基于社区过滤的商品推荐算法
2018-08-06韩丽莎
韩丽莎
(福州理工学院,福建 福州 350506)
在当今大数据时代,商品推荐系统已成为电子商务的重要研究内容.它能够主动快速地挖掘出潜在顾客,并利用潜在顾客的兴趣爱好和购买能力,为潜在顾客推荐感兴趣的商品,既增加了网站的销售量又增加了顾客对商品网站的信任度.
1 传统协同过滤商品推荐算法
协同过滤商品推荐[1]又叫做社区过滤,是Goldberg等学者1992年首次提出的.传统协同过滤商品推荐算法的关键是找出目标顾客的邻居,据最相似邻居的打分对目标顾客未购买的商品进行计算预测,并最终推荐给目标顾客.算法可划分为3个过程:建立顾客模型;形成最相似邻居;进行推荐.
(1)建立顾客模型.顾客打分数据用m×n维矩阵Rst表示,m是顾客数目,n是商品数目,rst是顾客s对商品t的评分.

(2)形成最相似邻居.据打分矩阵Rst计算顾客间的相似度,形成目标顾客的最相似的邻居集合.
(3)进行推荐.据最相似的邻居已经购买或已经浏览或已经评价但目标顾客还没有发现的商品形成候选商品集合,然后计算预测目标顾客对候选商品的打分,产生top-N商品,从而进行推荐.
随着顾客数目和商品数据的剧增,顾客打分数据呈现出极端稀疏问题[3],这对商品推荐结果的准确性有着重大影响.对于稀疏问题,目前尚无彻底的解决办法:Sarwar[4]等人利用单值分解方法处理稀疏的数据,结果发现这种方法虽然在一定程度上会提高商品的推荐质量,但会导致数据遗失,且计算复杂度高、可扩展性差;BP神经网络填充方法[2]也被一些学者提出用来解决数据稀疏问题,但其计算复杂度高、可扩展性差、推荐速度慢.
2 基于社区过滤技术的估计填充商品推荐算法
鉴于数据稀疏性问题,本文给出了基于社区过滤[2]技术的估值填充商品推荐算法.文中先通过聚类形成目标顾客在各商品种类中的相似顾客群,并从中寻找top-N邻居顾客;之后将邻居顾客已经浏览或已经评价或已经购买但目标顾客还没有发现的商品组成一个推荐候选商品集合;其次通过对候选商品集进行估值预测形成推荐;最后通过实验验证了该算法有着较好的推荐效果.
在传统的协同过滤算法中,在寻找相似邻居顾客时所关注的是目标顾客与其他顾客在所有商品上的兴趣相似度,且是在所有感兴趣的商品上向目标顾客进行推荐,所以当目标顾客想关注某方面的兴趣爱好时,此推荐系统是无法满足的.运用社区过滤技术可以有效地解决该问题,因为该技术考虑到了目标顾客当前感兴趣的每一个类别,能够针对任一类别向目标顾客进行推荐,可以全面反映目标顾客当前的兴趣爱好.
2.1 基于社区过滤技术的顾客估值填充
社区是指在某方面具有相同兴趣的顾客所组成的顾客群.因为顾客兴趣的多样性,一个顾客可以同时隶属不同的社区.社区过滤,也就是在某一社区内进行推荐.其基本思想是:首先通过聚类找出目标顾客在某一商品种类上的相似顾客群,也就是目标顾客在某一种类上的社区;然后计算并预测目标顾客对同一社区中的其他顾客所感兴趣的商品打分;最后据预测分数在该社区内向目标顾客进行推荐.
2.1.1 聚类技术
聚类分析[5]是一种重要的人为活动,并广泛地用于许多领域,包括市场研究、模式识别、数据分析、图像处理.比如,在商务中,聚类能够帮助市场分析员根据购买模式从顾客库中发现不同的顾客群,刻画顾客群的特征.
聚类是将数据分类到不同的类或者簇的过程,使同一个簇中的对象之间具有很高的相似性,而不同簇中的对象高度相异.相异度根据描述对象的属性值评估,通常使用距离度量.
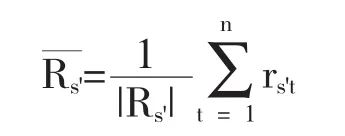
2.1.2 改进顾客估值填充公式
根据社区过滤思想,论文对原有的评分估值技术进行了改进:利用聚类找到目标顾客在每个商品种类上的相似顾客群,继而在每个商品种类的相似顾客群中计算“顾客评分尺度”和“商品受欢迎度”,从而完成更精准的估值预测,以提高商品的推荐质量.改进后的基于社区过滤技术的评分估值填充公式如下,
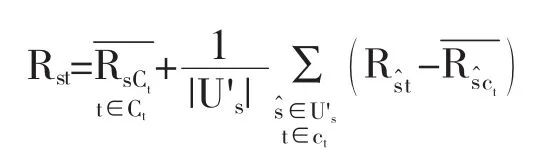
其中:
(1)U's示商品t所属种类ct上的相似顾客群;
(2)将顾客s对商品t所属种类ct的打分作为顾客打分尺度
2.2 生成最近邻居
该算法寻找目标顾客s在每个相似群中的最近邻居:首先通过Pearson相关方法[2]得出顾客之间的相似度sim(ui,uj),然后将计算出的相似度进行排列(从高到低),形成目标顾客在每个相似群中的相似度集合 sim(us)={sim(us,n1);sim(us,n2),…sim(us,nm)};最后,以预定的相似度阈值或邻居数确定top-N,进而确定目标顾客s在每个相似群中的邻居集合N(us)={n1,n1,…nn|n≤m}.
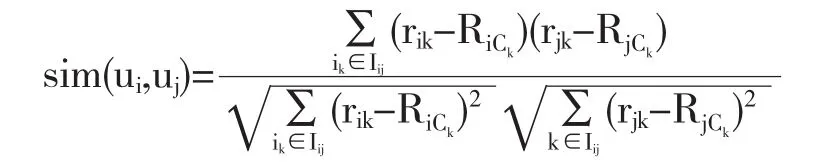
其中,Iij是顾客ui和顾客uj都打过分的商品集合;RiCk或RjCk为顾客ui或uj对商品种类ck的评分.
2.3 形成推荐
在目标顾客的各个相似群中,邻居集合N(us)={n1,n1,…nn|n≤m}形成以后,将邻居顾客已经浏览或已经评价或已经购买但目标顾客s还没有发现的商品组成候选商品集合CI(us),接着目标顾客s对候选集合CI(us)中的每个商品进行计算预测,然后将得出的分值按照从大到小的顺序排列,最后选出top-N商品集合并进行最终推荐.

其中:
(1)i(nj)∈CI(us)表示邻居顾客nj已浏览或已评价或已购买但目标顾客s还未发现的商品;
(2)RsCt表示目标顾客s对商品i(nj)所属种类的打分;
(3)sim(us,nj)表示目标顾客s和其邻居顾客j的相似度;
(4)rjt表示邻居顾客j对商品i(nj)的打分;
(5)RjCt为邻居顾客j对商品i(nj)所属种类的打分;
3 实验
论文利用商品推荐领域较权威的实验数据,选用评分商品数为0-40时的顾客,并参考eBay网中的电影分类,将给出的基于社区过滤技术的估计填充推荐算法CF1与原估值填充推荐算法CF从准确性、全面性两个方面进行比较分析.
(1)均值绝对误差MAE衡量整个检验集合中的平均误差.

CI(us)'⊆CI(us)是top-N=3时该算法推荐的商品集合;pst是预测的顾客s对商品it∈CI(us)'的打分;rst为顾客s对商品t的真实打分.
(2)查全率Recall验证推荐的商品占顾客真正感兴趣商品的比重.

TR(us)为顾客s的真正感兴趣的商品集合,即在测试数据集中为评分>=4的商品集合;|CI(us)'|∩TR(us)为向顾客s推荐的商品与其真正感兴趣的商品相重叠的部分.
3.1 实验结论及分析
实验将给出的基于社区过滤技术的估计填充推荐算法CF1与原有的评估填充算法CF从推荐准确性、全面性两个角度进行了对比.
(1)CF1与CF的均值绝对误差MAE的对比结果如图3.1.
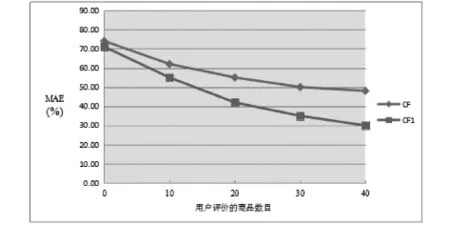
图3.1 算法CF1与CF的均值绝对误差MAE对比结果
如图3.1所示,随着顾客评价的商品越来越多,算法CF1与CF的MAE曲线都呈现下降趋势.这是因为顾客评价的商品越多,商品种类也就越多,顾客-商品评分矩阵需要填充得评分项也就越少,通过聚类寻找的邻居也就越准确,MAE也就越低.因此,从图3.1得出,本论文给出的基于社区过滤技术的估计填充推荐算法CF1的MAE比算法CF更低一些.
(2)算法CF1与算法CF的查全率Recall实验结果如图3.2所示.
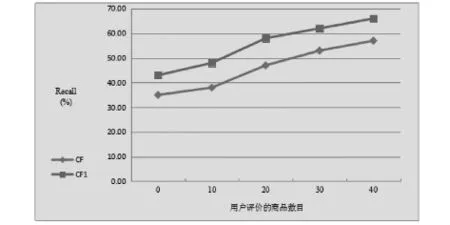
图3.2 算法CF1与CF的查全率对比结果
如图3.2所示,随着顾客评价的商品越来越多,算法CF1与CF的Recall曲线都呈现上升趋势,这是因为顾客评价的商品越多,商品种类自然也就越多,算法的Recall也就越高.因此,从图3.1得出,本论文给出的基于社区过滤技术的估计填充推荐算法CF1的查全率Recall相比算法CF更高一些.
4 总结
在当今大数据时代,商品推荐算法的研究有着深刻的社会影响意义.对于数据稀疏问题,本论文给出了基于社区过滤技术的估值填充商品推荐算法,论文最后又验证了该算法的可行性.然而本论文仍有很大改善空间,未来的研究工作主要有:
(1)本论文提出的算法的算法复杂度有待进一步降低.
(2)通过数据填充能够在一定程度上缓解数据稀疏性问题,但不能解决高维矩阵的降维,即数据可扩展性问题仍待解决.
