基于卷积神经网络的室内场景识别
2018-08-22蔡青青孙丽红
杨 鹏, 蔡青青, 孙 昊,3, 孙丽红
(1.河北工业大学 人工智能与数据科学学院 天津 300130; 2.智能康复装置与检测技术教育部工程研究中心 天津 300130; 3.河北省控制工程技术研究中心 天津 300130)
0 引言
场景识别是移动机器人系统的重要研究内容,其作用是移动机器人系统提供场景的语义上下文和先验信息,使智能机器人理解所处场景从而适应更加复杂的环境.在近年研究中,场景识别方法大多为提取场景特征,按照提取特征的性质可以将场景识别方法归为基于全局特征与基于局部特征两类.全局特征包括颜色、纹理、形状等低层特征,局部特征包括尺度不变特征变换(scale-invariant feature transform,SIFT)特征[1]以及梯度方向直方图(histogram of oriented gradient,HOG)特征[2]等.然而,上述技术应用于室内场景识别问题上无法获得理想的识别结果.这是因为相较于户外场景,室内环境具有排列无序、复杂的特点,缺少显著的局部或全局视觉特征.与上述传统手工特征不同,通过卷积神经网络提取的特征含有更加丰富的结构信息,具备可辨别能力强、旋转不变性等优势,已成为研究图像分类问题的重要工具.LeCun于1998年设计了卷积神经网络LeNet-5,实现了对手写数字的识别.在那之后,随着互联网大数据的兴起,卷积神经网络已经在图像理解领域中获得广泛应用[3-5].
基于以上研究成果,本文摒弃了传统人工提取场景特征的方法,选择了卷积神经网络结构,应用目前识别精度较高的GoogLeNet模型来完成室内场景的识别任务,以证明卷积神经网络在室内场景识别问题上的有效性.
1 卷积神经网络
卷积神经网络(convolutional neural network,CNN) 是带有卷积结构的深度神经网络,通过网络的卷积结构减小参数个数,简化计算过程,并采用dropout[6-7]等方式缓解过拟合问题,优化神经网络结构,提高识别的准确率.
1.1 卷积神经网络的网络结构
卷积神经网络是一个多层结构的网络,如图1所示,卷积神经网络由卷积层、下采样层和全连接层构成.输入首先通过滤波器在卷积层进行卷积后可获得一些特征图,下采样层经过池化处理后,由全连接层输出.

图1 卷积神经网络结构Fig.1 Structure of convolutional neural network
1.1.1卷积层 卷积层通过卷积运算使输入信号增强,噪音减小.卷积层的输入与上层感受野相连来提取特征,同时得到与其他特征间的位置关系.卷积层输出的特征计算方法为
(1)
1.1.2下采样层 下采样层也被称为池化层,卷积神经网络中每一个卷积层后都有一个下采样层,因为经卷积层所得特征数据量过大,若直接用于训练会增加网络模型复杂度.因此,可以通过对特征局部进行池化来降低特征的维度.同时,池化可以一定程度上改善卷积神经网络的过拟合问题,经过两次特征提取后可以使网络对输入有较强的畸变容忍能力.
1.2 局部感知与权值共享
卷积神经网络通过局部感受野和权值共享两种技术来减少网络参数.不同于以往的全连接方式,每个神经元仅需与局部图像相连感知局部信息,并将局部信息结合从而获得图像全局信息.通过局部连接的方式能够显著降低网络参数的个数,优化网络的性能.卷积神经网络还通过权值共享的方式来尽可能降低网络参数的数量,即在卷积神经网络同一个卷积核内,将所有神经元权值设置为相同值,从而降低网络的复杂度,加快训练速度.
2 GoogLeNet模型
通过加深网络深度可以提高识别的准确率,但网络规模的增大也使网络结构变得更加复杂,会大大增加网络训练的计算量,还有可能在训练过程中出现过拟合问题.而且,仅仅通过增加网络规模来提高识别准确率的做法无法提取更加有效的图像特征. 因此,由Szegedy等[5]设计的GoogLeNet网络模型不仅增加卷积神经网络的层数,还应用Inception模块得到了更优越的网络性能.Google团队优化了基本的特征提取单元,使用优化后的特征提取模块构建网络.实验证明了基于该思想设计的GoogLeNet模型具有良好的识别效果,且参数也小于AlexNet模型的网络参数,是目前性能出色的网络模型之一.
GoogLeNet模型是一个具有22层结构的深度卷积神经网络,模型除卷积层、池化层以外,还有Google团队提出的Inception结构.Inception结构采用不同尺度的卷积核优化网络中基本的特征提取单元,用优化后的特征提取模块去构建网络.文献[9]介绍了一种逐层结构,对结构最后一层的单元进行相关性统计,并将具有高相关性的单元聚集在一起形成簇,用这些簇去构成下一层的单元.假定上一层的单元与输入图像某一区域有对应关系,被滤波器分成若干组.低层靠近输入的相关单元会在局部区域聚集,最后可以获得一个区域的大量群,可以在下一层通过1×1卷积覆盖.而且可以利用覆盖更大的空间来减少单元组的数量.为了避免块对齐问题,基于方便性考虑,目前将Inception模块的滤波器大小限制在1×1、3×3、5×5.此外,由于池化操作对于目前成功的卷积神经网络是必不可少的,因此额外在每个模块上添加一个并行的池化结构.
基于此,Google团队提出了如图2所示的模型A.模型A中,卷积核与感受野的尺寸都不一样,那么后面的组合即代表多尺度数据融合.考虑到对齐问题,卷积核尺寸选择1、3和5.然而,网络越到后面,每个特征所涉及的感受野越大.因此,层数的增加会导致计算量大的问题,必须使用1×1的卷积核降低维度,改进后的Inception模型B如图3所示.总体来说,Inception结构的中心思想就是找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,达到优化网络模型的目的.

图2 模型A[5]Fig.2 Module A
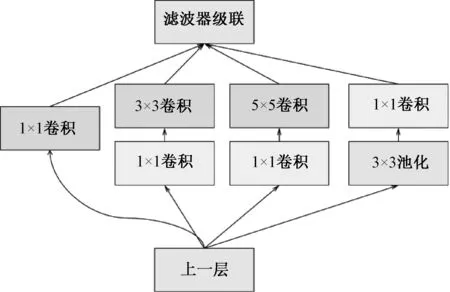
图3 模型B[5]Fig.3 Module B
3 实验结果与分析
3.1 数据集
评价所用模型的室内场景识别效果时要选择一个合适的数据集.深度卷积神经网络在训练过程中要求大量的图片作为输入数据,因此实验所选的数据集应包含丰富的场景图片,且之前有研究者做过相应研究并取得一定的成果,以便与本文所选方法做对比.基于以上要求,本文选用了在场景识别领域应用广泛的MIT_Indoor数据集[10].MIT_Indoor数据集是分类多样的室内场景应用数据集,数据集一共含有67种室内场景的总共15 620幅图片,不仅包括日常的生活场景如客厅、厨房、卫生间等,还包括发廊、洗衣店、酒窖等多种室内场景.
为了对模型进行训练并验证训练好的网络模型性能,首先对数据集进行标记,将67种场景图像的类别分别用0~66的数字表示出来.实验前将MIT_Indoor数据集的全部图像分为训练集和测试集两部分,其中训练集约占总数据集的80%,测试集占20%.
3.2 网络模型训练
进行场景识别前需要构建网络,如今实现深度卷积神经网络已经有了框架,比如Caffe、Torch、MXNet以及TensorFlow等深度学习框架,本文实验中采用的为Caffe[11].Caffe(convolutional architecture for fast feature embedding)是一个清晰而高效的深度学习框架,核心语言是C++,支持命令行、Python和MATLAB接口,且可以在GPU上运行.它直接集成了卷积神经网络神经层,提供了大量的示例模型,其中包括LeNet、AlexNet以及本文将要用到的GoogLeNet模型.
Caffe以四维数组blobs方式存储和传递数据,利用层之间的计算结果传递每层的输入和输出.训练要求输入的原始图像尺寸是一致的,因此在Caffe上训练卷积神经网络前,要对输入图像进行预处理,并改进数据的质量,使学习算法获得更好的效果.为了增加数据的多样性,利用翻转、旋转的数据增广来产生新的图像,如图4所示.图像的尺寸会影响卷积核的选取,如果图像尺寸过大,会增大运算量,耗费过多时间;如果图像太小,会导致图像有效信息的缺失.因此,通常情况下会选择256×256像素作为图像的尺寸大小.将所有图像的短边缩放到 256 像素,根据比例调整图像尺寸,留下中间224×224像素的部分,并经数据归一化操作后作为模型的输入.

图4 数据增广Fig.4 Data augmentation
本文选用的GoogLeNet模型在Caffe中有具体的网络定义文件,详细定义了网络结构各层的参数,实验中未进行修改.训练前只修改训练过程和测试过程所需要的参数,比如学习率、权重衰减系数、迭代次数、使用CPU还是GPU等.实验中使用MIT_Indoor室内场景数据集来进行训练和测试,本文对原模型参数进行了如下修改:每100次迭代进行一次测试,测试间隔为500次,初始化学习率为 0.01.每100次迭代显示一次信息,最大迭代次数为1×106次,网络训练的动量为0.9,权重衰退为0.000 2,每5×104次进行一次当前状态的记录.在GPU模式下进行训练.实验使用的是NVIDIA公司的GeForce GTX TITAN X GPU工作站,运算效率很高,完成一次迭代仅需0.3 s.参数设置完成后,即可对网络进行训练与测试,两天后得到网络模型的识别精度为59.7%.
3.3 结果分析
使用Caffe训练GoogLeNet模型并测试得出结果,与一部分使用传统人工特征提取的算法及其结果进行比较,这些算法是在欧洲计算机视觉国际会议 (European conference on computer vision, ECCV)和IEEE国际计算机视觉与模式识别会议 (IEEE conference on computer vision and pattern recognition, CVPR)上发表的具有一定的代表性,可以用来与本文做对照,如表1所示.在表1中能够发现,基于卷积神经网络的,GoogLeNet网络模型所得到的识别结果高于使用传统特征提取方法的结果,这说明了深度卷积神经网络在室内场景识别上的有效性.

表1 基于MIT_Indoor数据集的识别结果对比
4 结语
本文摒弃了传统的人工提取场景特征的方法,选择了可以自主学习图像特征的卷积神经网络,应用目前识别精度较高的GoogLeNet模型实现了对室内场景的识别,得到了59.7%的正确率,实验结果证明了卷积神经网络在室内场景识别问题上的有效性.随着研究的不断深入,深度卷积神经网络在场景识别领域也越来越受到重视,通过深度卷积神经网络得到的特征能够有效描述场景的语义信息,准确地判断场景与场景和目标与目标之间的差异性和相似性.由此可见,深度卷积神经网络的学习能力在图像分类问题的研究上具有强大的优势.在今后的工作中,会继续优化深度卷积神经网络的性能,从增大训练数据的数量和改进网络结构方面对算法进行更深入的研究,从而获得更加准确的识别结果.
