普通话双模态情感语音数据库的设计与评价
2018-07-27任国凤张雪英李东闫建政
任国凤 张雪英 李东 闫建政

摘 要: 针对包含发音动作参数和情感语音的双模态汉语普通话数据库非常匮乏的问题,设计包含中性、高兴、愤怒及悲伤4种情感的普通话语音库。该语音库由10名被试录制的1 440段音频及发音动作数据组成,文本长度有双音节词和句子两种类型。为了确保该数据库的有效性,邀请普通话较好、听力正常的10名评价者组成评价小组,对数据库内所有音频文件进行评价。根据评价小组评价结果结合发音动作数据的稳定性进行筛选,得到语音质量较好、发音动作参数稳定的双模态情感语音数据库。该数据库可用于开展情感语音的发音动作研究,进而单独或联合作为情感语音识别算法的样本数据,对情感语音识别率的提高具有积极的作用。
关键词: 数据库; 情感语音; 发音动作参数; 汉语普通话; 信号处理; 普通话语音库
中图分类号: TN912.3?34 文献标识码: A 文章编号: 1004?373X(2018)14?0182?05
Design and evaluation of Mandarin bi?modal emotion speech database
REN Guofeng1,2, ZHANG Xueying1, LI Dong1, YAN Jianzheng1
(1. School of Information Engineering, Taiyuan University of Technology, Taiyuan 030600, China;
2. Department of Electronics, Xinzhou Teachers University, Xinzhou 034000, China)
Abstract: In allusion to the problem of lack of bi?modal Chinese Mandarin database containing pronunciation action parameters and emotional speech, a Mandarin speech corpus that includes four emotions of neutrality, happiness, anger and sadness is designed. The speech corpus is composed of 1 440 segments of audio and pronunciation action data recorded by 10 subjects, and the textual length includes bi?syllable word and sentence. To ensure the validity of the database, 10 evaluators with good Mandarin and normal hearing are invited to constitute the evaluation group, so as to evaluate all the audio files in the database. According to the evaluation results of the evaluation group and in combination with the stability of pronunciation action data, the audio files are screened to obtain the bi?modal emotion speech database with good audio quality and stable pronunciation action parameters. The database can be used to conduct the pronunciation action research of emotional speech, and solely or jointly taken as the sample data of the emotional speech recognition algorithm, which has a positive function for improvement of the emotional speech recognition rate.
Keywords: database; emotional speech; pronunciation action parameter; Chinese Mandarin; signal processing; Mandarin speech corpus
0 引 言
情感语音由于包含了丰富的情感信息,在人们日常交流中起着非常重要的作用,因而对其开展研究有助于进一步了解人们交流时的心理状态[1?2]。同时,伴随着人机交互智能技术的快速发展,情感识别能力作为度量人机交互智能化水平的重要依据,受到众多研究者的青睐。而情感语音识别的研究离不开优质的情感语音数据库的支撑。由于情感认知的复杂性、数据采集的困难性、录制标准的不统一性、情感分类目的和方法的差异性等,导致目前大多数研究机构都是按照各自的科研需求建立相应的情感语音数据库,而无法构建相对统一的情感语音库[3?4]。目前,情感语音领域内存在的情感语音库类型较多,按照激发情感的类别可分为表演型、引导型和自然型[5]。情感的智能交互要求机器具有接近人类的语音情感识别和表达能力。为了实现该目标,建立一个真实自然并且拥有完整情感标注信息的优质情感语音数据库是十分重要的。
然而,人机交互智能的迅猛发展对情感语音的识别能力提出了更高的要求,单一的靠语音作为样本数据已不能满足情感识别的需要。所以越来越多的人将表情、脑电及口腔运动数据采集来进行情感识别[6],通过增加数据的维度以提高识别率。在此方面,美国南加州大学的情感语音小组利用超声波[7]、核磁共振[8]及EMA数据采集仪等与语音同步采集了舌、唇、咽喉等不易准确观察的发音器官的运动[9],并对其分析发现,不同情感下舌部的运动状态明显不同[10]。同时,Kim对英语发音中的情感与唇部运动比较发现,唇孔径的大小也可以作为特征来观察情感变化[11]。我国的中科院先進技术研究院和中国科技大学也对EMA数据进行了提取和分析,但他们的研究集中于可视语音合成及聋哑人康复训练等。近几年,天津大学及清华大学的团队开始了情感语音与EMA数据的结合研究,但是依然没有成熟有效的EMA数据与语音同步结合的汉语普通话双模态情感语音数据库[12]。基于此,本文旨在设计包含中性、高兴、悲伤和愤怒四种情感的普通话情感语音双模态数据库。
1 双模态情感语音数据库的整体设计
1.1 文本素材及被试选择
由于受到发音器官的隐蔽性及语音录制环境的限制,要想获取完全自然的情感语音及相应的发音器官运动信息是几乎不可能的。一般情况下,人们都选择在特定的环境下由外界引导而完成录制。本文所设计的数据库采用场景冥想式方法进行设计,由被试根据文本提示假想特定的语境酝酿相应情感并表达出来[13]。
1.1.1 文本素材的选择
为了情感的表现不失公允,本文中所选择的文本语料均为中性语义,不带有明显的情感倾向。具体的文本内容如表1所示。
1.1.2 被试的选择
本文中被试选择遵循以下原则:
1) 年龄在20~40岁之间;
2) 汉语普通话等级在二级乙等以上;
3) 未接受过牙齿矫正及修复等口腔手术;
4) 未接受过正式的语言表演训练。
因而,本数据库共选择5名男性、5名女性作为被试。所有被试均为籍贯为中国北方的在校研究生,且普通话等级为二级乙等以上。
1.2 采集方案的设计
1.2.1 实验环境
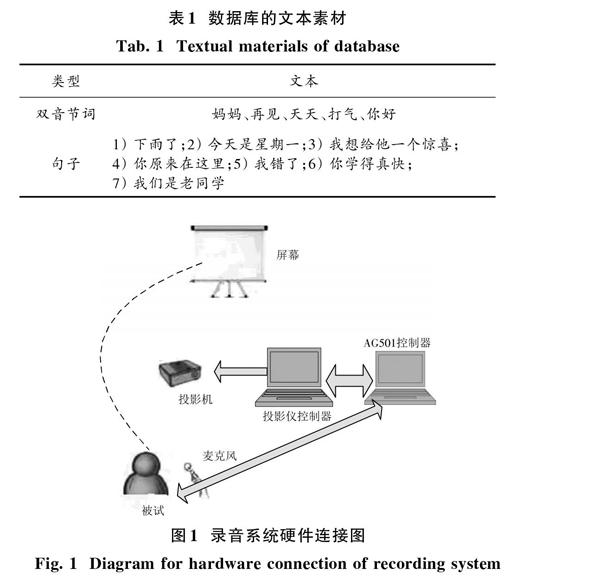
本文设计的数据库需要同步获得语义清晰的语音和误差很小的各发音器官动作数据。录制过程中以德国Carstens公司生产的三维电磁发音仪:AG501为主要采集仪器,同步采集语音和发音动作数据。为确保AG501工作稳定且不受外界电磁场干扰,所有录制均在室温25 ℃左右且远离金属材质的环境中。錄制过程中,使用外置麦克风采集语音、AG501配套传感器采集发音动作数据、投影仪远距离投影以避免被试在录音过程中头部运动太频繁。完整的硬件连接方法如图1所示。
1.2.2 AG501
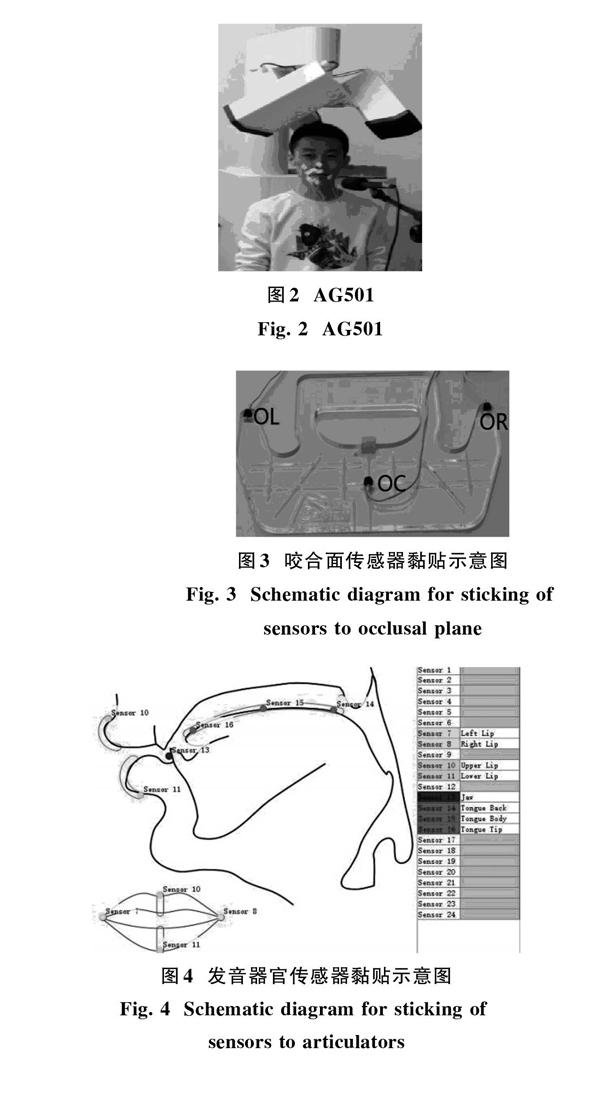
AG501是由德国Carstens公司生产的一款三维电磁发音动作采集仪。该仪器拥有24路采样率为48 kHz的发音动作数据采集通道、一路采样率为1 250 Hz的音频信号采集通道[14]。发音动作由黏贴在发音器官各部位的传感器采集,音频数据由专用麦克风采集。发音动作数据和音频数据可以实现自动同步。具体的仪器图如图2所示。
由于被试间的个体差异及在录制过程中被试的头部不可避免地会发生旋转等动作,仅依靠磁场下的笛卡尔坐标系的三维坐标值判断发音器官运动是不准确的,因此在录制过程中需要对头部进行校准。本研究中,为了更好地进行头部校准,传感器的黏贴工作分两步完成。
1.2.3 录制流程
搭建好录制系统后,具体的录制流程如下:
1) 录制前的准备工作。打开AG501电源让其预热15 min以上。在此期间,对被试进行简单培训。同被试签订知情同意书,并帮助被试熟悉录制流程及文本语料。同时,确保被试未佩戴任何金属类饰物。
2) 头部校准。将传感器黏贴在左右乳凸、鼻梁和图3所示的咬合面矫正板上。让被试坐在指定位置上,口中含着咬合面矫正板并将矫正板的凸起部位卡在上切牙内侧。由AG501采集各传感器运动数据并生成头部旋转矩阵,进而按该旋转矩阵对原始数据进行头部旋转使得图3中所示凸起为坐标原点、OL和OR在y轴上并以原点对称、OC在x轴上,三个参考点的z坐标均为零。
3) 黏贴剩余传感器。在完成头部校准后,其余的传感器将分别被黏贴到上下唇、左右嘴角和舌尖、舌中和舌根。具体的黏贴位置如图4所示。为了得到理想的动作数据,舌尖的传感器黏贴于距生理舌尖1 cm处,舌根位置的传感器在被试能承受的范围内尽量往舌根部黏贴,而舌中位置传感器位于舌尖和舌根位置传感器的中间点上,它距两个传感器的距离不得小于1 cm。
4) 录制语音。被试按照投影屏幕提示文本信息,依次表达中性、高兴、愤怒和悲伤4种情感,每种情感重复表达3次。这样,双音节词一共录制600条(10名被试×5条文本×4种情感×3次重复),句子一共录制 840条(10名被试×7条文本×4种情感×3次重复)。
2 双模态情感语音库的预处理
本设计中用到的发音动作采集仪:AG501可得到采样频率为1 250 Hz的语音信号。为滤除外界噪声,选择截止频率为1 300 Hz巴特沃斯低通滤波器进行滤波。同时,对语音信号和发音动作数据文件进行统一命名并编号,该文件名具体格式为“编号?语料类型?情感类型?重复次数?被试”。其中,编号取值范围为1~1 440,语料类型为j(表征句子)和s(表征双音节词),情感类型为a(表征愤怒)、h(表征开心)、n(表征中性)和s(表征伤心),重复次数取值范围为1~3,被试取值分别为f1~f5及m1~m5。
3 双模态情感语音库的评价及筛选
3.1 语音信号的评价
人的情感表达具有很高的主观性,表演者所表达的情感强度和别人所感受到的情感强度很难完全一致。同时,参与本语料库录制的被试均未接受过语言表演训练,缺乏情感表演的经验。为了研究者能从他们的语料中得到比较客观的情感数据,需要有一个统一的评价方法对其进行评价。本文中选择普通话标准、听力很好的5位男性和5位女性成立语料评价小组,每一位评价组成员需从被评语音的清晰度和情感表现度两方面独立打分。打分过程按照李斯特量表法进行[15],具体评分规则如表2所示。
其中,语音清晰度评价时不区分被试希望表达的情感类型,而情感表现度的主观评价需将文件事先按照被试希望表达情感类型进行分类,再由评价小组成员对同一情感类型下的语料逐一进行听测。同时,中性语料无需进行情感表现度听测。
通过评价小组成员对语音材料的独立评价,得到10名评价者的评分结果。令[Ui]表示语料的平均语音清晰度,[Di]表示语料的平均情感表现度。其中[i]表示语音材料的编号,N表示评价小组成员总人数,这里N=10,j表示成员编号。则有:
[Ui=1Nj=1Nui,j, i=1~1 140; j=1~10] (1)
[Di=1Nj=1Ndi,j, i=1~1 140; j=1~10] (2)
其中,中性情感语料的情感表现度得分取5分。
根据得到的统计数据可对语音数据做统计评价以筛选出表现较好的语料用于情感语音识别等研究中。具体筛选阈值为语音清晰度得分不小于4.5分,且情感表现度得分不小于4.0分的语料被认定为有效语料。
3.2 發音动作数据的评价
RMSE(均方根误差)是用来表征数据离散程度的一个重要指标,它揭示了数据的稳定程度。因而,在本数据库评价过程中,选择该参数作为发音动作数据的评价参数。根据任一语料采集到的某一传感器的发音动作数据,可直接计算该参数。计算方法如下:
[RMSE=i=1nd2in] (3)
式中:[n]为某一语料发音动作数据点的数量;[di]为任一数据点与均值点间的欧氏距离。
因此,式(3)可进一步写为:
[RMSE=i=1n(xi-x)2+(yi-y)2+(zi-z)2n] (4)
一般情况下,RMSE值越小发音动作数据越稳定。本设计中,RMSE值小于10 mm的动作数据被判定为稳定数据。在数据筛选过程中,筛选掉大于10 mm的数据。
根据语音数据和发音动作数据的双重评价及筛选,本数据库最终保留有403个双音节词及510条句子。具体情况如表3所示。
4 结 语
一个情感丰富、数据多样的情感数据库,对研究者进行情感语音识别研究,并作为情感语音合成的训练测试平台是非常重要的。本文中设计的结合发音动作参数及语音两类数据的情感语音数据库,包含了双音节词和句子两种类型文本,共计913多条语料。在一定程度上可为生理语音研究及情感语音的发音动作研究等提供服务。进而,该数据库着重于帮助研究者针对汉语普通话的情感语音识别研究提供数据支撑。同时,本数据库也可以单独作为发音器官的运动研究或者普通发音人的情感研究,甚至可扩展到普通话的情感语音合成研究领域中。
当然,该数据库也存在一定的不足之处。首先,文本内容还可以进一步丰富,从而提高数据库的普适性;其次,传感器数量不多,难以增加眼睑等面部运动信号的采集以丰富情感数据。
参考文献
[1] 韩文静,李海峰,阮华斌,等.语音情感识别研究进展综述[J].软件学报,2014,25(1):37?50.
HAN Wenjing, LI Haifeng, RUAN Huabin, et al. Review on speech emotion recognition [J]. Journal of software, 2014, 25(1): 37?50.
[2] 张雪英,孙颖,张卫,等.语音情感识别的关键技术[J].太原理工大学学报,2015,46(6):629?636.
ZHANG Xueying, SUN Ying, ZHANG Wei, et al. Key technologies in speech emotion recognition [J]. Journal of Taiyuan University of Technology, 2015, 46(6): 629?636.
[3] 赵国朕,宋金晶,葛燕,等.基于生理大数据的情绪识别研究进展[J].计算机研究与发展,2016,53(1):80?92.
ZHAO Guozhen, SONG Jinjing, GE Yan, et al. Advances in emotion recognition based on physiological big data [J]. Journal of computer research and development, 2016, 53(1): 80?92.
[4] 韩文静,李海峰.情感语音数据库综述[J].智能计算机与应用,2013,3(1):5?7.
HAN Wenjing, LI Haifeng. A brief review on emotional speech databases [J]. Intelligent computer and applications, 2013, 3(1): 5?7.
[5] 陈浩,师雪姣,肖智议,等.高表现力情感语料库的设计[J].计算机与数字工程,2014,42(8):1383?1385.
CHEN Hao, SHI Xuejiao, XIAO Zhiyi, et al. High performance emotional corpus [J]. Computer & digital engineering, 2014, 42(8): 1383?1385.
[6] AN J, BERRY J J, JOHNSON M T. The electromagnetic articulography Mandarin accented English corpus of acoustic and 3D articulatory kinematic data [C]// Proceedings of IEEE International Conference on Acoustic, Speech and Signal Processing. Florence: IEEE, 2014: 7719?7723.
[7] NARAYANAN S, NAYAK K, LEE S, et al. An approach to real?time magnetic resonance imaging for speech production [J]. Journal of the Acoustical Society of America, 2004, 115(4): 1771?1776.
[8] MATSUO K, PALMER J B. Kinematics linkage of the tongue, jaw, and hyroid during eating and speech [J]. Archives of oral biology, 2010, 55(4): 325?331.
[9] LEE S, YILDRIM S, KAZEMZADEH A, et al. An articulatory study of emotional speech production [C]// Proceedings of 9th European Conference on Speech Communication and Technology. Lisbon: [s.n.], 2005: 497?500.
[10] NEUFELD C, VAN L P. Tongue kinematics in palate relative coordinate spaces for electro?magnetic articulography [J]. Journal of the Acoustical Society of America, 2014, 135(1): 352?361.
[11] KIM J, TOUTIOS A, LEE S, et al. A kinematic study of critical and non?critical articulators in emotional speech production [J]. Journal of the Acoustical Society of America, 2015, 137(3): 1411?1429.
[12] WEI J, LIU J, FANG Q, et al. A novel method for constructing 3D geometric articulatory models [J]. Journal of signal processing systems, 2016, 82(2): 295?302.
[13] 吴丹,林学訚.人脸表情视频数据库的设计与实现[J].计算机工程与应用,2004(5):177?180.
WU Dan, LIN Xueyin. The design and realization of a video database for facial expression analysis [J]. Computer engineering and applications, 2004(5): 177?180.
[14] YUNUSOVA Y, GREEN J R, MEFFERD A. Accuracy assessment for AG500, electromagnetic articulograph [J]. Journal of speech language & hearing research, 2009, 52(2): 547?555.
[15] 王宝军,薛雨丽,于适宁,等.多模情感数据库的设计与评价[J].中国科技论文,2016,11(2):214?218.
WANG Baojun, XUE Yuli, YU Shining, et al. The design and evaluation of multimode affective database [J]. China sciencepaper, 2016, 11(2): 214?218.
