Speech Resampling Detection Based on Inconsistency of Band Energy
2018-09-11ZhifengWangDiqunYanRangdingWangLiXiangandTingtingWu
Zhifeng Wang, Diqun Yan, , Rangding Wang, Li Xiang and Tingting Wu
Abstract: Speech resampling is a typical tempering behavior, which is often integrated into various speech forgeries, such as splicing, electronic disguising, quality faking and so on. By analyzing the principle of resampling, we found that, compared with natural speech, the inconsistency between the bandwidth of the resampled speech and its sampling ratio will be caused because the interpolation process in resampling is imperfect.Based on our observation, a new resampling detection algorithm based on the inconsistency of band energy is proposed. First, according to the sampling ratio of the suspected speech,a band-pass Butterworth filter is designed to filter out the residual signal. Then, the logarithmic ratio of band energy is calculated by the suspected speech and the filtered speech. Finally, with the logarithmic ratio, the resampled and original speech can be discriminated. The experimental results show that the proposed algorithm can effectively detect the resampling behavior under various conditions and is robust to MP3 compression.
Keywords: Resampling detection, logarithmic ratio, band energy, robustness.
1 Introduction
In the past decade, digital speech has become more and more prevalent in the daily life.Compared with texts and images [Xia, Xiong, Vasilakos et al. (2017)], speech conveys much more information. However, the easy accessibility of digital speech has led to significant security problems, which is how to examine the authenticity of digital speech and how to detect malicious tampering [Xia, Zhu, Sun et al. (2018)]. The rapid growth of speech editing techniques has increased both the ease with which speeches can be manipulated and the challenge in distinguishing between modified and natural speeches.Most of these editing techniques can provide lots of artistic and entertainment value.However, they can also be used for malicious purposes. For example, splicing techniques such as inserting and deleting [Shanableh (2013); Pan, Zhang and Lyu (2012)], usually modify part of the speech in order to change the meaning of the speech, while generative techniques such as synthesizing [Sharma and Mahadeva (2017); Heiga (2009)], replaying[Alegre, Janicki and Evans (2014)], electronic disguising [Wu, Wang and Huang (2014)],produce a meaningful speech by employing different mechanisms. Resampling, also named sample-rate conversion, is the process of changing the sampling rate of an original speech to obtain a new one. Most of the speech tampering operations such as splicing,electronic disguising, and quality faking are accompanied by resampling. For example, a forger may splice two speech segments with different sampling ratios. In order to make the sampling ratio of the whole spliced speech consistent, it is needed to resample the spliced speech with a specified sampling ratio. Additionally, resampling can also be used to generate fake-quality speech, which means that a speech with low sampling ratio is resampled with a high sampling ratio. One downloads speech from online by comparing sampling ratios of the files and pay different prices according to the quality of the speech.
Up to now, according to our best knowledge, few studies on identifying resampled speech have been reported. Most of existed resampling detection methods for digital speech are inspired from the methods for digital image. Alin et al. [Alin and Hany (2005)]found that the resampled image will have the periodicity of the peak in the spectrum and the periodicity can be approximated by the expectation maximization algorithm. Based on the method of Alin et al. [Alin and Hany (2005)], Yao et al. [Yao, Chai, Xuan et al.(2006)] proposed a resampling detection method for digital speech with statistical moments. However, the computational complexity is high and it is only suitable for linear resampling. Gallagher [Gallagher (2005)] found that if a second-order differential operation is made on the resampled image, there will be a periodic change in its variance.The experimental results show that this method can achieve a high detection rate and be used for detecting both linear and nonlinear resampling. Mahdian et al. [Mahdian and Saic (2008)] extended the method of Gallagher (2005) to K-order differential operation.Hou et al. [Hou, Wu and Zhang (2014)] proposed a resampling detection method for digital speech based on second-order differential operation. In addition to the above-mentioned methods, Ding et al. [Ding and Ping (2010)] found that resampling will suppress the high frequency component in digital speech, resulting in a relative smooth spectrum value in high frequency sub-band. Based on this observation, the spectral features with sub-band analysis are extracted to detect the resampling. However, this method is only effective for linear resampling.
Based on the existing research, the effect of resampling on the original speech is studied in this work. We found that the spectrum bandwidth of the speech is changed obviously after resampling. Then, a resampling detection method based on the inconsistency of the bandwidth and the sampling ratio is proposed. In order to make the statistical classification stable and effective, we propose the bandwidth energy logarithm ratio of this statistic. The logarithmic ratio of bandwidth energy before and after resampling is used to determine whether the speech signal is resampling. The experimental results show that the method has good detection effect and strong robustness against MP3 compression.
The rest of this paper is organized as follows. In Section 2, we briefly introduce the principle of resampling. In Section 3, we study the resampling effect on spectrogram, in order to briefly explain the reasons for using such band energy features. Then we proposed an algorithm to identify the resampled speech. In Section 4, a series of experimental results based on two datasets two resampling methods are taken into consideration. Finally, in Section 5, we give the conclusion of this paper and future work.
2 Review of resampling
Resampling is a necessary process for the scenarios that require different sampling rates.A typical example is the transfer of audio on a compact disc, which has a sampling rate of 44.1 kHz to a digital audio tape, which uses a sampling frequency of 48 kHz or vice versa.Several resampling techniques have been proposed in the literature [Gordon, Salmond and Smith (1993); Li, Sattar andSun (2012)]. The basic operations of resampling are interpolation and decimation. Let enote the speech signal withsamples.is the resulting signal resampled by a factor ofand its total number isfollowing equation, we will have an interpolated signal

Different types of resampling methods (e.g. liner, cubic) differ in the form of the interpolation filter. More details about resampling can be found in Gutta et al. [Gutta,Praneeth and Chandra (2016)].
3 Detection of resampled speech
3.1 Effect of resampling on power spectral density
Since the original signal is always assumed to be band limited to half the sampling rate,Nyquist-Shannon sampling theorem tells that the signal can be exactly and uniquely reconstructed for all time from its samples by band limited interpolation. As discussed in Section 2, during the up-sampling process in the resampling, some zero values are added between the original samples and then the interpolation filter is applied to ensure smooth transitions, which makes the speech signal more natural. Depending on the sampling theorem, the sampling ratio should be two times of the bandwidth of the signal, thus,increasing the sampling rate also increases the theoretical bandwidth. However, the power spectral density of the extended band should be equal to the power spectral density of the quantization error, or eventually to a residual signal depending on the frequency response of the interpolation filter. That indicates that the power spectral density of the resampled speech will be smaller than that of the original speech.
As an illustration, the spectrograms of the original speech, its down-sampling (is 1/2) and up-sampling (is 2) versions are shown in Figs. 1(a), 1(b) and 1(c). The original speech is randomly selected from TIMIT dataset which is WAV, 16 KHz sampling ratio, 16-bit quantization and mono. In this case, the original speech is first down-sampled from 16 KHz to 8 KHz and then the down-sampled speech is up-sampled from 8 KHz to 16 KHz. From Fig. 1(b), it can be seen that the full frequency range of 4 KHz energy is used in the down-sampled speech. Meanwhile, it should be noted that the 8 KHz energy in the up-sampled speech (Fig. 1(c)) is not fully utilized. The bandwidth of the up-sampled speech is limited to 4 KHz because it is obtained from the 8 KHz down-sampled speech. That means once the speech is resampled, the consistency between the bandwidth and the sampling ratio is not able to be kept. Fig. 1 presents the expected differences and supports our analysis above. Therefore, it is possible to distinguish whether the suspected speech is resampled or not by checking the abnormality of the bandwidth.

Figure 1: Spectrogram (a) Original speech at 16 KHz (b) Down-sampled speech at 8 KHz (c) Up-sampled speech at 16 KHz
3.2 Algorithm for detecting resampled speech
By exploiting the inconsistency of band energy and sampling rate, we proposed the algorithm to detect resampled speech. Suppose that the suspected speech isFirstly, the sampling rateis first extracted by parsing the header information of the suspected speech file. Then, for the speech signal, a six-order bandpass Butterworth filter is used to filter out the residual signalabove the specific frequency. The frequency response of the bandpass filter is,


frequencies of the designed filter, respectively. In this work, the values ofare determined by,


Table 1: Parameter settings for Butterworth filter (kHz)

As analyzed in Section 3.1, once the speech is resampled, the abnormality on the power spectral density will be caused. To capture the abnormality, the average short-time energy,which offers a simple way to exhibit high variationsuccessive speech frames, is selected as the feature. The short-time energy for theframe is calculated by,

Generally, energy is normalized by dividing it withto remove the dependency on the frame length. Therefore, Eq. 10 becomes,

Therefore, the average short-time energy ofis given by,

Similarly, the average short-time energy of the filtered residual speechcan also be calculated by,

Considering on the large range of the short-time energy, the logarithmic ratio of theandis calculated via Eq. 13,

At this point, for the original speech, the value ofshould be very small because the bandwidth of the speech is not limited. On the contrary, the value ofwould become large once the speech is resampled. The overall block diagram of the detection algorithm is shown in Fig. 2.

Figure 2: Block diagram of the proposed detection algorithm
4 Experimental results
4.1 Experiment setup
TIMIT and UME-ERJ (UME) are adopted as speech databases in this paper. TIMIT is consisted of 6300 speeches with the average duration of 3 s from 630 speakers. And UME contains 4040 speeches with the average duration of 5 s from 202 speakers. The file format of all the two databases is WAV, 16 KHz sampling ratio, 16-bit quantization and mono. When resample factor is too small or too large, the effect of resampled speech is obvious, it means that the speech will be distorted too much, thus it is easy to be detected by human hearing. Hence, in this paper, a series of resampled factors from 0.8 to 2 with a step 0.1 are considered. In order to evaluate the proposed identification algorithm comprehensively, two kinds of typical resampling tools are taken into consideration: Matlab Resample (MR) and Adobe Audition (AA). Each method can be applied to obtain the resampled speeches by various factors. The total number of the resampled speech is 134420. Additionally, the duration of each frame is set to 50 ms and the overlap between two adjacent frames is 25 ms.
In our experiments, the specificity, sensitivity, detection rate and receiver operating characteristic (ROC) curve (with the area under the curve (AUC) measurement) are employed to evaluate the performances of the proposed method. Denoting TP , FP ,TN and FN as the true positive samples, false positive samples, true negative samples and false negative samples respectively, the sensitivity, specificity and detection rate are defined as,

Note that the original speech and the resampled speech are defined as the negative sample and the positive sample, respectively.
4.2 Experimental results
4.2.1 Cross-method evaluation
Since there are several kinds of resampling methods in practice, it is very possible that the method used in testing is different from the one for training models. Hence, in this case, when a certain resampling method is used at the training stage, another one method is tested in turn, which simulates real forensic scenarios and reveals the effect of various resampling methods on the proposed algorithm.
The results of this case are shown in Tab. 2 and Fig. 3. It can be seen that the detection rates of resampled speech are steady and higher than 93% (for Matlab Resampling) when the resampling factor is over 1.2. It indicates that the proposed method has good robustness to various resampling methods. Since there is no information loss during down-sampling which the resampling factor is lower than 1.0, the performance decreases dramatically. In fact, there is no actual application of down-sampled speech because the quality of the speech will be distorted once it is down-sampled.
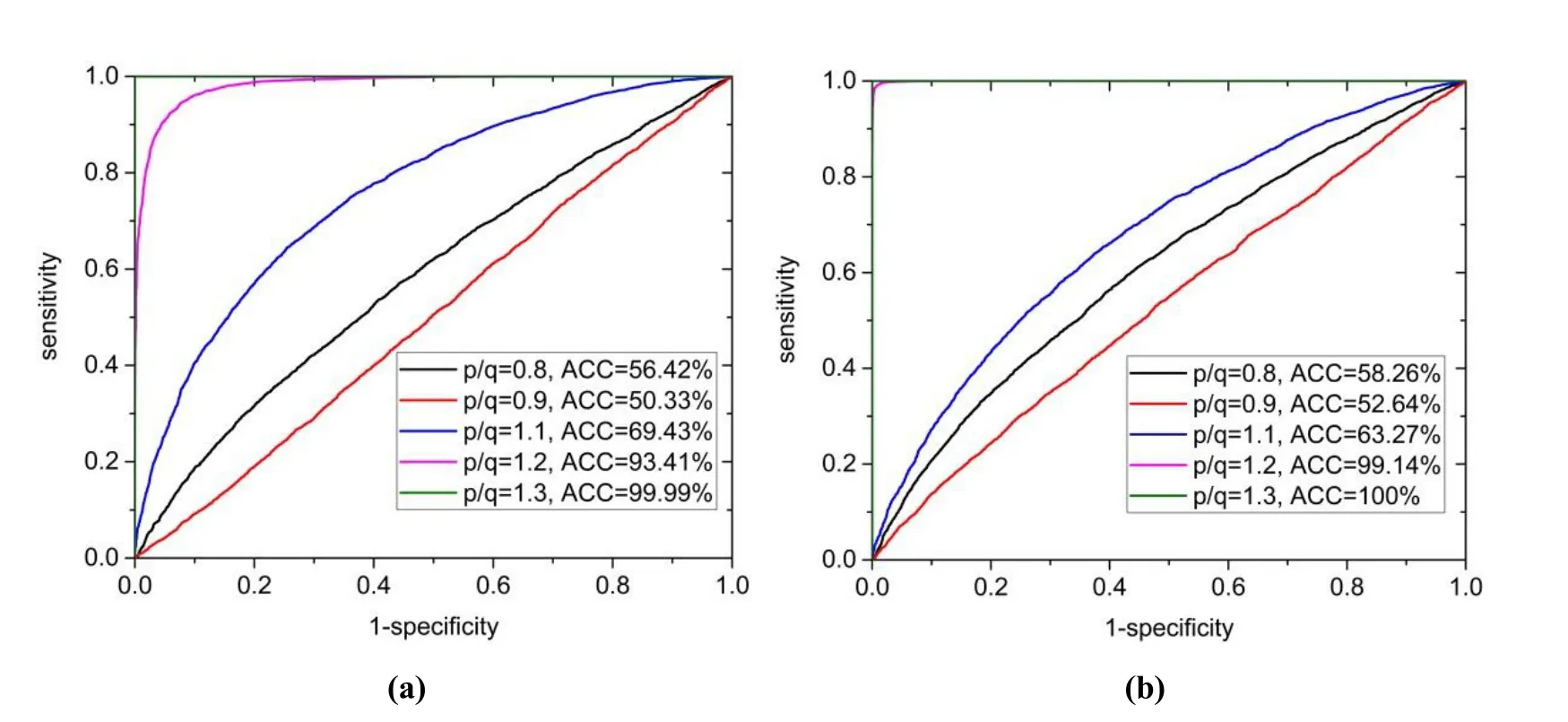
Figure 3: ROC curves for various resampling methods with TIMIT dataset

Table 2: Detection performance of cross-method evaluation
4.2.2 Cross-dataset evaluation
In real forensic scenarios, the suspected speeches may come from various environments and have various contents. Hence, cross-dataset evaluation is a necessary and important issue. In this case, the speeches from TIMIT and UME-ERJ databases are tested. And Adobe Audition is chosen as the resampling method.
Tab. 3 and Fig. 4 show the experimental result of the cross-dataset evaluation. It can be observed that the cross-dataset performance is a little worse than the one in Tab. 2.However, most of the detection rates are higher than 98% when the factor is over 1.2,which indicates that our proposed method is still effective to identify resampled speeches and has enough robustness to various speech contents.


Table 3: Detection performance of cross-dataset evaluation

Figure 4: ROC curves for various datasets with Adobe Audition
4.2.2 Comparison with the previous work in Hou
In the work of Hou, an algorithm for identifying resampled speech was proposed. In Hou’s work, it is theoretically shown that, if an original speech is re-sampled, significant peaks can be found in second-order derivative of the spectrum, and the peak position is related to re-sampling factor. The comparison between the proposed algorithm in this paper and the work is presented in Hou’s work.
TIMIT and UME-ERJ datasets are chosen in this case. The experimental results of Hou’s work are present in Tab. 4, Tab. 5, Figs. 5(a) and 5(b). It can be seen that most of the detection rates of the proposed algorithm are higher than the one in Hou’s work. It is demonstrated that the proposed algorithm in this paper outperforms significantly.
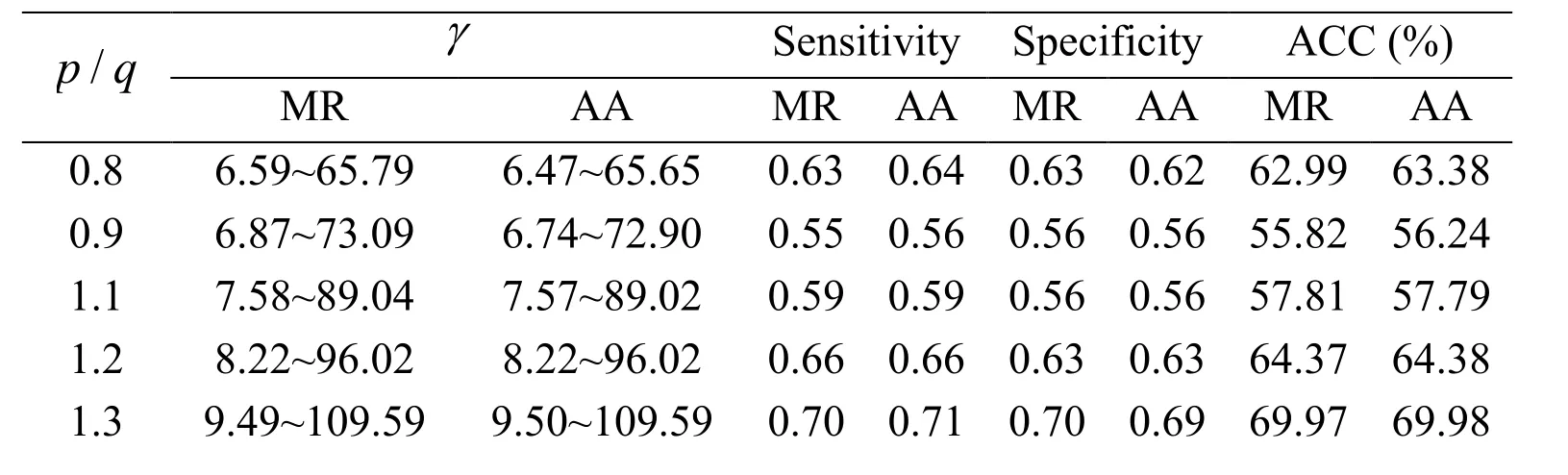
Table 4: Detection performance of cross-method evaluation in Hou’s work
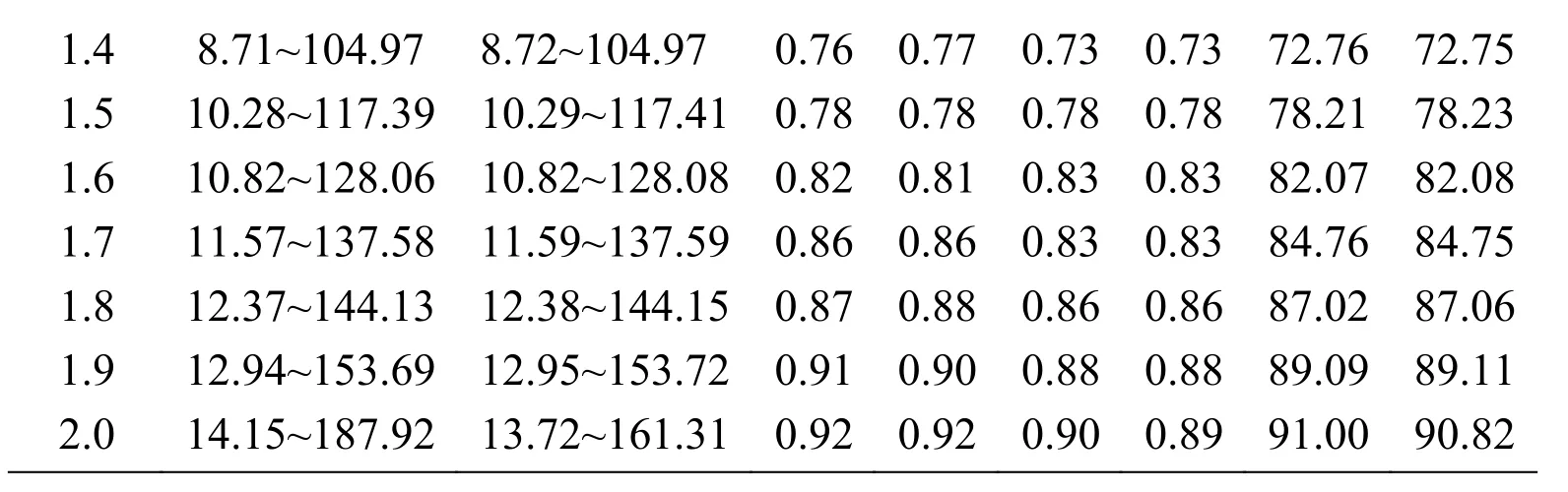
?
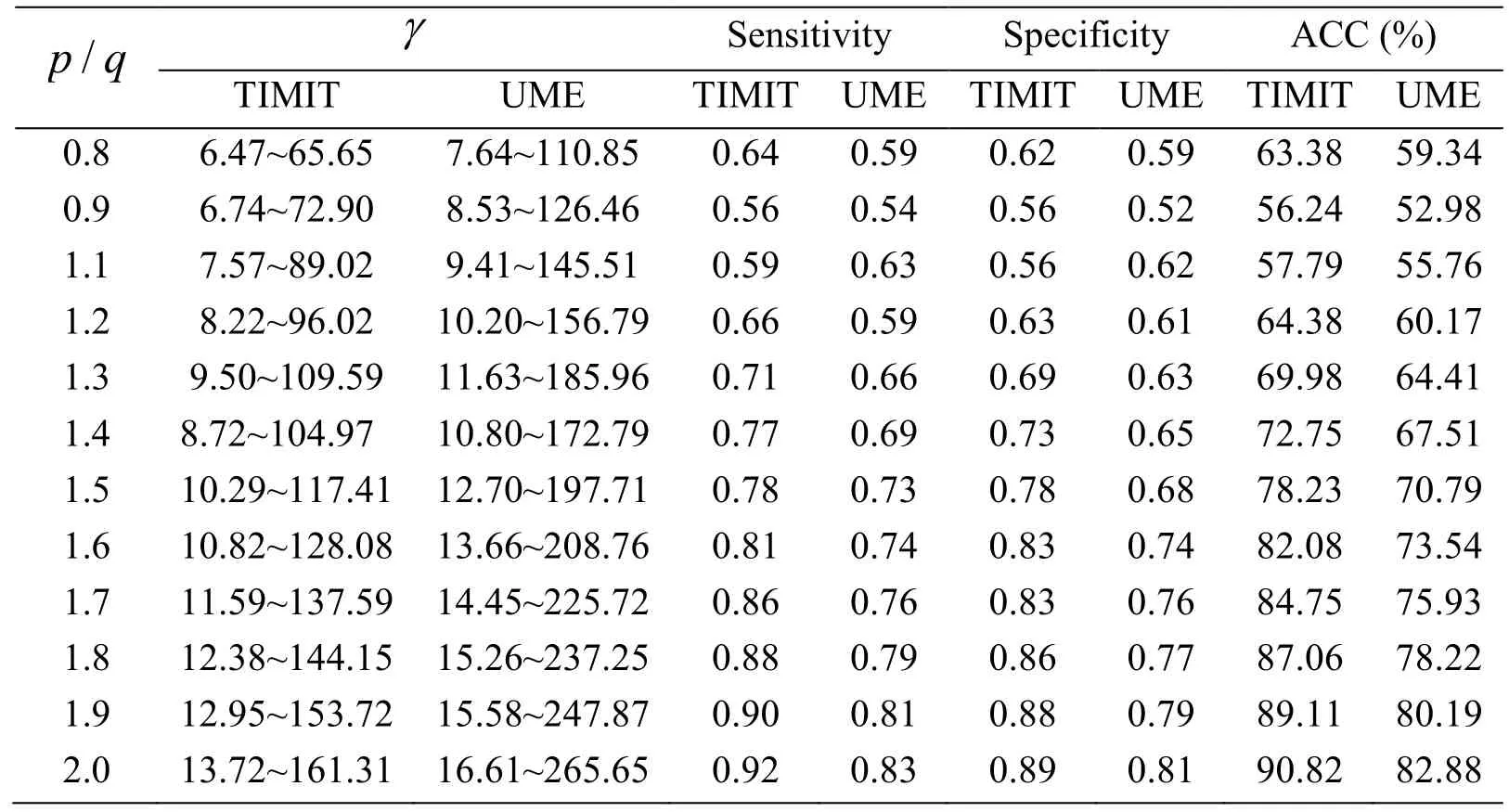
Table 5: Detection performance of cross-dataset evaluation in Hou’s work
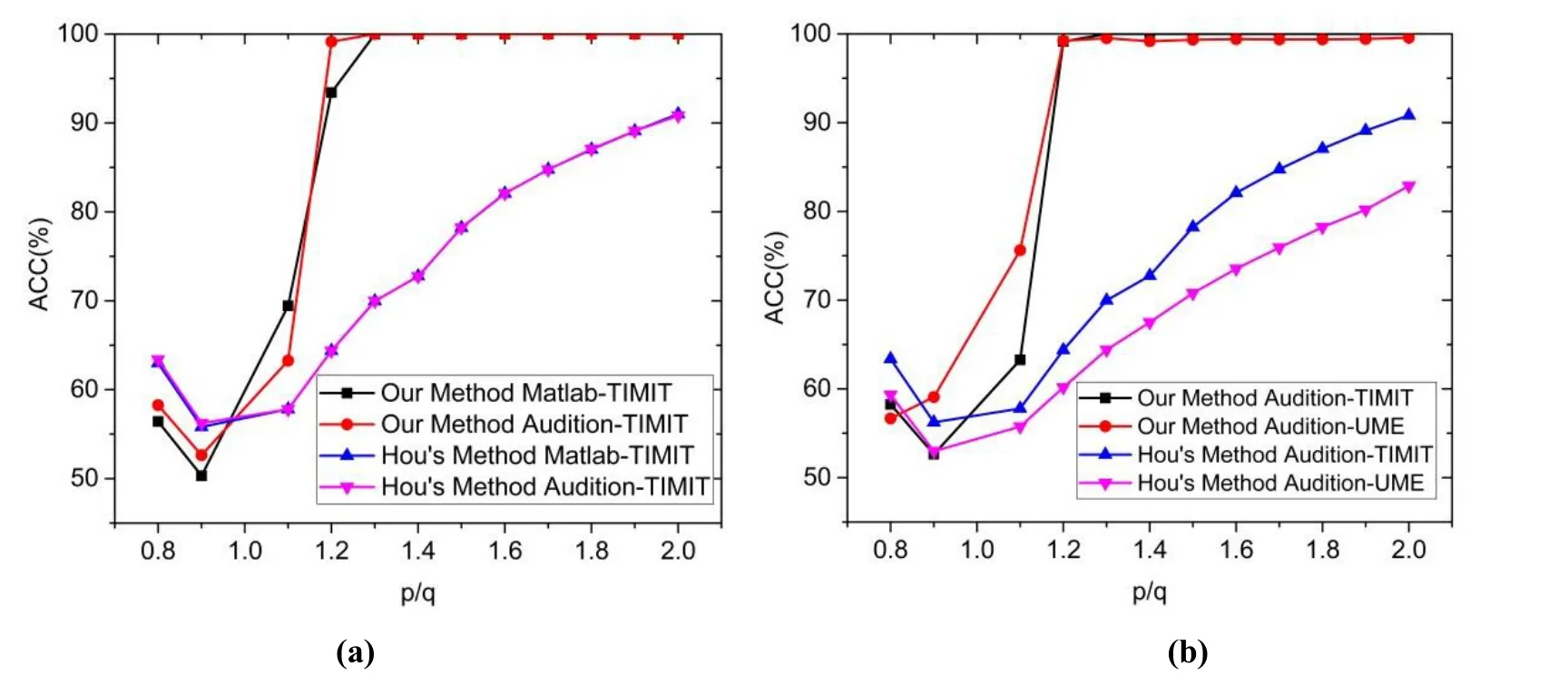
Figure 5: Detection rates in Hou’s work and the proposed algorithm
4.2.3 Robustness to MP3 compression
MP3 is one of the widely used audio formats for storage and transmission. In most speech forensic scenarios, speech signals are compressed as MP3 format. In this case, the speeches are taken from TIMIT dataset and set the resample factor to 2, and then compressed with lame MP3 encoder. Various compression bitrates of 64 Kbps, 128 Kbps,and 256 Kbps are considered. Before feature extracting, each MP3 speech is firstly decompressed to a WAV speech.
The detection results of the MP3 speeches resampled by a variety of factors are shown in Tab. 6. For various compression bitrates, all the detection rates are 100%, which indicates that the proposed method achieve perfect robustness to MP3 compression.

Table 6: Detection performance of MP3 compression attack
5 Conclusion
In this paper, an algorithm for identifying resampled speech is proposed. The inconsistency of band energy is extracted as the discriminative feature. A statistical analysis of the recompressed feature indicates that the band energy of the original speech is altered due to resampled. Thus, the inconsistency of band energy can be used to separate resampled speech from original speech. An identification system based on the inconsistency of band is designed in our work. The basic idea of the proposed algorithm is that it is possible to distinguish the speech resampled by an optimal threshold from original speech. In simulation experiments, two speech datasets and two kinds of commonly used resampling methods are used for testing. The experimental results show that the resampling detection algorithm based on inconsistency of band energy proposed in this paper can be simple, fast, effective and accurate whether the speech is resampled.Based on the detection method proposed in this paper, when the resampling factor is greater than 1, the detection accuracy is high. When the resampling factor is less than 1,the detection accuracy is not very good. How to find some other detection methods and the method proposed in this paper are combined to form a more complete detection system is next stage of our work. To analyze the influence of the proposed algorithm on the performance of systems is also to be taken into consideration.
Acknowledgments:This work was supported by the National Natural Science Foundation of China (Grant No. 61300055, U1736215, 61672302), Zhejiang Natural Science Foundation (Grant No. LY17F020010, LZ15F020002), Ningbo Natural Science Foundation (Grant No. 2017A610123), Ningbo University Fund (Grant No. XKXL1509,XKXL1503) and K.C. Wong Magna Fund in Ningbo University.
杂志排行

Computers Materials&Continua的其它文章
- An Empirical Comparison on Multi-Target Regression Learning
- Automatic Mining of Security-Sensitive Functions from Source Code
- Full-Blind Delegating Private Quantum Computation
- Improved GNSS Cooperation Positioning Algorithm for Indoor Localization
- A Novel Universal Steganalysis Algorithm Based on the IQM and the SRM
- Research on Trust Model in Container-Based Cloud Service