大数据集合中冗余特征排除的聚类算法设计
2018-07-27侯莉莎
侯莉莎
摘 要: 传统microRNA聚类算法对数据的新特征要求较高,未全面分析大数据集内的冗余特征,使得聚类结果均衡性差。因此,提出大数据集合中冗余特征排除的聚类算法,其采用聚类集成算法,在组构造时期通过使用一致的聚类算法抽取各种子集样本,实现大数据冗余特征的排除,获取排除冗余特征的大数据集聚类结果。对得到的大数据聚类特征分类能力以及特征关联性实施度量,采用基于特征聚类以及随机子空间的miRNA识别算法,实现大数据集合冗余特征的聚类。实验结果表明,所提算法具有较高的冗余数据排除性能,该算法下的大数据聚类效果优,具有较高的均衡性。
关键词: 大数据集; 冗余特征排除; 聚类算法; 特征关联性; 随机子空间; miRNA识别算法
中图分类号: TN911?34; TP311 文献标识码: A 文章编号: 1004?373X(2018)14?0048?03
Design of clustering algorithm for redundancy feature removal in big data sets
HOU Lisha1,2
(1. Tianjin University, Tianjin 300072, China; 2. Beijing Professional Business Institute, Beijing 102488, China)
Abstract: The traditional microRNA clustering algorithm has relatively high requirements for new features of data, and the redundancy feature in big data sets are not fully analyzed, resulting in poor equilibrium of clustering results. Therefore, a clustering algorithm for redundancy feature removal in big data sets is proposed, in which the integrated clustering algorithm is adopted, and samples of various subsets are extracted by using the consistent clustering algorithm during the group construction period, so as to realize the redundancy feature removal of big data, and obtain the clustering results of big data for redundancy feature removal. The classification capability and correlation of the obtained big data clustering features are measured. The miRNA recognition algorithm based on feature clustering and stochastic subspace is adopted to realize clustering of big data sets and redundancy features. The experimental results show that the proposed algorithm has high redundancy data removal performance, and the big data clustering effect under the algorithm is superior with high equilibrium.
Keywords: big data set; redundancy feature removal; clustering algorithm; feature correlation; stochastic subspace;
miRNA recognition algorithm0 引 言
隨着社会经济的飞速发展,带动信息技术和数据存储技术的迅猛发展,促使数据量规模也逐渐增大,大量的高维度数据在金融领域、生物医药领域以及数据传感领域应用较广,高维度和海量的数据中可能存在大量的冗余信息,在实际应用中需要对冗余数据进行剔除,对大数据集合中冗余数据特征的聚类算法设计是提高海量高维度数据利用率的有效手段[1]。传统microRNA聚类算法,对数据的新特征要求较高,未全面分析大数据集内的冗余特征,使得聚类结果均衡性差。本文设计大数据集合中冗余特征排除的聚类算法,提高算法的聚类效果,增强大数据聚类的均衡性。
1 大数据集合中冗余特征排除的聚类算法
1.1 聚类集成算法
通过聚类集成手段来构成组特征进而完成组构造。若历史数据集是[D],其中含有[n]个训练标本,[D=X,Y=xi,yini=1],第[i]个分子是[d]维向量在此数据集内。
本文选取的聚类集成方法,以聚类分析为基准包含多种优势,具有良好的平均性,广泛使用的办法如下:
1) 在数据集合聚类算法完全一致的情况下,可以通过对算法参数的特殊设定进而生成多种聚类结果[2];
2) 当数据集一致时可通过其他聚类算法进行计算,获取多种聚类结果;
3) 在初始数据集中获取多种子集,通过一致的聚类算法针对子集实施聚类进而得到各种聚类结果;
4) 通过初始数据集获得一定数量的特征子集,针对特征子集实施同种聚类算法,也可获得多个聚类结果。
本文提出的聚类算法是指在组构造时期,通过使用一致的聚类算法抽取各种子集样本,实现大数据冗余特征的排除,获取排除冗余特征的大数据集聚类结果。详细程序如下,选取bigging思想作为训练集分类器的基础,根据有反应的抽样样本来实现样本子集的收集过程。若利用bigging思想获取到多种样本子集,此间某一个聚类器选取K?means方法。此方法在保证子集特点接近性的基础上完成收集[3],实现了针对大数据集中冗余特征的聚类。
此间特征中的接近性度量手段采取关联数据。随机变量分别由[u],[v]代替,它们和关联系数[ρ]的关系如下:
[ρu,v=covu,vvar(u)var(v)] (1)
式中:[var]代表变量的方差;[cov]表示两个变量的协方差。若[u]以及[v]具有关联性,则二者确定为非动态关联,[ρu,v]为1或-1;若[u]与[v]不具备关联性,[ρu,v]为0。所以,变量[u]以及变量[v]的接近性可以借助[1-ρ(u,v)]来进行检验[4]。
针对[m]个样本子集实施K?means聚类,可获得[m]个聚类结果,单一聚类结构都具有不同特征,为[C11,…,C1l1,…,Cm1,…,Cmlm]。此间第[h]次聚类形成的第[j]个特点类型用[Chj]代表,第[m]次聚类形成的全部特征数据用[lm]表示。
根据以上在特征接近性K?means方法中获得的各种聚类结果结合为聚类集体以后,接下来应选取相符的集成方法进行聚类结果总结。本文以互联矩阵为基础,针对[m]个聚类结果将同组中的每一种特征实施划分计算,再用聚类次数[m]予以平均计算[5],得出用矩阵[Wq,r]代表特征[q]以及特征[r]的接近程度。最后根据凝聚型分层聚类,针对全部特征实施合并,以特征组中的接近性不小于[θ,θ]的特定数据为合并基础,通过类平均措施统计特征组中的接近性,使其不受异常值变化的干预。
1.2 结果表征以及评价
1.2.1 特征分类能力度量
一般情况下特征分类能力由信息增益率来进行检验[6]。将训练数据集设为D,客观pre?miRNA以及伪发夹组成序列由[Ci(i=1,-1)]来依次代表。正例标本集合以及反例标本集合分别由[Dp],[Dn]表示。由此得出数据集D的信息熵计算公式:
[H(D)=-iP(Ci)lb P(Ci)] (2)
式中,[P(Ci)]表示随机样本归属类别[Ci]的可能率,设[i=1],那么[P(Ci)=DpD],相反[P(Ci)=DnD]。
1.2.2 特征关联性度量
特征相关性度量由两部分构成:第一部分是由Pearson积矩关联数据、线性关联数据组成的线性关联;另外一部分是熵,包括信息增益性和未知性等。本文利用熵的对称未知性对特征中的动态相关性进行分析[7]。特征[X]取第[i]个值的几率由[P(xi)]表示,特征[Y]取值是[yi]时特征[X]取值是[xi]的几率由[P(xiyi)]表示,[X]的数据熵计算方法如下:
[SUX,Y=2IGXYHX+HY] (3)
定义对称未知性[SUX,Y]来评价特征[X]和特征[Y]的关联性,过程见式(3)。借此获得特征关联性度量[SUX,Y∈ [0,1]],若取值是0,那么特征[X]以及特征[Y]都处于独立状态,若取值是1,则表示特征[X]与特征[Y]具有极强的相关性[8]。
1.3 基于特征聚类以及随机子空间的miRNA识别算法
本文基于1.1小节聚类集成算法排除大数据冗余特征后,得到的大数据集聚类特征和随机子空间的基础上,采用miRNA识别算法,根据特征取得备用特征集,按照特征关联性对备用数据集进行归类[9],在各个簇中任意抽取等量特征构建出特征集用以形成基分类器,最终根据投票办法对位置序列是否归属miRNA实施辨别。
为了使随机两簇中特征阈值低于最小距离,可通过凝聚最短距离层次聚类算法对备用特征集实施计算,将原始化的单独特征进行单独分类,最后使用[Dist]完成合并替换矩阵[10]。根据特征集[S]从初始信息中获得数据集训练分类器,通过分类器集成手段判断抽取标本所属类型。
2 实验分析
为了验证本文算法在解决大数据集合中冗余特征排除结果的有效性,以模糊信息粒化算法、粗糙集近似算法、多维数据去重算法为对比算法,这些聚类算法本身可以针对不同类型的数据进行冗余特征排除。
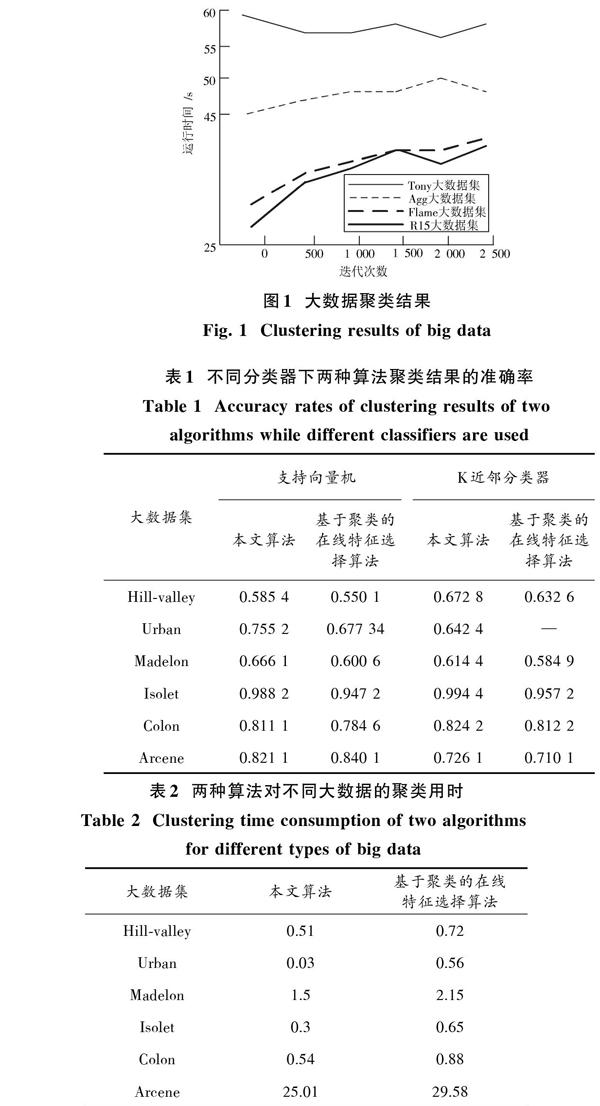
实验选取的大数据为某高校教学用的测试数据集,选取的样本大数据集有Tony,R15,Flame以及Aggregation大數据集。检测结果如图1所示。从图1实验检测结果可以看出,本文算法在样本4个具有不同特征大数据集上均能够得到聚类结果且用时也较短,并且本文算法聚类结果具有较高的均衡性。
为了分析本文算法的计算性能,将本文算法用于不同的大数据集上对本文算法的聚类性能以及用时情况进行测试,实验数据集来自UCI数据库。
实验采用十字交叉验证法对Isolet大数据集中的数据集评分成10分,其中训练用数据集占[15],其余为实验测试用。表1为采用不同分类器下,本文算法和基于聚类的在线特征选择算法聚类结果的准确率;表2为本文算法和基于聚类的在线特征选择算法对不同大数据集的聚类用时。
从表1分类结果的准确率结果可以看出,本文算法无论采用哪一种分类器分类结果的准确率都要优于基于聚类的在线特征选择算法。在数据维度较高的Urban数据集上,基于聚类的在线特征选择算法不能对其数据操作,可以得出本文算法能够提高大数据的分类正确率,以及对高维度的大数据也能进行正确分类。从表2算法的计算用时可以看出,本文算法和基于聚类的在线特征选择算法在对相同的大数据进行冗余特征排除法聚类中,本文算法的运算用时均低于基于聚类的在线特征选择算法,说明本文算法的时间效率较好,可以节省时间成本。
3 结 论
本文提出新的用于解决大数据集合中冗余特征排除的聚类算法,其通过基于特征聚类以及随机子空间的miRNA识别算法,实现大数据的高效率、准确聚类,并且增强了大数据聚类的均衡性。
参考文献
[1] 古凌岚.面向大数据集的有效聚类算法[J].计算机工程与设计,2014,35(6):2183?2187.
GU linglan. Efficient clustering algorithm for large data sets [J]. Computer engineering and design, 2014, 35(6): 2183?2187.
[2] 羅恩韬,王国军.大数据中一种基于语义特征阈值的层次聚类方法[J].电子与信息学报,2015,37(12):2795?2801.
LUO Entao, WANG Guojun. A hierarchical clustering method based on the threshold of semantic feature in big data [J]. Journal of electronics & information technology, 2015, 37(12): 2795?2801.
[3] 张顺龙,库涛,周浩.针对多聚类中心大数据集的加速K?means聚类算法[J].计算机应用研究,2016,33(2):413?416.
ZHANG Shunlong, KU Tao, ZHOU Hao. Accelerate K?means for multi?center clustering of big datasets [J]. Application research of computers, 2016, 33(2): 413?416.
[4] 向尧,袁景凌,钟珞,等.一种面向大数据集的粗粒度并行聚类算法研究[J].小型微型计算机系统,2014,35(10):2370?2374.
XIANG Yao, YUAN Jingling, ZHONG Luo, et al. A coarse?grained clustering unit based parallel algorithm for big data set [J]. Journal of Chinese computer systems, 2014, 35(10): 2370?2374.
[5] 谢川.基于混沌关联维特征提取的大数据聚类算法[J].计算机科学,2016,43(6):229?232.
XIE Chuan. Big data clustering algorithm based on chaotic correlation dimensions feature extraction [J]. Computer science, 2016, 43(6): 229?232.
[6] 张晓,王红.一种改进的基于大数据集的混合聚类算法[J].计算机工程与科学,2015,37(9):1621?1626.
ZHANG Xiao, WANG Hong. An improved hybrid clustering algorithm based on large data sets [J]. Computer engineering and science, 2015, 37(9): 1621?1626.
[7] 朱琪,张会福,杨宇波,等.基于减法聚类的合并最优路径层次聚类算法[J].计算机工程,2015,41(6):178?182.
ZHU Qi, ZHANG Huifu, YANG Yubo, et al. Combined optimal path hierarchical clustering algorithm based on subtractive clustering [J]. Computer engineering, 2015, 41(6): 178?182.
[8] 周润物,李智勇,陈少淼,等.面向大数据处理的并行优化抽样聚类K?means算法[J].计算机应用,2016,36(2):311?315.
ZHOU Runwu, LI Zhiyong, CHEN Shaomiao, et al. Parallel optimization sampling clustering K?means algorithm for big data processing [J]. Journal of computer applications, 2016, 36(2): 311?315.
[9] 卢志茂,冯进玫,范冬梅,等.面向大数据处理的划分聚类新方法[J].系统工程与电子技术,2014,36(5):1010?1015.
LU Zhimao, FENG Jinmei, FAN Dongmei, et al. Novel partitional clustering algorithm for large data processing [J]. Systems engineering and electronics, 2014, 36(5): 1010?1015.
[10] 巩树凤,张岩峰.EDDPC:一种高效的分布式密度中心聚类算法[J].计算机研究与发展,2016,53(6):1400?1409.
GONG Shufeng, ZHANG Yanfeng. EDDPC: an efficient distributed density peaks clustering algorithm [J]. Journal of computer research and development, 2016, 53(6): 1400?1409.
