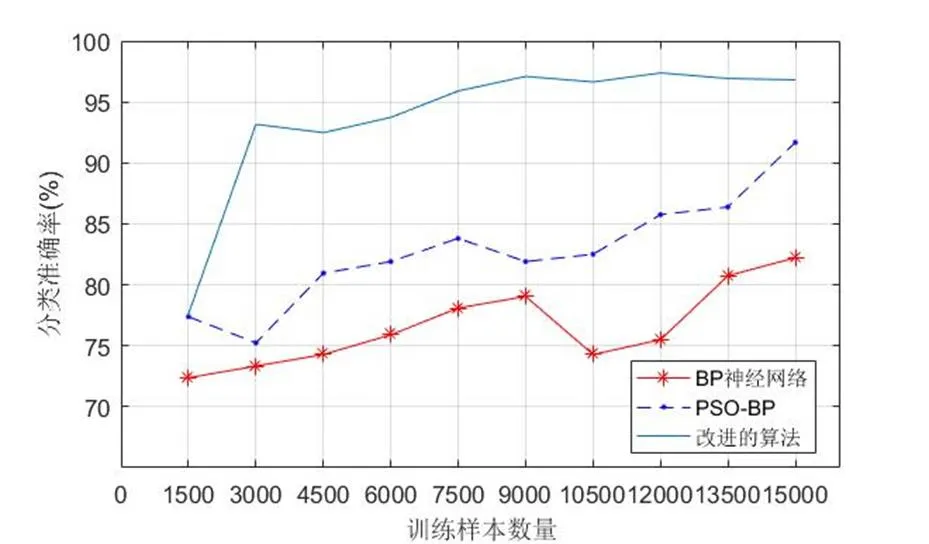
图3 三种算法的分类准确率
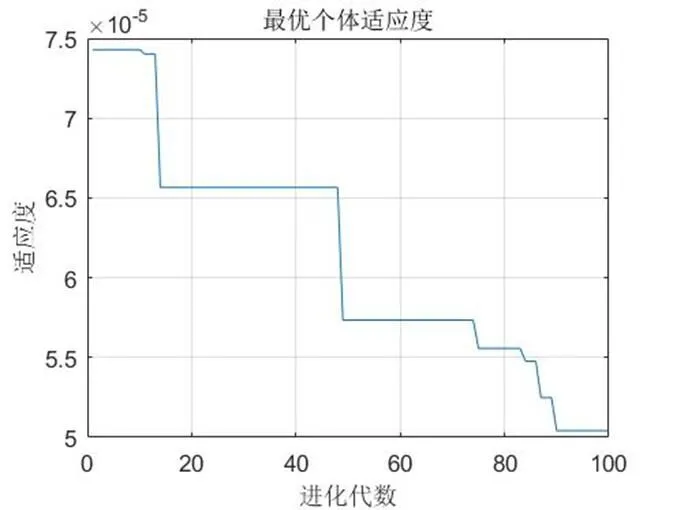
图4 每次迭代中最优粒子适应度

图5 强学习算法与弱BP学习算法效果的提升
综上分析,通过基于Adaboost改进的PSO-BP神经网络学习模型用于校园网日志识别更为合理,更加有效地提高了识别的泛化能力和可靠性。
4 结论
校园网安全问题已经逐渐成为高校建设的焦点问题,对大数据平台海量日志的分析和挖掘越来越有深刻的意义。对于如何提高校园网安全日志识别准确率,不仅需要对分类学习算法改进设计,还要对数据集本身进行合适特征选择和提取。本文提出一种基于Adaboost思想改进的PSO-BP强学习算法,并通过真实校园网安全日志的实验验证了改进后的算法具有良好的分类准确率,对于传统BP神经网络的分类效果有明显改善,能够更加有效地识别具有攻击行为的校园网安全日志,预测网络攻击。
[1]姜传菊.网络日志分析在网络安全中的作用[J].现代图书情报技术,2004.
[2]Hand D J, Smyth P, Mannila H. Principles of data mining[J]. Drug Safety, 2007.
[3]Osmar R. ZaÏane, Xin M, Han J. Discovering Web Access Patterns and Trends by Applying OLAP and Data Mining Technology on Web Logs[C]// Advances in Digital Libraries Conference. IEEE Computer Society, 1998.
[4]郭岩,白硕,杨志峰等.网络日志规模分析和用户兴趣挖掘[J].计算机学报,2005.
[5]Deshpande M, Karypis G. Selective Markov models for predicting Web page accesses[J]. Acm Transactions on Internet Technology, 2004.
[6]Sarukkai R R. Link prediction and path analysis using Markov chains 1[J]. Computer Networks, 2000.
[7]Liu B, Hsu W, Ma Y. Mining association rules with multiple minimum supports[C]// Proc. of the ACM SIGKDD Intl. Conference on Knowledge Discovery and Data Mining. 1999.
[8]Chen M S, Park J S, Yu P S. Data mining for path traversal patterns in a web environment[C]// International Conference on Distributed Computing Systems. IEEE Computer Society, 1996.
[9]陈泽红.基于Web访问日志的用户聚类研究[D].厦门大学,2014.
[10]邢东山,沈钧毅,宋擒豹.从Web日志中挖掘用户浏览偏爱路径[J].计算机学报, 2003.
[11]刘进军,张明勇.基于校园网日志数据挖掘系统的研究[J].滁州学院学报,2007.
[12]Kennedy J, Eberhart R. Particle swarm optimization[C]// IEEE International Conference on Neural Networks, 1995. Proceedings,1995.
[13]沈学利,张红岩,张纪锁.改进粒子群算法对BP神经网络的优化[J].计算机系统应用,2010.
[14]周志华.机器学习 : = Machine learning[M].清华大学出版社, 2016.
[15]曹莹,苗启广,刘家辰等.AdaBoost算法研究进展与展望[J].自动化学报,2013.
[16]Hansen L K, Salamon P. Neural network ensembles[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence,2002.
[17]职为梅,郭华平,范明等.非平衡数据集分类方法探讨[J].计算机科学,2012.
