基于CUDA的高性能对称密码算法实现技术研究
2018-08-11杨海云张梓锌段博坤
◆杨海云 张梓锌 隆 昆 段博坤
基于CUDA的高性能对称密码算法实现技术研究
◆杨海云 张梓锌 隆 昆 段博坤
(中国民航大学计算机科学与技术学院 天津 300300)
在大数据和云计算应用与日俱增的今天,很多的应用服务器面临着执行大量计算稠密的加密挑战。CUDA作为NVIDIA推出的一种并行计算平台和编程模型,能够利用现有的显卡资源,以低成本的方式提升加密性能。在NVIDIA Geforce 940M 上设计并实现了并行的AES和SM4算法,与传统的CPU实现方式进行对比,AES最高可以获得92.70%的加密效率提升和13.69倍的加速比,SM4最高可以获得98.41%的加密效率提升和62.92倍的加速比。
CUDA;并行计算;对称密码算法;加速比
0 引言
在当今诸多的网络应用中,数据加密必不可少。伴随着大数据时代的到来,加密效率已经成为一个不容忽视的问题。同时,计算机正在从只使用CPU的“中央处理”向CPU与GPU并用的“协同处理”发展。CUDA[1]作为NVIDIA公司推出的一种并行编程计算框架,有效利用GPU的计算能力,提高了计算速度。本文将先以基于CUDA的AES和SM4算法[2]为实践基础,研究GPU计算对于这两种常用加密算法的性能提升,进一步探索基于CUDA的对称密码算法设计实现的一般性方法。
1 CUDA简介
CUDA(Compute Unified Device Architecture,统一计算设备架构)是一种由NVIDIA推出的通用并行计算架构,该架构使GPU 能够解决复杂的计算问题。它包含了CUDA指令集架构以及GPU内部的并行计算引擎,开发人员可以使用C语言来为CUDA架构编写程序。它要求计算机的显卡必须支持CUDA技术,然后安装CUDA开发环境即可使用C语言进行编程。
2 AES和SM4算法简介
2.1 AES算法
AES(Advanced Encryption Standard,高级加密标准)是由美国国家标准技术研究所在2001年发布的一种对称加密算法,目前,AES算法已然成为对称密钥加密中最流行的算法之一。
作为一种分组加密算法,AES的分组长度为128bit,密钥长度有三种可选取值:128bit、192bit和256bit。加密时首先将明文切割成为128bit的分组,每个分组首先进行密钥相加,其次按照密钥长度加密不同的轮数。每一轮中有四层,分别为字节替换(SubBytes,使用Sbox进行非线性替换)、行移位(ShiftRows,对每行分别进行0,1,2,3字节的循环移位,达到字内混淆)、列混合(MixColumns,线性变换每列以混淆数据)、密钥相加(AddRoundKey,对轮密钥和状态进行异或运算,进行盲化)。需要注意的是,最后一轮不包括列混合层。加密对应轮数后,即完成了一个分组的加密变换。对其余分组也进行这样的操作,组合每个分组的加密结果,便完成了整个明文的加密[3]。
2.2 SM4算法
SM4是由中国国家商用密码管理办公室2006年发布的一种Feistel结构的分组密码算法,分组长度和密钥长度均为128bit。加解密算法与密钥扩展算法都采用32轮非线性迭代结构。对加密流程中涉及的参数做出如下定义:
加密密钥:
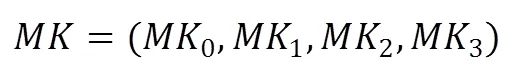
轮密钥由加密密钥扩展而来,表示为:
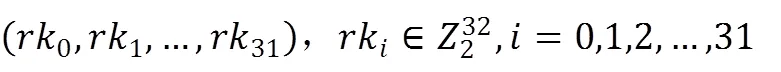
系统参数:
为字,固定参数:
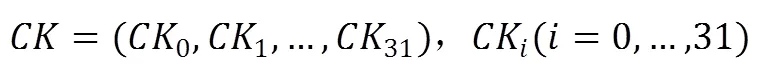
为字,轮函数F为:

输出为:
则:

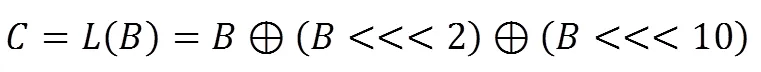
定义反序变换R为:

整个加密的流程图如图1所示。

图1 SM4加密流程图
3 基于CUDA的SM4和AES算法设计与实现
通过上面对SM4和AES的算法介绍可以看出,对称密码算法的主要特点是:明文加密前需要按照分组长度进行切块,各个明文分组加密过程没有影响。这个特点是算法并行实现的理论基础所在。传统的加密程序将明文读取与切块、密钥扩展、分组加密,加密结果整合这四个步骤统一放在CPU上处理,而CUDA提供了一个低成本的并行计算平台,可以将分组加密这个最耗费时间和计算资源的步骤放在GPU上。CPU要做的只是明文读取与切块、密钥扩展、加密结果整合这三个计算量比较小的步骤,这样便大大节省了CPU的计算资源。
GPU的计算线程集中在每一block(线程块)上,计算执行时加载到流处理器上运行[4,5]。所以并发度与流处理器的个数和每个线程块中所能容纳的最大线程数目有直接关系。本实验使用的显卡为NVIDIA Geforce 940M,流处理器有3个,每个线程块的最大线程数目为1024,即每个线程块最大可以让1024个明文分组执行加密运算。GPU的启动参数计算方法如下:
设明文分组个数为n,线程块数目为p,每个线程块中启动的线程数目为q,则:
if(n/3>1024)
p=n/1024
q=1024
else
p=3
q=n/3
然后使用0号线程对共享内存中的S盒等一些必要数据参数进行初始化,从1号线程开始进行加密,对于单个线程来说,它们执行一个分组的完整加密流程,每个block中的各个线程互不干扰,计算各自的加密结果。最后使用线程ID将它们的计算结果收集起来,得到最终的加密结果[6]。
在CUDA程序设计中,将CPU称为主机端,GPU称为设备端[7,8]。通过上面的分析可知,无论是AES,还是SM4。明文文件的读取,密钥扩展,加密结果整合都应该在主机端完成,只有分组加密在设备端。图2总结了实现并行AES和SM4的算法的主要思想。

图2 基于CUDA的SM4和AES算法设计框图
4 实验
4.1 测试方案与步骤
为了比较传统的CPU加密和GPU加密时间,在表1的配置环境下我们设计出如下的测试方案:
第一步:准备1MB, 4MB,8MB,10MB,15MB,20MB,30MB,50MB,100MB的10个文件。
第二步:分别将这10个文件用传统的AES和SM4算法加密20次,计算并记录平均加密时间。
第三步:分别将这10个文件用并行的AES和SM4算法加密20次,计算并记录平均加密时间。
第四步:整理实验数据,计算加密效率与加速比。
定义加密效率S为:

定义加速比r为:

表1 实验环境配置
4.2 实验结果
按照上面的实验步骤,分别可以得到AES算法和SM4算法串行与并行的加密时间。计算对应数据的加速比和加密效率。AES算法的实验数据如表2所示,加速比变化趋势见图3。SM4算法的实验数据如表3所示,加速比变化趋势如图4所示。
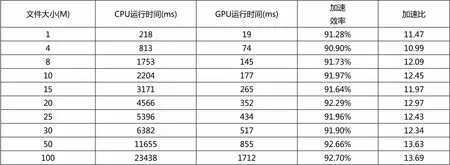
表2 AES算法加密数据统计表

表3 SM4算法加密数据统计表

图3 AES算法性能分析图表

图4 SM4算法性能分析图表
4.3 实验结论
通过表3的数据可以看出,就AES算法而言,加密1MB的小文件,基于CUDA的并行AES算法要比传统CPU加密快11倍,效率提升达到91.28%,伴随着文件大小逐步增加到100M,加速比与加密效率也稳步提升,加密效率峰值达到92.70%,加速比达到13.60倍。结合表4与SM4算法进行纵向对比,SM4算法的效率提升平均在98%,文件大小在100MB时加密效率达到98.41%,加速比达到峰值62.92倍。
实验数据表明,基于CUDA的SM4和AES可以以低成本的方式获得很高的效率提升。是否可以将这种设计方法推广到其他的对称密码算法呢?SM4和AES算法的一个重要的共同特征就是分组加密。各个明文分组之间互不干涉的进行着一次加密流程,可以发现,这也是对称密码算法的特征。需要找出的是每次加密中重复且互不影响的部分,使用GPU上的线程来计算这部分内容,然后将运行结果返回CPU进行整理。这样就可将对称密码算法使用CUDA来重新设计,节省了CPU有限的计算资源,充分发挥了GPU闲置的计算能力,提高密码算法的效率。
5 结束语
本文以解决大量数据加密为出发点,提出了基于CUDA的加密算法实现方法,通过对常用加密算法AES和SM4实验,数据表明,SM4算法最高加速比和效率可以达到98%和62.92倍。说明这种设计思路是合理的,可以推广到其他的对称加密算法。
[1]NVIDIA Corporation. CUDA Technology[OL].
[2]国家密码管理局.国家密码管理局公告第23号.[EB/OL].http://www.sca.gov.cn/app-zxfw/zxfw/bzgfcx.jsp.
[3]马小婷等译.深入浅出密码学[M].北京:清华大学出版社,2012.
[4]刘金硕等著.基于CUDA的并行程序设计[M].北京:科学出版社,2014.
[5]方民权等著.GPU编程与优化[M].北京:科学出版社, 2016.
[6]李大为,赵旭鑫,武萌. SM4密码算法的高速流水线实现[J].电子器件,2007.
[7]苏统华,李东等译.CUDA并行程序设计 GPU编程指南[M].北京:机械工业出版社,2014.
[8]赵开勇,汪朝辉,程亦超等译.大规模并行处理器编程实战(第二版)[M].北京:清华大学出版社,2013.
大学生创新创业训练项目(项目编号:IECAUC2017044)。
