基于旅客出行意图的潜在高价值航线挖掘
2018-08-07李照宇刘康超
卢 敏,李照宇,刘康超,李 纯
(中国民航大学,天津 300300)
我国虽然已形成覆盖沿海发达城市以及重要省会城市的20家区域性枢纽空港,但航线布局呈东密西疏、沿海密内陆疏的发展态势,且航空运输干支网络缺乏有效衔接,使得各个航线不能充分的体现其价值,也无法发挥枢纽机场的中转功能和航空网络的整体效能[1]。因此,如何帮助航空公司合理安排航班航线,减少各航空公司间航班的重叠率,成为航空公司收益管理的重要组成部分。
民航航线挖掘任务是发现具有潜在高收益的航线,进而为航空公司航线开辟提供理论依据,其核心问题是如何准确评估航线的价值。已有的方法可以概括为3大类:
(1)传统航线收益评价方法[2],其核心思想是只考虑单航线历史的收益,航线收益好,公司就继续经营甚至投放更多的运力扩大经营规模,反之,减少运力投放,缩小经营规模;
(2)在航线收益基础上,融入起飞机场和目的机场的经济特性等知识[3];
(3)设计融入航线运营成本的多指标决策问题模型[4]。
由于旅客乘坐的航线本质由旅客的出行需求决定,为此本文提出基于旅客出行意图发现的航线价值计算方法。其核心初衷是:旅客出行受出行目的、季节性、年龄段、出差、旅游等因素的影响,而上述因素最终表现为旅客出行意图,因此航线价值较大程度上取决于旅客的出行意图。
1 基于旅客出行意图发现的航线价值计算
1.1 LDA算法(定义)及其核心思想
概率主题模型最早起源于潜在语义分析(LSI,Latent semantic Indexing)[5], 旨在解决信息检索中面临的一词多义和多词同义的语义问题。在此基础之上,研究者提出更多的概率主题模型,其中经典的概率主题模型是潜在狄利克雷分配(LDA)[6]。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。针对词条件独立的约束,研究者分别提出考虑syntax的主题模型[7]、引入word correlation的主题模型[8]以及term selection的主题模型[9]。针对文档相互独立的假设,由于很多实际应用中文档间存在引用和链接关系,研究者分别提出link-based LDA[10]以及author-topic LDA[11]。针对主题相互独立的约束,提出 topic-link LDA[12]、correlated LDA[13]、hierarchy LDA[14]等。针对没有充分利用文档标注信息,研究者提出supervised LDA[15]。除上述研究之外,研究者还研究了大规模数据上的LDA近似计算及推理模型[16],以及将LDA模型应用于社交网络分析[17-18]。
1.2 问题建模
采用P(a)描述航线a未来旅客的乘坐概率,取值越大表示航线潜在价值越高,其中航线是由起始机场和目的机场决定的,如PEK#SHA表示北京PEK到上海虹桥SHA的航线。航线的价值体现为现在和将来选择乘坐该航线上航班的旅客数量,而航班记录仅是由已乘坐的旅客组成,很多旅客当前未乘坐该航线上航班,并不代表这些旅客将来不会选择该航线,故而不能根据航班记录简单的统计直接得出结论。因此,航线a的潜在价值应该为所有旅客乘坐航线a的概率和,即:P(a)=∑up(a,u)。
1.3 航线价值的计算方法
根据用户出行意图和贝叶斯全概率公式,将航线概率P(a)展开为:

其中:
a—表示航线,如PEK#SHA表示北京到上海的航线;
P(a)—表示航线 a的价值;
u—表示具体某个旅客;
P(u)—表示用户乘坐所有航线的次数,即在航班记录中的乘坐次数,也是用户的重要度;
zu—表示用户u的潜在出行意图z,在LDA中,每位旅客都有对应的出行意图z∈{1, 2, …, K},即LDA中总有K个出行意图,每条航线只能选择其中一个意图,意图标号依次是1, 2, …,K;
P(a|zu)—表示潜在出行意图zu下的航线a分布;P(zu|u)—表示用户u的潜在出行意图zu分布。
公式的物理含义为:用户u乘坐航线a的概率P(a,u),直接由旅客出行意图影响。由于旅客的出行意图zu是不可见的,使用LDA主题模型从预处理过的民航旅客订票日志中挖掘,并根据贝叶斯全概率公式P(a,u)= ∑zup(a, zu,u)和条件独立的假设,进一步展开求解p(a, zu,u)=P(zu|u)P(u)。
旅客u在潜在出行意图zu下选择航线a的概率p(a, zu,u)本质是两阶段形成的:旅客u首先确定潜在出行意图zu,然后才会根据出行意图再选择航线a。在此基础之上,使用贝叶斯条件概率公式将上述概率进一步展开,则p(a, zu,u)=p(a|zu)p(zu|u)。其中,p(zu|u)表示用户u选择潜在出行意图zu的可能性,而p(a|zu)为当前意图zu下选择航线a的概率。
基于上述假设,式(1)中需要求解的是P(u),p(a|zu)和p(zu|u),其中,p(a|zu)和p(zu|u)可通过主题模型LDA进行挖掘。
1.4 模型优化及参数求解
为了快速求解参数P(u),p(a|zu)和p(zu|u),提出基于Map-reduce和LDA的航线价值计算方法。
Map-reduce是一种编程模型,用于大规模数据集(大于1 TB)的并行运算。概念“Map(映射)”和“Reduce(归约)”,是它们的主要思想,都是从函数式编程语言和矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
1.4.1 基于Map-reduce和LDA的航线价值计算方法
(1)输入航班数据;
(2)Map处理:将乘客的每一条乘坐记录单独分割;
(3)reduce处理:以每一个乘客的id作为键,乘坐记录作为值,将旅客所乘坐的所有航班的飞行航线筛选出来合并到一起;
(4)基于LDA的旅客出行意图挖掘,计算p(a|zu)和p(zu|u);
(5)根据公式(1),计算航线乘坐概率P(a)。
1.4.2 基于Map-reduce的民航旅客订票日志数据处理
民航旅客订票日志(PNR)是旅客乘坐航班的信息,对于如此庞大的数据量,一般算法用于有限内存,难以得出LDA的数据源。Map-reduce是基于分布式的针对这种场景的算法,将航班数据文件切割成小段,再对其每一段进行运算,统计每位旅客乘坐的所有航线的集合,得出结果后以旅客身份证(加密)为键值进行归并得到最终的LDA输入数据源,即一行为一个旅客的所有乘坐记录,而每一行内单个词则是旅客的一次乘坐记录,Map-reduce处理过程如图1所示。
1.4.3 基于LDA的旅客出行意图挖掘
LDA有两个先验参数α和β。参数α决定了旅客的意图概率先验分布,而参数β则描述某出行意图下的航线概率先验分布。最终通过LDA模型训练得到旅客-意图概率θ和意图-航线概率φ。 用Gibbs采样估计两个未知参数,主要思想是贝叶斯估计。贝叶斯估计把待估计参数看作是服从某种先验分布的随机变量。
学习过程:给定一个旅客集合,旅客乘坐航线是可以观察到的已知变量,α和β根据经验给定,其他的变量Z(出行意图)、θ和φ都是未知的隐含变量,需要根据观察到的变量来学习估计的。根据LDA的图模型,可以写出所有变量的联合分布:
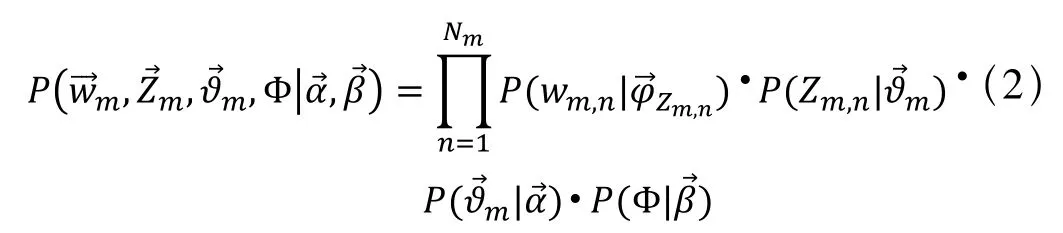
其中:
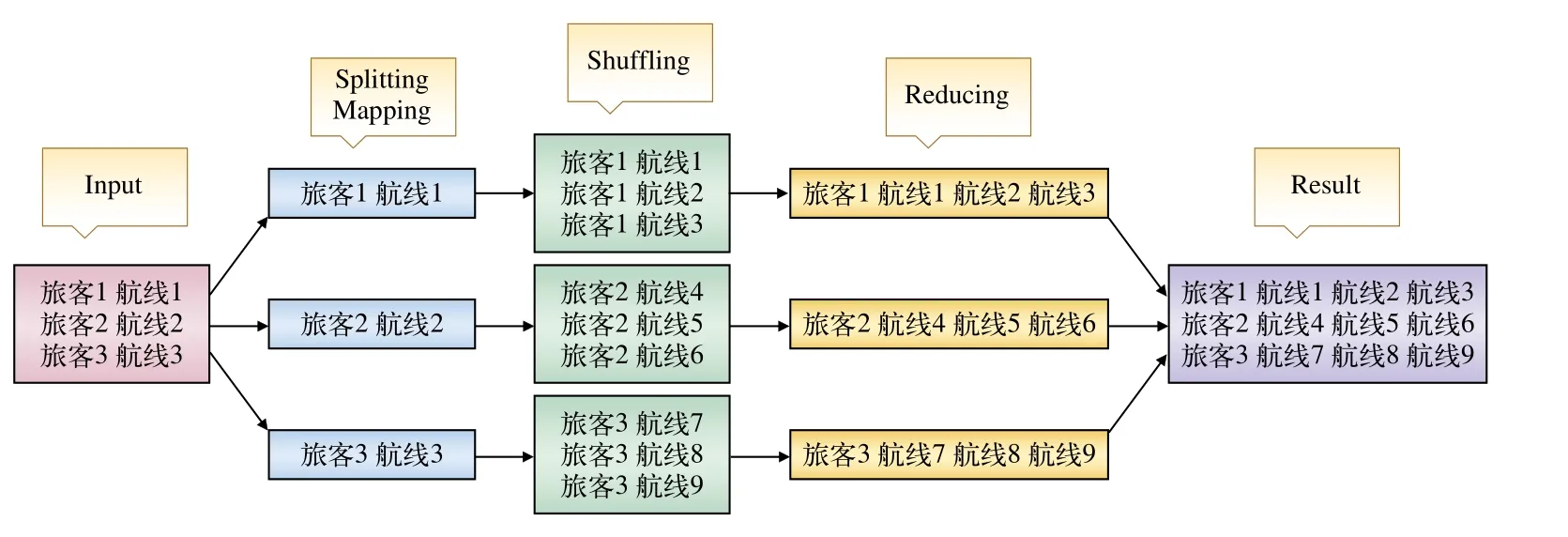
图1 Map-reduce处理过程
Zm,n—表示从意图的多项分布ϑm取样生成旅客m第n个可选航线的意图;—表示从狄利克雷分布β中取样生成意图Zm,n对应的航线分布;
wm,n—表示旅客m最终选择的航线n。
因为意图分布θ,确定具体意图,且β产生的航线分布φ,确定具体航线,所以式(2)等价于式(3)所表达的联合概率分布:
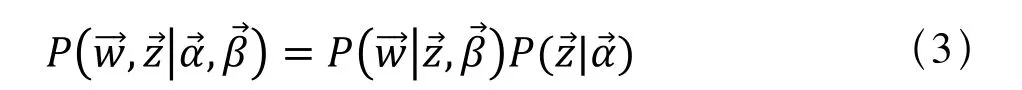
公式的物理含义为:第1项因子表示的是根据确定的意图和航线分布的先验分布参数采样航线的过程,第2项因子是根据意图分布的先验分布参数采样意图的过程,这两项因子是需要计算的两个未知参数。
根据推算得到P(,)的联合分布结果为:
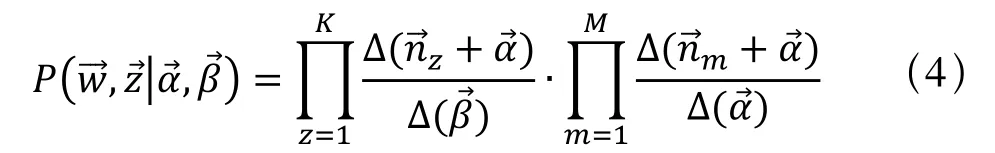
有了P(,)联合分布,便可以通过联合分布来计算在给定可观测变量w下的隐变量z的条件分布(后验分布)P(,),进行贝叶斯分析。
先定义几个变量:¬i表示除去i的航线,。排除当前航线的意图分配,即根据其他航线的意图分配和观察到的航线来计算当前航线的意图的概率公式为:

经推导得到结果:
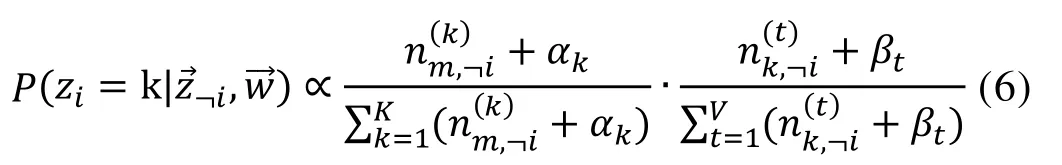
其中,是旅客m的意图数向量,是意图k下的航线项数向量。Gibbs Sampling通过求解出意图分布和航线分布的后验分布,从而成功解决意图分布和航线分布这两参数未知的问题。
2 试验与分析
2.1 数据及其预处理结果
对中国民航信息股份有限公司(TravelSKY Technology Limited)2010—2011年共计48 G的航班记录做预处理,将乘坐次数5次和10次以上的旅客记录借助Map-reduce算法在Hadoop分布式平台上分别筛选出来,然后以旅客身份证号(加密)将筛选过的航班记录的特征性信息(每个旅客乘坐过的航线)提取出来,整个文档中每一行表示一个旅客,行中每一词即是该旅客乘坐过的航班航线。
表1是原始数据经过Map-reduce平台进行数据预处理,筛选出来的乘坐次数大于等于5次的航班记录。第1行为旅客总数量,其他每行则是单一旅客乘坐过的航班航线记录。每条航线记录由6个大写英文字符构成,前3个字符是出发机场三字码,后3个则是到达机场三字码,如NKGSZX表示从南京(NKG)到深圳(SZX)的航线。

表1 经过Map-reduce预处理过的数据示例
2.2 传统方法
基于航班次数统计的航线价值计算方法:统计各航线的旅客乘坐次数,进而计算P(a)。

2.3 评价指标
Jaccard index又称为Jaccard相似系数(Jaccard similarity coefficient),用于比较有限样本集之间的相似性与差异性,Jaccard系数值越大,样本相似度越高。
给定两个集合A、B,Jaccard 系数定义为A与B交集的大小与A与B并集的大小的比值,定义如下:
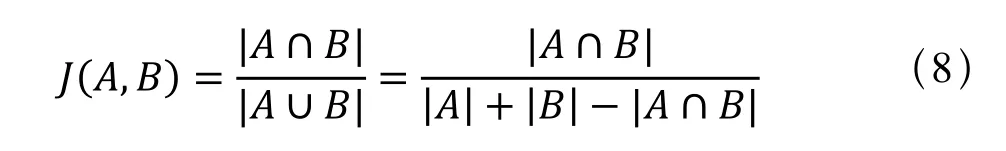
当集合A,B都为空时,J(A,B)定义为1。
真实列表通过统计航线热度(即航线乘坐次数)并倒序处理得到;而本文的航线预测列表则是首先通过公式(1)计算所有航线的价值,然后按照价值从高到低进行降序排列。为了更加彰显算法的性能优势,本文选择排序列表的前TopK个航线计算Jaccard 系数。
2.4 实验设置
(1)参数 α, β 的设置
α和β是LDA模型中旅客出行意图分布θ和意图下航线分布φ的先验分布的先验参数,这两个参数的设置会影响θ和φ的生成,从而影响最终航线价值,α和β取值范围皆为0.1~0.9。
(2)参数k的设置
k值为主题数,其值会影响θ矩阵的列数和φ矩阵的行数,取值范围根据内存大小而定,实验中取值为 :10、20、50、80、100。
2.5 实验结果
(1)热点航线挖掘
以航线潜在价值(预测序列)为键进行排序得到表2,并与其对应真实航线乘坐次数进行对比,可以发现两者并不完全正比,说明航线潜在价值会受其他因素影响,传统算法具有一定局限性。
(2)性能对比
3组最优LDA模型与传统算法的性能对比见表3,可以发现,与传统算法相比,本文算法在top100内参数设置为α=0.8, β=0.3,k=20时指标提升2%,但在top500和top1 000范围内性能与传统算法相差无几,可见这组模型在top100是性能表现最优。另外两组模型类似,分别在top500和top1 000内达到性能最优,并且性能指标分别高于传统算法2%和1%,说明LDA模型可以通过调整先验参数可以挖掘不同范围内比传统算法更加有效的航线潜在价值。
2.6 实验参数分析
进行多组实验,将旅客乘坐次数大于10次以上和5次以上的筛选出来,作为LDA模型输入,并对结果进行统计分析,得到top100、top500、top1 000下各模型的性能,如表4、表5所示。通过表4可以发现,本文算法在top100时能够取得92%的Jacarrd相似系数,说明算法有效。
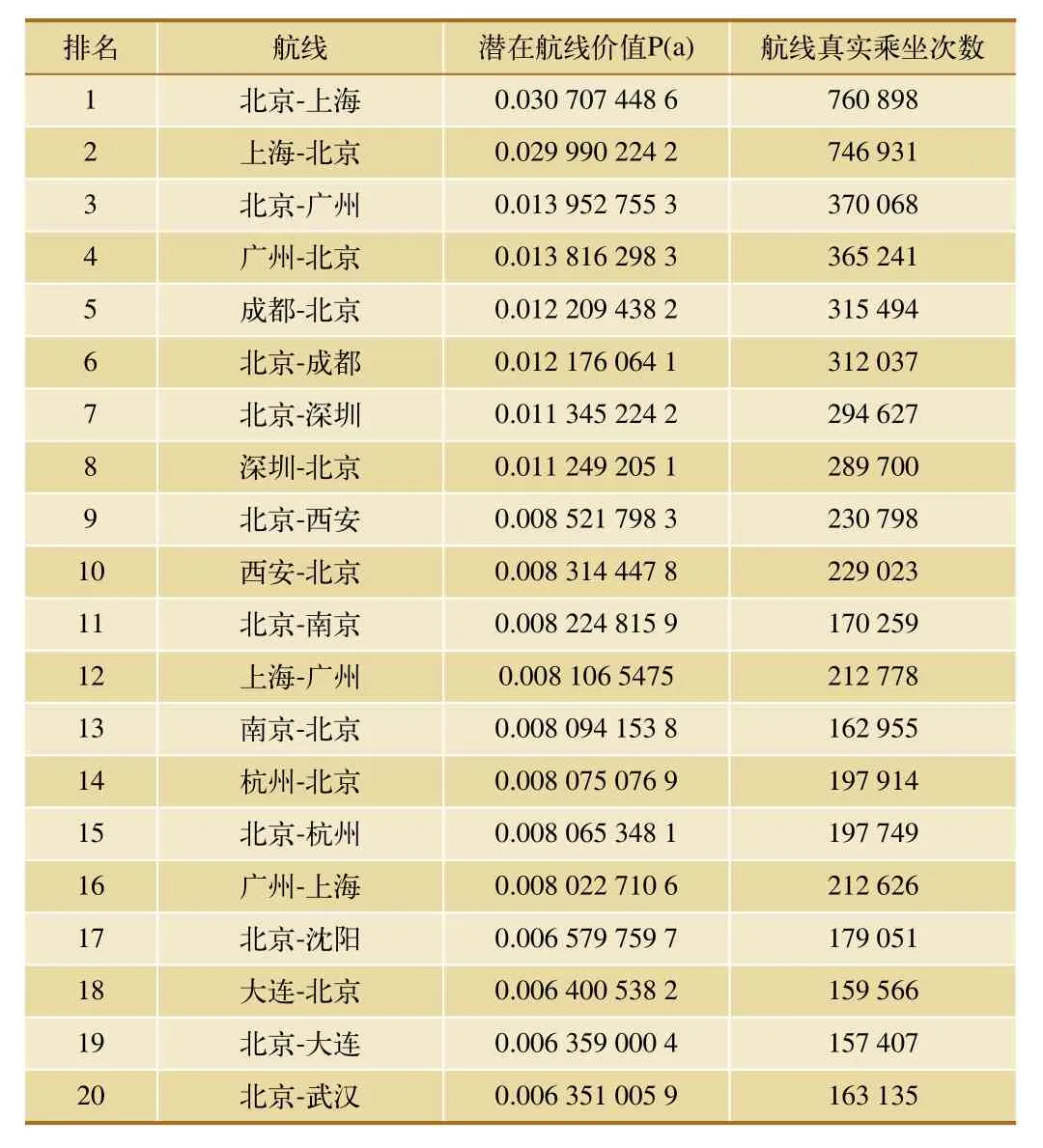
表2 航线潜在价值排名top20
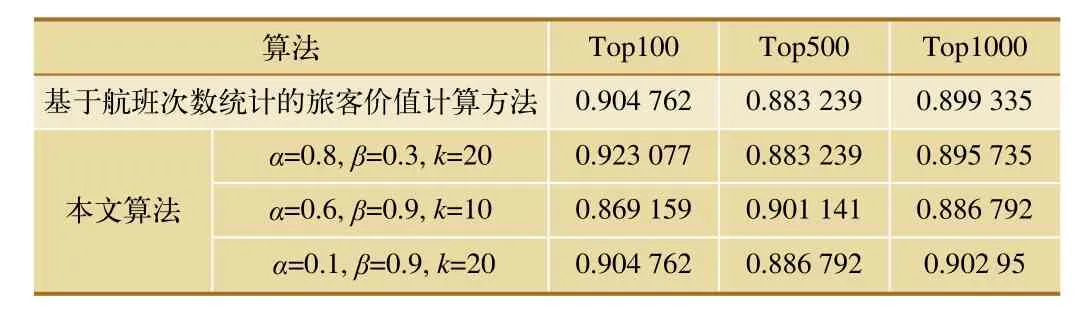
表3 实验性能对比
通过实验数据发现,不同范围内算法性能也不一样,α、β、k三者同时影响航线价值。可以看出,k=10的记录占top rank的大部分(实验中,k=10、50、80、100),意味着旅客出行的潜在意图的数量占10个的概率极大。
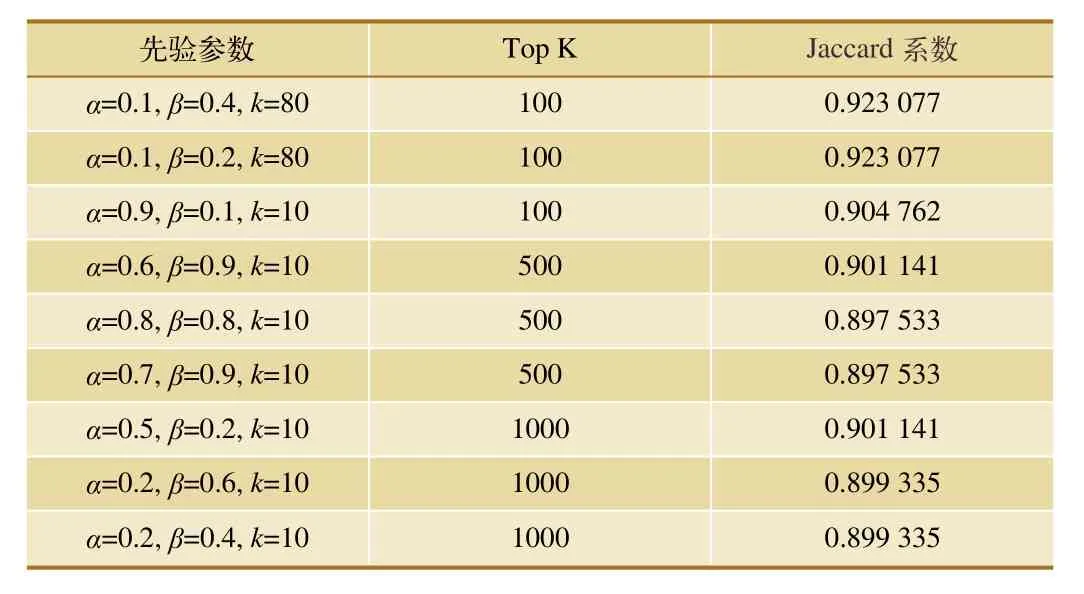
表4 性能评估,旅客乘坐次数为10次以上
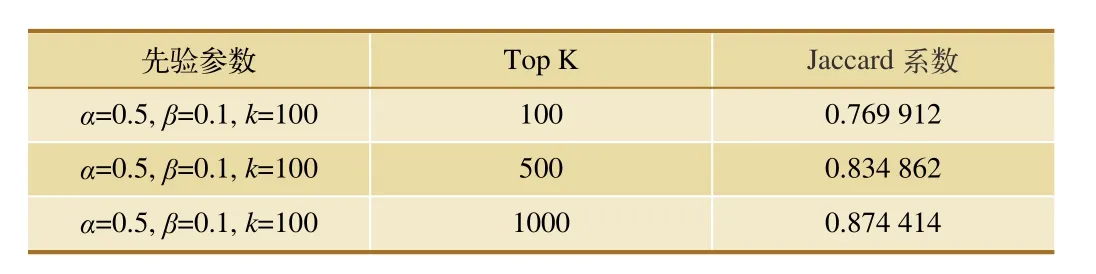
表5 性能评估, 旅客乘坐次数5次以上
3 实验结果分析
通过实验可以发现,虽然传统算法计算的航线价值实现简单,并且准确度也不低,但其挖掘潜在价值的方式是基于航线的历史使用情况,所以预测效果存在偏差;而LDA与传统算法比较,准确度较高,能挖掘出更多的航线,并且算法模型可控,能够适应旅客基于多种潜在出行意图下的航线价值,同时具有可扩展性,可以通过词扩充来提高航线的概率。综上所述,LDA算法对于挖掘潜在模式具有一定的优势。
4 结束语
本文从旅客出行行为的角度出发,将出行的不同因素归结为出行意图,从而利用出行意图得到航线数据。(1)构建了面向大规模民航旅客订票数据分析的Map-reduce平台,处理中航信2010年和2011年的48 G订票日志。(2)提出了基于旅客出行意图发现的潜在高价值航线挖掘算法,通过挖掘在大规模旅客订票日志的旅客出行意图,计算航线未来潜在概率,丰富了机场的航线营销和航空公司的航线网络布局技术。(3)面向大规模的LDA主题模型构建方法,丰富了主题模型构建方法,可拓展到其他大规模数据的主题模型中。
