基于蜂群算法的专业任选课程预测模型研究
2018-08-17武丽芬张鸿雁
武丽芬,张鸿雁
(晋中学院 信息技术与工程学院,山西 晋中 030619)
0 引言
提高人才培养质量已经成为国内外高等教育实现大众化以后最为紧迫的任务,而准确的人才培养目标定位则是提高质量的前提[1].
专业基础课程关注学生该专业的基本科学文化素养,追求知识与技能的基础性、系统性,为学生的一般发展奠定基础.但是,随着知识的发展,知识在不断走向分化和细化,知识的不断分化与细化使传统基础课程很难反映人类知识的当代成就,滞后于知识的发展,而专业任选课程则可以弥补必修课的不足,它一方面可以对必修课的内容进行拓展或深化,另一方面,又可以发展学生的技能、特长[1].因此专业任选课在学生的培养环节上作用不容忽视.
1 研究背景
专业任选课是指根据学分制培养目标和要求,为学生开设的专业选修课程,旨在促进学生在课程中的选择性,扩大学生的知识范围,提高学生的智能结构[2].
就晋中学院而言,目前专业任选课的开设目前存在如下弊端:
1.该课程的设置比较随意,因人设课的现象很普遍,教学过程中的随意性更是突出.
2.没有考虑学生的主、客观情况,有悖专业任选课的初衷.
由于没有考虑学生的个体因素,很多学生觉得没有兴趣或不适合自己或对自己的未来没用,诸多原因导致旷课率严重,即使因纪律约束来到教室,也是身在曹营心在汉.学生认为来上课是在浪费时间,对课程内容严重不满.经常听到学生抱怨:“给我们上这个课有什么用,理论性太强也太难,给我们开点有用的课吧.”学生情绪上如此抵触,导致所开设课程的意义全无.
但是何为有用课程,每届学生情况各不相同,有的学生适合学术研究,就希望开设该专业的前沿课程,为今后继续深造打下基础;有的学生适合技术应用,就希望开设当今社会正在流行的应用软件,为今后就业提供一技之长;还有的学生迷茫懵懂,不知自己究竟想学习什么.因此我们不能简单照搬照抄官方规定或名校经验,而应该有一套合理的方法,分析每一届学生的特点,既不拔高也不贬低,既不越位也不缺位,实事求是,因材施教,因材施管,保证不同素质特点的学生健康成长,成人成材.
综上述所,可以考虑给学生一定的自由度让他们自己选择,然而新的问题又出现了.当面临选择时,学生开始困惑和迷茫了,不知道自己选择哪门课程好,患得患失.这也是中国学生普遍存在的问题,不善于为自己做出选择.
鉴于上述情况,基于数据挖掘中的聚类算法设计一个学生专业特点分类器,对学生进行一个大致的分类(理论研究型、实践应用型、技能型等),以辅助教师和学生正确合理的开设相应的专业任选课,使得教学更顺利地进行,学生更加学有所获.
2 算法介绍
聚类是指将具体或抽象对象的集合分组成由类似对象组成的多个类或簇的过程.聚类必须同时满足以下两个条件:1)每个簇至少包含一个数据对象;2)每个数据对象必须属于且唯一属于一个簇[3].在实际应用中,簇中的数据对象可以作为一个整体来对待.
聚类主要包括以下几个过程:
(A)数据准备:主要指特征标准化和降低维度.
(B)特征选择和提取:从原始数据特征中选择有效特征,并存储于向量中.
(C)提取特征:通过对选择的特征进行转换,形成新特征.
(D)聚类:选择适合特征类型的距离函数进行度量,而后执行聚类.
K-means[1]算法也称作K-平均值算法或K均值算法,于1967年由MacQueen提出[2],其原理简单,运算速度快,但它的明显不足是:使用完全随机选择初始化聚类中心点的策略,使K-means算法容易陷入局部最优解,同时对离群点和噪音数据较为敏感,这不仅影响了算法的准确性,而且大大降低了算法效率.
针对上述问题专家学者们不断提出新的解决方法,其中比较著名的有蜂群算法,该算法是一种非数值优化计算方法,也是一种较为新颖的全局优化算法[3],具有结构简单,控制参数少、易于实现的特点.
蜂群算法基本工作原理如下[4]:
步骤1:初始化蜂群.
确定种群的大小,运用构造启发式算法和随机产生方式生成初始种群,比较所有种群个体,按适应度值从大到小进行排序,排在第一位的个体即定义为蜂王,其余个体为雄峰集合.
步骤2:蜂王婚飞行为.
反复执行步骤2至步骤6若干次,直到产生的子代个体数达到种群原始大小.
初始化蜂王受精囊容量和飞行速度,飞行速度Squeen通过式(1)随机生成:
Squeen(speed)=rand()(Smax-Smin)+Smin.
(1)
式(1)中,rand()是随机函数,Smax、Smin分别是蜂王最大、最小速度的初始值.当Squeen(speed)<=Smin,则返回蜂巢.
步骤3:随机选择一个雄峰个体,计算其被蜂王选择的概率.概率Prob(D)的计算式为:
Prob(D)=exp(-|fqueen-fdrone|/Speed(t)).
(2)
式(2)中,fqueen是蜂王的目标函数值;fdrone是雄峰的目标函数值.
步骤4:产生随机数R(0<=R<=1),如果Prob(D)>=R,则将该雄峰的遗传信息存储到蜂王的受精囊中,同时从雄峰集合中删除该雄峰.
不管雄峰的基因是否能够存储到蜂王搜精囊中,蜂王的飞行速度都按式(3)降低.返回步骤5,直到Squeen(speed)<=Smin,或者蜂王受精囊的容量已满.
Speed(t+1)=α×Speed(t).
(3)
式(3)中,α∈(0,1),是每次蜂王速度减小的数量级.
步骤5:产生子代,通过对蜂王及蜂王所存储的雄峰基因个体的交叉产生子代种群个体.
步骤6:培育后代,由工蜂对子代个体进行培育.
步骤7:用新生子代种群集合替换原始种群,并按照其适应度值从大到小排列.
步骤8:检查算法终止条件,如果满足,则终止算法,输出最优解;否则,返回步骤2继续执行[4].
3 实验数据的采集和预处理
①采集数据:提取晋中学院计算机专业某届学生大一到大三的成绩数据.
②对数据进行清洗和预处理:
A.特征选择和提取
从教务系统中采集的数据维度高达56列,经过削减、归类、课程分析最终留下了10列能够反映学生计算机水平的专业主干课程.在此过程中对多个表数据进行合并,筛选相同的课程,从而获取选课人数较多的课程;对其中一些非正常数据如“缺考”等用平均分进行相应替换.
B.清洗数据
现实世界中大多数的数据库均包含异常数据、不明确数据和噪声数据,而几乎所有的聚类算法对这样的数据都非常敏感并会导致获得较差的聚类结果[大数据书本].
本数据源中删除了成绩在10分以下的考生数据并对缺失数据进行均值填充,清洗后的数据如表1所示.
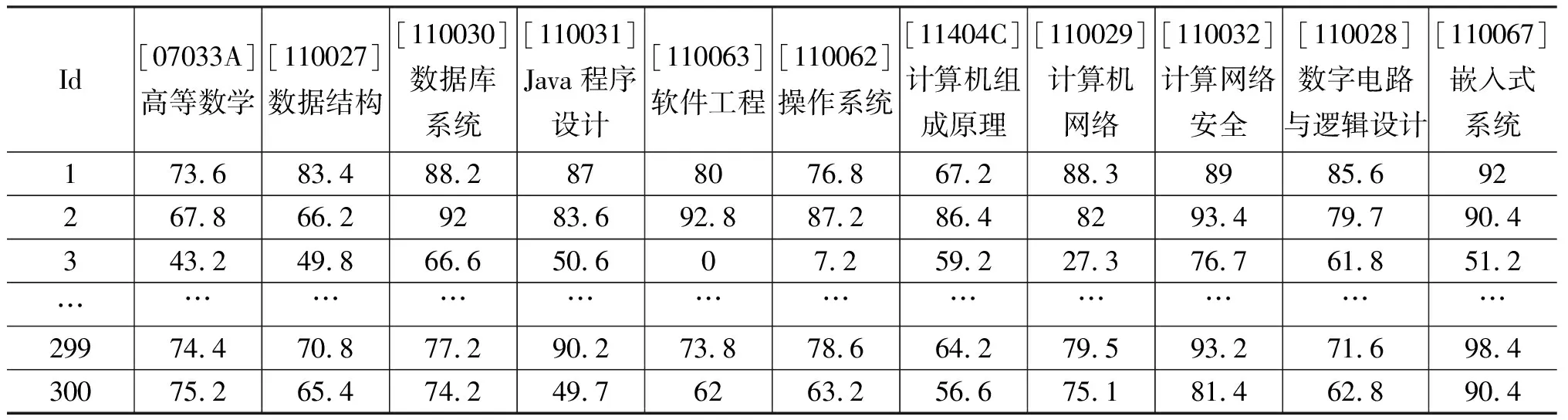
表1 参与聚类分析的数据表
4 实验工具Python简介
实验工具选择Python.Python是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum发明,其源代码和解释器都遵循GPL(General Public License)协议,是一款纯粹的自由软件.
Python由于其简洁的语法、较为全面的功能、可移植性和可扩展性的特点,目前越来越多的科研机构在采用Python做科学计算,还有很多知名大学的程序设计课程在采用Python讲授,比如麻省理工学院的计算机科学编程导论和卡耐基梅隆大学的编程基础就用的是Python语言[5].
实验中部分关键代码如下:
#将原始数据中的索引设置成得到的数据类别,根据索引提取各类数据并保存
df=pd.DataFrame(X,index=labels,columns=columns)
df_list=[]
foriinrange(X_col):
df_list.append(df[df.index==i])
#绘图
plt.figure(figsize=(10,8),dpi=80)
#axes=plt.subplot()
#s表示点大小,c表示color,marker表示点类型
foriinrange(X_col):
plt.plot(range(X_row),X[:,i],color[i])
#显示聚类中心数据点
#type_center=plt.plt(range(X_col),df_center.loc[:,'y'],s=40,c='blue')
plt.xlabel('x',fontsize=16)
plt.ylabel('y',fontsize=16)
#axes.legend((type1,type2,type3,type4,type_center),('0','1','2','3','center'),loc=1)
plt.show()
实验结果用散点图展示如图1所示.

图1 聚类结果散点图
其中蓝色实点为聚类中心,其中心分别为(83.446,86.825)、(81.698,52.571)、(55.815,48.982)、(67.2,75.11).“0”“1”“2”“3”分别表示“理论型”“应用型”“综合型”“技能型”.
实验结果分析,通过聚类模型预演,得出该届学生理论型(红色聚类区)人数居多,且分布相对集中,那么在开设选修课的时候,可以主要考虑这部分学生的情况,这部分学生中绝大部分是要考研的,那么在开设选修课时可倾向于这部分学生开设研究生阶段的前沿、本科生阶段的扩张课程.图中还可以看出棕色聚类区也相对集中,但人数没有红色区域多,那么也可适当考虑开设一些应用型选修课程.
该模型同样可以适用于其他专业,前提是需要对开设课程进行分类处理,按照分类结果对聚类样本进行有效聚类,可以根据学生对知识的理论水平、应用实践能力的相似程度进行学生分类,有的放矢地开设选修课程,一定程度上实现真正的因材施教.
