基于学习算法SSD的实时道路拥堵检测
2018-09-04李超凡陈庆奎
李超凡 陈庆奎

摘 要:随着人们生活水平的不断提高,道路车辆拥堵情况愈发严重。如何实时、精确地检测出道路车辆,对于解决道路拥堵问题具有重要意义,GPU和人工智能技术的飞速发展为其提供了可靠的解决方案。研究分析传统目标识别算法、基于候选区域深度学习的目标提取算法RCNN和基于回归的深度学习目标检测YOLO,最终确定采用基于卷积神经网络的实时目标检测算法SSD。首先调用VGG16网络模型在ILSVRC CLS-LOC数据库上预训练生成初始网络模型,进而设置超参数并在自身数据集上进行再训练,生成新的网络检测模型,然后将训练和测试部署到深度学习框架Caffe上加以实现。通过在数据库COCO、VOC2012上的测试结果表明,该模型检测精度为76%左右,处理速度为26FPS。同时通过道路路口的实地车辆检测,显示该算法能够实时、精确地检测出道路车辆,为道路拥堵情况判定提供可靠数据。
关键词:GPU计算;拥堵检测;卷积神经网络;车辆检测;SSD
DOI:10.11907/rjdk.173313
中图分类号:TP302
文献标识码:A 文章编号:1672-7800(2018)006-0008-05
Abstract:With the continuous improvement of the people′s living standard, the congestion of road vehicles becomes more and more serious. How to accurately detect road vehicles in real time is of great significance to solve the problem of road congestion. The rapid development of GPU and artificial intelligence provides a reliable solution. We analyse the traditional target recognition algorithm, target extraction algorithm RCNN based on the candidate region deep learning and regression-based deep learning target detection YOLO, and finally we adopt the real-time target detection algorithm SSD based on convolutional neural network . First we call the VGG16 network model to pre-train the initial network model on the ILSVRC CLS-LOC database to set up hyper-parameters and retrain on their own data sets to generate a new network detection model and then deploy training and testing to the deep learning framework Caffe. Tests on the database COCO, VOC2012 showed that the model detection accuracy reached about 76%, the processing speed reached 26FPS. the final road junctions The field of vehicle detection in the road junctions proves that the algorithm can realise real-time accurate detection of road vehicles so as to provide reliable data about road congestion.
Key Words:GPU computing; congestion detection; convolutional neural network; vehicle detection; SSD
0 引言
隨着大数据、云计算、GPU等技术的发展,人工智能领域的相关技术和应用也不断深入。图像识别是人工智能领域的关键应用之一,其中基于视频流的视觉目标检测与静态图片视觉目标检测是目前计算机视觉领域的研究热点。随着人们生活水平的提高,越来越多电子设备应用于人们生活中,其中数字图像已成为不可或缺的重要信息媒介,时刻都在产生大量图像数据[1]。如今对图像中的类别进行精确识别和分类已变得越来越重要,而且不是仅对目标图片进行简单分类,而是希望将图像中感兴趣的区域提取出来并且作出精确判断,例如现在比较流行的鉴黄软件、十字路口的电子猫眼、犯罪分子的人脸识别等相关应用都离不开目标检测技术的支持。因此,目标视觉检测有着广阔的应用前景[1],除智能视频监控、机器人导航、汽车无人驾驶、嵌入式电子产品、数码相机、人脸识别等技术外,目标检测也为更高级的人体行为识别、图像语义分割、事件检测等提供了技术支持。本文即是应用相关目标检测算法对道路路口车辆进行实时识别检测。
1 相关工作
目前目标检测领域相关算法主要分为3大类:①传统目标检测算法,例如HOG[2](Histogram of Gradient)+SVM(Support Vector Machine)、SIFT[3](Scale-invariant Feature Transform)、前景提取等;②RCNN系列基于候选区域的深度学习目标检测算法,如RCNN[4]、FAST-RCNN[5]、FASTER-RCNN[6]、RFCN[7];③基于回归方法的深度学习目标检测算法,如YOLO[8]、SSD[9]等。目标检测算法大致分类如图1所示。
(1)HOG、SVM、DPM等传统目标识别算法不需要训练,但检测精度不高,而且处理速度非常慢。
(2)RCNN系列基于候选区域的深度学习目标检测算法,从RCNN[4]、Fast-RCNN[5]、Faster-RCNN[6]、RFCN[7]速度依次变快,而检测精度相差不大。RCNN检测精度略高,但该算法存在的一个最大问题是处理速度慢,每秒大概5帧,无法达到实时性要求,而且需要分开训练,处理复杂,步骤耗时,生成的图片文件占用磁盘空间较大。如图2所示为基于候选区域的深度学习检测算法基本流程。
(3)基于回归的深度学习目标检测算法,主要包括YOLO[8]、YOLO2和SSD[9]等相关算法,其中YOLO[8]算法实际上是结合RCNN系列算法作出的改进,即在牺牲精度的情况下提高了处理速度。YOLO的处理速度在每秒30帧左右,精度为65%左右,相比于RCNN的75%降低了不少;SSD算法网络模型进行的目标检测,与YOLO相比,在保持速度不变的情况下提高了精度,其精度甚至比RCNN系列更高。SSD使用卷积神经网络对图像进行卷积后,在不同层次的特征图上生成一系列不同尺寸与长宽比的边框,该网络对于每一个边框中物体类型的可能性进行了预测,并且可以调整边框形状,以适应相应的目标物体形状大小。最后在PASCAL VOC、MS COCO和ILSVRC数据集上进行测试,实验显示其平均精度在75%左右。而本文即针对预训练的SSD网络模型进行改进,并在自己数据集中训练生成新的网络模型,并进行实地的检验测试。实验结果表明,该方法能够准确提取出道路车辆特征,检测出道路拥堵情况。
2 SSD基础原理
2.1 车辆目标任务构建
本文任务是通过在道路十字路口安装摄像头,实时采集视频,即通过视频流方式实时检测路口车辆。
2.2 SSD网络模型
SSD(Single Shot MultiBox Detector)是一个单一的检测器,能够识别多个物体,其核心是预测固定集合的类别分数和盒偏移,并使用应用于特征映射的小卷积滤波器的默认边界框。如图4所示为一张图像中含有多个特征图在不同比例下的检测框,在训练期间,SSD只需要一个输入图像和地面实框图。在卷积中,评估一个小集合在具有多个特征图的情况下,每个位置处不同纵横比的默认框。对于每个默认框,预测所有对象类别((c-1,c-2,…,c-p))的形状偏移和置信度,训练时首先将这些默认框与实际框图进行匹配。例如,本文匹配了两个默认框猫和狗,它们被视为感兴趣区域,其余作为不感兴趣区域。另外,模型损失是本地损失(例如平滑L-1[10])和置信损失(例如Softmax)之间的加权和。
SSD方法是基于前馈卷积网络,在这些框中的实例有一个固定大小的边界框集合和用于存在对象类的分数,最后通过非最大抑制步骤产生最终检测结果。之前的网络层基于标准架构用于高质量图像分类,如图5所示为SSD网络结构,SSD通过使用VGG-16-Atrous作为基础网络,Conv8_2 Conv9_2 Conv10_2 Conv11_2作为特征提取层。SSD与YOLO的不同之处是,除在最终的特征图上进行目标检测外,还在之前选取的5个特征图上进行预测。如图5所示为SSD网络预测示意图,检测过程不仅在添加特征图(conv8_2, conv9_2, conv_10_2, pool_11)上进行,为了保证网络对小目标的检测效果,检测过程也在基础网络特征图(conv4_3, conv_7)上进行。
2.3 SSD训练算法介绍
訓练算法和一般的机器学习训练算法相同,首先定义损失函数,即衡量与实际结果间的差距,然后找到最小化损失函数的W和b。根据SSD训练网络结构,可以知道GT标签在分特征图上生成priorbox,再将所有priorbox组合为mbox_priorbox,作为所有默认框的真实值。
预测过程会在选取的特征图上进行两个3×3卷积,其中一个卷积层输出每个默认框的位置(x, y, w, h)4个值,另一个输出每个默认框检测到不同类别物体的概率,输出个数为预测类别个数。再将所有默认框位置整合为mbox_loc,并将所有默认框预测类别的向量组合为mbox_conf。mbox_loc、mbox_conf为所有预测默认框,将其与所有默认框的真实值mbox_priorbox进行损失计算,得到mbox_loss。SSD的损失函数如公式(1)所示,由每个默认框的定位损失与分类损失构成。
Sigmod激活函数如图6所示,从图中可以看出,当数值逐渐增大时,函数斜率趋近于0,因而在反向传播时会出现导数值为零的现象,不易进行训练和计算,也即常说的梯度饱和现象。
基于以上缺陷,本文改用Relu作为激活函数,如图7所示为Relu函数曲线。
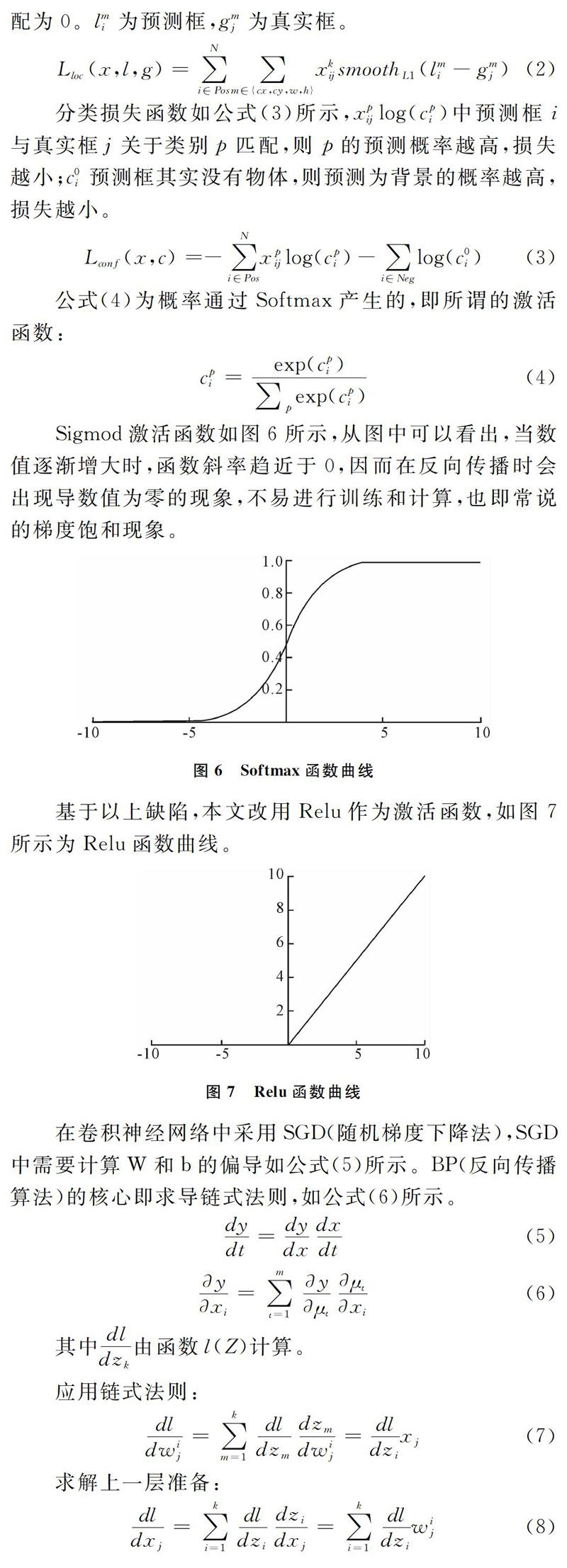
在卷积神经网络中采用SGD(随机梯度下降法),SGD中需要计算W和b的偏导如公式(5)所示。BP(反向传播算法)的核心即求导链式法则,如公式(6)所示。
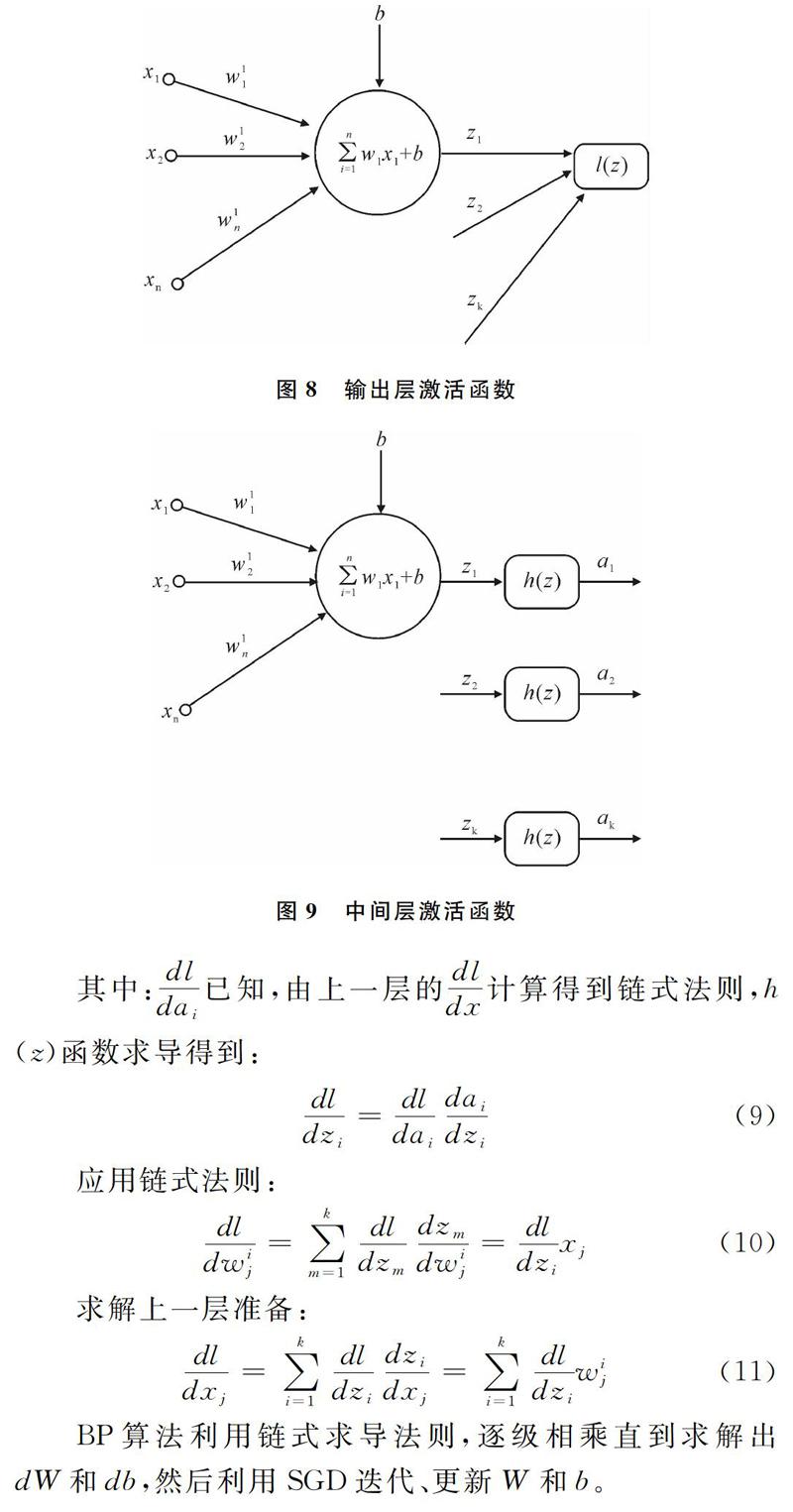
BP算法利用链式求导法则,逐级相乘直到求解出dW和db,然后利用SGD迭代、更新W和b。
2.3 SSD训练过程
本文采用一个SSD预训练模型,将预训练模型在自己的数据集上进行训练,生成全新的检测模型。
首先,准备原始数据。数据集要满足以下格式:–Annotations ***.xml(标注的物体信息文件);--Images ***,jpg(图片集);--ImageSets test.txt(测试集) train.txt(训练集);--results (null)(作为保留结果)
其次,生成训练数据集。具体步骤为:
(1)将VOC0712目录下的create_data.sh labelmap_voc.prototxt create_list.sh三个文件复制到数据集目录下。
(2)修改create_data.sh内容。
root_dir=/home/sea/caffe (指定SSD目录)
data_root_dir="MYMHOME/caffe/data/Fruit4"(指定原始数据集路径)
dataset_name="Fruit4"(将要生成的数据集名称)
mapfile="MYMroot_dir/data/MYMdataset_name/labelmap_fruit4.prototxt"(标签映射,注意labelmap_***.prototxt与自己修改的文件名称相对应)
(3)修改create_list.sh内容。
root_dir=MYMHOME/caffe/data/Fruit4(原始数据集路径)
sub_dir=ImageSets(保存train.txt和test.txt目录名称)
sed -i "s/^/\Images\//g" MYMimg_file(保存图片目录名称)
sed-i"s/^/\Annotations\//g"MYMlabel_file (保存标注目录名称)
if [ MYMdataset == "test" ](这里对应test.txt)
if [ MYMdataset == "train" ](这里对应train.txt)
(4)修改labelmap_***.prototxt内容。
没有顺序要求,background不需要更改,打开文件即知如何修改。
(5)运行create_list.sh,会看到数据集目录下生成test.txt train.txt test_name_size.txt。
(6)运行create_data.sh,可看到数据集目录下生成文件中指定的新数据集(例如Fruit4),该目录下保存了lmdb文件,并在example/Fruit4目录下生成lmdb软链接。
最后开始训练。首先复制一份example目录下的ssd文件夹,修改ssd_pascal.py内容,然后运行python example/fruit4/ssd_pascal.py,可以看到网络已开始训练,训练模型保存在models/fruit4_models_fruit4_300×300目录下。
3 实验结果与分析
本文实验都是通过基础网络VGG16[11],在ILSVRC CLS-LOC[12] 数据库预训练得到初始模型,然后在自己数据集上再次进行训练得到最终的车辆检测网络模型。与DeepLab-LargeFOV[13]相似,本文将fc6和fc7转换为卷积层,并且从中抽取样本参数,将pool5 从2*2-s2变为3*3-s1;使用trous算法填充漏洞,并且删除所有的dropout层和fc8层;设置初始学习速率为0.001,动量为0.9,重量衰减为0.000 5,batch size为32,每个数据集的学习速率衰减策略略有不同;然后针对自己的数据集进行训练,完整的训练和测试代码均建立在深度学习框架Caffe[14]下进行;最终生成训练好的网络模型,在coco数据库中检测精度为76%。
本实验使用的处理器为Intel(R)Core(TM)i7-3770,4核8线程,主频3.4GHz,内存32G;显卡采用NVIDIA GTX970,显存4G;操作系统ubuntu16.04,CUDA版本8.0,OpenCV版本为2410,Python版本为Anaconda 3.6,实验图片规格统一为300*300。
因为SSD是一个目標检测网络模型,可以检测多种目标,如图10所示为上海金桥中心某一路口检测车辆的情况。
如图11所示同为金桥中心某一路口的检测情况,其中将检测到的类别用方框框出并标出具体类别和置信度。在试验中设置了检测车辆和行人两种类别,检测结果显示,其基本能够识别出行人和车辆。
如图12所示为上海延安路某一路段的检测情况,该实验不仅标出了类别与置信度,而且显示出运行速度。速度大概为每秒26帧,可达到实时处理要求。
4 结语
本文对现阶段相关的目标检测算法及其相应的设计、训练难度、检测效果、价值可用性等方面进行了全方位对比,提出一种基于学习算法SSD的实时车辆检测模型,并给出该模型搭建、损失函数求解、训练过程实现及测试等相关步骤,然后将模型的训练测试代码在深度学习框架Caffe上加以实现,最后在不同路口场景下进行实验分析。实验结果表明,该目标检测模型可实时对道路车辆拥堵情况进行精确检测,精度为76%左右。系统具有安装方便、检测精度高、性价比高等优点,对于后续道路路口车辆的拥堵检测研究具有一定参考价值。
参考文献:
[1] 张慧,王坤风,王飞跃.深度学习在目标视觉检测中的应用进展与展望[J].自动化学报,2017,43(8):1290-1304.
[2] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C].Computer Vision and Pattern Recognition, 2005:886-893.
[3] LOWE D G.Distinctive image features from scale-invariant keypoints [J].International Journal of Computer Vision, 2004,60(2):91-110.
[4] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutionalnetworks for visual recognition [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2015,37(9):1904-1916.
[5] GIRSHICK R. Fast R-CNN [C].Proc of IEEE International Conference on Computer Vision,2015:1440-1448.
[6] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [C].Advances in Neural Information Processing Systems,2015:91-99.
[7] DAI J, LI Y, HE K, et al. R-FCN: object detection via region-based fully convolutional networks [C].Neural Information Processing Systems, 2016:379-387.
[8] REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, realtime object detection [C]. Proc of IEEE Conference on Computer Vision and Pattern Recognition,2016:779-788.
[9] LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C].Proc of European Conference on Computer Vision, 2016:21-37.
[10] GIRSHICK R. Fast R-CNN[C].ICCV,2015:1440-1448.
[11] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]. NIPS,2015.
[12] RUSSAKOVSKY O, DENG J, SU H,et al. Imagenet large scale visual recognition challenge[J]. International Journal of Computer Vision , 2014,115(3):211-252.
[13] CHEN L C, PAPANDREOU G, KOKKINOS I, et al. Semantic image segmentation with deep convolutional nets and fully connected CRFs[J]. Computer Science, 2014(4):357-361.
[14] 深度學习:Caffe实战[N].中华读书报,2016.
(责任编辑:黄 健)
