基于Random Forest 和AHP的贵德县北部山区滑坡危险性评价
2018-07-26张向营张春山孟华君王雪冰赵伟康郑满城中国地质科学院地质力学研究所北京100081自然资源部新构造运动与地质灾害重点实验室北京100081北京城建勘测设计院有限责任公司北京100101中国地质大学北京地球科学与资源学院北京100083
张向营,张春山,孟华君,王雪冰,赵伟康,4,郑满城,4(1.中国地质科学院地质力学研究所, 北京 100081;2.自然资源部新构造运动与地质灾害重点实验室,北京 100081;3.北京城建勘测设计院有限责任公司,北京 100101;4.中国地质大学(北京)地球科学与资源学院,北京 100083 )
滑坡是我国山区环境中破坏最严重的地质灾害之一[1],开展滑坡危险性区划工作对实现防灾减灾、灾害管理等具有重要的现实意义。
自20世纪60年代GIS技术出现后,国内外学者对滑坡危险性区划方法进行了积极的探索,至今已发展了近几十种评价模型[2],主要包括信息量模型[3]、逻辑回归模型[4]、证据权重模型[5]、贡献率模型[6]、聚类分析[7]、神经网络模型[8]等客观评价模型及层次分析法等主观评价模型[9~10]。这些成果丰富了滑坡危险性的分析与评价,但也都存在不同程度的缺陷,如主观评价模型存在人为主观性、模型普适性等问题;客观评价模型则存在样本数据点要求较高、指标选取缺乏科学依据等问题。随机森林算法[11](Random Forest,RF)具有很高的学习能力和预测精度,已广泛应用于医学、自然生态学、市场经济学等统计领域[12],在滑坡危险性区划领域中也有应用[13~14],但使用者均局限于模型本身,并未克服客观赋权法存在的共性问题。
为探索更为实用的组合评价形式,选取应用较为成熟的层次分析法(Analytic Hierarchy Process,AHP)和随机森林算法分别得到致灾因子的主、客观权重,然后基于距离函数计算得到组合权重,构建组合评价模型,并以青海省贵德县北部地区为研究区,对3种模型区划结果进行对比分析,探讨组合模型的可靠度。
1 研究方法
1.1 随机森林算法
随机森林算法集成了Bagging与Random subspace两种主流学习方法,与其他统计学学习方法相比,两个随机性的引入,使得随机森林算法不容易陷入过拟合,在运算量没有显著提高的前提下提高了预测精度,而且在异常值和噪声方面具有较高的容忍度,结果对缺失数据和非平衡的数据比较稳健[11]。其主要步骤见图1。
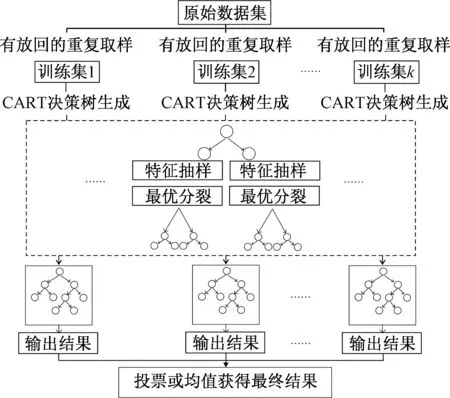
图1 随机森林方法步骤[19]Fig.1 Schematic illustration of the Random Forest method
(1)因子选择及多元共线性诊断
在对复杂决策系统充分了解的基础上,划分出层次结构及其各因子的从属关系,在滑坡危险性区划中,筛选出n个滑坡危险性评价指标(x1,x2,…,xn)。为避免多个变量高相关,造成模型方程的不稳定,构建随机森林模型之前还应对各因子进行多元共线性诊断。常用的多元共线性考核指标包括因子相关矩阵的条件数κ和方差膨胀因子(Variance Inflation Factor)两类[15]。同时,为了减少单一取样方式对模型结果产生的影响,应将总体样本数据(由正样本和负样本等量组成)按一定比例(α︰1-α)随机划分为训练样本集和检验样本集两类。
(2)模型建立及检验
随机森林模型的创建及结果验证部分是在R软件环境下进行的,它可以提供一些集成的统计工具,如本次建模需要的 “RandomForest”、“caret” 工具包。对于建模效果的评价,模型运算的不同阶段中所用的检验指标也不尽相同,通常包括混淆矩阵(Confusion matrix)验算、接受灵敏度曲线(Receiver-Operating Characteristic,ROC)、曲线下面积(Area Under Curve)、泛化能力和预报效率曲线[16]等指标。
(3)结果分析及客观权重确定
各建模因子对于滑坡危险性的贡献和影响规律各不相同,对各变量贡献及影响规律进行量化分析,可以为后期滑坡灾害管理、防灾减灾工作提供重要指导。随机森林方法的一个重要特性就是能够计算每个变量的重要性值,RF提供两种基本的变量重要性值:平均Gini指数降低度(Mean Decrease Gini)和平均准确率降低度(Mean Decrease Accuracy)[11]。其中,平均准确率降低度为袋外数据自变量值发生轻微扰动后的分类正确率与扰动前分类正确率的平均减少量;平均Gini指数降低度是用来表示所有树的变量分割节点平均减小的不纯度。本次评价把平均Gini指数降低度作为相应因子的客观权重值ωi(i=1,2, …,n)。
1.2 层次分析法
层次分析法(AHP)是一种定性与定量分析方法相结合的综合性评价方法,目前在地质灾害危险性评价领域中是应用最为成熟的模型之一[17],其主要步骤如下:
(1)构建判断矩阵U
在RF模型筛选的滑坡危险性评价指标基础上,为了量化各评价因子的主观赋值权重,评价因子之间需形成一个两两对比的矩阵,利用1~9标度表示评价因子之间的影响强弱(表1),通过专家赋值法确定各判别因子之间的相对重要性并赋与相应的分值,形成行、列相等的对称矩阵U。

表1 1~9标度的意义表Table.1 Meaning of scales 1 to 9 in the judgment matrix
(2)确定主观权重
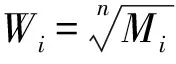
1.3 组合赋权
层次分析法计算出的权重作为主观权重,随机森林法计算出的权重作为客观权重,利用特定的数学理论公式,使主、客观权重有机地结合起来称之为组合赋权。目前,关于组合赋权的方法主要包括基于乘法归一化的组合赋权法[18]、线性加权组合法[19]、距离函数法[20]等。线性加权法主要是根据主观实际经验判断分配系数,人为干扰相对强烈;乘法归一化则是对各权重与其对应的指标值之间的差异程度进行优化,但当数据特征差异性较大时,可靠度会显著下降;而距离函数法引入了距离函数的概念,将主、客观权重之前的差异程度与其对应的分配系数间的差异程度一致化,有机地结合起来,既兼并了评判者对实际情况的主观经验,又使组合权重具有统计学意义。因此,笔者采用了距离函数法进行组合赋权,具体步骤如下:
设由层次分析法确定的主观权重为ai,由随机森林法确定的客观权重为ωi,两者的距离函数为d(ai,ωi)[20],其表达式为:
(1)
设组合权重为φi,组合权重值为二者的线性加权,表达式为:
φi=μai+νωi
(2)
式中:μ、v——主、客观权重的分配系数。
为了使不同权重之间的差异程度和分配系数间的差异程度一致,使分配系数与式(1)中的距离函数取等式,其表达式为:
d(ai,ωi)2=(μ-ν)2
(3)
μ+ν=1
(4)
联立式(3)、(4),即可得组合赋权的分配系数μ、v。
(5)
ν=1-μ
(6)
再将μ、v带入式(2),即可得到综合权重值φi。
1.4 综合评价模型
本文滑坡危险性评价方法主要采用综合指数评价法,由综合评价指数计算获取,其计算公式为:
(7)
式中:W——滑坡灾害危险性综合指数;
ai——评价因子;
φi——综合权重。
根据上述滑坡灾害相关性影响因子统计分析结果,分别使用主观权重、客观权重和综合权重,在ArcGIS软件中把各因子栅格图层进行空间叠加运算,分别得到了研究区滑坡危险性分区图,在此基础上利用自然断点法将危险性区划图各自分为四类:低危险性、中危险性、高危险性、极高危险性。
2 实例分析
2.1 研究区概况
贵德县北部山区地处青海省海南藏族自治州东部,处于黄河上游龙羊峡与李家峡之间,黄河由西向东横贯其中,区内沟壑纵横,中部呈多级河流阶地和盆地丘陵地貌,南北两侧为高山峡谷地貌。气候属大陆性高原气候,特点是“冬寒夏短日照长,风多雨少、太阳辐射强”,年降水量在251~559 mm之间。大地构造位置处于南祁连块体和西秦岭块体的交接部位,受构造运动影响,区内主要为NWW向走滑断裂和逆冲断裂。岩性包括松散第四系沉积物,新近系钙质泥岩、粉砂岩及砂岩及零星出露的早古生界和中古生界侵入岩,其中,新近系地层为区内主要的易滑地层。
2.2 数据来源及因子选择
选择地形地貌、年降雨量、地质条件、水文、人类工程活动、植被等6大类10个指标作为研究区滑坡危险性影响因子(表2)。其中,植被归一化指数(NDVI)为利用Landsat8遥感影像在ENVI软件中提取生成,其余因子都在ArcGIS软件中处理生成。表2中专家认可度这一指标主要是在层次分析法中构造判断矩阵时使用。
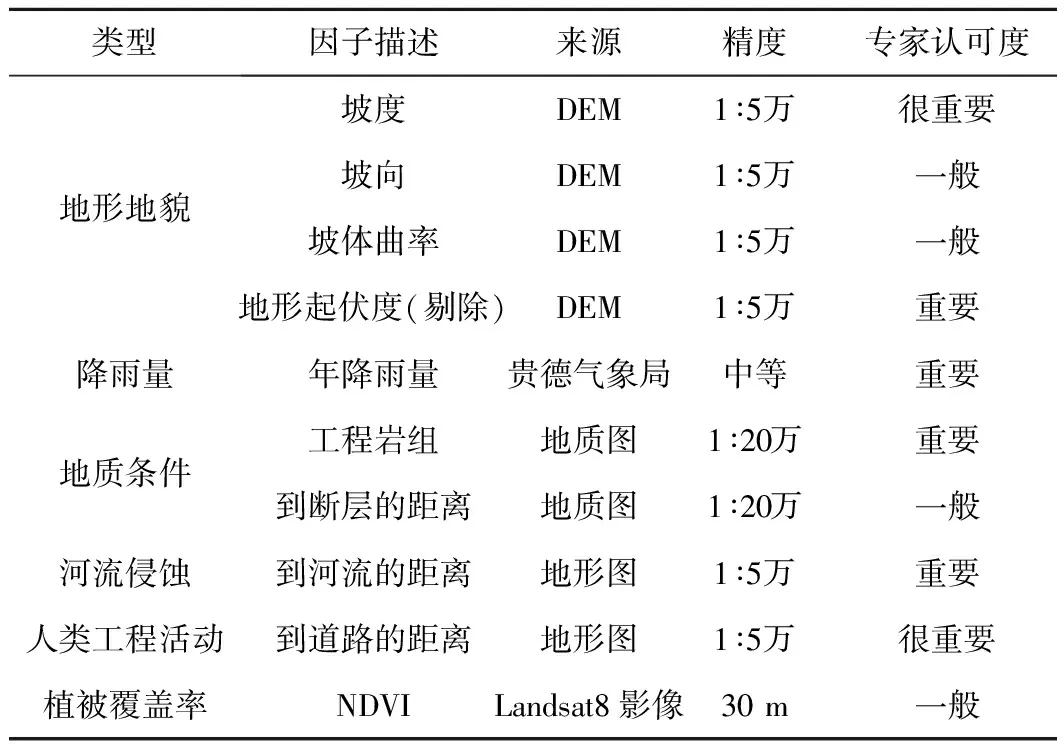
表2 滑坡因子说明表Table 2 Explaination of influencing factors
2.3 客观权重
(1)多元线性诊断
本文建模所需的样本集包括正样本和负样本两部分,正样本集为野外实地调查的158个滑坡点,负样本集是为维持数据样本的平衡性,利用ArcGIS随机取样工具,在已知滑坡点100 m外随机选取的158个非滑坡点组成的样本集。并把样本总集随机划分为70%的样本数据作为训练样本集和30%的样本数据作为检验样本集。
在获取总样本后,基于R软件平台进行了因子多元线性诊断,得到各因子特征之间的相关性系数。发现坡度与高差之间的特征相关性系数高达0.68,呈较高的相关性,而其他因子相关性系数均小于0.25,因此,为维持模型的结果客观性,本次危险性区划剔除了高差这个因子。

图2 研究区滑坡位置点Fig.2 Location of landslide in the study area
(2) 模型建立及评价
参数mtry是随机森林建模中构建决策树分支时随机抽样的变量个数[21],通过遍历设定mtry为1至9,并进行9 次建模,打印出每次建模的错误率,选择错误率最低的mtry取值为3。通过模型错误率与决策树数量的关系可视化,本次模型选择以mtry=3,ntree=150进行随机森林建模。建立模型后,选择Kappa系数[13]对模型结果进行了评价检验。本次模型的混淆矩阵见表3。

表3 混淆矩阵Table 3 Confusion matrix
从表2可以看出模型对于测试样本集的预测情况,实际未滑动而预测滑动的样本个数为8,实际发生滑动而预测未滑动的样本个数为6。由Kappa系数的计算公式[13]可得,模型的Kappa系数为0.82,总体来说,模型预测精度较高。
随机森林模型有两种衡量滑坡因子相对重要性的方式:①将某滑坡因子的取值随机打乱。分析其打乱前后随机森林的准确性和错误率,模型错误率提升越多的因子越重要,即平均准确率降低度(Mean Decrease Accuracy);②计算某因子对森林中所有决策树节点不纯度的影响,即平均Gini指数降低度(Mean Decrease Gini),该值越大表示该变量的重要性越大。通过R语言的importance命令,得到了9个滑坡因子的重要性评价,结果如图3所示。
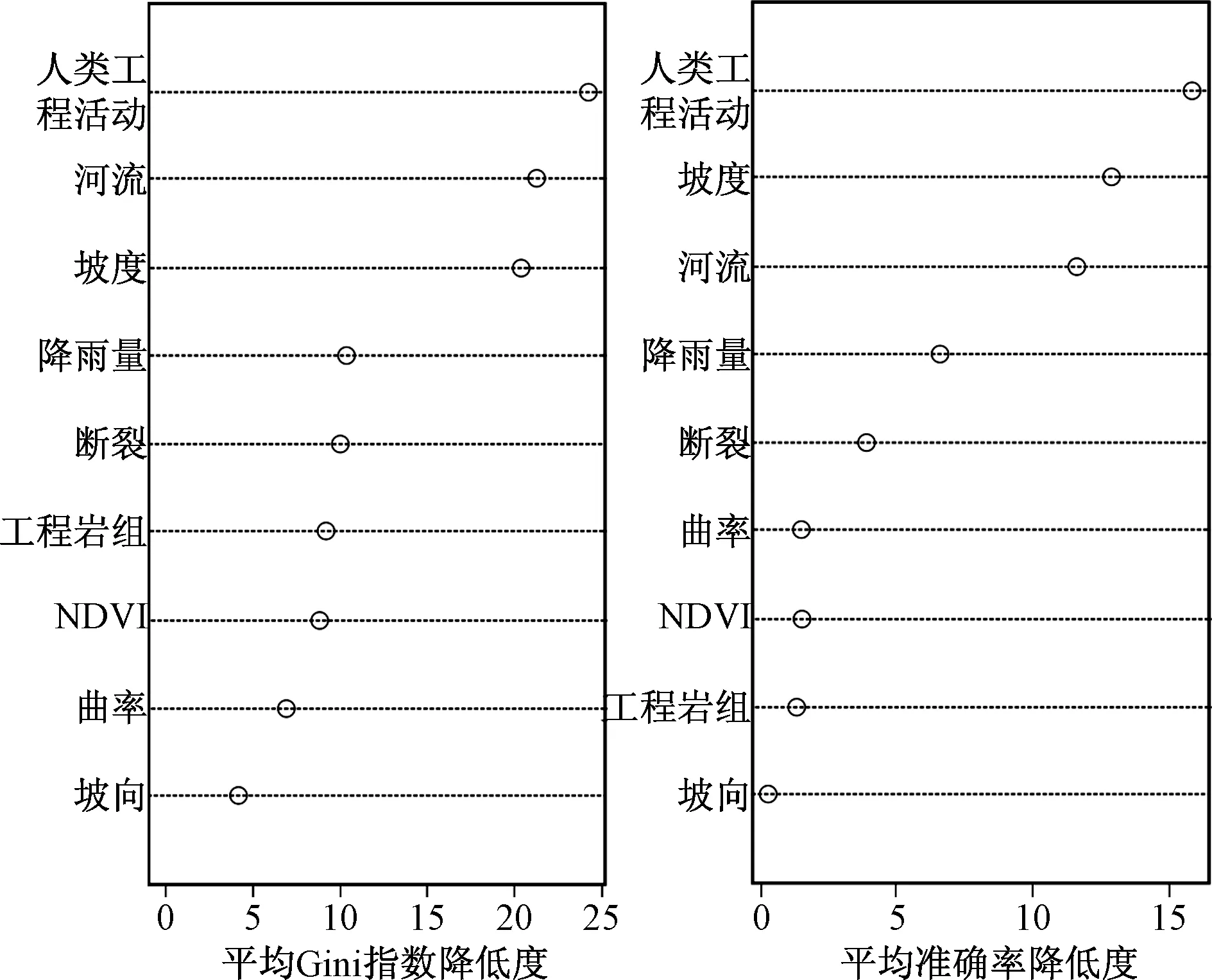
图3 因子重要性分析结果Fig.3 Factor importance evaluation
从两种因子重要性分析方法得出的结论来看,人类工程活动、河流侵蚀、坡度、降雨量都是对滑坡危险性贡献最多的四种因子;排名靠后的几个因子在两种方法中顺序虽有所变化,但考虑这几种因子比例相差不大,加上其相对重要性较低,因此,认为这种排序整体上是合理的。此次评价将平均Gini指数降低度作为客观权重ωi(表4)。
2.4 主观权重
(1)构建判断矩阵U
在RF模型筛选的滑坡危险性评价指标基础上,为了量化各评价因子的主观赋值权重,评价因子之间需形成一个两两对比的矩阵,通过专家赋值法,利用1~9标度表示评价因子之间的影响强弱(表3),确定判断矩阵U。
(2)AHP法确定主观权重

ai即为各因子对应的主观权重值,然后计算出最大特征值:
最后利用CR=CI/RI=(λmax-n)/RI(n-1) 进行一致性检验,由文[17]可知n=9时,RI=1.46。于是可知CR0.0392<0.1,表明主观权重计算合理。
2.5 组合权重
将上述所求的主观权重ai和客观权重ωi分别代入距离函数法计算公式(5)和(6),可得:
ν=1-μ=0.42
将μ、v带入式(2),即可得到各因子组合权重值φi(表4)。

表4 权重赋值表Table 4 Weight assignment table
2.6 危险性评价
将主观权重、客观权重及组合权重分别代入综合评价模型(式7),得到三种研究区滑坡危险性分区图(图4)。

图4 滑坡危险性区划图((a)为层次分析法;(b)为随机森林法;(c)为组合赋权法)Fig.4 Landslide susceptibility map(A:AHP;B:RF;C:RF-AHP)
3 危险性结果与讨论
3.1 危险性结果
得到全区滑坡危险性区划图后,统计得到了三种模型的危险性等级与实际灾害分布的对比关系(表5)。
3.2 讨论
对比分析三种方法得出的危险性评价结果可知:
AHP模型中的极高和中等危险性区域与已有滑坡灾害点的分布吻合性最好,但其危险性和极高危险性区域面积也是最高的,达到了1 365.6 km2。
RF模型结果中的低危险区、中危险区及高危险区面积均超过26%,且各区域内包括的灾害点数量没有较大变化,评价结果过于均值化。导致均值化的原因主要是由于RF模型对模型因子的相对不敏感性,模型往往会对不重要的因子高估,对重要的因子低估,导致危险性分区相对均值化[22]。
从RF-AHP区划结果来看:在高危险区和极高危险区面积占比38.38%的情况下,就包括了60.13%的滑坡灾害,结果准确性相比AHP和RF两种模型有较大提升;而且随着危险性等级的逐步提高,灾害实际发生的比率(b/a,亦即等级中的灾害密度与研究区总的灾害密度的比值)随之增大,说明RF-AHP不但把RF的高学习能力、预测精度和AHP的专家经验修正等优点进行了有效整合,还将两种模型各自的缺点进行优化,使得RF-AHP在评价准确性及实际应用方面有了较高的提升。
4 结论
(1)本文基于层次分析模型和随机森林模型,通过引入距离函数,探索性提出了一种新的组合赋权方法,并对组合模型进行了系统性的推导。以贵德县北部地区为研究区,选取了地形地貌、植被覆盖率、地质构造、工程岩组、河流侵蚀、降雨量和人类工程活动等9个评价指标对组合评价模型进行了验证,以Kappa系数和灾害实际发生比率两个指标对模型可靠度进行了检验分析。
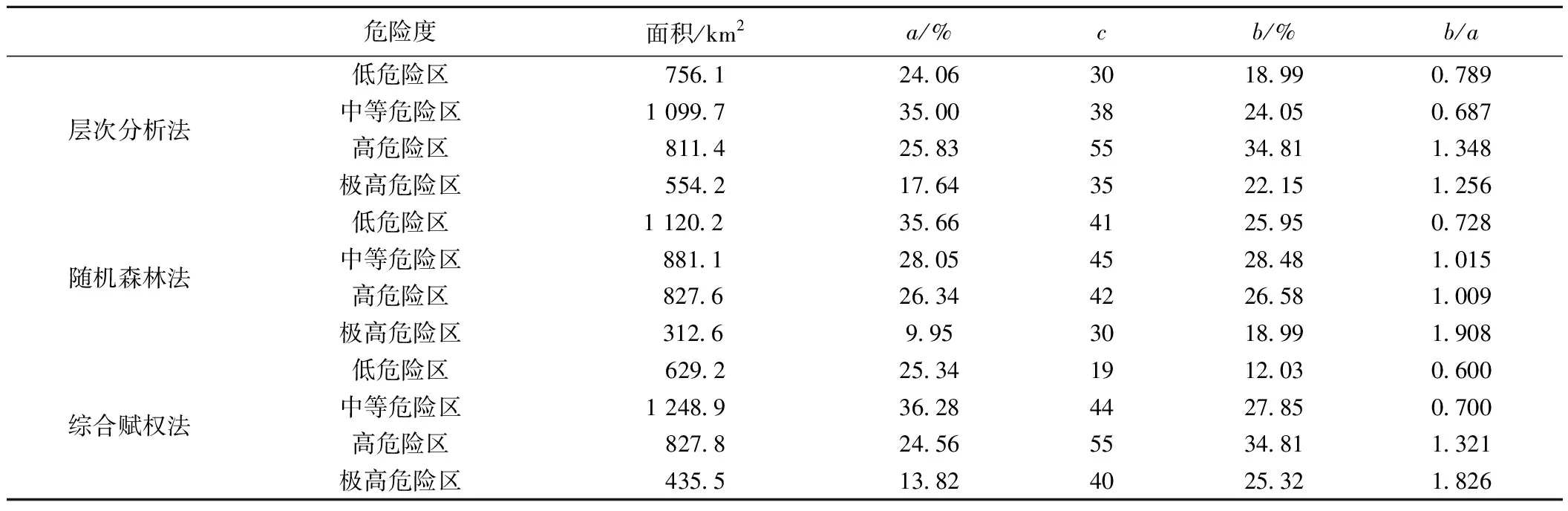
表5 划分的危险性等级与实际灾害分布的对比Table 5 Comparison between the evaluation results and the actual disaster distribution
注:(1)a为本类危险性等级的面积占研究区总面积的百分比;(2)b为落在该危险性分区内的灾害占灾害点总数的百分比;(3)c为落在该类危险性分区内的灾害数量。
(2)把评价结果同RF和AHP模型结果进行了比较,得到的危险性区划成果在空间分布上与既有历史滑坡数据一致性较好,说明本方法能够通过主、客观方法的结合和组合赋权规则的改进,得到相对真实、客观的滑坡危险性区划结果,为此类评价提供了一种新思路。
(3)基于RF-AHP的滑坡灾害评价模型同样存着适用性未知和研究缺陷,由于模型是基于大量的数据统计来进行规律拟合的,在灾害点样本量较少、样本质量较低的地区,该模型是否具有同样的可行性和精度尚不得而知。
