深度学习框架对城市日供水量预测的研究
2018-09-10牟天蔚蒋白懿沈丹玉赵明
牟天蔚 蒋白懿 沈丹玉 赵明
摘要:供水量预All是建立管网水力模型的前提,为提高供水管网模型精度,提出一种基于深度学习框架的小波深度信念网络(SW-DBN)时间序列模型。该模型首先通过Symlets小波对日供水量数据进行分解,然后将各分解项分别导入SW-DBN时间序列模型中进行训练,最后利用训练的模型进行预测。以新开河2014-2015年日供水量为训练数据,2016年1月1-7日供水量为测试数据,导入该模型进行预测。依据该测试方法对其后200d的供水量进行预测,结果表明:该模型用于日供水量预测比深度信念网络模型及传统BP神经网络模型精度高,相对误差均小于5%,是一种有效的方式。
关键词:深度信念网络模型;深度学习框架;Symlets小波;日供水量
中图分类号:TV213.4 文献标志码:A Doi:10.3969/j.issn.1000-1379.2018.09.014
随着经济社会发展,居民的用水需求量不断增大,供水部门为保障供水,应对城市供水量进行统计、分析及预测。供水量预测分为短期预测、中期预测、长期预测3类[1],日供水量预测属于短期预测。目前,大量成熟的短期预测模型得以应用。鲍燕寒川通过混沌时间序列模型对城市日供水量成功进行预测,但其缺点是不能完全适应供水量值的波动;陆志波等[2]通过自回归积分滑动平均模型和BP神经网络模型对人均生活用水量进行预测,但该模型仅适用于小样本数据预测,且准确性有待提高;李斌等[3]通過灰色神经网络组合模型对需水量进行预测,虽然准确性有所提高,但对大样本适应性仍然较差。近年来,深度学习框架被广泛应用于分类、预测、诊断问题中,其中深度信念网络(DBN)、卷积神经网络(CNN)较为常见,相比BP模型,DBN模型对大样本预测具有精度高、耗时少等特点[4]。Z.Y.Wn等[5]运用DBN模型对日用水量进行预测,但经测试,对于波动性大的历史数据样本仍无法适应。T.E.G.Swee等[6]运用Symlets小波对数据进行分解后,成功地解决了大波动样本预测的问题,但目前暂无案例将小波分解应用于深度学习框架之中。
笔者在深度信念网络基础上,结合Symlets小波模型,提出一种小波深度信念网络时间序列模型,对日供水量进行预测,以期达到适应大样本预测、提高预测精度的目的。
1 预测原理
1.1 计算原理
小波深度信念网络模型(SW-DBN)是Symlets小波与深度信念网络(DBN)组合的模型,通过Symlets小波将日供水量训练样本分解为趋势项、周期项、随机项,并运用分解结果对DBN模型进行训练,最后通过拟合模型对测试样本进行预测并进行误差分析。
1.2 Symlets小波模型
Symlets小波又称Daubechies近似对称小波,通常写作Sym N(N为阶数,N=2,3,…,n),是一种具有有限紧支撑、近似对称性质的双正交小波[7]。
matlab小波工具箱是通过高通、低通分解滤波器及重构滤波器来进行分解与重构数据的,其中:分解滤波器可将原始数据序列分解为平均与细节信息,重构滤波器可将分解的信息还原并去除原始数据的噪声。滤波器的阶数N越高,小波函数的平滑度越高;分解级数越高,重要信息越突出。但是,过高的阶数与级数会导致信息的丢失,因此选择合适的阶数、级数是非常重要的。日供水量时间序列历史数据一般为非平稳时间序列,可分解为趋势项、周期项和随机项。研究表明,利用Sym8小波的滤波器分解10级的效果较好[4]Sym8的4种滤波器如图1所示,滤波器长度为16,根据文献[8]可知,各滤波器的系数分别如下。
低通分解滤波器:
Lo_D=[-0.003,-0.001,0.032,0.008,-0.143,-0.061,0.481,0.777,0.364,-0.052,-0.027,0.049,0.004,-0.015,0.000,0.002]
低通重构滤波器:
Lo_R=[0.002,0.000,-0.015,0.004,0.049,-0.027,-0.052,0.364,0.777,0.481,-0.061,-0.143,0.008,0.032,-0.001,-0.003]
高通分解滤波器:
Hi_D=[-0.002,0.000,0.015,0.004,-0.049,-0.027,0.052,0.364,-0.777,0.481,0.061,-0.143,-0.008,0.032,0.001,-0.003]
高通重构滤波器:
Hi_R=[-0.003,0.001,0.032,-0.008,-0.143,0.061,0.481,-0.777,0.364,0.052,-0.027,-0.049,0.004,0.015,0.000,-0.002]
在确定分解的级数后,通过低通、高通分解滤波器,将日供水量原始数据分解,再分别进行下抽样运算,得到第一级的平均、细节部分的分解信息,然后运用滤波器,对上一级再次分解,递归计算,直至达到分解级数为止,即可获得各级分解的平均与细节信息。重构是分解的逆过程,通过重构低通、高通滤波器,对低频系数、高频系数分别进行上抽样,直至重构到趋势、周期规律明显的级数为止,即可获得去除噪声的数据。
1.3 深度信念网络(DBN)预测模型
DBN模型是由G.E.Hinton[9]提出的一种由隐含层与可视层组成的双层结构模型——限制波尔兹曼机模型(RBM),如图2所示。
RBM模型有高斯-伯努利、伯努利-伯努利、高斯-高斯3种类型。Z.Y.Wu等[5]运用高斯一伯努利模型解决了日供水量预测问题,其能量方程为式中:ωij为第j隐含层与第i可视层之间的权重;ai为可视层节点i的偏移量;bj为隐含层节点j的偏移量;νi为第i可视层的值,即输入变量的值;hj为第j隐含层的值;σi为可视层νi对应的高斯噪声的标准差。
RBM模型的核心部分在于向前传播,即输入数据在可视层与隐含层之间双向传播计算,假设每一个隐含层节点的取值都为0或1,即hj∈{0,1},令σi=1,当输入数据为hj时,通过式(1)可推导出可视层vi取值为1的概率:式中:σ(x)为S型激活函数,是隐含层对输入变量的二级运算。
得到可视层取值为1的概率P(vi=1|h)后,随机生成0~1之间的随机数l,若l同理,可视层vi取值为0或1,可求出隐藏层hj取值为1的概率:
计算过程采用对比散度算法,将输入变量赋予可视层神经元vq,通过式(4)计算出每一隐含层神经元的概率P(hj|vq),并采取吉布斯抽样法抽取其中一个样本P(hp1|vq),然后通过hp1重构可视层,采用式(2)计算每一个可视层神经元的概率P(vi|hp1)。同理,抽取样本P(vq1|hp1),通过vq1重构隐含层,得到P(hj|vq1),并抽取样本P(hp2|vq1)。采用均方差公式,求出可视层v与P(vi=1|h)各神经元之间的均方差:式中:J为计算误差;K为可视层神经元的个数。
最后通过样本值反向传播,更新权重,计算公式为
ωijθ=ωijθ-1+MΔωijθ-1+λiθ-1(C1-C2)(6)
bjθ=bjθ-1+MΔbjθ-1+γiθ-1[P(hj=1|vq1)-P(hj=1|vq2)]
(7)
λiθ=λiθ-1+MΔλiθ-1+λiθ-1[vi-P(vi=1|h)]
(8)式中:λi為学习速率;θ为迭代次数;P(hj=1|vq1)、P(hj=1|vq2)分别为隐含层的两次重构计算的结果;C1、C2分别为可视层vi与P(hj=1|vq1)、P(vi=1|h)与P(hj=1|vq2)的数组乘积;M为常数。
将RBM模型堆叠起来,下层的隐含层作为上层的可视层,并在最上方加人有向图算法层(如BP算法),即可得到深度信念网络(DBN)模型,如图3所示。
1.4 预测步骤
利用Symlets小波模型对历史日供水量数据进行分解,并采用DBN模型(见图4)进行预测,主要步骤如下。
(1)将水厂日供水量原始数据载入Matlab中,并进行归一化处理。
(2)将阶数设定为N=8,应用Matlab小波工具箱中的Sym N函数,对原始数据进行分解。
(3)从高频项中筛选出趋势项a,从低频项中筛选出周期项d,其余项之和作为随机项r。
(4)将分解各项以第t日的前k个时刻数据作为输入变量,t时刻数据为输出变量,代入DBN模型中进行训练,表达式为
y(t)=F[y(t-1),y(t-2),…,y(t-k)](9)式中:y(t)为t日各分解项的值;k为时间序列长度,为一常数值;F[y(t-1),y(t-2),…,y(t-k)]为输入变量与输出变量的映射。
(5)充分训练第一个RBM模型,直到模型的输出数据误差小于给定值为止。
(6)固定第一个RBM模型的权重值与偏移量,将第一个隐含层神经元作为第二个RBM模型的输入变量,对第二个RBM模型子层同样训练,并堆叠到上一个RBM层上,重复以上步骤进行多次RBM堆叠。在最顶层的RBM模型训练时,该RBM模型的可视层中除了可视层神经元外,加入有代表标签(输出变量)的神经元,一起进行训练,即可视层神经元包含输入变量和输出变量,最后加人3层BP全连接层,并使最后一层RBM为输入层,整个计算过程为无监督训练。
(7)使用输出的标签作为样本进行有监督训练,为更好地对供水量数据进行处理,运用BP模型的有向图算法进行反向传播计算。
(8)将分解后的新数据代入式(9)进行预测,并累计求和、还原。
(9)进行误差分析,符合要求则结束,否则返回步骤(4)。
2 实例分析
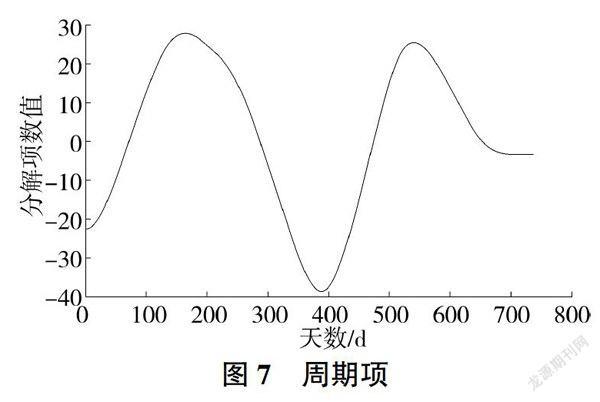
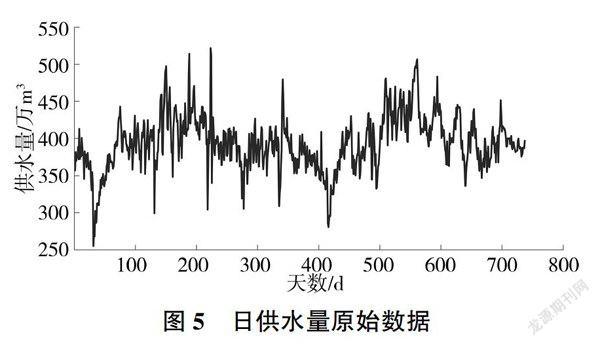
以新开河2014-2015年日供水量数据为训练数据、2016年1月1-7日供水量数据为测试数据,运用Matlab 2016a编写SW-DBN模型计算程序。首先将2014年1月1日-2016年1月7日共737d的供水量数据(见图5)导入Madab中。
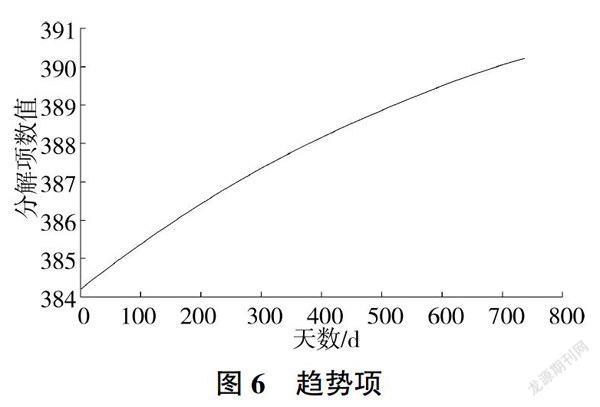
设定分解层数为10,运用Sym8小波对数据分解并进行重构,得出低通第十级重构为趋势项、高通第八级重构为周期项,其余项之和作为随机项,见图6~图8。
其次,对分解后的3项训练数据分别进行归一化处理,令式(9)中k=8,转换数据为时间序列格式,并导入数据对DBN模型进行训练,其中RBM模型共3层,分别包含32、28、24个神经元。在第三可视层上面加人输出变量作为标签,最后通过3层全连接层计算,其中隐含层神经元个数为16,然后进行有监督反向传播得出分解项结果,最后对各项结果求和,获得拟合模型。对测试数据进行归一化处理并代入拟合模型,求出预测结果,并与真实结果对比(见图9),可知相对误差均在5%以内,符合精度要求。
利用DBN模型、传统BP神经网络模型分别进行预测,并将预测结果与SW-DBN模型进行比较。DBN模型中RBM隐含层的神经元数量与SW-DBN模型的相同;BP模型共有3层神经元,其中隐含层神经元数量与SW-DBN模型的相同。预测结果及相对误差见表1。
由表1可以看出,SW-DBN模型比BP模型、DBN模型精度均高,其相对误差最大值为3.29%,小于BP模型的4.63%及DBN模型的3.56%。为进一步比较模型的精度,采用平均绝对误差(MAE)、平均绝对百分比误差(MAPE)对模型进行评价[8],结果见表2。可知,SW-DBN模型的MAE,MAPE均小于BP模型与DBN模型的。
为更好地检验SW-DBN模型的精度,以2016年1月8日一7月25日200 d的供水量数据作为测试数据进行检验。首先对模型进行训练,然后将1月1-7日数据加人原始数据中,对8-14日的7d数据进行预测,之后把8-14日的真实数据加人原始数据中,预测接下来的7d,依此类推。预测结果见图10,预测值相对误差最大仅为3.06%,精度较高。
3 结语
采用小波深度信念网络(SW-DBN)时间序列模型对新开河的日供水量进行预测,结果表明:预测值相对误差均小于5%,满足精度要求。通过与DBN及BP神经网络模型的预测结果对比,SW-DBN模型最大相对误差、MAE与MAPS均有所减小。因此,SW-DBN模型可有效提高城市日供水量预测精度。
参考文献:
[1]鲍燕寒.城市用水量预测研究[D].合肥:合肥工业大学,2010:3-5.
[2]陆志波,陆雍森,王娟.ARIMA模型在人均生活用水量预测中的应用[J].给水排水,2005,31(10):97-101.
[3]李斌,许仕荣,柏光明,等.灰色-神经网络组合模型预测城市用水量[J].中国给水排水,2002,18(2):66-68.
[4]HINTON G E.A Practical Guide to Training Restricted Bolt-zmann Machines[J].Momentum,2012,9(1):599-619.
[5]WUZY,RAHMAN A.Optimized Deep Learning Frameworkfor Water Distribution Data-Driven Modeling[J].ProcediaEngineering,2017,186:261-268.
[6]SWEE T E G,ELANGOVAN S.Applications of Symlets forDenoising and Load Forecasting[C]//IEEE ComputerSociety.Proceedings of the IEEE Signal ProcessingWorkshop on Higher-Order Statistics.Madison,USA:Tech-nical Communication Services,1999:165-169.
[7]李中偉,程丽,佟为明.Symlets小波幅值算法研究[J].电力自动化设备, 2009,29(3):65-68.
[8]DAUBECHIES I.Ten Lectures on Wavelets[M].Edmonton:Capital City Press,1992:249-274.
[9]HTNTON G E.Training Products of Experts by MinimizingContrastive Divergence[J].Neural Computation,2002,14(8):1771-1800.
