基于主成分分析与Fisher判别法的底板突水预测研究
2018-07-30张兆威滑怀田
张兆威,滑怀田
(1.神华神东煤炭集团公司石圪台煤矿,陕西 榆林 719000;2.山西工程技术学院,山西 阳泉 045000)
0 引言
我国许多矿井的水文地质条件复杂,随着煤层开采深度的不断加大,岩溶承压水对工作面安全开采的威胁已日益凸显[1]。因此研究多因素协同作用下工作面底板的突水规律,建立精度较高的突水危险性判别模型,对于保证工作面的安全回采具有重要的指导意义。
目前数值模拟手段和数据发掘分类技术已被广泛应用在煤层底板突水的评价和预测研究中[2]。文章[3]运用FLAC3D数值模拟方法研究了断层影响下底板突水通道的演化规律,文章[4]利用经验公式及理论计算等多种方法分析了灰岩含水层对工作面底板破坏深度的影响。文章[5]以岩石的强度理论为基础建立了精度更高的突水系数计算公式,文章[6]从煤层底板的充水通道、底板完整性等方面出发,综合运用突水系数法等多种手段对煤层带压开采的可行性进行了研究。文章[7]以五矿306中巷的实际地质条件为背景,提出了岩巷掘进过断层的安全技术措施。文中将选取18例矿井的实测数据作为学习样本[8],首先运用主成分分析法对纳入研究的6个自变量进行信息浓缩,然后计算各样本的主成分得分值,并将其作为中间变量建立判别函数,最后将主成分转变回各原始变量,从而建立以样本原始数据为自变量的底板突水危险性判别模型。
1 主成分降维分析
煤层底板突水是多因素综合作用的结果,为了能够较为全面地反映不同变量对底板突水的影响,在建模时往往希望纳入较多的自变量,但因部分变量间可能存在着大量的信息重叠,如果直接用它们建立预测模型会由于变量间的强共线性使得模型精度降低。
Pearson相关系数是一个介于-1~1之间的值。它是在协方差的基础上除以两个随机变量的标准差求得的。通过计算Pearson相关系数值的大小可以定量的反应两变量之间的线性相关程度,当系数值为0~0.2为无关联,0.2~0.4为弱关联,0.4~0.6为中等关联,0.6~0.8为强关联,0.8~1.0为极强关联。由表1可知含水层水压与煤层倾角的相关系数值分别为0.612、隔水层厚度与采高的系数值为0.528,表明部分变量间的确存在强关联性。
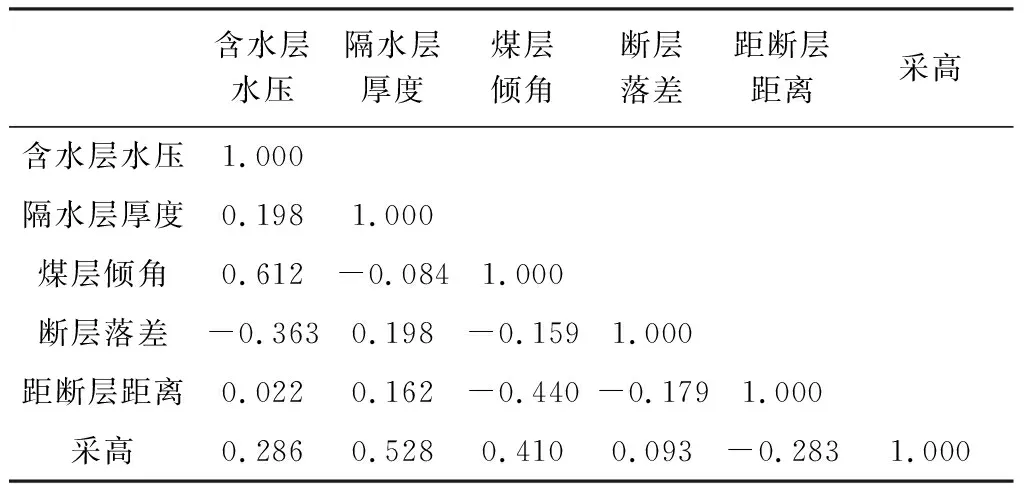
表1 各突水因素相关系数矩阵
主成分分析法属于信息浓缩方法的一种,其目的是通过对原始变量进行合理的线性组合,从而减少分析的维度,避开多重变量间的共线性。
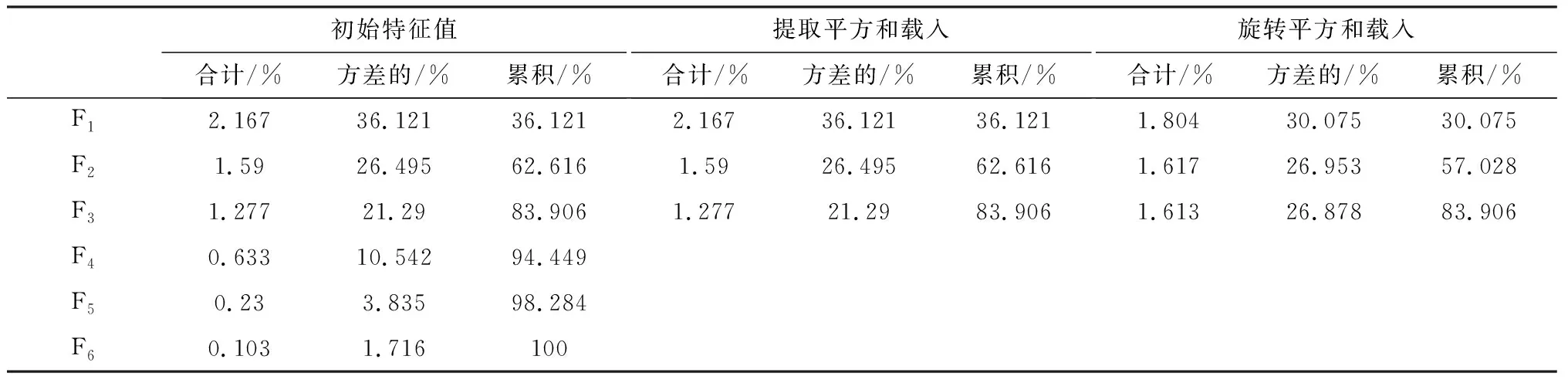
表2 各主成分解释的总方差
在进行主成分分析时首先需要对变量X1~X6进行标准化,可记为Zx1~Zx6,从而消除各变量在数量级及量纲上对研究结果的影响。然后计算标化数据的协方差矩阵。最后求得协方差矩阵的特征值λ1≥λ2≥…≥λ6及其对应的单位特征向量。
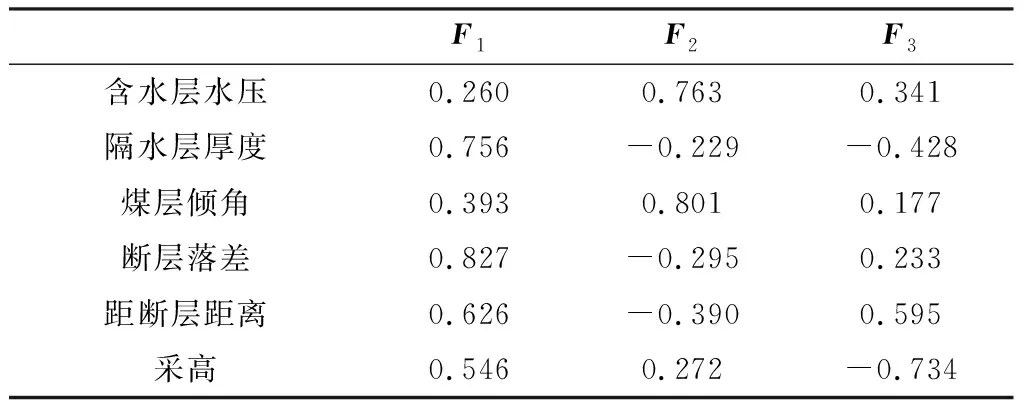
表3 旋转前因子载荷矩阵

图1 碎石图
从表3可知对于当前所提取的3个主成分很难对其代表的实际意义做出合理解释,因此采用最大方差法对初始因子载荷矩阵进行正交旋转,见表4。在旋转后F1~F3的方差贡献率分别为30.075%、26.953%、26.878%,与旋转前相比3个主成分的方差贡献率均发生了变化,并且彼此间的差值也有所减小,但是在转换前后3者的累计方差贡献率并未发生变化仍为83.906%,这说明因子旋转只是对信息量进行了重新分配。从旋转后的因子载荷矩阵可知F1在断层倾角及距断层距离两个自变量上有较大的载荷,因此说明F1主要反映的是断层构造对工作面底板突水的影响。虽然隔水层厚度、采高及含水层水压、煤层倾角在F2、F3的载荷分布上各有侧重但代表的实际意义依旧不是特别明确。
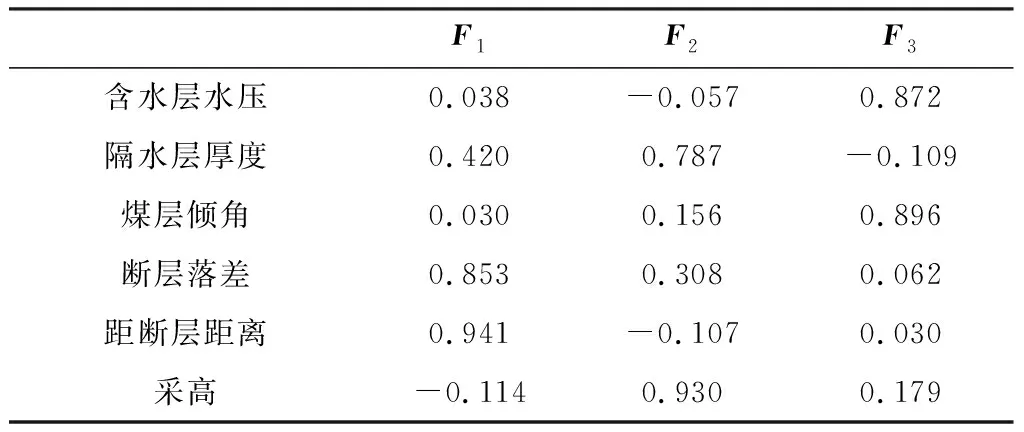
表4 旋转后因子载荷矩阵
由表5可知主成分F1~F3的表达式分别为
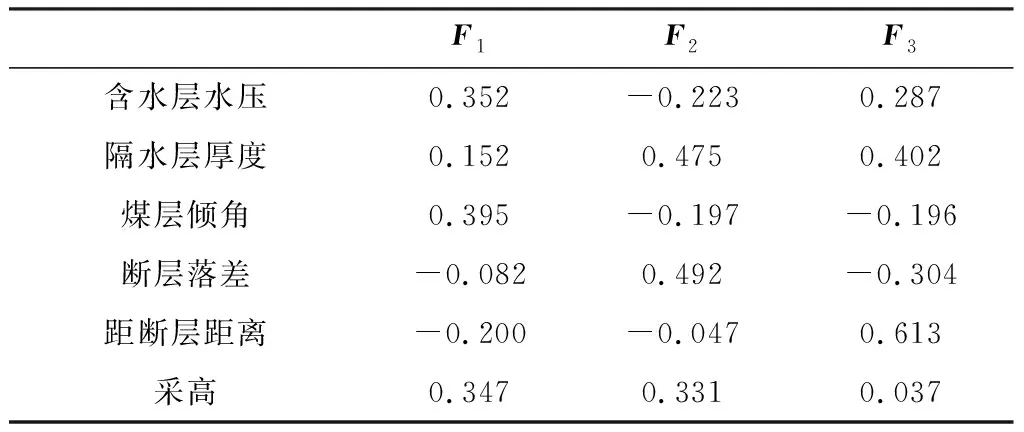
表5 主成分得分系数矩阵
F1=0.352Zx1+0.152Zx2+0.395Zx3-0.082Zx4+0.200Zx5-0.347Zx6
(1)
F2=-0.223Zx1+0.475Zx2-0.197Zx3+0.492Zx4-0.047Zx5+0.331Zx6
(2)
F3=0.287Zx1+0.402Zx2-0.196Zx3-0.304Zx4+0.613Zx5+0.037Zx6
(3)
2 Fisher判别分析
2.1 Fisher判别分析原理及模型
Fisher判别法是以方差分析原理为基础,试图找到一个由原始自变量组成的线性函数,使得组间平方和尽可能的大,而样本的总离差平方和尽可能的小。
2.3 ER-β 基因Alu I 多态性与促卵泡激素、黄体生成素和雌孕激素测量结果 广西壮族绝经妇女45~50岁5个ER-β 基因Alu I 酶切基因(AA、Aa、aa、a、A)组的血清雌二醇、孕酮水平中,AA基因组、Aa基因组、a基因组、A基因组,四组间两两比较,差异无显著性(P>0.05),aa基因组与其它4组之间比较差异有显著性(P<0.05):aa基因组的雌二醇和孕酮血液水平明显高于其它4组(P<0.05),而aa基因组的促卵泡激素、黄体生成素明显低于其它4组(P<0.01),见表3、表4。
y(x)=c1f1+c2f2+c3f3=CTF
(4)
式中:C=(C1,C2,C3)T,F=(f1,f2,f3)T则有
(5)
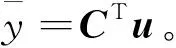
(6)
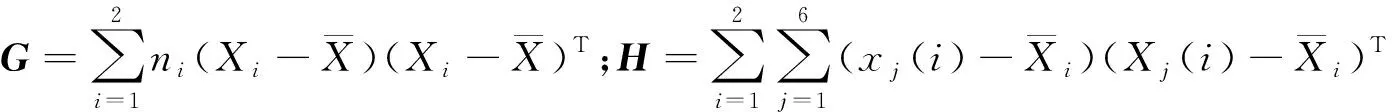
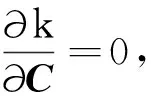
运用之前介绍的理论,将各样本的主成分得分值作为自变量,分组变量为突水状况,建立煤层底板突水的Fisher判别模型。
y=0.918F1+1.175F2-0.058F3+0.123
(7)
将式(1)~式(3)代入式(7)可得以样本原始数据为自变量的判别模型
y=0.07x1+0.07x2+0.04x3+0.09x4-0.01x-3.66

(8)
2.2 模型有效性检验
对于判别分析只有当组均值不相等时,才能建立的有效的判别函数,Wilks的Lamada值是在组内平方和的基础上除以样本的总平方和求得的,其值越小说明组别间的均值差异越大,通过计算式(7)的Wilks的Lamada值只有0.4,因此认为G1(突水)、G2(不突水)之间的区分度非常明显,所以在此基础上所建立的判别函数是有统计学意义的。
判别得分和自变量间的相关系数被称为模型的结构矩阵,相关系数越大表明该自变量对于判别模型的影响越大,F1、F2、F3与判别得分的相关系数值分别为-0.535、0.440、0.737,所以该判别函数主要与F3有关,而通过前面的分析可知F3又主要携带的是含水层水压、煤层倾角2个原始自变量的信息,这提示可能含水层水压及煤层倾角两个变量在判别中起到了主要的作用。事实上若只用含水层水压及煤层倾角进行判别分析,模型的综合正确率仍为72.2%。
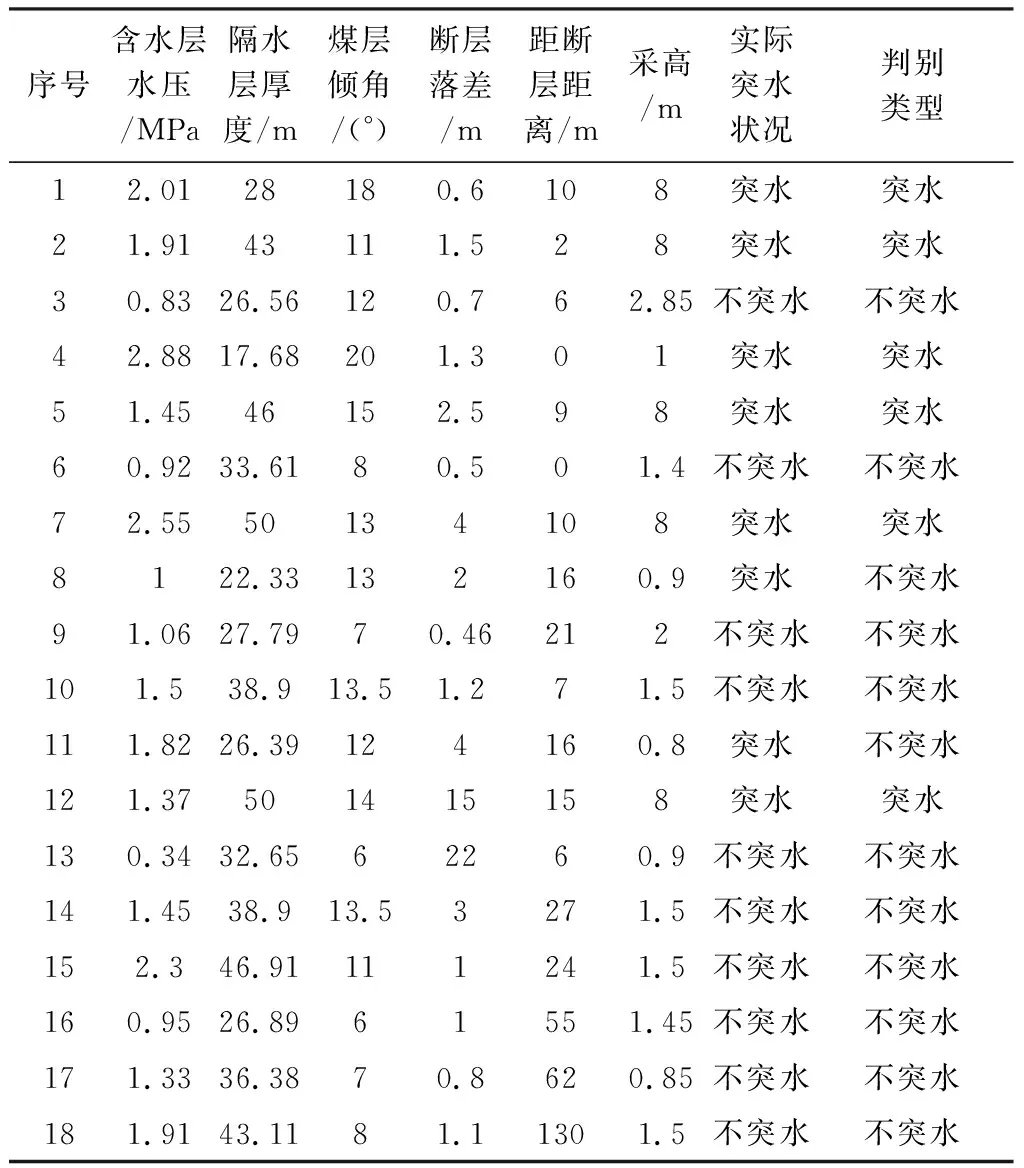
表7 训练样本数据及Fisher模型判别结果
突水组重心处的函数值为1.263,不突水组重心处的函数值为-1.011。通过比较每个样本点与各组重心的马氏距离可以确定该案例的分组倾向性。最终的判别结果见表7,可见对于8例突水样本模型成果预测出了6例,正确率为75%,对于10例不突水样本模型成果预测出了9例正确率为90%,虽然2类样本都存在不同程度的错判但模型的综合正确率已达83.3%。
为进一步检验模型的精度,将运用式(5)对3例待分组样本进行判别分析,从表8可知对于3例样本模型全部取得了与实际吻合的结果。
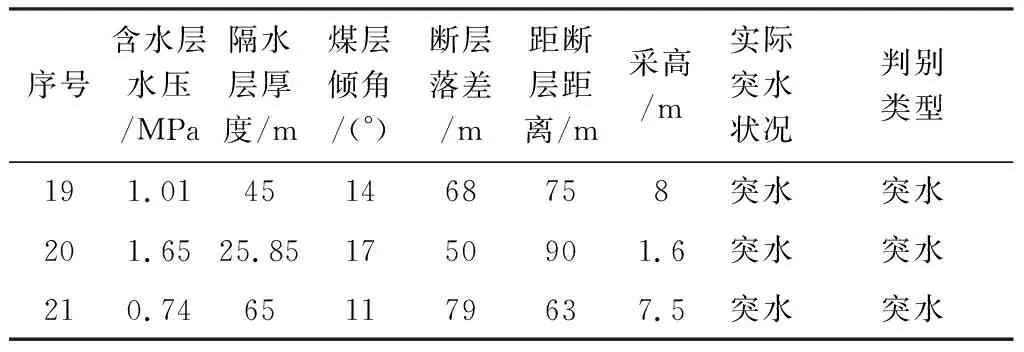
表8 测试样本判别分析结果
3 结论
(1)通过主成分分析法提取了F1、F2、F33个主成分,其累计方差贡献率达到了83.707%,达到了信息浓缩的目的,并且避免了变量间的多重共线性问题。
(2)以主成分得分值为中间变量建立了煤层底板突水的Fisher判别模型,通过对18例训练样本进行回代判别,模型的综合准确率为83.3%。在对3例待分组样本的检验中误判率为0,表明模型对于类似地质条件下底板突水危险性的判别具有一定的参考价值。
(3)突水组与不突水组在含水层水压及煤层倾角两个变量上存在显著差异,因此在全面收集样本数据比较困难的情况下,可重点关注两者的变化,并将其作为判别分析的主要指标。
(4)煤层底板突水是多因素综合作用的结果,因此需要广泛搜集更多具有代表性的突水数据作为训练样本,从而提高模型的精度和适用性。
