改进的协同过滤算法在农资电子商务网站的应用
2018-09-07许贝贝王文生郭雷风
许贝贝, 王文生, 郭雷风
(中国农业科学院农业信息研究所,北京 100081)
目前,推荐系统较成熟地应用于电子商务领域的网站如全球最大的网上书店亚马逊、淘宝等[1-2],而作为一个农业大国,与农业息息相关的农资电子商务网站却很少应用推荐系统,如果用户在购买农资时能得到相关的产品推荐,将会为用户带来极大的便利,提高其购买满意度。
调研得知,当前一些农资电子商务网站虽然也具备推荐功能,但仅仅是对热点农资的推荐,与用户的相关性较弱,未能结合用户的兴趣和浏览历史记录等进行推荐,不能满足用户的个性化需求。
推荐系统的研究关键就在于推荐算法,推荐算法中应用较多的是协同过滤推荐算法和基于内容的推荐算法[3]。基于协同过滤的推荐算法是成功的个性化推荐技术,该算法根据用户过去的喜好和其他兴趣相似的用户的选择给该用户推荐事物或根据用户过去发生的行为为用户推荐和过去相似的事物[4];基于内容的推荐算法提取事物的特点和属性,同时利用记录构建用户的偏好模型,将用户兴趣与事物进行匹配为用户进行推荐。但每种算法均有一定的局限性,表1为推荐算法的优缺点总结。
因此,本研究基于上述2种算法,结合用户兴趣偏好的特点,运用切换混合算法[8],利用用户相似度改进协同过滤算法中的“冷启动”问题,采用内容相似度的方法弥补协同过滤算法中“稀疏性”问题[9],同时也解决了单独使用协同过滤或基于内容的算法推荐较为单一的问题。
1 改进的协同过滤算法
1.1 算法的思路
改进的协同过滤算法是在切换混合算法[8]的基础上分2个部分进行:一是为解决协同过滤算法中冷启动问题的基于用户相似度的推荐算法,包括基于用户关注类别的相似度计算模块和搜索最近邻用户浏览的农资模块;二是内容向量模型补充的协同过滤算法[9],其包括构建基于时间评分的用户-农资信息评分矩阵模块、逆向最大匹配中文分词模块、TF-IDF方法模块、构建用户浏览兴趣特征模型模块、基于用户的最近邻居推荐生成等模块。图1所示为算法的流程图。

表1 推荐算法的优缺点总结
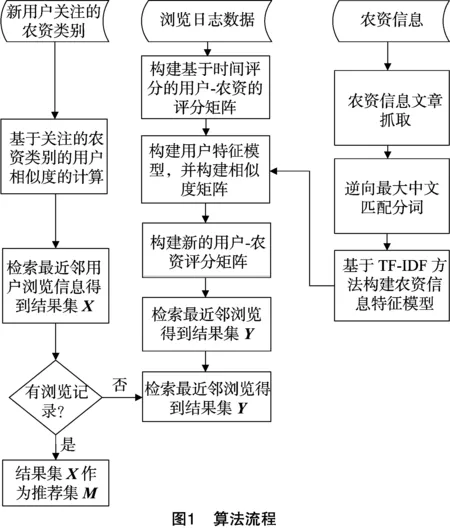
1.2 算法详述
1.2.1 基于用户相似度的推荐算法 为解决新用户在初始阶段面临冷启动问题而无法直接利用协同过滤等算法进行推荐,本研究提取新用户设置的关注农资类别建立用户特征向量模型,计算用户之间的相似度,最后将与其相似度较高的用户购买过的和浏览过的农资产品推荐给该用户。具体计算过程如下:
首先对用户的特征建立空间向量模型
user={f1,f2,f3,f4,…,fn}。
(1)
式中:fn表示用户关注的农资产品类别。
其次采用如下公式计算用户的相似度
(2)
式中:sim(a,b)表示用户a与b之间的相似度,其数值越大说明两者越差异越小;N(a,b)表示a与b共同关注的农资产品类别的数量;Na表示a关注的农资产品类别的数量;Nb表示b关注的农资产品类别的数量。
最后根据计算出的用户的相似度进行排序,检索相似度较高的用户购买过或浏览过的农资产品结果集X推荐给该新用户。
1.2.2 内容向量模型补充的推荐算法 对于有浏览农资信息记录的用户,采用基于内容的向量模型补充的协同过滤算法,具体的流程如下。
1.2.2.1 构建基于时间评分的用户-农资产品信息评分矩阵 在农资产品信息的浏览过程中,并不能通过类似于电影打分机制评定一篇农资产品信息的好坏,而浏览时间却能很好地体现一篇农资产品信息对于用户的吸引程度。所以引入时间评分制度来设定用户对浏览的农资产品信息的评分:
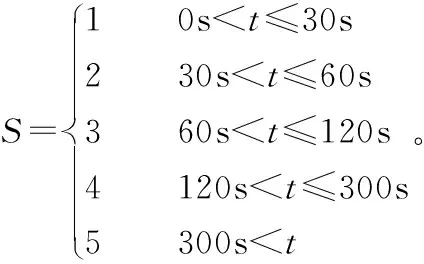
(3)
由公式3可构造出用户-农资产品信息评分矩阵Um×n
(4)
式中:m表示用户个数;n表示农资产品信息的序数;Rm,n表示用户m对农资产品信息n的评分。越接近5,表示该用户对这篇农资产品信息越感兴趣;0表示该用户并未浏览过此农资产品信息。
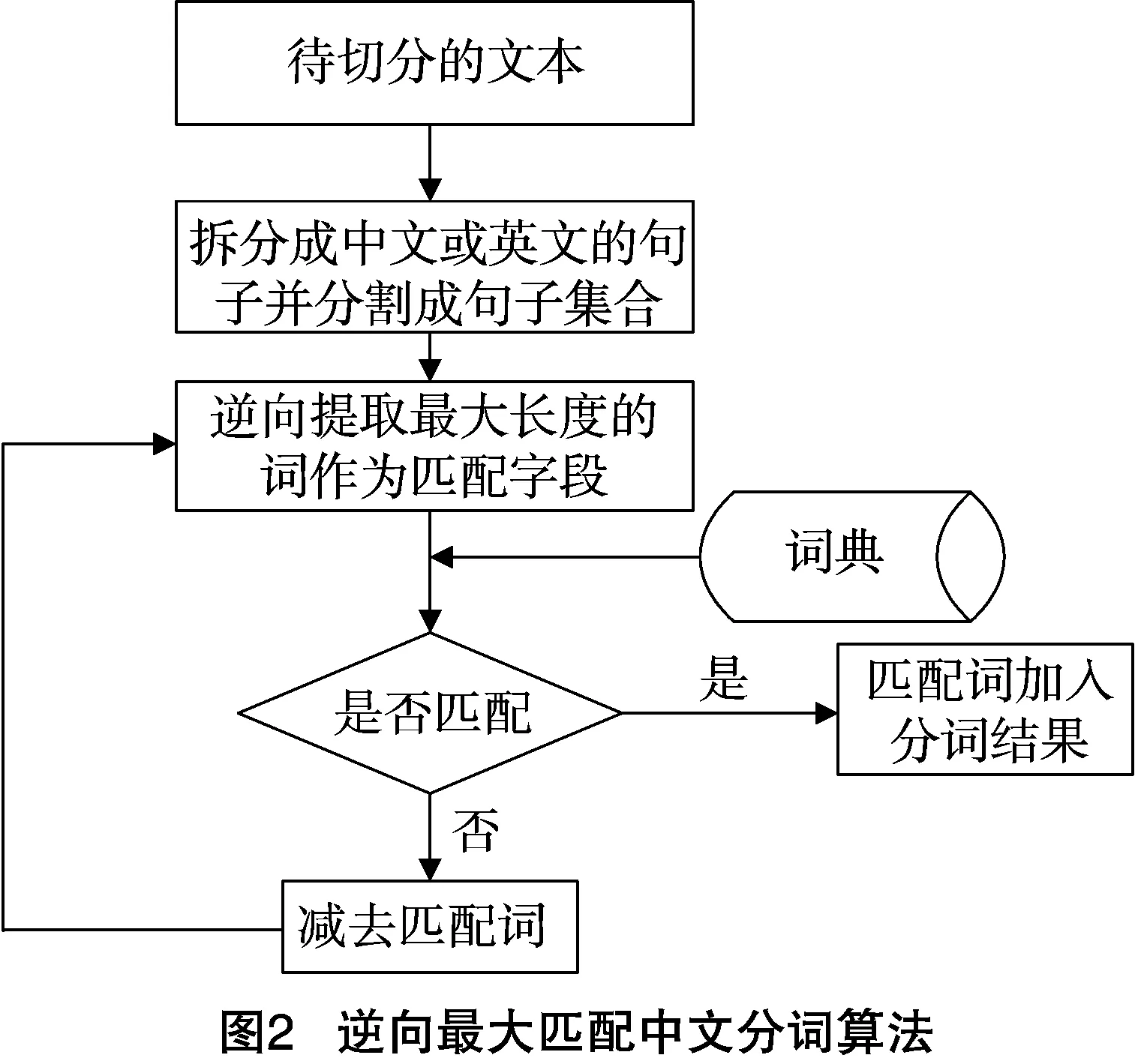
1.2.2.2 逆向最大匹配中文分词 逆向最大匹配中文分词算法[10]是一种基于词典的快速分词算法,在保证分词精确度的情况下大幅提高了词典加载和分词的效率,图2为具体步骤。
1.2.2.3 TF-IDF TF-IDF[11]是信息检索领域的成熟技术,表示词频和反文档频率。在TF-IDF模型中,文档表示为算出的TF-IDF值向量。
通过逆向最大匹配中文分词方法以及TF-IDF方法将一篇农资产品信息转化为一个特征向量模型。即:
Zi={(T1,Xi,1),(T2,Xi,2),…,(TN,Xi,N)}。
(5)
式中:(YN,Xi,N)表示第N个特征,Zi表示第i篇农资产品信息的TF-IDF值向量。
1.2.2.4 构建用户特征模型,并构建相似度矩阵 基于公式(4)与农资产品信息构建出来的TF-IDF特征空间向量模型,将公式(5)中的每一行转换为针对每一位用户的浏览信息特征模型。以公式4中第1行为例:
[R1,1,R1,2,…R1,n]。
对于同一用户,将农资产品信息的序数变为列,每一篇农资产品信息的特征空间向量为行,并都与其值匹配。
计算用户i对于某个特征N的兴趣偏好程度Ai,TN:
(6)
式中:i表示用户编号;TN表示第N个特征;s(TN)表示用户i评价过的具有TN的农资产品信息的TN的TF-IDF值与其评分Ri,j的乘积之和;num(n)为用户i评价过的具有TN的农资产品信息的篇数;s(i)所有特征的TF-IDF值与其农资产品信息评分Ri,j的乘积之和;num(i)为用户i所有评论过的信息的篇数。
通过以上变换,将用户特征向量模型表示为
Di={(T1,Ai,T1),(T2,Ai,T2)…(TN,Ai,TN)};而农资产品信息的特征向量模型表示为:
Zi={(T1,Xi,1),(T2,Xi2)…TN,Xi,N};通过Di与Zi,得出它们之间的相似度
(7)
根据所得到的相似度,归一化处理(即将其中的最大值化为1)后构造出相似度矩阵
(8)
1.2.2.5 构建新的用户-农资产品信息评分矩阵 公式(8)相似度矩阵与公式(4)用户-农资产品信息评分矩阵通过以下规则合并:
(9)
合成出新的用户-农资产品信息评分矩阵:
(10)
1.2.2.6 基于用户的最近邻居推荐 给定一个评分数据集和当前(活跃)对象的ID作为输入,找出与当前对象过去评分相似的对象,这些对象称为最近邻。最近邻的确定方法通用的是Pearson相关系数[12]。
设用户a的最近邻居集合用NNa表示,则a对农资产品信息k的预测评分Ca,k可由a的最近邻居集合NNa对农资产品信息的评分得到,计算方法如公式(12)所示:
(11)
(12)
1.2.2.7 判断是否有浏览记录 如果没有浏览记录,结果集X即为推荐集M;如果有浏览记录,则按照X∶Y=A∶B比重生成推荐集N。其中X表示无浏览记录时直接得到的结果集,Y表示有浏览记录时根据得到的结果集,A∶B表示X与Y的比例结果。
2 试验结果与分析
2.1 试验过程
本研究共选取60名用户利用爬虫软件进行追踪调查,挑选100篇合适的农资产品信息作为信息数据库,同时建立1个小型特征词典,并记录事先已有浏览信息的15名用户。将其余45名用户分为3组,分别使用本研究算法、协同过滤算法和基于内容的算法进行农资产品推荐[13],以下详细说明本研究算法过程。列举部分新用户关注的农资产品类别见表2。

表2 新用户关注的农资产品类别
对于基于用户相似度的推荐,首先利用新用户关注的农资产品类别计算用户的相似度,表2中1、3、5号有历史浏览信息,而2、4、6号没有。以2号推荐为例,使用公式(2)计算与其他用户的相似度,结果如下:
2号与1号的相似度sim(2,1)=0.14;2号与3号的相似度sim(2,3)=0.07;2号与4号的相似度sim(2,4)=0.21;2号与5号的相似度sim(2,5)=0.14;2号与6号的相似度sim(2,6)=0.29。
根据相似度的高低排序,检索相似度较高的用户浏览过的或购买过的农资产品为该用户推荐得到结果集合M。
为每名用户在结果集合M中选取推荐10份农资产品信息,通过记录每位用户浏览每篇农资产品信息的时间利用公式(3)得到用户-农资产品信息评分矩阵,部分记录见表3。
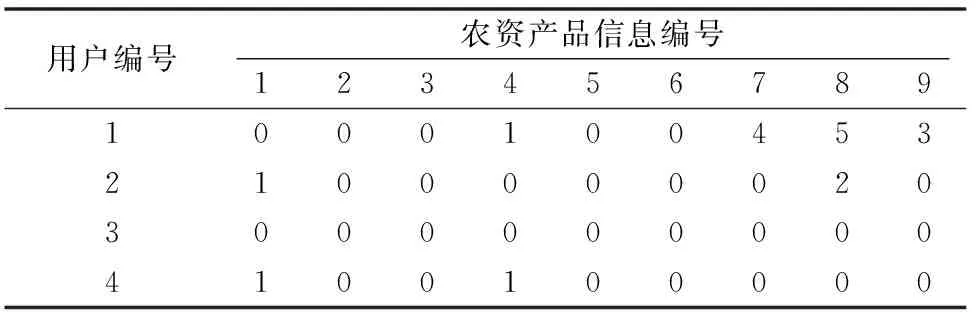
表3 用户-农资产品信息评分矩阵
通过小型特征词典利用逆向最大匹配中文分词算法,为100份农资产品信息构建特征向量模型,并与表3构建出用户浏览信息特征模型,部分结果见表4。
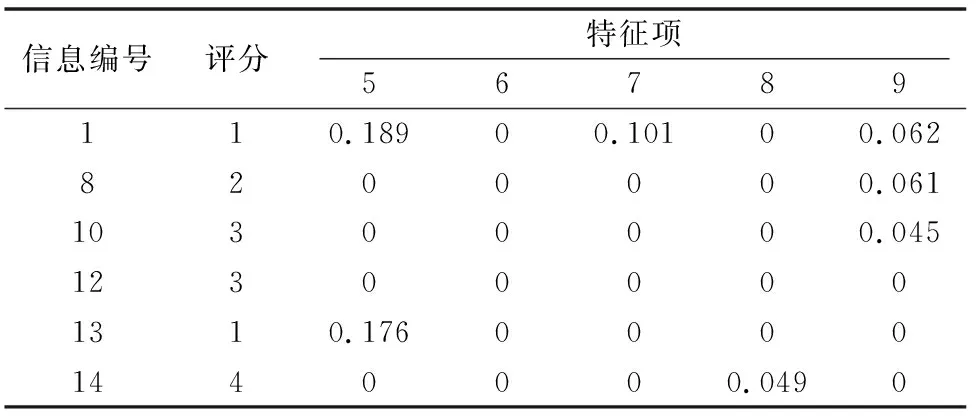
表4 用户浏览信息特征模型
根据公式(5)计算出该用户特征向量模型并进行归一化处理后得到表5。利用公式(6)和公式(7)构造出相似度矩阵如表6。将表3与表6利用公式(9)和(10)合成出新的用户-农资产品信息评分矩阵表7。最后利用公式(11)和公式(12)得到推荐结果集Y,按X和Y的比值取数值最高的前10份农资信息推荐给用户2。

表5 用户特征向量模型
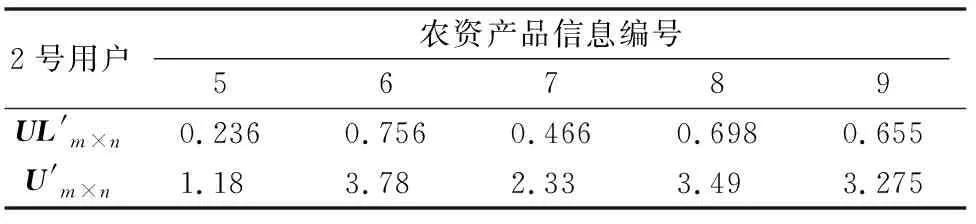
表6 相似度矩阵

表7 新的用户-农资产品信息评分矩阵
另外2组用户分别按照基于内容的推荐算法与基于用户的协同过滤算法为其推荐15份农资信息,本研究不作详述。
2.2 结果分析
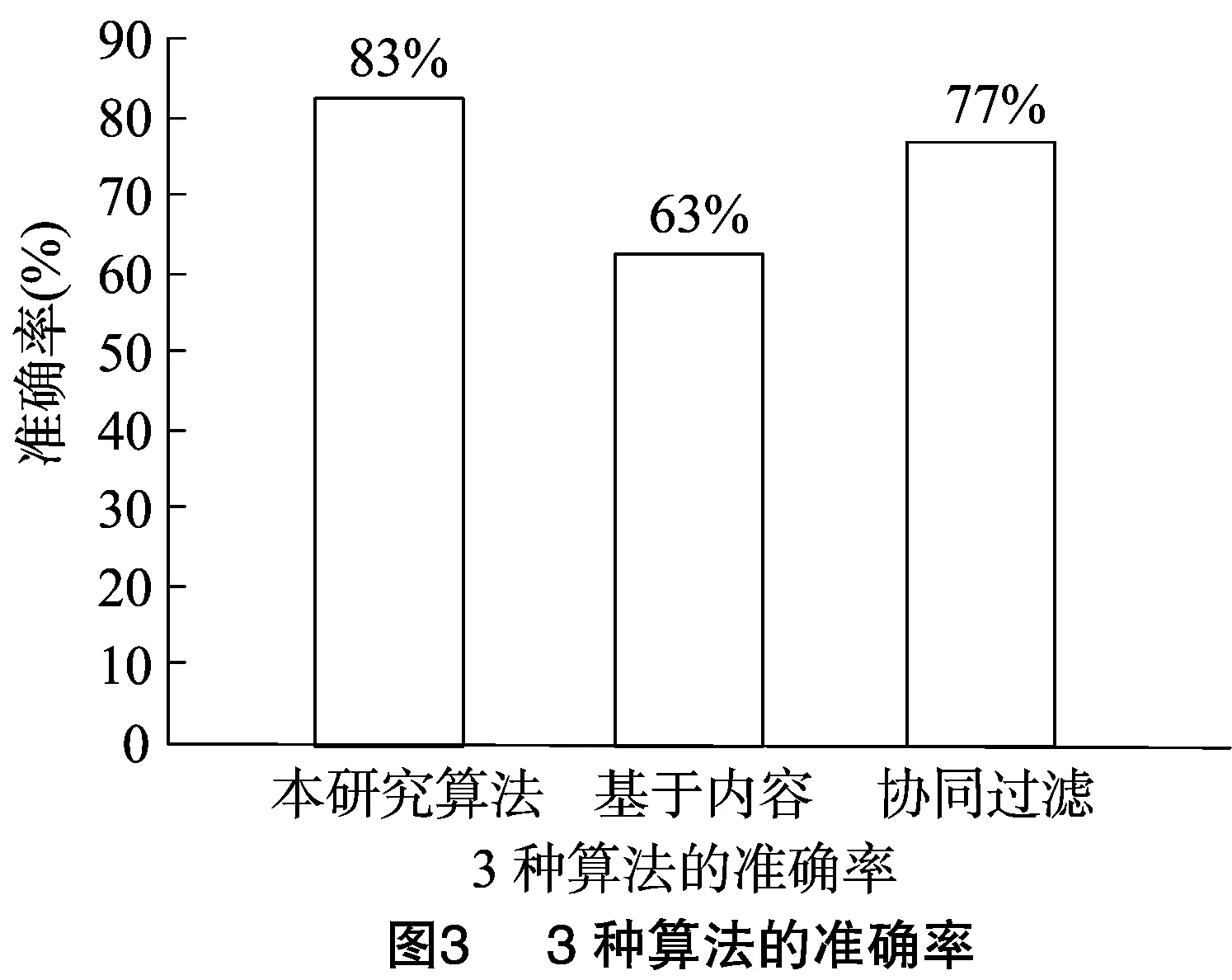
本研究采用推荐的准确率评价推荐效果,即用户对推荐的农资产品信息是否加入购物车或购买。3种算法的准确率统计如图3所示。结果表明,本研究改进的推荐算法有效率为83%,协同过滤算法的有效率为77%,基于内容的推荐算法的有效率为63%。试验表明本算法提高了推荐精度及推荐的有效率。
3 结束语
本研究提出的运用切换式的混合推荐算法,根据是否有浏览记录分别采用不同的算法,解决了传统算法中冷启动与稀疏性问题。由于得到的数据有限,本算法还存在一些问题,如在构建基于时间评分的用户-农资产品信息评分矩阵中时间评分系统的参数须再进一步研究,试验的数据量也不是特别多,这些也都是下一步改善研究的重点。
