基于Hadoop云计算平台的车牌识别
2018-08-21侯向宁刘华春
侯向宁,刘华春
(成都理工大学 工程技术学院,四川 乐山 614007)
0 引 言
随着国内机动车辆规模的不断扩大,机动车流量呈爆发式增长,城市交通面临巨大的挑战。车牌识别系统在进行交通管理、处理交通事故、追查被盗车辆以及肇事取证等方面起着非常重要的作用。传统的基于终端的车牌识别系统因受硬件的限制,易导致出现错识、漏识、升级困难,以及一些当前最新的识别算法难以应用等问题。此外,实时性较差、极端环境下的识别率也很不理想。Hadoop云计算平台具有强大的海量数据分发、存储以及对大数据进行并行运算的能力,是大数据处理领域的首选。文中提出的车牌识别系统基于Hadoop云计算平台,充分利用Hadoop云计算平台的各种优势,在实时性、准确性和高效性方面进一步提高车牌识别的效率。
1 Hadoop云计算平台
Hadoop是对大数据进行分布式处理的软件框架,具有高效分发数据,可靠存储PB级数据,便于部署在低成本的普通机群,快速并行处理数据等诸多特点。这些优点使得Hadoop在高效性、可靠性以及经济性上都无与伦比。HDFS和MapReduce是Hadoop框架的核心,其中,HDFS负责对海量数据的存储和管理,MapReduce负责对海量数据进行相关运算。
1.1 HDFS
HDFS(Hadoop distributed file system)是用Java开发的能够运行在通用机器上的具有高容错性、高吞吐量的分布式文件系统。HDFS基于M/S模式,其体系结构由一个NameNode节点和若干DataNode节点构成。NameNode即主控服务器,其职责是维护HDFS命名空间,协调客户端对文件的访问及操作,记录文件数据在每个DataNode节点上的位置和副本信息[1-3]。DataNode是数据存储节点,在NameNode的调度下,负责客户端的读写请求以及本节点的存储管理[4-5]。
1.2 MapReduce
MapReduce是处理海量数据的分布式编程模型和并行计算框架[6]。编程模型便于开发人员高效地开发应用程序,并行计算框架为应用程序在上千通用机器组成的集群上并行处理TB级的海量数据提供了有效保障。
MapReduce分布式计算模型的核心是Map和Reduce函数,依据分治法思想,Map将任务分割成多个子任务,将数据映射为
2 车牌识别
2.1 车牌定位
车牌定位在车牌识别系统中起着至关重要的作用,车牌定位的准确与否,直接会影响到后续的字符分割和字符识别的效率,从而影响整个系统的速度和识别率。从广义的角度,车牌定位可以分为基于灰度图像的边缘检测和基于彩色图像的色彩分割两类[7]:基于灰度图像的边缘检测的优点在于计算量小、速度快、实时性好;缺点是在复杂背景下定位的效果不理想。基于颜色分割定位的优点是在复杂背景下车牌定位的效果很好;缺点是计算量较大、速度不够快,当光照不均,车牌与车身颜色相近时效果不理想。
在众多边缘检测算法中,Sobel算子较为常用,原因在于Sobel算子计算量小,抗噪性较好,边缘检测效果好。与RGB空间相比,HSV颜色空间较符合对颜色的主观体验[8]。因此,文中采用基于HSV空间模型的颜色分割与Sobel算子相结合的定位算法,使得车牌定位的准确性和实时性都得到了较大提升。算法具体流程如图1所示。

图1 基于HSV空间模型的颜色分割与Sobel算子相结合的车牌定位流程
2.2 字符分割与识别
字符分割的流程是首先对已定位的车牌进行颜色判断,然后对蓝、黄车牌分别用不同的阈值进行二值化。为了取得良好的车牌字符分割效果,对二值化后的车牌去除边框及铆钉。然后取字符轮廓求其外接矩形,将外接矩形所在的单个字符区域提取出来,最后对单个字符区域进行归一化,以便送入识别模型进行识别。
在众多字符识别方法中,基于神经网络的识别算法自适应和自学习能力突出,其并行分布处理使得算法实时性较好,即使对模糊、扭曲的字符也能识别,具有很好的容错性[9-10]。
收集3 000个归一化字符区域作为样本,首先对这些样本进行手工分类,贴好标签后,用其中2 100个作为训练样本,将其输入人工神经网络(ANN)的MLP模型中进行训练,反复迭代直至模型收敛。训练完成后,将剩余900个样本输入模型进行测试,进而对参数进一步调优。基于神经网络的字符识别的具体流程如图2所示。

图2 基于神经网络的字符识别流程
3 基于Hadoop云平台的车牌识别
3.1 MapReduce流程设计
MapReduce数据流设计如图3所示。
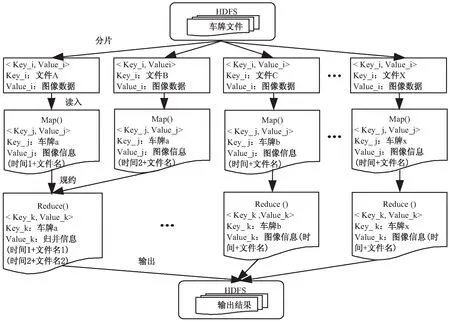
图3 MapReduce数据流设计
Map/Reduce数据流设计是MapReduce流程设计的核心,要对车牌图像数据进行存取、运算及处理,首先要对Map/Reduce相应的输入、输出key/value进行合理的设置[11]。MapReduce框架将存储在HDFS上的车牌文件以
3.2 系统架构
Hadoop云平台的系统架构如图4所示。为方便用户使用Web浏览器对Hadoop云计算平台进行操作,需要架设Tomcat作为应用服务器,因为Tomcat与Hadoop均由Apache基金会开发,且二者结合近乎完美。配置好Tomcat服务器之后,用户就可以通过Web浏览器导入车牌文件,Tomcat服务器接收到车牌文件后调用车牌识别模块并将需要识别的车牌图像文件传给Hadoop云计算平台,通过HDFS将数据分片输入MapReduce进行识别,最后由Tomcat服务器将识别结果反馈给用户。
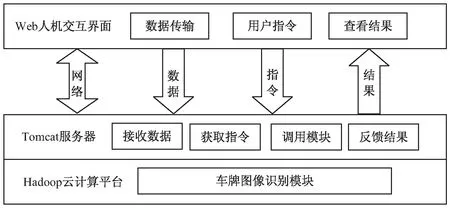
图4 Hadoop云计算平台系统架构
4 实 验
4.1 实验环境搭建
文中采用伪分布式搭建Hadoop云计算平台,优点如下:第一,节省硬件资源,仅需一台内存至少8 G的主机就可享受跟完全分布式一样的环境;第二,操作系统安装简单,只需装一台虚拟机,后续只需复制虚拟机的镜像;第三,节省了重复繁杂配置的无谓耗时,Slave1配置好之后,Slave2和Slave3的配置只需复制Slave1的镜像就可以了;第四,由于三个Slave具有相同的软硬件环境,屏蔽了完全分布式方式下软硬件间的差异,便于最终实验结果的对比和分析;最后,伪分布式便于开发人员进行调试和学习。伪分布式方式下各节点的配置如表1所示。
4.2 实验结果与分析
实验的目的之一是要观察单机及分布式环境下车牌识别数量与系统耗时之间的关系;另外,更重要的是观察分布式环境中不同节点数量的识别速度。实验设置了7组数据,各组需要识别的车牌图像数分别为100,200,300,500,1 000,2 000和3 000。伪分布式环境下节点的个数依次为1,2,3。最终实验结果如图5所示。

表1 Hadoop集群节点配置

图5 识别数量与耗时
实验结果显示,在识别数量较小的情况下,单机与单节点、双节点和三节点的速度相差无几,说明Hadoop云计算平台的优势还没有发挥出来,这主要因为分布式环境下master与slaves之间要进行必要的通信以及数据交换,这无疑增大了系统开销,尤其在识别数量较少的情况下,这种开销不容忽视。随着识别数量的增加,由于单机没有额外的系统开销,因而比单节点的耗时略小;然而单机与双节点、三节点的耗时差异越来越大,这时Hadoop云计算平台并行计算的优势越来越突出,当识别数量达到3 000时,分布式下三节点的识别速度比单机将近快了3.6倍,这主要是因为在海量数据冲击下分布式环境中各节点的负载较均衡,内存消耗比单机的要小很多,正是单机内存的消耗在一定程度上拖累了它的效率。实验结果表明,Hadoop云计算平台在识别海量车牌数据时,其效率和性能远远超越单机,具有很好的应用前景。
5 结束语
在分析车牌识别流程的基础上,设计了基于HSV空间模型的颜色分割与Sobel算子相结合的车牌定位算法,以及基于神经网络的字符识别算法。在研究Hadoop云计算平台架构的基础上,为了将车牌识别算法应用于Hadoop云计算平台,对MapReduce数据流及Hadoop云计算平台的系统架构进行了设计。通过搭建Hadoop云计算平台环境,对基于Hadoop云计算平台的车牌识别系统进行了相关测试。实验结果表明,Hadoop云计算平台在识别海量车牌数据时,其效率和性能远远超越单机,具有很好的应用前景。
