面向选择类题型求解的相似问题发现研究
2018-08-01郑雨晴郑德权赵姗姗
于 凤,郑雨晴,郑德权,,赵姗姗
1.哈尔滨商业大学 计算机与信息工程学院,哈尔滨 150028
2.哈尔滨工业大学 计算机科学与技术学院,哈尔滨 150001
1 引言
在人工智能火热的今天,智能解题逐渐成为一大研究热点,人们热衷于让人工智能参加各种“测试”,并与人类选手进行比试,从而衡量目前人工智能系统的“智力”水平。
目前,在世界范围内已有多家研究机构正在从事这一方面的研究。例如,日本国立情报学研究所开发的AI机器人“东Robo君”,他们让机器人挑战大学试题,目标是2021年能够考上东京大学[1]。艾伦人工智能研究所(Allen Institute for Artificial Intelligence)也举办了一项比赛,来自全世界的几千个团队纷纷提交了自己的软件系统来挑战8年级的科学题目,最终,该比赛的第一名达到59%的正确率[2]。在我国,国家科技部2015年也启动了“高考机器人”项目(863计划中的类人智能项目),让人工智能系统和全国的文科考生一样,挑战2017年高考语文、数学、文综三项科目,研究相关类人答题系统,超过30多家高校和科研机构(清华大学、中科院自动化所、哈工大等)联合参与了该项目。此外,在智能解题方面,文献[3]提出通过动词分类来解决较简单的算术问题;文献[4]通过句子边界来构造和求解一个线性方程组;南京大学的研究人员针对历史选择问题,在维基百科中检索与问题相关的页面,通过对页面进行排序、过滤、评价,求得最终结果[5]。
2011年,IBM Watson超级计算机在电视智力竞赛节目《Jeopardy!》中战胜人类而一举成名[6],AlphaGo战胜世界围棋顶尖高手,这些都代表着科学技术向认知系统的进步。而类似的知识问答系统,如中国科学院自动化研究所开发的百科知识问答系统、百度的小度机器人、微软小冰等,在现代生活中应用也日趋广泛。
通过深入了解上述各相关系统,发现它们的关键技术一般都包括知识处理、信息检索、语义理解等部分。类比上述这些系统,可以考虑将此类技术应用到基础教育领域。利用当前大数据特性以及自然语言处理技术,研究多源知识的识别、抽取、发现等问题,构建面向基础教育领域的关联类与推理类问题的求解系统。本文主要针对选择类题型求解的相同或相似性问题发现展开研究。
本文是根据已有的问题和知识库求解新问题,由于自然语言语义表达的多样性,当从已有问题中查找相似问题时,相似不仅代表问题内容的相似,还有可能是内容不同但语义却相似,这给问题检索带来了一定的困难,现阶段主要围绕语义相似度进行研究。
本文在求解题目时,同样核心点落在从已有题库中求解相似问题,具体过程是:首先对新问题进行关键词抽取及扩展,完成多源知识搜索;其次根据扩展后的关键词完成关联问题的检索;再根据关联问题计算相似度;最后获得各个候选项的打分,完成答案选择。
2 问题理解与分析
2.1 选择题及知识点关系分析
本文以地理问题为研究对象,通过搜集各类地理教材、地理题目及历年高考地理大纲等,发现考查基本内容、知识点变化不大,而每年考题的多样性重在对知识点的灵活应用,且题目都有一定的规律。以人教版高中地理课本为例,共有3本必修,7本选修,包含250个左右的知识点,包含自然地理、人文地理、中国地理、世界地理等部分。再分析从各个网站下载的题目发现,在有限的知识点下,每类知识点对应的题目却非常多。表1是根据某网站的题库,统计的若干具体的知识点与其现有的题目数量分析。

表1 知识点与现有的部分题目数量关系
因此本文通过分析题目相关的知识点,然后从题库中查找相同或相似知识点的若干题目,再通过分析这些相似知识点的题目,来求解新问题。
2.2 问题发现分析
问题发现可以分为两步完成:问题分析和相似问题发现。问题分析又称问题理解,主要完成对新问题预处理,生成适当的检索项,为下一步相似问题发现提供输入。相似问题发现则主要根据问题分析结果应用不同的相似度分析方法从已有题库中查找部分相似问题。
本文在问题分析时对问题的处理包括关键词提取和扩展两部分。关键词提取包括有监督的、无监督两种方法。有监督方法中,文献[7]提出了使用向量空间模型(Vector Space Model,VSM)提取关键词;文献[8]提出了使用朴素贝叶斯模型的关键词提取方法。无监督方法中,最简单易用的关键词抽取算法是TF-IDF(Term Frequency-Inverse Document Frequency),文献[9]和文献[10]提出使用类似于PageRank的算法TextRank抽取关键词,文献[11]提出使用LDA(Latent Dirichlet Allocation)主题模型的方法来抽取关键词。
考虑到地理问题一般都是一句话或者若干单句组成的复合语句,本文使用TextRank和词性标注两种方法来标注关键词。关键词提取之后,使用Word2Vec对关键词进行聚类,然后根据聚类后的结果扩展关键词。
目前问题相似度计算方法大致分为三类:基于词汇、基于句法特征以及基于语义特征的问题相似度计算方法。基于词汇的相似度计算方法主要是基于词袋模型(bag of word),该模型忽略了词汇之间的顺序、句法、语法及语义信息,将一个文本看作若干词汇组成的集合,认为词的分布或者服从0-1分布或者服从多项式分布。传统基于词袋的检索模型有VSM[12]、BM25模型(Best Match25)[13]。这两个模型都是基于TF-IDF来计算,不同点在于BM25模型中加入了对句子长度的分析。此外,根据编辑距离和最长公共子序列来计算相似度也是一种简单可行的方法。根据句法特征计算问句相似度,主要是应用现有的句法分析工具获得问句句法结构,然后从句法结构中抽取问题特征,进行相似度计算。文献[14]中使用依存句法分析树,根据树中节点的依存关系及节点路径信息来分析句子的相似度;文献[15]使用短语句法树核的方法,通过分析句法树中子树的相似度来计算两个问题的相似度。汉语语言中经常有语义相同特征词却不同,或者特征词相同而语义却不同的句子,因此又引入了基于语义的相似度分析,现有的语义相似度研究方法中一般借助《知网》、主题模型等来分析[16-17]。

表2 两种方法的关键词抽取结果
由于本文主要是为了求解知识点类似的地理题目,而且地理题目结构内容灵活,句法分析技术并不是十分适用,因此本文主要从词法和语义两方面研究:词法上,主要对新问题的关键词扩展,然后根据Lucene中TFIDF机制获得初始候选问题;语义上,使用word2vec分析词语的语义相似度,进而研究两个句子的相似度。在分析相似度时根据不同的关键词抽取方法和相似度计算方法间的组合,来获得最佳结果。
2.3 word2vec分析使用
近年来随着深度学习(Deep Learning,DL)在计算机视觉和语音识别领域的广泛应用,在自然语言处理领域的应用也逐渐展开。Tomas Mikolov等人在2013年建立了word2vector模型,将单词转换成词向量的形式[18]。不同于传统的使用One-hot Representation来表示词向量,word2vec是将词用Distributed Representation表示成一种低维实数向量。Google开源了word2vec学习工具,该工具包含了对两种语言模型的训练,即连续词袋模型(Continuous Bag-Of-Words Model,CBOW)和 Skipgram(Continuous Skip-Gram Model)。词向量是在训练语言模型的同时得到的副产品,并没有直接的模型来训练获得。针对这两种模型,又有两种不同的学习方法,即HS(Hierarchical Softmax)和NS(Negative Sampling)。
本文在训练词向量时,使用的是维基百科中英文语料,语言模型使用Skip-gram,训练使用NS负采样方法。在此基础上采用谱聚类算法[19-20]对关键词聚类,以便在关键词扩展的时候使用。计算相似度采用基于word2vec生成的词向量来设计不同的相似度计算方法。
3 相似性问题发现
3.1 关键词提取
本文使用两种方法抽取关键词,一种方法是参照TextRank算法,另一种方法是使用词性标注(Part Of Speech,POS)的结果。
TextRank算法是类比PageRank实现的,将每个单词作为PageRank的一个节点,设定窗口大小后,认为窗口中任两个单词对应的节点之间存在一个无向无权的边,然后根据构成的图计算出每个单词节点的重要性,按照重要性的大小得到关键词。另一种方法是使用FudanNLP分词器对问题进行词性标注,从标注结果中提取出具有名词、地名、专名、形容词等词性的词,然后给每个词赋予不同的权值,得到关键词集合。表2给出了上述两种方法对于2个例句的关键词抽取结果。
在进行关键词扩展时,先使用word2vec生成词向量,然后再对词聚类。为了减小噪声,避免关键词中噪声过大,对词的聚类并没有使用维基百科语料,而是使用题库中已有题目作为语料训练词向量,使用文献[21]中提出的基于全局K-means的谱聚类算法完成对词聚类。表3给出了4组词聚类中词频较高的样例。

表3 词聚类结果
3.2 相似度计算
3.2.1 基于改进的BM25方法
BM25算法是二元独立模型的扩展,在信息检索中通常用来作为搜索相关性评分。其主要思想是,对用户查询进行解析,生成语素qi,然后再计算每个语素qi与检索到的文档D的相关性得分,最后将每个qi与文档D的相关性进行加权求和,进而得到Query和文档D的相关性得分,其计算公式如公式(1)所示:

其中,Wi=IDF(qi)是语素qi的逆文档频率,代表其权重,而语素qi与文档的相关性表示如公式(2)所示:
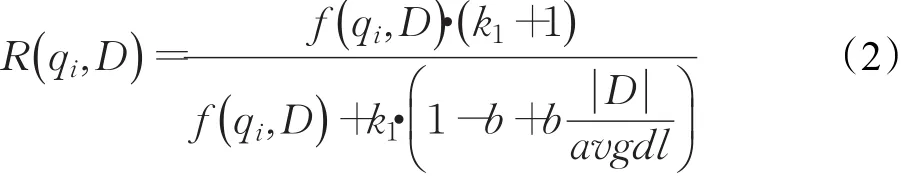
其中,f( )
qi,D 表示语素qi在文档D中的词频,k1和b为调节因子, ||D表示文档长度,avgdl表示所有文档的平均长度。BM25算法的优点在于可以灵活改变各部分内容,对算法进行改进。
为了有效模拟人类求解问题的过程,往往需要更多考虑问题知识点,因此可以尝试将一个问题分解为多个关键词,代表不同知识点,然后再判断每个关键词与已有问题的相似性,再对各个关键词与问题的相似性进行加权求和。因此可以对上述算法的两部分进行更改,得到求解两个地理问题相似度的方法,如公式(3)所示:
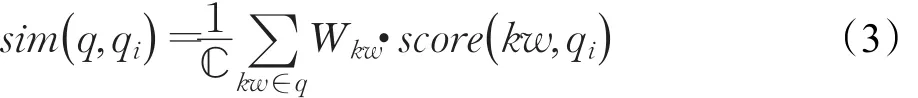
其中,kw代表一个关键词,ℂ为归一化因子,wkw代表关键词权重,score(k w ,qi)代表关键字kw与已有问题qi的得分,计算方法如公式(4)所示:
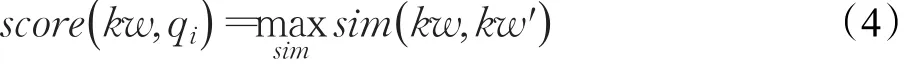
其中,kw'为qi的关键词。
之所以采用公式(3)描述的计算方法,主要是考虑到地理题往往是一个短文本,问题中每个关键词的频率一般为1,而传统的BM25算法根据词频计算,所以在此过程中并不适用。而两个地理题的相似更多的是偏重于某个知识点的相似,因此关键词kw与问题qi的相似度求的是问题qi中与kw最相似词的相似度。表4中给出了2个例句及其相似度计算的结果。

表4 相似度计算的2个例句
根据改进后的BM25算法,分别使用两种不同的关键词抽取方法得到的相似度均为1.0,这证明了该方法的可行性。该方法中主要计算每个单词与候选问题的相似度,因此后文中也将其称为基于词的相似度计算方法(byWord)。
3.2.2 基于词项向量加权的方法
word2vec值得注意的另一个特性是可以对训练得出的词向量进行加减组合运算,进而得到与这些词语相关的词语信息。在3.2.1小节中是将新问题的各个关键词分别与已有问题计算相似度,在本小节中考虑在基于句子级别上分析两个句子的相似度。首先求得问题的关键词及其权重,然后对各个关键词进行加权求和得到问题向量,最后再用余弦相似度来计算两个问题的相似度,具体的计算公式如下:

此处求解问题向量时并没有进行归一化计算,因为即使有归一化因子,在后边计算余弦相似度过程中也会被约掉。
使用该算法对3.2.1小节中的2个例句求相似度时,使用TextRank抽取关键词得到的相似度为0.7,使用词性标注结果抽取关键词相似度为0.9。虽然此处相似度值与3.2.1小节结果有差距,但是实验结果证明,使用该方法效果也较好。该方法最终是将句子转为句子向量来求解,因此后文中也将其称为基于句子的相似度计算方法(bySent)。
3.2.3 基于改进编辑距离的方法
编辑距离是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。编辑操作包括对一个字符的增加、删除和修改。传统的编辑距离计算时是对单个字符执行编辑操作,且认为每一次操作的代价为1。本文中,将单个词,每一次的操作代价r(w ,w')与两个词语的相似度sim(w ,w')成反比,记为1-sim(w ,w')。做了上述改进之后,根据动态规划的思想,算法迭代式如下所示:
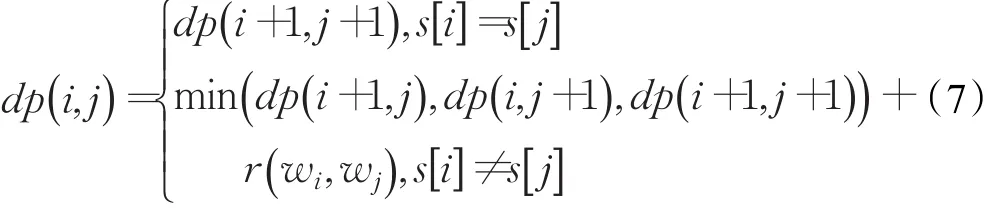
根据此算法求出两个问题的编辑距离dp(q ,qi),再对编辑距离规范化,使其范围在0~1之间,且使编辑距离与两个问题的相似度成反比,具体公式如下:
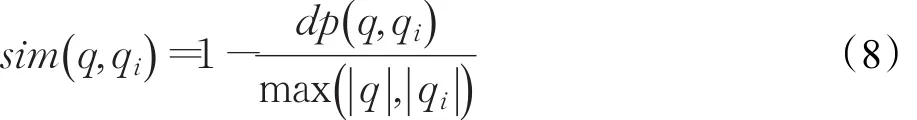
其中, ||q和 ||qi为两个问题的长度。
实验发现使用该算法时,相似度计算值浮动较大。给定第5个例句如下:
例句5:“对西欧海洋性气候的形成有巨大作用的洋流是北大西洋暖流”
对3.2.1小节中的例句3和例句5分别使用两种关键词抽取方法得到的相似度在0.8左右;而对3.2.1小节中的例句3和例句4计算相似度时值却在0.38左右,这表明该算法对句子中语义相似词的位置比较敏感。但是实验结果证明,该方法在求解关联推理的地理题时也有一定效果,分析可能是由于地理关联推理类题目往往是局限在地理知识点内的。后文中也将该方法称为基于编辑距离的相似度计算方法(byEdit)。
4 实验结果与分析
4.1 数据来源
本文以地理选择题的求解为处理对象,所用题库分为两部分:一部分是从互联网上下载的题目,总共大约有10万多题,其中选择题共有6万多,去除选择题中的图表分析题和组合选择题,共剩余26 000左右,将这部分作为检索库;另一部分是人工录入的历年高考题,大约3 700多题,去除其中的非选择题、图表题、组合选择题和计算题,剩余340题左右,将这部分题作为测试集使用。对检索库中的题集仅保留问题和答案,并采用Lucene对其创建索引。
4.2 word2vec模型训练语料
在学习词向量时,word2vec的训练语料使用维基百科数据,共800 MB左右,而对词聚类时,因为本文主要是为了扩展地理方面的词汇,为了避免关键词类中噪声过大,对词的聚类并没有使用维基百科语料,而是使用题库中已有题目作为语料,生成关键词聚类,结果如表3所示。此外,word2vec的训练语料需要提前分词,本文使用FudanNLP分词器,并加入从维基百科中抽取的地理专业词汇,完成对语料的分词。
4.3 实验设计
本文以地理选择题作为实验数据,对问题的求解主要是根据相似度对问题的各个候选项打分,共分为4个步骤实现,流程如图1所示。
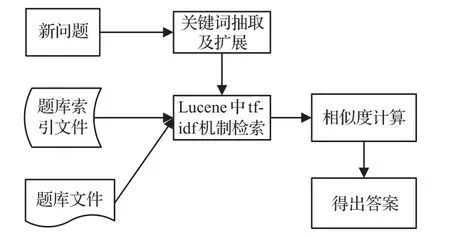
图1 问题求解的流程
步骤1分析问题,形成检索项。首先将问题与各个选项组合成一句话(以表5中例题为例,首先将其合成一句话“贮煤地层的岩石类型,一般是沉积岩”);其次对每句话使用FudanNLP分词器进行词性标注;然后根据两种方法抽取关键词;最后利用已有的词聚类结果扩展关键词。
步骤2采用Lucene系统,根据扩展后的关键词集合从题库检索候选问题得到候选集合。
步骤3融入word2vec生成的词向量,计算相似度。采用不同的相似度计算方法,对检索出的候选问题与检索前的句子求相似度,据此得出问题和各个选项的得分。
步骤4根据相似度的计算结果,以各个选项中得分最大的选项作为最终答案。

表5 地理选择题示例
4.4 结果及分析
本文使用最终求解问题的准确率作为对各个方法的评价。在关键词抽取时使用了TextRank和词性标注两种方法。在计算相似度时分别使用了改进的BM25方法、词项向量方法、改进的编辑距离等三种方法。将两种关键词抽取和三种相似度计算方法进行组合,共产生六种不同的求解方法。
在测试集上,为了验证各个相似度计算方法的准确性,在检索集上进行了10次封闭测试,每次从检索集中随机选择200道题作为测试集,计算各个求解方法的准确率,求10词的平均准确率(Average Precision,AP)。然后再使用手工录入的高考题作为测试集,计算求解各个方法准确率。因为从Web中下载的题目与高考题目会有重复,所以最后又对检索库中的问题进行10次交叉测试。检索库中大约有26 000道题,每次随机选取260道作为测试集,剩余的作为检索库,求出平均准确率。具体的实验结果如表6所示。

表6 几种方法的实验结果对比
图2是对表6的直观表示。
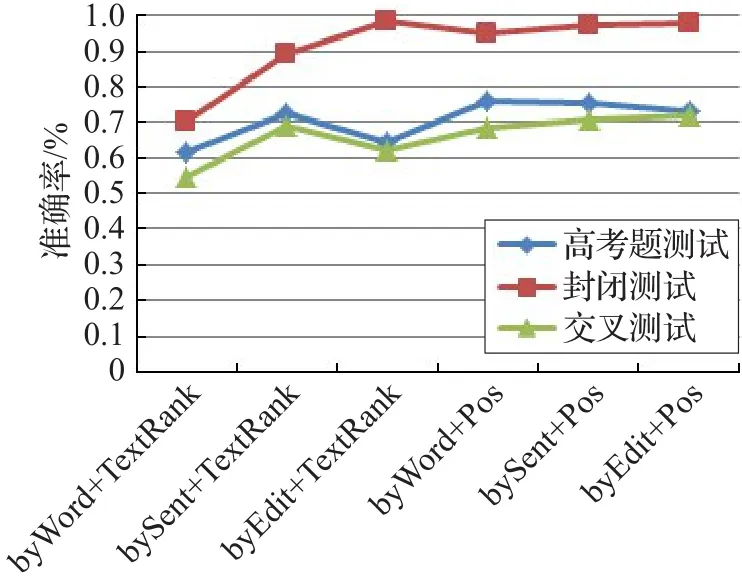
图2 几种方法的实验结果对比图
从图2中可以发现,TextRank抽取关键字整体效果不是特别好,分析主要是因为地理题目一般都比较简短,而TextRank对长文本更加有效。其中基于改进的BM25方法,在采用TextRank抽取关键词方法上的效果最不好,主要因为基于改进的BM25方法是基于词的计算,所以效果不理想。观察基于改进的编辑距离方法在两种关键词抽取方法上的效果相差不大,分析是因为它是根据词序计算编辑距离,而且句子短时效果更好,因此词数目的减少对其影响不是很大。基于词项向量方法,在使用基于词性的关键词抽取方法上与采用改进的编辑距离的结果不分上下。总体看,在地理选择题目求解时,采用词性标注方法抽取关键词,要比基于TextRank的方法好一些;而相似度计算上采用改进编辑距离的方法较好一些,但是使用不同的关键词抽取方法,采用词项向量的方法也能够取得较好的结果。
5 结语及展望
本文主要通过对问题进行关键词抽取与扩展,然后融入word2vec生成的词向量的语义信息,再使用基于改进的BM25方法、基于词项向量方法和基于改进的编辑距离三种计算相似度方法,完成了基于题库的选择类问题求解。实验结果表明,采用检索题库中相似问题完成对地理知识关联、推理类问题的求解也是可行的。
由于本文中的方法主要集中在相似度的计算上,考虑语义时仅仅使用了word2vec,下一步可以加入更多的语义分析,并加入事件的抽取,进而来比较两个知识点类似的高考题表述的事件是否一致,同时也可以考虑引入深度学习的方法。
