基于聚类分析算法的铁路通信设备厂商信息智能分类
2018-08-07王华伟
赵 颖,王华伟
(中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
铁路通信设备是铁路运输生产的基础,是铁路实现集中统一指挥的重要保障,为实现对铁路运输设备技术状态的全面掌控和精益化管理,铁路相关部门组织开展了铁路通信大数据平台相关技术的研究,实现了对通信设备的履历化管理,以及设备全生命周期管理、故障预测、健康管理、状态评价等应用服务[1]。
通信设备履历管理是通信大数据平台的一个重要组成部分,而建立设备履历需要一系列字典信息作为基础,包括组织机构字典、通信机房字典、产品生产厂商字典等。其中,产品生产厂商字典由各铁路局用户通过系统录入并上报,需要对数据进行分析归类,再通过人工审核,最终才能形成规范的字典数据。
机器学习作为人工智能领域的一个重要分支,近年来在解决现实生活中的实际问题上发挥了显著的作用,其中,在对无标记样本的分类任务中,研究最多、应用最广的是“聚类”[2]。因此,通过研究并选择一种高效的聚类分析算法,实现对通信设备厂商信息的智能分类,是铁路通信设备大数据平台的一项重要工作。
1 聚类分析
1.1 算法介绍
在“无监督学习”中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。聚类分析将相似的对象归到同一个簇中,将不相似的对象归到不同的簇中。聚类方法几乎可以应用于所有对象,簇内的对象越相似,聚类的效果越好。相似这一概念取决于所选择的相似度计算方法,而采用哪种相似度计算方法取决于具体的应用。
1.2 相似度计算方法
欧氏距离是一种常用的距离定义,指在m维空间中两个点之间的真实距离,对多维向量A=(A1,A2,……,An),B=(B1,B2,……,Bn),欧氏距离的计算公式为:
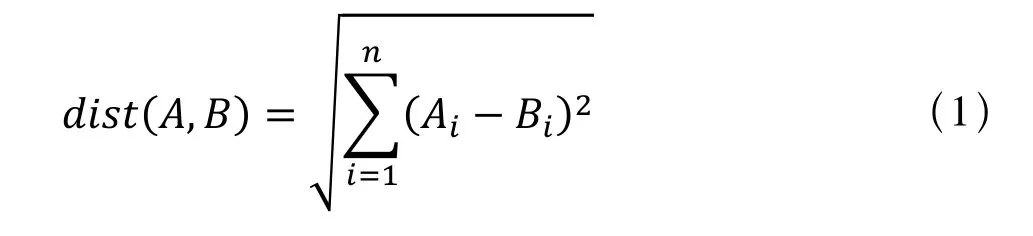
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体差异的大小。相比欧氏距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上的差异。余弦值的计算公式为:
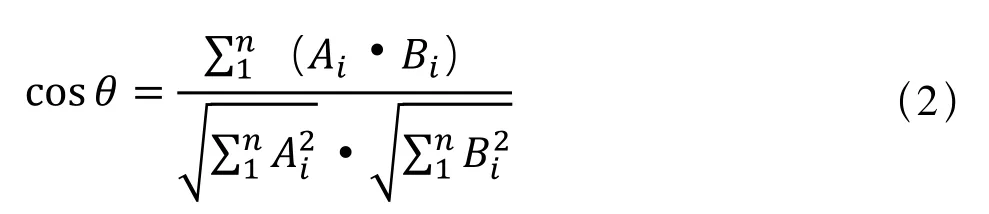
相对于欧氏距离,余弦相似度更适合计算文本的相似度。首先将文本转换为权值向量,通过计算两个向量的夹角余弦值,就可以评估他们的相似度。余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量方向越接近;越趋近于-1,代表他们的方向越相反。为了方便聚类分析,将余弦值做归一化处理,将其转换到[0,1]之间,并且值越小距离越近。
1.3 性能度量
同一个簇内的样本尽可能相似,不同簇的样本尽可能不同,也就是说聚类结果的“簇内相似度”高且“簇间相似度”低。
考虑聚类结果的簇划分C={C1,C2,…,CK},定义:
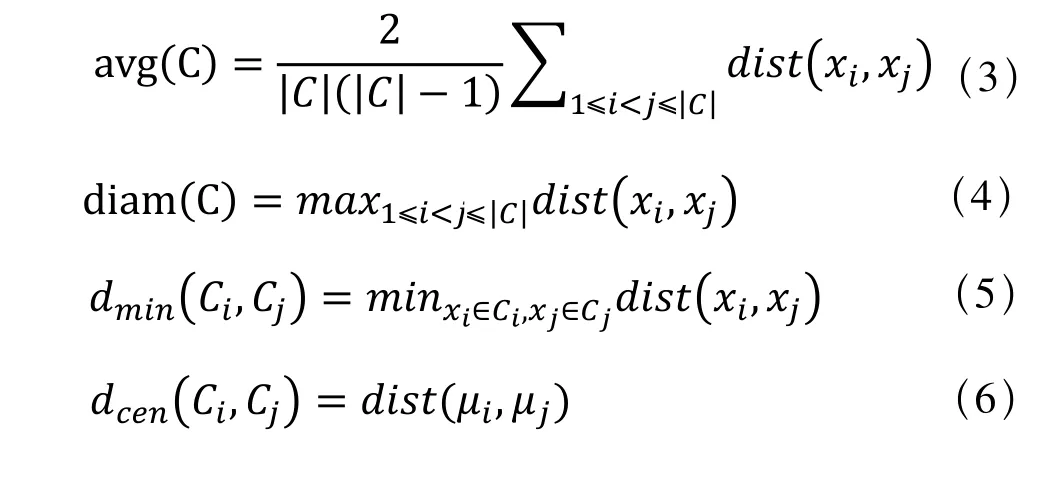
其中,μ代表簇C的中心点;avg(C)代表簇C内样本的平均距离;diam(C)代表簇C内样本间的最远距离;dmin(Ci,Cj)对应于簇Ci和簇Cj最近样本间的距离;dcen(Ci,Cj)对应于簇Ci和簇Cj中心点间的距离。
基于以上公式可导出下面2个常用的聚类性能度量内部指标:
(1)DB 指数(DBI,Davies-Bouldin Index)
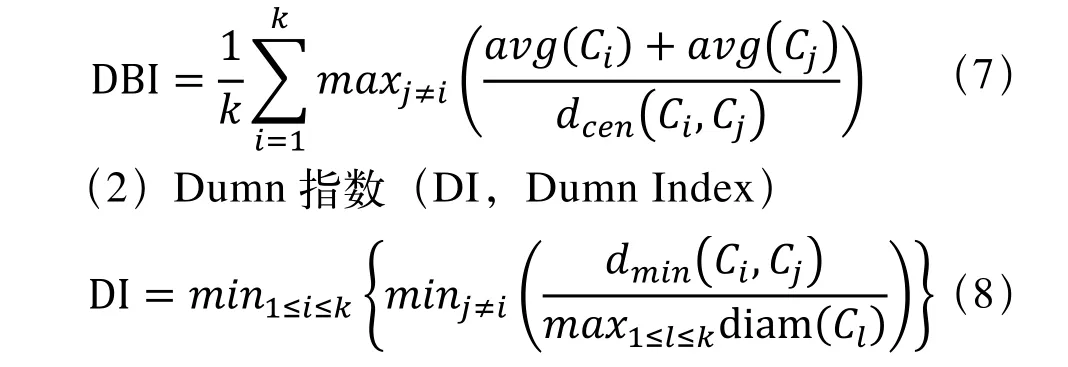
DB 指数的计算方法是任意两个簇内样本的平均距离之和除以两个簇的中心点距离,并取最大值,DBI 的值越小,簇内距离越小,同时簇间的距离越大;Dumn 指数的计算方法是任意两个簇的最近样本间的距离除以簇内样本的最远距离的最大值,并取最小值,DI 的值越大,簇间距离大而簇内距离小。因此,DBI 的值越小,同时DI 的值越大,聚类的效果越好。
2 数据预处理
2.1 分词处理
对中文文本做聚类分析,首先要对文本做分词处理,Python提供专门的中文切词工具,它可以将中文长文本划分为若干个单词。
为了提高分类的准确率,还要考虑两个干扰因素:(1)英文字母大小写的影响,为此我们将英文字母统一转换为大写;(2)将某些通用词汇连同“()”、“-”、“/”、“&”等符号作为停用词,将其从分词结果中去除掉,最后得到有效的词汇组合。分词并去除停用词后的效果图如图1所示。
2.2 构建词袋模型
文本被切分成单词后,需要进一步转换成向量。将所有文本中的所有词汇构建成一个词条列表,其中,不含重复的词条。再对每个文本,构建一个向量,向量的维度与词条列表的维度相同,向量的值是词条列表中每个词条在该文本中出现的次数,这种模型叫做词袋模型[3-5]。例如,“阿尔西集团”和“阿尔西制冷工程技术(北京)有限公司”两个文本切词后的结果是“阿尔西 集团”和“阿尔西 制冷 工程技术北京”,它们构成的词条列表是[阿尔西, 集团, 制冷,工程技术, 北京],对应的词袋模型分别是[1,1,0,0,0],[1,0,1,1,1]。
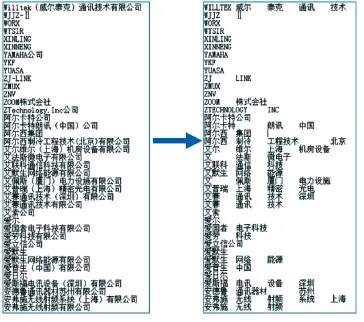
图1 厂商名称分词效果图
2.3 权值转换
TF-IDF是一种统计方法,用来评估一个词条对于一个文件集中一份文件的重要程度。TF-IDF的主要思想是:如果某个词在一篇文章中出现的频率TF高,并且在其他文件中很少出现,则认为此词条具有很好的类别区分能力,适合用来分类。
(1)词频(TF,term frequency):

分子是词条ti在文件dj中出现的次数,分母是文件dj中所有词条出现的次数之和。
(2)逆向文件频率(IDF,inverse document frequency):
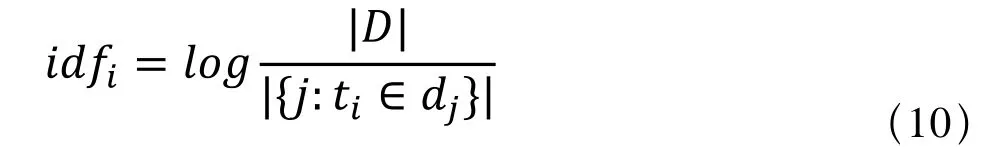
对数内的分子是文件总数,分母是包含词条ti的文件数,如果该词不存在,就会导致分母为零,因此一般使用1+|{j:ti∈dj}|作为分母。
(3)TF-IDF:
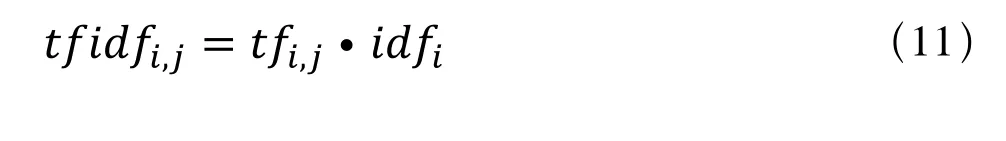
将TF与IDF相乘得到TF-IDF权值。由以上定义可知,一个词语在某一特定文件中出现的频率高,在整个文件集中出现的频率低,可以产生高权重的TF-IDF值。因此,将词袋向量转换为TF-IDF权值向量,更有利于判断两个文本的相似性。
3 厂商信息聚类分析
3.1 K-均值聚类
K-均值是将数据集划分为k个簇的算法,簇的个数k是用户给定的,每个簇通过其质心(簇中所有点的中心)来描述。K-均值算法的工作流程是:
(1)随机确定k个初始点作为质心。
(2)将数据集中的每个点找到距离最近的质心,并将其分配到该质心对应的簇中。
(3)将每个簇的质心更新为该簇中所有点的平均值。
(4)重复第(2)、(3)步骤,直到簇的分配结果不再变化。
为了评价聚类的质量,定义一种用于衡量聚类效果的指标误差平方和(SSE,Sum of Squared Error),误差是指样本到其质心的距离。SSE值越小,表示数据点越接近质心。
由于K-均值算法是随机选取质心,因此可能会收敛到局部最小值,而非全局最小值。为了克服这个问题,提出了一种二分K-均值算法。该算法的思路是将:(1)所有点作为一个簇;(2)将该簇一分为二;(3)选择一个能最大程度降低SSE值的簇继续进行划分,直到得到用户指定的簇数目为止[6-8]。
随机选取539个样本作为测试样本,由于事先无法确定分类的个数k,通过观察DI和DBI的变化趋势来确定一个合适k值。为此,将k设置一个较大的值,通过运算得到DI和DBI的变化趋势,如图2所示。
由图2可知,DBI值趋于不变,DI值的变化趋势也没有规律。同时,分别对539个样本划分为200、300、420个簇,经过人工校验,被成功分类的样本分别为111个、106个、105个。因此,K-均值算法不适合对厂商名称的分类,分析其原因,可能是由于厂商名称所包含的词汇量太少,而K-均值算法具有一定的随机性,从而导致分类效果不理想。
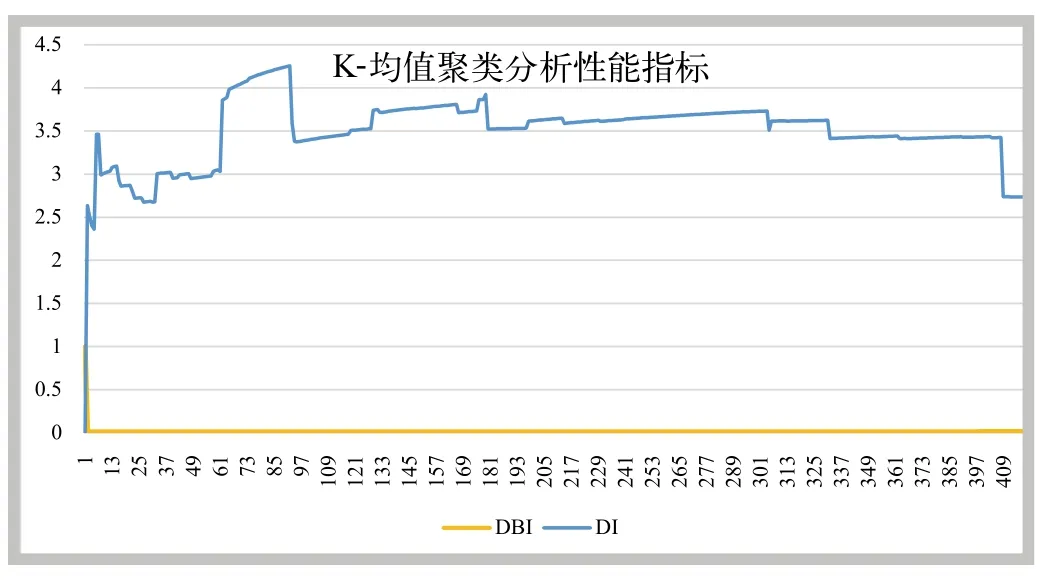
图2 k-均值聚类算法性能变化趋势
3.2 层次聚类
层次聚类[2]试图在不同的层次对数据集进行划分,可以采用“自底向上”的聚类策略,也可以采用“自顶向下”的分拆策略。一般采用“自底向上”的策略,它的思路是先将数据集中的每个样本看作一个初始聚类簇,找出两个聚类最近的两个簇进行合并,不断重复该步骤,直到达到预设的聚类个数或某种条件。关键是如何计算两个簇之间的距离,每个簇都是一个集合,因此,计算集合的某种距离即可。例如,给定簇Ci和Cj,可通过以下3种方式计算距离:
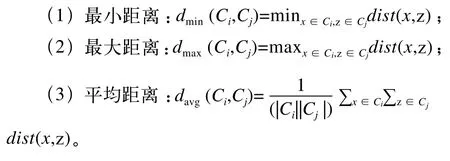
最小距离由两个簇的最近样本决定,最大距离由两个簇的最远样本决定,平均距离由两个簇的所有样本决定。
接下来要考虑如何确定一个合适的聚类个数或某种结束条件,具体思路是:
(1)选定一部分测试样本,对其进行层次聚类分析;
(2)记算性能度量指标DBI和DI的变化趋势,结合人工校验,得到一个合适的聚类个数和对应的距离阈值;
(3)将此距离阈值作为聚类结束的条件,对所有样本做聚类分析。
仍然选择K-均值算法所用的539个样本,对其进行层次聚类,得到的性能指标变化趋势如图3所示。
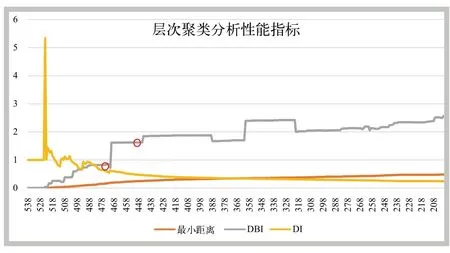
图3 层次聚类算法性能变化趋势
从图3可以看出,DI值呈下降趋势,DBI值呈阶跃上升趋势,根据性能度量的规则(DBI的值越小越好;DI的值越大越好),最优值可能出现阶跃点附近,即划分为471类和445类两个点,同时结合人工校验,可以确定445类更加合理。
将k值设置为445进行层次聚类分析,发现仍有少量相似的样本被划分到不同的类。根据业务需求,为了减少后续的核实工作量,将相似的样本尽可能划分到同一类中,同时可以接受少部分不同的样本划分到同一类,给予k值适当的冗余,将其设置为420,再分别基于最大距离、最小距离、平均距离进行分析,得到结果如表1所示。

表1 层次聚类分类效果对比
从以上分类结果看出,采用层次聚类算法对539个测试样本进行分类,效果明显优于K-均值聚类算法。并且,该算法可以通过学习得到距离阈值作为聚类结束的条件,从而解决了分类个数k值无法确定的问题。
为了降低个别样本对整体结果的影响,选择基于平均距离的距离分析算法,并将距离阈值设置为0.29,对全部4 574个样本做聚类分析,最后得到3 128个类,部分样本的分类结果如图4所示。
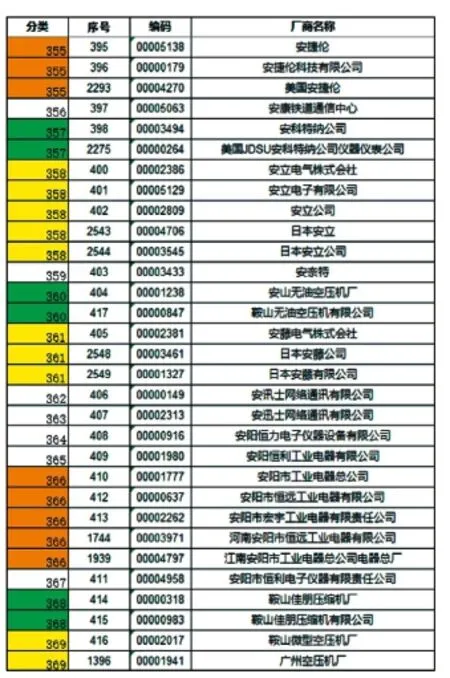
图4 层次聚类算法分类效果
4 结束语
本文针对铁路通信大数据平台中通信设备生产厂商信息不规范的问题,提出了基于聚类分析算法对生产厂商进行分类的思路。通过分词、构建词袋空间、权值转换等一系列数据预处理方法,将文本转换为可分类的权值向量。采用K-均值聚类、层次聚类算法分别对部分样本进行聚类分析,比较测试结果,选择层次聚类算法对所有样本进行聚类分析,最终得到理想的分类结果,从而极大地降低了人工审核并规范信息的工作量,为形成厂商字典提供了有力的支持。随着铁路通信大数据平台的推广应用,采集的数据量也会越来越大,海量数据规范、设备故障预测、智能状态评价等需求将会日益突出,因此,通过人工智能的理论和技术来进行数据挖掘,从而提供更加智能的决策支持将成为日后的工作重点。
