LWIP中零拷贝技术的研究与应用
2018-07-25赵成青李宥谋刘永斌
赵成青,李宥谋,刘永斌,王 涛
(西安邮电大学,陕西 西安 710000)
0 引 言
LWIP是瑞典计算机科学院(SICS)的Adam Dunkels开发的用于嵌入式系统的开源TCP/IP协议栈[1]。LWIP的含义是轻量级的TCP/IP协议,专注于减少资源消耗。嵌入式网络传输系统由于成本资源的限制,往往采用简化的TCP/IP协议。文中通过研究、分析常用的嵌入式网络协议栈LWIP的结构,在物理层和应用层提出了提高系统传输效率的改进方法。
在小型嵌入式系统中,LWIP的实现基于上层协议已明确知道下层协议所使用的数据结构的特点[2]。它会假设各层间的部分数据结构和实现原理在其他层是可见的。在数据包递交过程中,各层协议可以通过指针直接指向数据包中其他层次的字段。所以上层可直接使用取地址计算得到下层中的数据,这不仅使整个协议栈对数据包的操作更加灵活,而且避免了LWIP协议栈内部数据递交时的复制。但是,这仅仅是在LWIP协议栈内部实现数据的零拷贝。在物理网卡向协议栈传递数据时和协议栈向应用程序传递数据时,还是存在两次消耗较大的数据拷贝过程。所以,文中提出在网卡接收数据时让LWIP内核存储区指针直接指向物理网卡的寄存器地址的方法,避免了物理网卡数据到LWIP协议栈缓冲区数据的拷贝[3]。在应用层,提出了利用μcos操作系统的邮箱机制,避免了多个外部应用程序和协议栈内核交互时的数据拷贝[4],从而实现了从物理层到应用层真正的数据零拷贝,并且提高了系统的并发性。
1 物理网卡到LWIP协议栈数据的传递
在嵌入式系统中应用比较广泛的是MicroChip公司的ENC28J60网卡。在网卡驱动函数接收数据包时,网卡驱动函数首先向网卡发送数据包传送指令,此时网卡会把BNRY(边界寄存器)处的一个网卡格式的数据包数据一次性全部发送到DMA端口,此时网卡驱动函数会在DMA端口读取所有字节数据后,网卡会自动将BNRY(边界寄存器)值调整为下一个数据包地址,以准备下一次读取所有字节数据。然后将接收到的数据封装成LWIP熟悉的格式并且写到缓冲区中,这个过程涉及到数据到拷贝[5]。在ENC28J60网卡中接收缓冲器由一个硬件管理的循环FIFO构成。ERXST表示接收缓冲区起始地址,ERXNDH表示接收缓冲区结束地址[6]。如图1所示,通过把网卡相关的寄存器映射到LWIP内核内存空间,就可以直接对网卡寄存器进行操作,避免了物理网卡到LWIP内核空间的数据拷贝。然后封装成LWIP内核能够识别的pbuf类型的数据包结构,在LWIP内核中由low_level_input()函数完成这个功能。通过ehternetif_input()函数解析该数据包的类型,然后将该数据包指针递交给相应的上层。
2 LWIP协议层间数据传递
在网卡接收数据时,需要申请一个数据包,然后将网卡中的数据填入数据包中。发送数据包时,协议栈的某层中会申请一个pbuf,并将相应的数据装入到数据区域,同时相关的协议首部信息也会被填写到pbuf的预留数据区域中[7]。数据包申请函数有两个重要参数,一个是想申请的数据包pbuf类型,另一个重要参数是该数据包是在协议栈中哪一层被申请的,分配函数会根据这个层次的不同,在pbuf数据区域前为相应的协议预留出首部空间,这就是offset值。总的来说,LWIP定义了四个层次,当数据包申请时,所处的层次不同,会导致预留空间的offset值不同[8]。层次定义时通过一个枚举类型pbuf_layer:
Typedef enum{
PBUF_TRANSPORT,//传输层
PBUF_IP,//网络层
PBUF_LINK,//链路层
PBUF_RAW,//原始层
}pbuf_layer;
上面的结构体中除了定义枚举类型pbuf_layer来表示各个网络协议层的名称外,还定义了两个宏:PBUF_TRANSPORT_HLEN和PBUF_IP_HLEN。前者是典型的TCP报文首部长度,而后者是典型的不带任何选项字段的IP首部长度。代码如下所示:
Switch(layer){
Case PBUF_TRANSPORT:
Offset=PBUF_LINK_HLEN+PBUF_IP_HLEN+PBUF_TRASNSPORT_HLEN;
Case PBUF_IP:
Offset=PBUF_LINK_HLEN+PBUF_IP_HLEN;
Case PBUF_LINK:
Offset=PBUF_LINK_HLEN;
Case PBUF_LINK:
Offset=0;
在LWIP的数据包管理函数pbuf.c中,首先根据数据包申请时传入的协议层参数,计算需要在pbuf数据区签预留的长度offset值,然后根据pbuf的类型进行实际申请。Pbuf_pooll类型申请最复杂[9],因为可能需要几个pool连接在一起,以此来满足用户的空间需求。
限于篇幅,对LWIP内存分配机制不做深入研究;pbuf_ref和pbuf_rom类型申请最简单,它们只是在内存MEMEP_PBUF中分配一个pbuf结构空间,然后初始化相关字段,注意这两种类型的payload指针需要用户自行设置,通常在调用完函数pbuf_alloc后,调用者需要将payload指向某个数据区。
在原始层以太网驱动中:
P=pbuf_alloc(PBUF_RAW,recvlen,PBUF_RAM);
这个调用语句申请了一个PBUF_RAM类型的pbuf,且其申请的协议层为PBUF_RAW,所以pbuf_alloc函数不会在数据区前预留出任何首部空间;通过使用p->payload,就可以实现对pbuf中数据区的读取或者写入操作了。
在传输层TCP层:
P=pbuf_alloc(PBUF_RAW,recvlen,PBUF_RAM);
它告诉数据包分配函数使用PBUF_RAM类型的pbuf,且数据前应该预留一部分的首部空间。由于这里是PBUF_TRANSPORT层,所以预留空间将有54个字节,即TCP首部长度的20个字节、IP数据包首部长度的20个字节以及以太网帧首部长度的14字节。当数据包往下层递交,各层协议就直接操作这些预留空间的数据,以实现数据首部的填写,这样就避免了数据的拷贝。
3 LWIP软件与用户程序间的数据传递
3.1 用户缓冲数据结构
协议栈API实现时,也为用户提供了数据包管理函数,可以完成数据包内存申请、释放、数据拷贝等任务。无论是UDP还是TCP连接,当协议栈接收到数据包后,会将数据封装在一个netbuf中,并递交给应用程序[10]。在发送数据时,不同类型的连接将导致不同的数据处理方式。对于TCP连接,内核会根据用户提供待发送数据的起始数据和长度,自动将数据封装在合适的数据包中,然后放入发送队列;对于UDP,用户需要手动将数据封装在netbuf中,通过调用发送函数,内核直接发送数据包中的数据段。
应用程序使用netbuf结构来描述、组装数据包,该结构只是对内核pbuf的简单封装,是用户应用程序和协议栈共享的。外部应用程序可以使用该结构来管理发送数据、接收数据的缓冲区。netbuf是基于pbuf实现的,其结构如以下代码所示:
Struct netbuf{
Struct pbuf *p,*ptr;
Ip_addr_t *addr;
U16_t port;
}
其中,netbuf相当于一个数据首部,保存数据的字段是p,它指向pbuf链表首部,ptr指向链表中的其他位置,addr表示IP地址,port表示端口号。
netbuf是应用程序描述待发送数据和已接收数据的基本结构,引入netbuf结构看似会让应用程序更加繁杂,但实际上内核为应用程序提供了API,通过共享一个netbuf结构(如图2所示),两部分API就能实现对数据包的共同处理,避免了数据拷贝。

图2 用户缓冲区结构
3.2 操作数据缓冲区指针
与BSD相同,LWIP协议栈API也对网络连接进行了抽象。但它们之间的抽象存在一定的差别:BSD实现了更高级别的抽象,用户可以像操作文件那样来操作一个网络连接;LWIP中,API只能实现较低级别的抽象,用户操作的仅仅是一个网络连接,而不是文件。在BSD中,应用程序处理的网络数据都处于一片连续的存储区域中,可以使用户对数据的处理更加方便。在LWIP中,若API使用上述数据存储机制可能会导致很大的缺陷,因为LWIP中网络数据都存储在pbuf中,如果要实现存储在连续的存储区的话,需要将所有pbuf数据拷贝到这个连续的存储中,这将造成数据的拷贝。为了避免数据拷贝以后再递交给用户,需要直接操作pbuf的一些方法,而LWIP中恰恰提供了这些方法。比如通过netbuf_next()可以修改数据指针指向下一个数据段,如果返回值为0,表示netbuf中还存在数据段,大于0说明指针已经指向netbuf中的最后一个数据段了,小于0表明netbuf中已经没有数据段了。当用户未调用netbuf_next()函数的情况下,ptr和p都默认指向第一个pbuf。通过netbuf_next()对协议栈和应用程序共同缓冲区指针的调整和读取,避免了应用程序和数据以及内核栈的拷贝。
4 应对多个外部应用程序的指针传递
在单独运行LWIP时,用户应用程序和协议栈内核处于同一进程中,用户程序通过回调的方式进行。这样,用户程序和协议栈内核出现了相互制约的关系,因为用户程序执行的时候,内核一直处于等待状态,内核需要等待用户函数返回一个处理结果再继续执行。如果用户执行计算量很大,执行时间很长,则协议栈代码就一直得不到执行,协议栈接收,处理数据包效率会受到直接的影响。最严重的结果是,如果发送方速度很快,则协议栈会因为来不及处理而出现丢包的情况。
为了设计多进程外部应用程序,将LWIP移植到μcos操作系统下,让LWIP内核作为操作系统的一个任务运行[11]。LWIP协议栈设计时,提供了协议栈与操作系统之间函数的接口。协议栈API由两部分组成。一部分提供给应用程序,一部分提供给协议栈内核。应用程序和协议栈内核通过进程间通信机制进行通信和同步[12]。使用到的进程通信机制包括了以下三种[13]:
(1)邮箱,例如内核邮箱mbox、连接上接收数据的邮箱recvmbox;
(2)信号量,例如op_completed,用于两部分API同步;
(3)共享内存,例如内核消息结构tcp_msg、API消息内容api_msg等[14]。
两部分API间的关系如图3所示。API设计的主要思想是让应用程序成为一个单独的进程;而协议栈也成为一个单独的进程。用户进程只负责数据的计算等其他工作,协议栈进程仅仅负责通信工作。两部分进程之间使用三种IPC方式中的邮箱和信号量集,内核进程可以直接将数据递交到应用程序邮箱中,然后继续执行,不必阻塞等待,邮箱对于应用程序来说就像一个输入队列,提高了系统的实时性[15]。
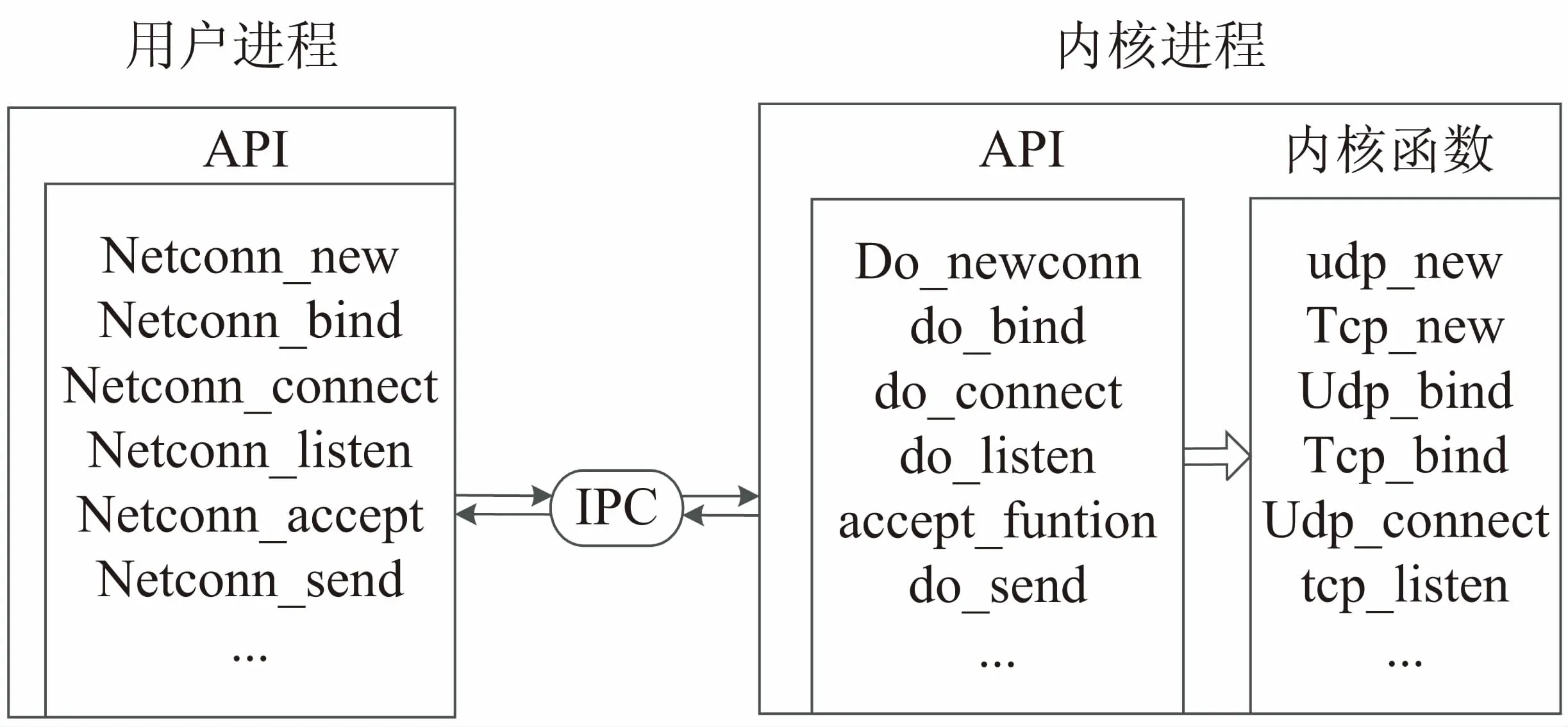
图3 两部分独立进程间的通信
全局邮箱mbox在协议栈初始化时建立,用于内核进程tcpip_thread接收消息。内核进程通过共享内存的方式与协议栈的其他各个模块进行通信,它从邮箱中获得的是一个指向消息结构的指针。函数tcp_input在内存池中为系统消息结构申请空间,并根据消息类型初始化结构中的相关字段,把内核消息封装在tcp_msg结构中,最后将消息投递到系统邮箱中等待内核进程tcpip_thread处理。tcpip_thread使用从邮箱中获得的指针指定到对应内存地址处读取消息内容,从而避免了两个进程间通信的数据的拷贝。
5 性能测试对比及其应用
在局域网内,对ARM开发板STM32F103VET6-EV上基于无操作系统和移植了μcos操作系统的LWIP两种方法编写的UDP服务器进行数据吞吐能力的测试,以此来估算网卡及整个板子的网络处理性能及对比无操作系统模拟层和在操作系统模拟层下编写的UDP服务器性能的差别。
在Windows主机上运行iperf软件来测试服务器的数据吞吐能力。如图4(a)所示,在软件上选择UDP协议,设置好服务器IP地址(192.168.1.230)和端口号(5000)后,单击start iperf,软件开始对服务器性能进行测试。从图4(a)可以看出,服务器的上下行带宽都可以维持在9 800 kb/s左右,很接近ENC28J60网卡的处理值上线10 M/s。在操作系统模拟层下基于LWIP零拷贝技术编写的UDP服务器,板子的网络处理性能达到最优。从图4(b)可以看出,基于无操作系统模拟层下编程的服务器在客户端连续发送大量数据时导致丢包情况,严重情况下甚至出现死机的情况。
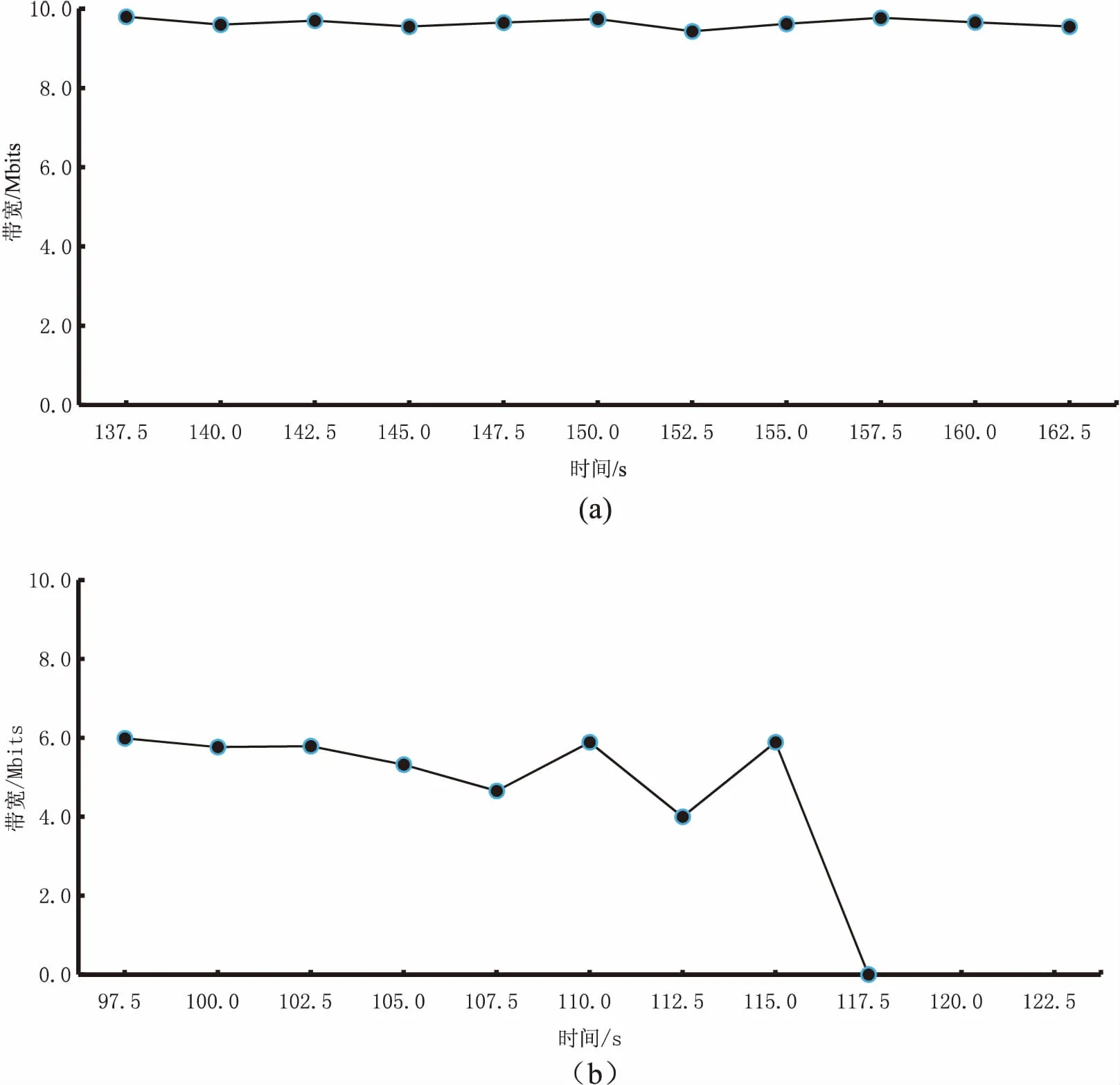
图4 UDP性能测试
6 结束语
综上所述,在应对多个外部应用程序的情况下,无操作系统模拟层的UDP服务器编程,虽然避免了数据的拷贝,但是无法应对多个外部应用程序。所以将LWIP移植到μcos操作系统下,不仅减少了内存开销,而且能够应对多个外部应用程序。文中的研究成果已经成功应用于嵌入式网管系统项目并实际运行,不仅提高了基于STM32平台μcos操作系统下测量仪器代理模块的传输效率,提高了系统的实时性,而且节约了内存开销。
